MySQL语句技巧
1、查询时间的格式:
(1) 查询时将时间戳格式化
SELECT FROM_UNIXTIME(eventtime) FROM table_name SELECT FROM_UNIXTIME(eventtime, '%Y-%m-%d %H:%i:%S') FROM table_name
(2) 查询1月18号 post_date为date或者datetime类型,同理可以只 month(post_date)=n查某个月,或者 day(post_date)=n某一天,或者 year(post_date)=n 某一年的数据。
SELECT * FROM posts WHERE MONTH(post_date)='1' AND DAY(post_date)='18';
(3)查询datetime类型时,只对比其中的日期。例如查询2019-01-02数据,post_date为datetime类型、post_time为时间戳(int)类型
SELECT * FROM posts WHERE DATE(post_date) = '2019-01-02'; SELECT * FROM posts WHERE DATE_FORMAT(post_time,'%Y-%m-%d') = '2019-01-02'; SELECT * FROM posts WHERE post_time>=unix_timestamp('2019-01-02')
(4)按时间分组查数据
SELECT DATE_FORMAT(eventtime,'%Y%m') AS ym,COUNT(*) FROM table_name GROUP BY ym #按月分组 SELECT DATE_FORMAT(eventtime,'%Y%m%d') AS ymd,COUNT(*) FROM table_name GROUP BY ymd #按天分组
(4)按周分组和按月分组查数据
#按周统计,mdate为每周第一天,如果某一周里只有一天有数据,比如2023-01-02,则mdate为该2023-01-02,而不是该周第一天2023-01-01 SELECT MIN(event_time) AS mdate,DATE_FORMAT(event_time,"%X-%V") week_num,SUM(ltv14d) AS LTV1W,SUM(ltv0m) AS LTV0M FROM data_ltv_debug WHERE event_time>='2022-03-01' GROUP BY week_num; #按月统计 SELECT DATE_FORMAT(event_time,'%Y-%m') AS mdate,SUM(ltv14d) AS LTV1W,SUM(mltv0m) AS LTV0M FROM data_ltv_debug WHERE event_time>='2022-03-01' AND event_time<'2023-05-01' GROUP BY mdate;
2、查询一段时间内,每5分钟间隔分时在线数据统计(eventtime是时间戳)
可以延伸统计一段时间内每10分钟、30分钟、1小时等时间段为分组的登录、付费、激活等各种数据。
SELECT FROM_UNIXTIME(`eventtime`-`eventtime`% (5*60), '%Y-%m-%d %H:%i:%S') AS stime, count(distinct uid) uids FROM 20170828_online WHERE eventtime>=1503921000 AND eventtime<=1503925200 GROUP BY stime;
3、最高效的删除重复记录方法 ( 因为使用了ROWID)例子:
#使用临时表 CREATE TABLE tmp SELECT last_name, first_name, sex FROM person_tbl GROUP BY (last_name, first_name, sex); DROP TABLE person_tbl; ALTER TABLE tmp RENAME TO person_tbl; #加主键 ALTER IGNORE TABLE person_tbl ADD PRIMARY KEY (last_name, first_name); #其他 DELETE FROM EMP E WHERE E.ROWID > (SELECT MIN(X.ROWID) FROM EMP X WHERE X.EMP_NO = E.EMP_NO);
4、将两个表的查询结果合并成一行
select A.newusers,B.pay from (SELECT COUNT(DISTINCT uid) AS newusers FROM applogs.20171025_firstentry WHERE game=12 AND client=1) AS A,(SELECT SUM(money)/100 AS pay FROM applogs.20171025_paylog WHERE eventdate=flogindate AND game=12 AND client=1 ) AS B;
5、列转行技巧
eg:统计id为1的记录数,id为2的记录数以及id为3的记录数。
