OO第一单元总结
OO第一单元总结
目录
第一次作业
思路
- 标准化输入,去除空格。
- 正则表达式识别项,合并正负号。
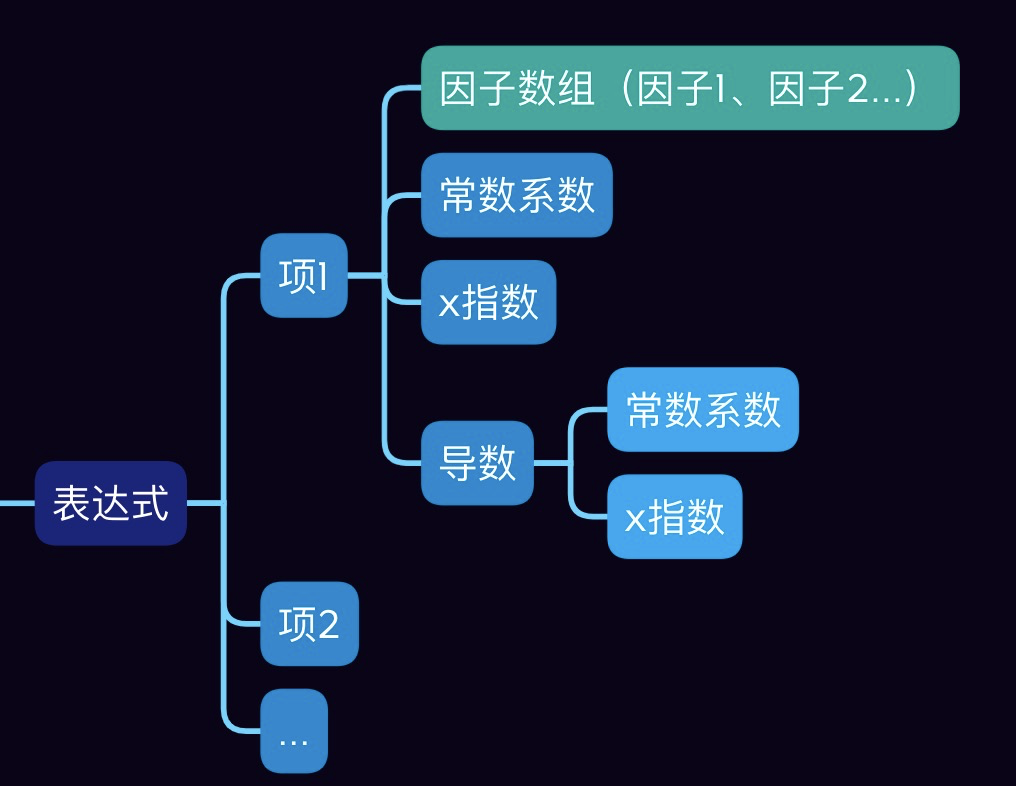
- 正则表达式识别项中的因子,把每个项合并成
a*x**b的形式,并求导存储形式不变。 - 对项进行合并(使用HashMap),并优化输出。
UML
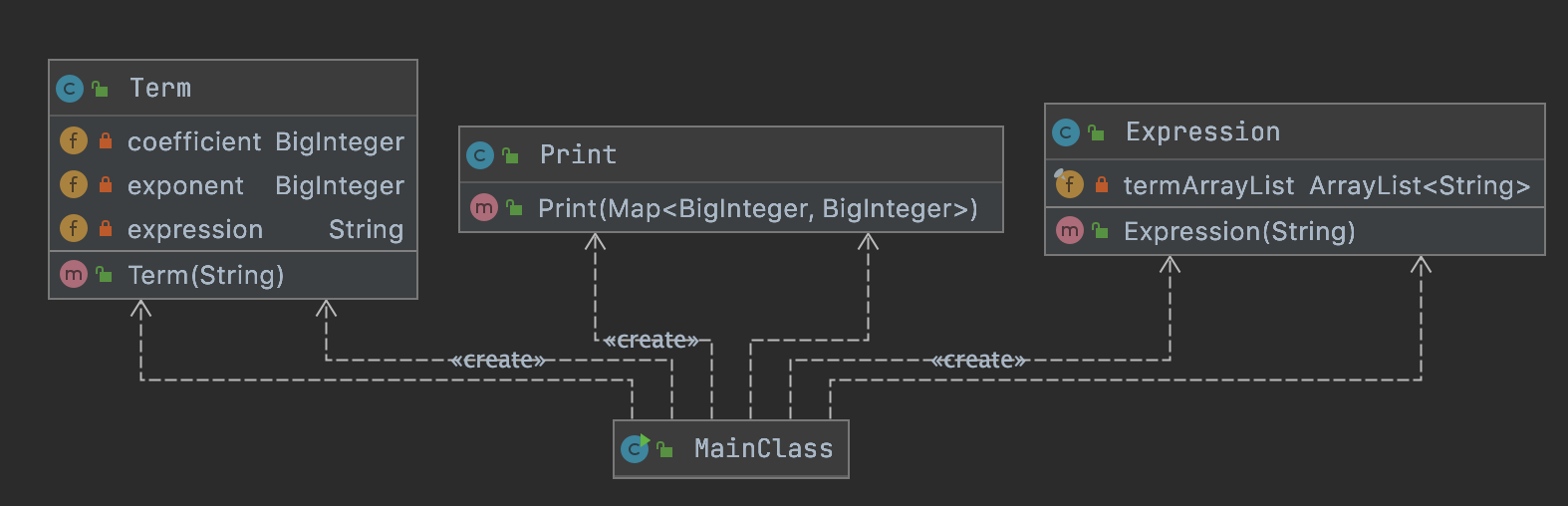
主要类的逻辑关系
- 深蓝色表示
Expression层 - 浅蓝色表示
Term层 - 浅绿色表示
Factor层
Statics

Metrics
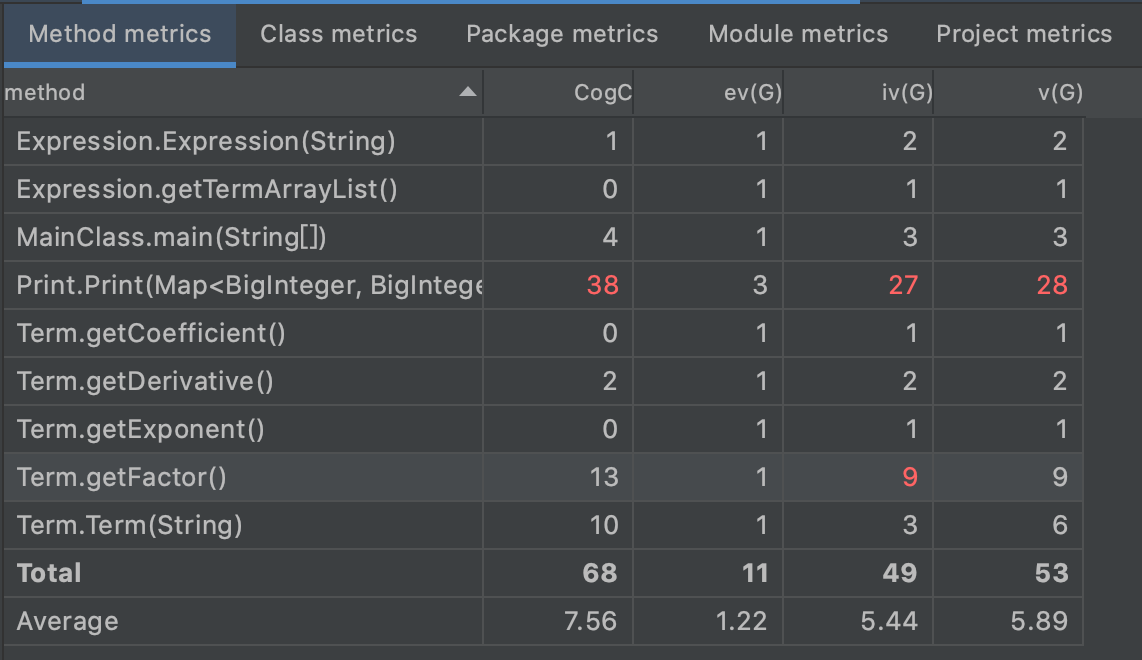
从复杂度分析来看
- Print函数由于掺杂了过多的用于优化输出
if-else,圈复杂度很高,更加难以覆盖测试。事实上,如果将优化部分作为单独的模块,并配以合适的接口应该可以有效降低输出方法的复杂度。 Term.getFactor()方法是因为我选择冗余设计多次识别因子来降低出错概率,事实上是完全没必要的。
Bug