SELECT COUNT(CASE WHEN id=1 THEN 1 ELSE NULL END ) AS `one_num`,COUNT(CASE WHEN id=2 THEN 1 ELSE NULL END ) AS `two_num`,COUNT(CASE WHEN id=3 THEN 1 ELSE NULL END ) AS `tree_num` FROM test; #转化列的内容 SELECT CASE WHEN DATE_FORMAT(eventdate,'%W')='Monday' THEN '星期一' WHEN DATE_FORMAT(eventdate,'%W')='Sunday' THEN '星期天' ELSE '其他' END AS week_name FROM test
6、group_concat函数的使用方法
公式:group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符'])
比如:SELECT GROUP_CONCAT(row_id ORDER BY eventtime SEPARATOR "||") AS tmp_str FROM test.tmptable;
将查询row_id列根据eventtime排序后用 || 为分隔符号连接器字符串。分隔符也可以用 - ,. ',' 等。
基础表格:(以5中的表格数据为例)
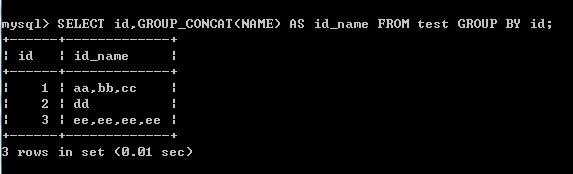
(1)以id分组,把name字段的值放在同一结果行,以逗号分隔(默认)
SELECT id,GROUP_CONCAT(NAME) AS id_name FROM test GROUP BY id;
结果:
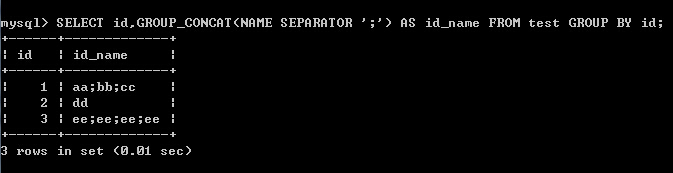
(2)以id分组,把name字段的值放在同一结果行,以分号分隔
SELECT id,GROUP_CONCAT(NAME SEPARATOR ';') AS id_name FROM test GROUP BY id;
结果:
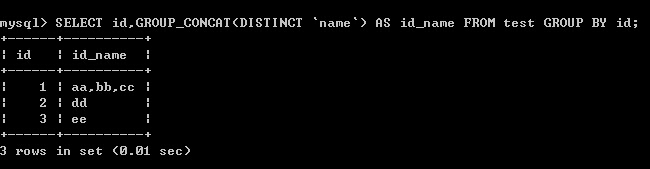
(3)以id分组,把去冗余的name字段的值放在同一结果行, 以逗号分隔
SELECT id,GROUP_CONCAT(DISTINCT `name`) AS id_name FROM test GROUP BY id;
结果:
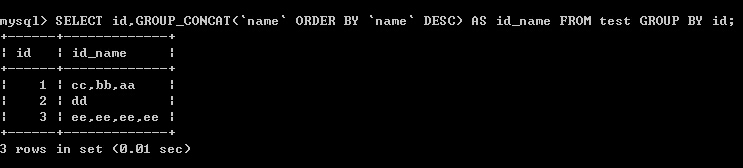
(4)以id分组,把name字段的值放在同一结果行,逗号分隔,以name排倒序
SELECT id,GROUP_CONCAT(`name` ORDER BY `name` DESC) AS id_name FROM test GROUP BY id;
结果:
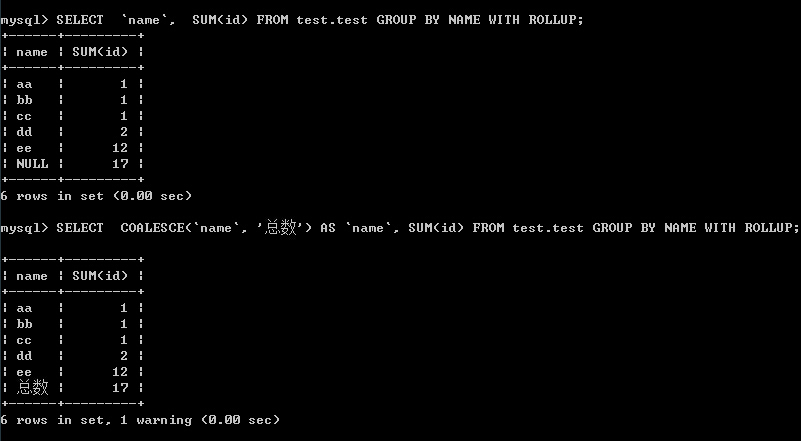
7、with rollup 的用法 (表格以5中的数据表为例)
SELECT `name`, SUM(id) FROM test.test GROUP BY NAME WITH ROLLUP SELECT COALESCE(`name`, '总数') AS `name`, SUM(id) FROM test.test GROUP BY NAME WITH ROLLUP
结果:
COALESCE函数说明:
select coalesce(a,b,c);
如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null。coalesce(a,b,c,d...)同理。
8.0、插入或更新:插入数据出现UNIQUE索引或PRIMARY KEY冲突时就使用更新(ON DUPLICATE KEY UPDATE 语法)
INSERT INTO `sy`.`day` (id, name, phone) VALUES('666', 'xst', '10086') ON DUPLICATE KEY UPDATE name = VALUES(name),phone = VALUES(phone); INSERT INTO table_name (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1; (UPDATE TABLE SET c=c+1 WHERE a=1;) INSERT INTO table_name (a,b,c) VALUES (1,2,3),(2,5,7),(3,3,6),(4,8,2) ON DUPLICATE KEY UPDATE b=VALUES(b);
8.0.1插入一行数据,当主键已经存在,则更新该主键的相关数据,但数据表中 level原先的数据等于0或者为空或者小于即将更新进去的 level 值的时候,就将新的值更新进去,否则不做处理。
INSERT IGNORE INTO test.test (uid,roleid,rolename,game,`server`,`level`) VALUES('2','1002','test2','1','1001','98') ON DUPLICATE KEY UPDATE `level` = (CASE WHEN `level`=0 OR 'level'=NULL OR `level`<VALUES(`level`) THEN VALUES(`level`) ELSE `level` END)
8.1 插入或替换:如果我们希望插入一条新记录(INSERT),但如果记录已经存在,就先删除原记录,再插入新记录。此时,可以使用REPLACE语句,这样就不必先查询,再决定是否先删除再插入:
REPLACE INTO tablename (id, name, phone) VALUES (1, 'xst', '13333333333');
8.2 插入或忽略:如果我们希望插入一条新记录(INSERT),但如果记录已经存在,就啥事也不干直接忽略,此时,可以使用INSERT IGNORE INTO ...语句:
INSERT IGNORE INTO tablename (id, name,phone) VALUES (1, 'xst', '13333333333');
9、若两个表字段相同或相似,将一个表的数据插入另一个表
表字段相同的情况:
INSERT INTO dbname.table1 select * FROM dbname.table2;
表字段不同的情况:
INSERT INTO dbname.table1 (a,b,c,d,e,f,g) SELECT a,b,c,d,e, x as f,y as g FROM dbname.table2;
10、查询一个用户是否连续 7天或者10天登录(通过两个日期字段计算其相差的天数)
SELECT eventdate FROM login WHERE user='xst' AND DATEDIFF(eventdate,firstlogindate)<=7 GROUP BY eventdate SELECT COUNT(DISTINCT eventdate) AS days FROM login WHERE user='xst' AND DATEDIFF(eventdate,flogindate)<=7
11、查询某个字段的一个值出现过两次以上的记录
(1)查询数据表中did出现两次以上的记录:
select * from did_table where did in (select did from did_table group by did having count(did)>1);
(2)查询用户登录数据表(记录一个用户登录时的用户和设备信息)中使用两种以上客户端(或者设备)登录的用户。uid为用户id,cid为客户端id
SELECT uid,COUNT(cid) AS cids FROM (SELECT uid,cid FROM data_base.20181104_login WHERE channel='140' GROUP BY uid,cid) AS A GROUP BY uid HAVING cids>1;
12、将一个表(B)的某个字段数据更新到另一个表(A)
UPDATE first_open A, open B SET A.uuid=B.uuid WHERE A.game=B.game AND A.did=B.did AND A.cid=B.cid AND A.aid=B.aid AND A.osid=B.osid and A.ip=B.ip and A.eventtime=B.eventtime
13、查询每个用户最后一条数据
select * from (select * from usertable order by eventtime desc) a group by uid;
第(1)这种方式有一种缺点:Using temporary; Using filesort; 并且当查询的表中有自增ID或者其他非eventtime字段的主键时,使用时间字段就会无效,默认只获取到自增ID最小的行。因为group by一般主键优先。
select B.* from (select uid,max(mtime) as mtime from usertable group by uid) A left join usertable as B on A.uid=B.uid and A.mtime=B.mtime
获取每个uid的mtime最大的记录,也可以用min获取每个uid的mtime最小的记录,当A有where条件时,B的where条件应当与A相同,不然,B有太多未筛选的数据,可能导致预期结果不理想。比如:
select B.* from (select uid,max(mtime) as mtime from usertable where pid='10' and mdate=flogindate group by uid) A left join usertable as B on A.uid=B.uid and A.mtime=B.mtime where B.pid='10' and B.mdate=B.flogindate
14、查询两个表某个字段的交集
(1)左表有,右表没有 left join