这次作业在强测环节未出现错误,反而在互测环节因为一个优化导致的+x被输出为x被hack了一次。(可能是因为第一次,强测比较友好,不然可能会被扣掉不少分)。这其实是相当于我连自己代码特判的优化情况都没有用全部覆盖测试...后面的作业我也吸取了相关经验,至少要保证每种特判情况都完成功能测试。
第二次作业
思路
- 仍然不涉及WrongForamt,输入同样地去除空格,以项为单位合并正负号。
- 由于出现了表达式嵌套,原来的线形思维正则表达式拆解输入不再好用,经过多番尝试与调查,我选择了在预处理环节,将最外层的所有
(与)替换为<与>,以此对当前处理的表达式层次进行标记,<与>内部的字符以^>(正则表达式,含义为非>字符的所有字符)进行概括。 - 通过正则表达式识别项与因子,引入工厂模式生成具有共同抽象父类
Factor的四种因子们。 - 将
表达式项与三角函数项的括号内容分别按照表达式与项继续分层解析,并至此完成对输入表达式的嵌套解析。 - 输出环节类之间的嵌套关系决定了输入解析的调用顺序完全适用于输出,因此可以直接递归输出。
- 优化环节我做的并不好,因为按照字符串传递导数的结构导致我并不能拆除括号进行优化,不大幅度改变结构的前提下,我仅能做的是合并
常数项和幂函数项,当然在第二次作业的前提下也可以合并三角函数项但也是由于三角函数并不要求内部嵌套,终究也是治标不治本。
UML
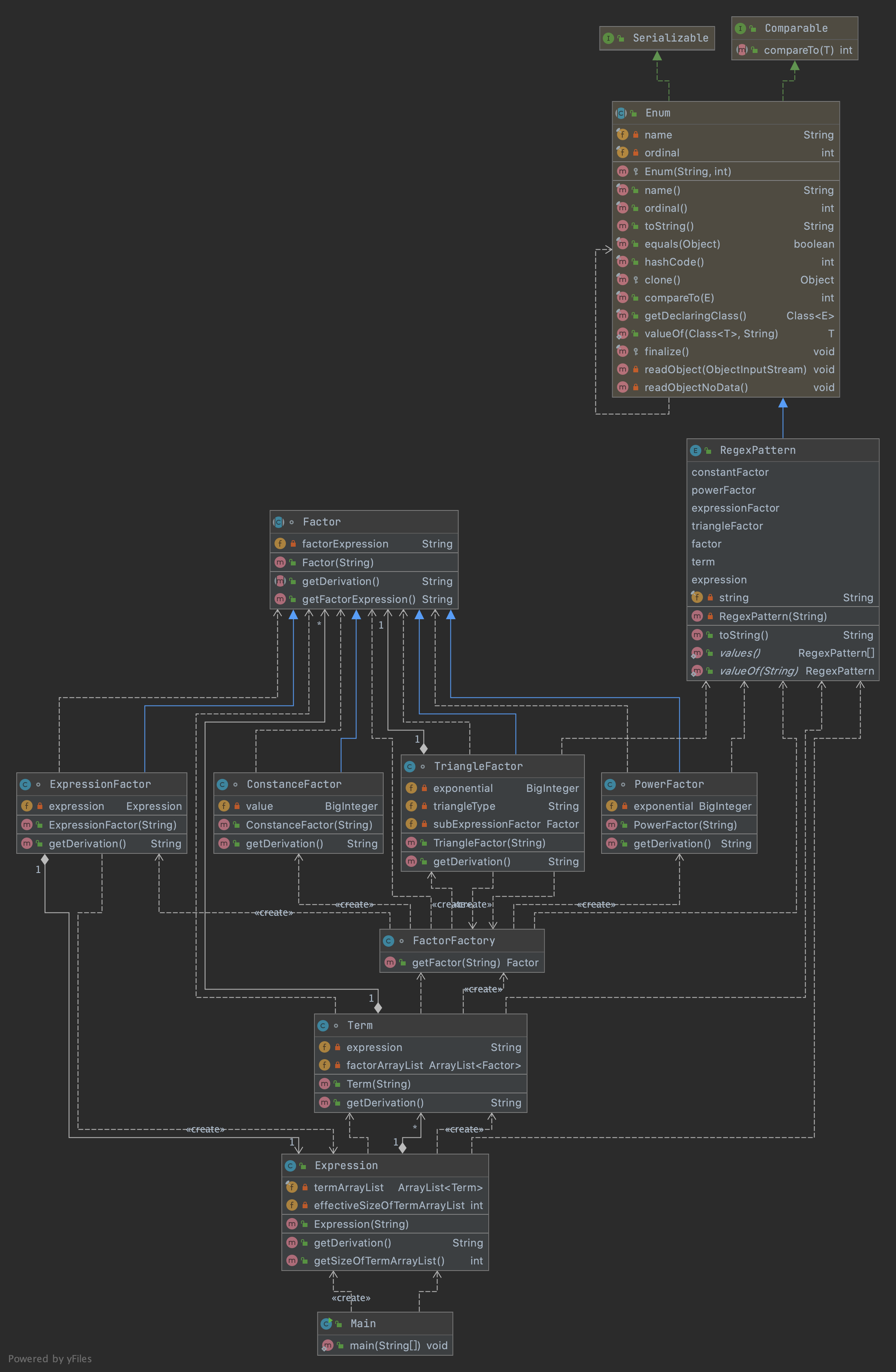
主要类的逻辑关系
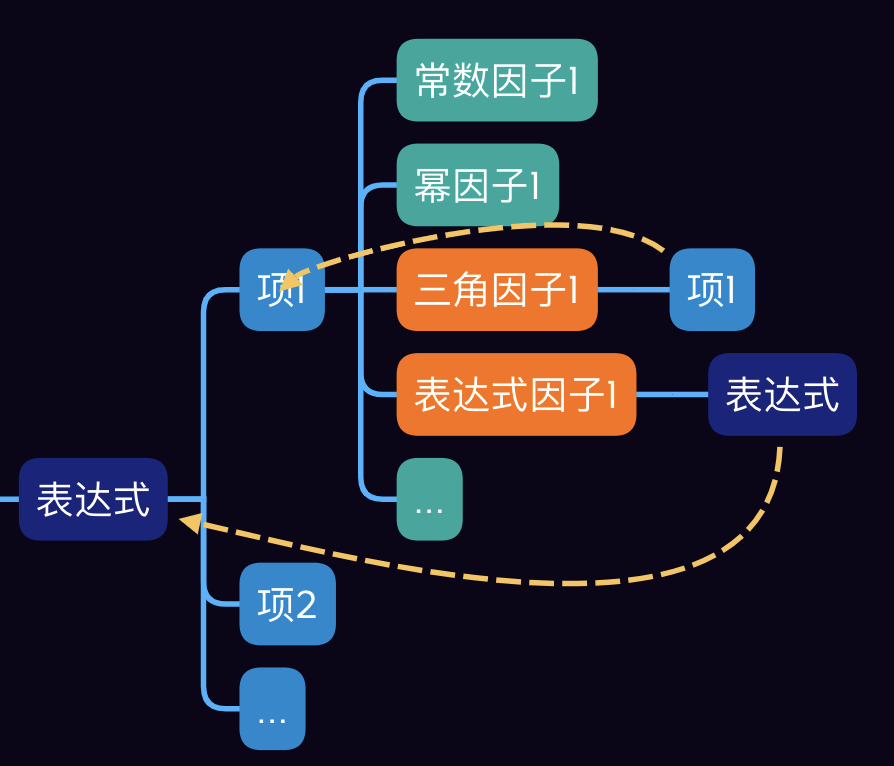
- 深蓝色表示
Expression层 - 浅蓝色表示
Term层 - 浅绿色表示
Factor层 - 橙色表示相比上次作业的新增部分
- 各个类主要方法均为:构造方法、导数产生方法。分别负责解析
String形式的表达式,生成String形式的导数。 Factor层次的类经由FactorFactory生成
Statics

Metrics
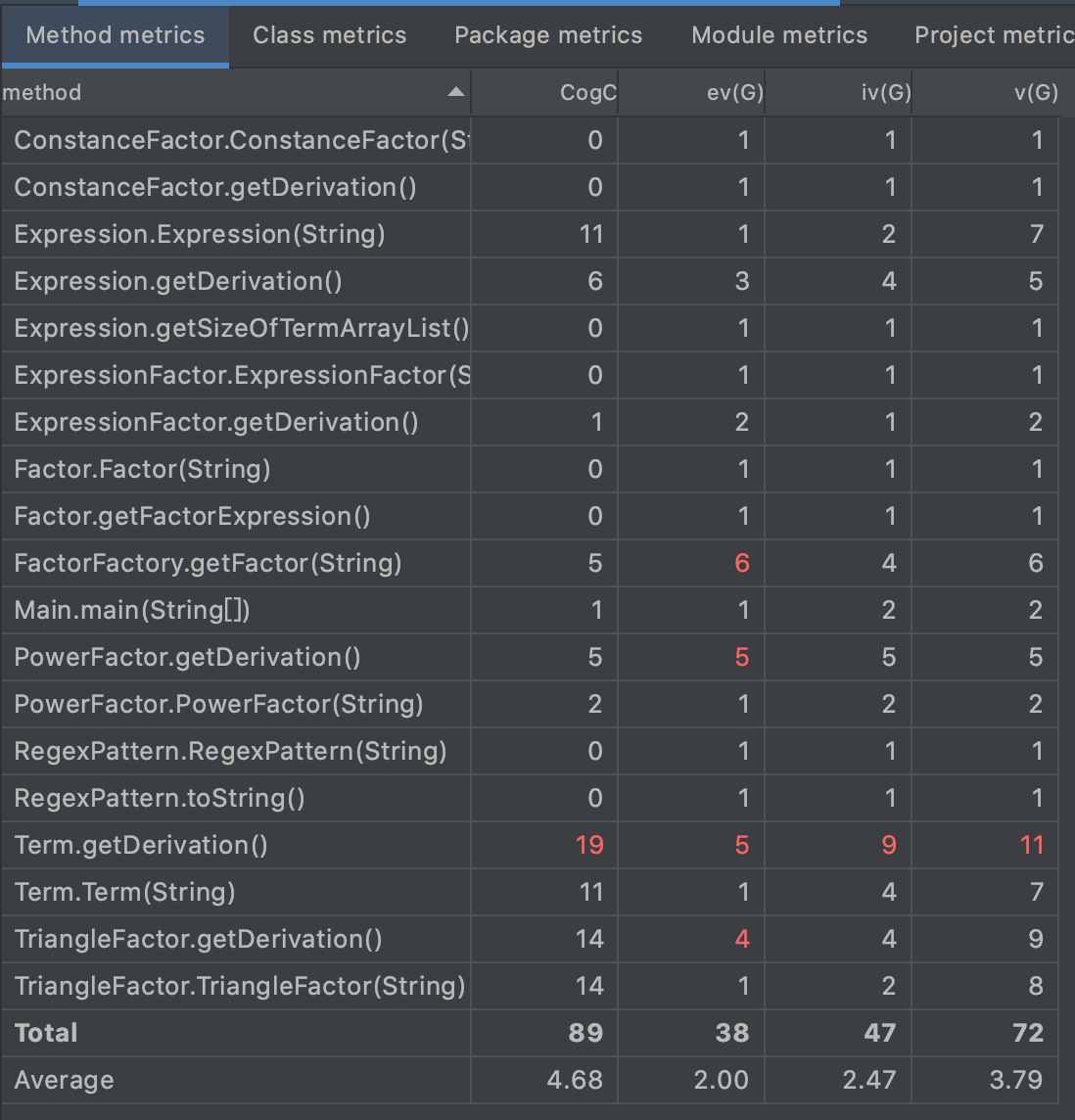
复杂度分析
Factor.getFactor()仅完成了工厂类的核心基本功能,出现的ev(G)略微超额似乎无法降低。PowerFactor.getDerivation()与TriangleFactor.getDerivation()是由于因子输出时顺手做了优化使用了几个if-else,降低的策略应该是分离优化与输出环节,这几次作业但我做的都不太好,设计还需要完善。- 最丑陋的设计是
Ter1m.getDErivation(),输出与优化环节完全耦合,这也是后续限制继续优化性能的一大重要原因。 - 总结来看,这次的复杂度超额部分绝大多数都是由于输出环节和优化环节没有完全分开导致的,反思原因还是思想懒惰不想完全按照面向对象思维设计,一定要认真改正。