SELECT A.finish_date,B.game,A.order_num,B.pay_num,B.pay_type,A.company FROM mydb.mytable AS A LEFT JOIN mydb.testtab AS B ON A.order_num = B.pay_num WHERE B.game=63 AND B.pay_num IS NULL
(2)右表有,左表没有 right join
SELECT B.game,A.order_num,B.pay_num,B.pay_type FROM mydb.mytable AS A RIGHT JOIN mydb.testtab AS B ON A.order_num = B.pay_num WHERE B.game=63 AND A.order_num IS NULL
(3) 此外,inner join 交集,union 为并集去重,union all 为并集不去重。
15、sql中的三元表达式
SELECT IF(type=1,'增加','减少') AS type,role_name,item_name FROM_UNIXTIME(eventtime) FROM base.item SELECT CASE WHEN type=1 THEN '增加' ELSE '减少' END AS type,role_name,item_name FROM_UNIXTIME(eventtime) FROM base.item
16、假设A表xid原先只是个ID字段,与之对应的名称字段在其他表B,或者通过同一张表的子查询获取,将B表中的名称字段映射给A表的xid字段
SELECT A.aid,A.aname,A.`xid`,B.aname AS xname FROM db.table AS A LEFT JOIN (SELECT aid,aname FROM db.table WHERE xxx) AS B ON A.xid=B.aid WHERE A.aid>0
17、表名后面加 force index(索引名) 强制使用索引:
在查询或者更新的时候,数据库系统会自动分析查询语句,并选择一个最合适的索引。但是很多时候,数据库系统的查询优化器并不一定总是能使用最优索引。如果我们知道如何选择索引,可以使用FORCE INDEX强制查询使用指定的索引(当然了,指定索引的前提是索引 index_id 必须存在)。例如:
SELECT * FROM students FORCE INDEX (index_id) WHERE class_id = 1 ORDER BY id DESC; UPDATE a FORCE INDEX(indexname) SET id=22 WHERE id=1 AND time='2021-03-23' UPDATE login AS a FORCE index(index_uid), register as b set a.server=b.server,a.flogintime=b.eventtime where a.uid = b.uid
17.2 表面后面加 ignore index(index_name) 忽略索引
针对重复度较高的列(比如只有成功和失败的状态列,大多数是成功,少数是失败),查询成功的状态数据时忽略索引触发全表扫描反而比使用索引更快,查询失败的数据时加上索引更快。
SELECT * FROM students ignore INDEX (index_id) WHERE class_id = 1 ORDER BY id DESC;
18、联表删除
注意:delete后面要跟随表的别名,比如event_info a 那么就是 delete a from...
delete a from event_info a, tracker_info b where a.tracker=b.tracker and b.channel='渠道名' and a.eventtime>='2021-09-03' and a.eventtime<'2021-09-07'
注意:
GROUP BY 能对一个表中某个字段进行分组,如果需要通过 GROUP BY 来获取用户的一行数据,或者用 GROUP BY 作为子查询去获取每个用户的一行数据时,则需要注意,获取到的是用户的哪一行记录?
换句话说,比如一个用户账号A有10条订单记录,如果 GROUP BY A 之后,可以查看到该用户的一条记录。那么这条记录是10条记录中的哪一条呢?这个问题在某些场景下会直接影响到该步骤后面的代码逻辑。
分以下几种情况:
1:没有主键的情况下,按照插入顺序的第一条。
2:有主键的情况下,按照主键升序排序后的第一条。如果有多个主键,则是多个主键分别升序排序后的第一条。(相当于 select * from table order by 主键1 ASC,主键2 ASC... limit 1)
3:原本没有主键后来加上主键的情况,则数据按照第2点方式排序获取。
4:原本有主键后来删掉主键的情况下,原本有主键的那部分数据仍然按照第2点的方式排序,删除掉主键后,新插入的数据则按照步第1点的方式排序。此时 group by 获取到的,是原本有主键时按照主键排好序的那部分数据的第一行数据。其实就是相当于删除主键后的表是一张新表,然后把原本数据找第2点有主键时排好序后的顺序插入。就回归到第一点的情况了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号