Bug
正确性
- 这次的正确性出现了一个bug,是优化括号嵌套情况时,当表达式因子内仅包含1项时,错误地去除了括号。(短短的一行优化代码强测+互测被刀了20个点(悲)。
- 终究是因为懒没有自己写测评机,以为一遍通过中测就是万事大吉,仅仅根据表达式结构构造了几个长样例,覆盖性低,出bug才是理所应当的事(
我现在就去准备第二单元测评机)
时间性能
- 由于没有在循环中保存需要递归调用得出的结果,导致多层括号嵌套时CPU_TIME指数爆炸,超过10层的括号直接无法得出结果。这告诉我们评测时虽然不需要注意时间性能,但使用递归调用时要小心仔细,避免再出现类似情况。
Bug与圈复杂度、代码规模的关系反思
- 圈复杂度和代码行数从两个不同的角度体现了一段代码的设计复杂程度,随着复杂度越高,覆盖测试(不论是自动生成数据还是手动构造用例)的难度将会迅速上升。
- 体现在这次的bug中
Term.getDerivation()由于优化输出与求导完全耦合,导致在静态检查以及结合结构构造用例时,根本无心关注变量保存带来的嵌套括号导致CPU时间指数爆炸的风险。说白了就是复杂的设计会导致在每次测试该段方法时,一定程度的精力会被分散到理解设计结构上,以至于我们的注意力根本无法覆盖所有的细节。因此,对于高圈复杂度、多代码行数的设计方法,出bug是情理之中,不出bug也只能说是幸运,而幸运不可能永远眷顾我们的代码。
第三次作业
思路
这次作业表达式结构与上次无异(预判到了三角因子的可扩展),但WrongFormat则对我的预处理环节们提出了巨大的挑战。抱着绝不重构的心态,仔细思考之后,我沿着第二次按括号分层解析表达式的思路,选择了分层判断是否WF,具体做法如下。
- 预处理环节并不去除空格与合并正负号,首先通过替换最外层括号进行分层。
- 用正则表达式判断最外层的WF。
- 按原思路去除空格、合并正负号、识别项与因子。
表达式项与三角函数项的括号内容分别按照表达式与项分层解析之前,重复1、2步,判断该层的WF。(啰嗦一句,其实表达式因子的并不需要额外判断,因为步骤1是封装在表达式类中的。)- 其余步骤与第二次均相同。
UML
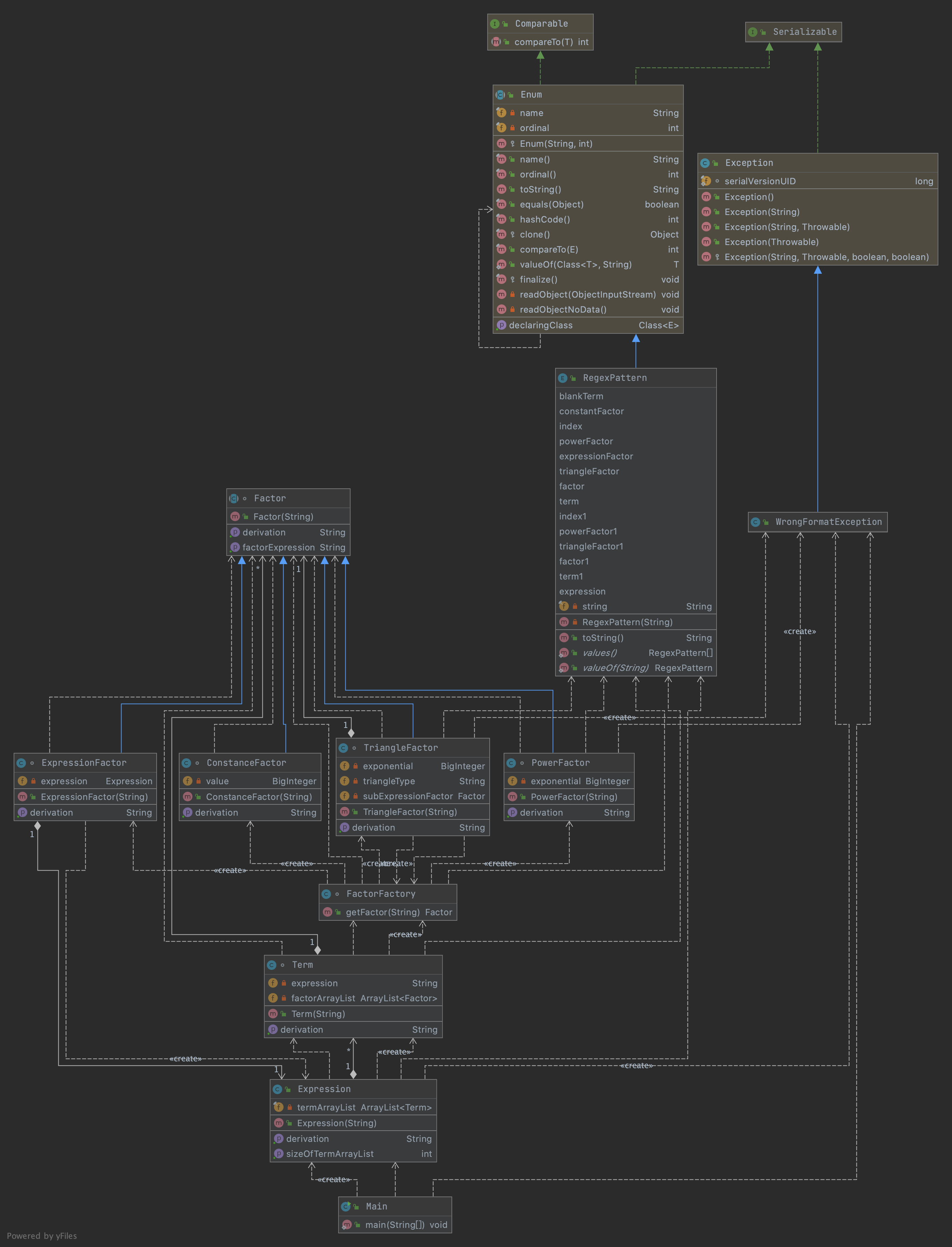
主要类的逻辑关系
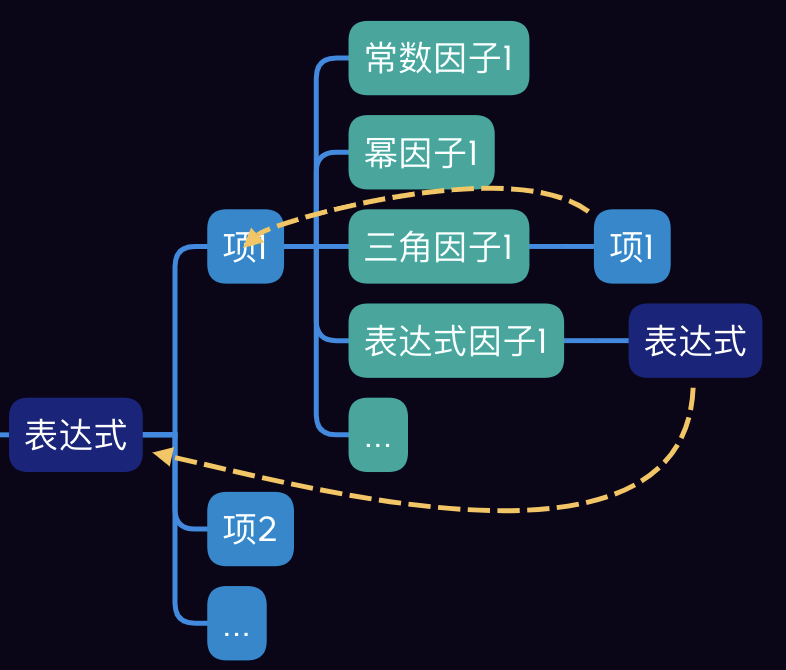
- 深蓝色表示
Expression层 - 浅蓝色表示
Term层 - 浅绿色表示
Factor层 - 各个类主要方法均为:构造方法、导数产生方法。分别负责解析
String形式的表达式,生成String形式的导数。 Factor层次的类经由FactorFactory生成
Statics
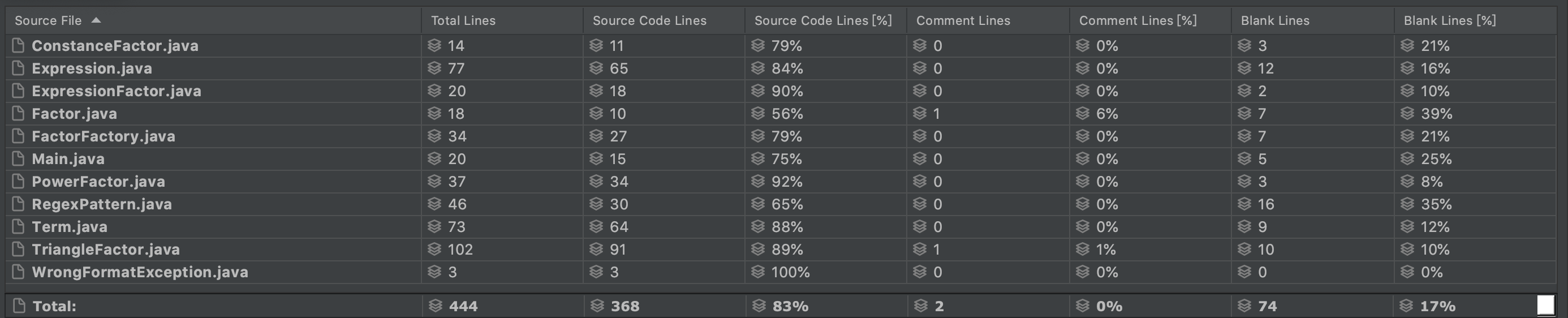
Metrics
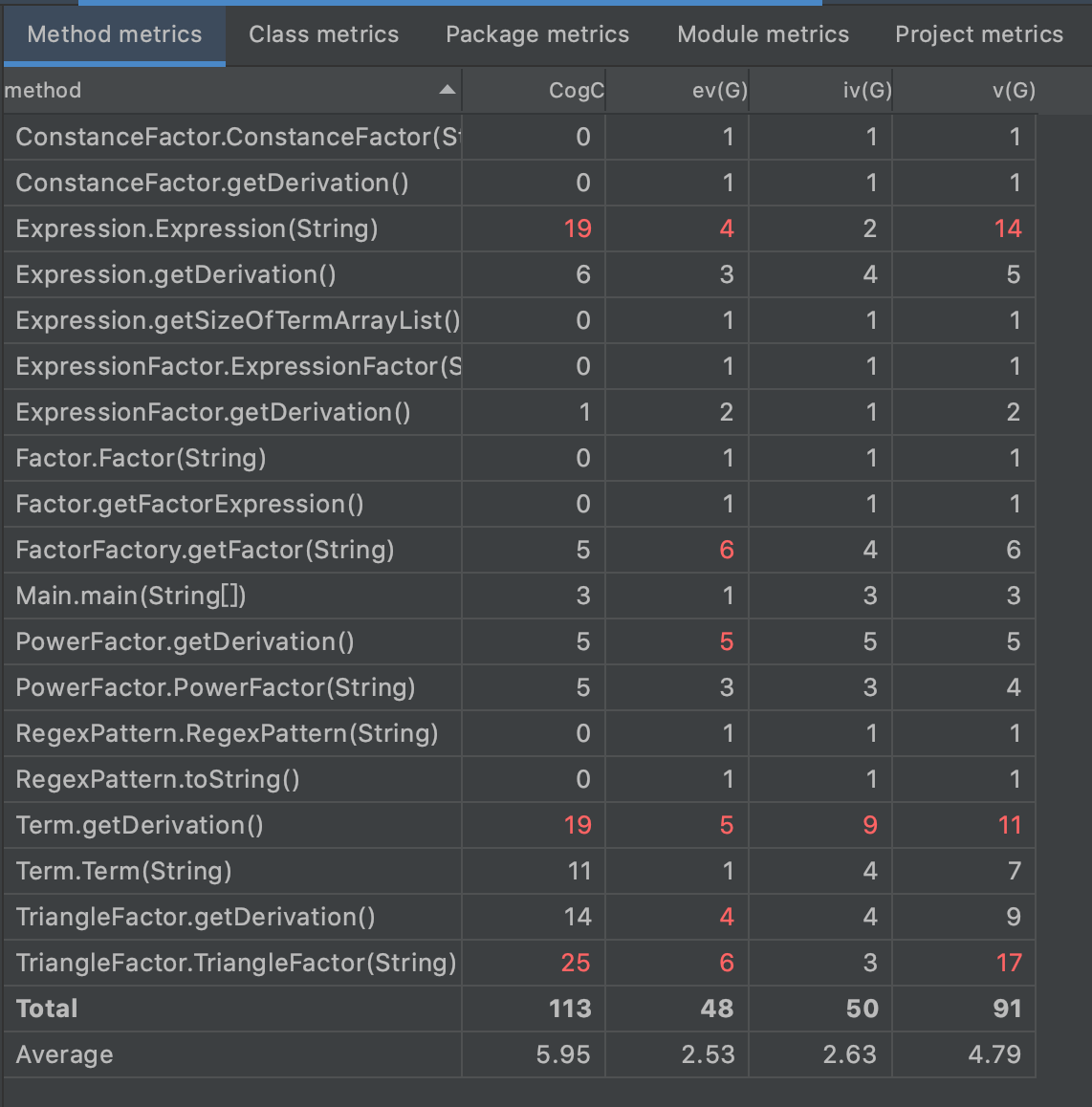
复杂度分析
- 由于几乎全部沿用了第二次的解析、求导、输出与优化功能,复杂度也被很好(丑)地继承了下来。
- 此外,新增WF判断还导致了
表达式和三角函数因子的构造方法复杂度裂开,现在反思来看这其实也是面向对象没有严格落实的下场,正确的做法应该是新建WF判断类完成该功能。
Bug
本次强测、互测均未出现Bug。
关于测试
测试经历
- 第一次作业,由于时间真的很紧张,我只是挑了几个认为可能的边缘数据进行测试,但程序结构简单优化也不复杂,也算是完成了测试任务,互测的时候把这几个数据无脑扔给同房,意料之中的没有刀中任何人。
- 第二次作业,时间相对宽裕,除了想到的边缘数据,我采取了依据题目形式化表达,自底向上按照表达式生成规则,通过排列组合尽可能遍历输入情况,这确实也完成了部分有效测试,de出了一个bug。但也恰恰是这次作业,我出现了一个巨大bug,上面已经说过在此不再赘述此bug具体情况。互测时也是把这些数据无脑上传,意外还是刀中了一两个点(
结合最后强测分C房无遗 - 第三次作业,由于改动仅存在于新增的WrongFormat判定部分,测试用例也仅围绕此部分进行。具体来说主要是穷举空白字符出现的位置,还有注意自己为了处理而进行字符替换的特殊情况如
<与^,就正确性测试效果还不错。互测时不让测WF所以我的大部分数据不能用,所以我就测了几个边缘数据,剩下的只能肉眼读代码找bug了,成效也不是很好。
自动测试
- 我认为想要很好地迭代优化、参与互测,一台自己的测评机是必不可少的。虽然我从第一次作业就开始写测评机,折腾了不少时间,由于python和文件知识的缺少,我那测评机是真的不好用,不好用。不论是正确性分析还是对拍功能,都存在不少的问题,处于时间和精力的考虑,我还是采取了手动构造测试样例的方法进行第一单元三次作业的测试。
手动测试
- 手动构造测试用例,考验的是对题目的理解能力,想到了就是想到了,想不到既写不出来也测不到。因此,除非是在静态阅读代码的过程中对题目有了新的理解,不然思路不改变的情况下,也无法想出自己设计功能外的数据。
- 然而,手动测试还是有很多事情可以做的,例如,通过测试至少要保证每行代码的功能都与设计初衷无误!这三次作业出现的两个正确性bug都是由于我没有做到这点而导致的。换句话说,虽然不能想出设计之外的测试用例,我们至少应该保证设计之内的代码实现无误。
迭代经历
- 由于每次都一定程度考虑到后续的扩展性,也进行了有意识地解耦设计,这三次作业我并没有经历重构。
- 不过,为了追求代码简单,每个版本更新改动最少,我并没有对输出和优化部分做到很好的面向对象。这也是我没有很好的优化的两大主要原因之一(还有一个是测评机没写好)。希望下次作业从最开始就考虑到所有环节的解耦。
体会与反思
- 有一台自己的测评机真的很重要!!!
- 设计的面向对象程度与后续重构的可能性成反比。
- 只有做好上面两点,才能优雅的完成版本迭代,既不用重构也不用担心复杂的改动/优化对正确性的影响。
- 复杂的设计会分散测试时关注细节的注意力,也会极大增加自动生成数据覆盖测试的难度,因此应当极力避免高圈复杂度,过多代码行数的设计出现。
- 优化也不用强求,评分方式决定了完成直观、自然的基本优化就可以拿到绝大部分分数(但基本优化功能完不成就几乎没有性能分
- 难是真的难,学到的东西也是真不少,接下来的作业继续加油吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号