sql 语句
date_add(date1, interval( 取时间间隔) n day)delim:通过该标识符来进行截取的,delim可以为任意字符,不要为空;
count:代表第几次出现;count为正数,代表从左边取标识符出现第count次之前的子串;负数则相反,从右边取标识符出现第count次之后的子串。【'左边’代表‘前’, '右边’代表‘后’】
lead后面括号里的三个参数分别是(字段名称,行数,默认值),字段名称就是,你要从后面的行里取那个字段;行数就是你要取后面的第几行数据,需要注意的是,这个字段是可以省略的,省略就等同于设为1;默认值就是如果到最后一行了,也就是没有下一行了,这个字段填什么,需要注意的是,这个字段是可以省略的,省略就等同于设为null。所以上面那段代码其实就是,取后面第一行的time字段,如果到最后一行了,这个字段就填null。
over后面的括号里是分组语句和排序语句,当然也可以不填或者任选其一。
最后是给这个字段取个别名。
切割、截取、删除、替换
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
select-- 替换法 replace(string, '被替换部分','替换后的结果')-- device_id, replace(blog_url,'http:/url/','') as user_name-- 截取法 substr(string, start_point, length*可选参数*)-- device_id, substr(blog_url,11,length(blog_url)-10) as user_nam-- 删除法 trim('被删除字段' from 列名)-- device_id, trim('http:/url/' from blog_url) as user_name-- 字段切割法 substring_index(string, '切割标志', 位置数(负号:从后面开始))device_id, substring_index(blog_url,'/',-1) as user_namefrom user_submit; |
- 限定条件:2021年8月,写法有很多种,比如用year/month函数的
year(date)=2021 and month(date)=8,比如用date_format函数的date_format(date, "%Y-%m")="202108" - 每天:按天分组
group by date -
day函数 定义:
DAY函数返回指定日期的日的部分
语法:
DAY(date)
-
where year(date)="2021" and month(date)="08"
参数:
①date参数是合法的日期表达式。
返回值:
int型数据 2、substr函数格式 (俗称:字符截取函数) 格式1: substr(string string, int a, int b);
格式2:substr(string string, int a) ;
- INNER JOIN:如果表中有至少一个匹配,则返回行
- LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN:只要其中一个表中存在匹配,则返回行
limit offset: 一起使用时,limit表示要取的数量,offset表示跳过的数量
select device_id from user_profile limit 2 offset 0 // 跳过0条,从第一条数据开始取,取两条数据 ---运行效率中
select device_id as user_infors_example from user_profile limit 0,2;
这里主要是用到了 起别名关键字 as 以及组合限制查询 limit 索引,个数
其中as可以省略,索引为0可以省略
as表头重命名 select count(gender) as male_num
2、计数:count函数
3、保留小数位数:round(列名,位数)
4、求平均数:avg函数
select count(gender) as male_num,round(avg(gpa),1)as avg_gpa from user_profile where gender='male'
完整sql:
select count(male) as male_num, round(avg(gpa),1) as avg_gpa from user_profile where gender='male'
条件查询案列(where)
select device_id,university from user_profile where university='北京大学';
更具需求,首先知道要北京大学的学生,条件查询案列(where)所有用条件university='北京大学'
1.between 在列值得某与某之间
select
device_id,
gender,
age,
university
from user_profile
WHERE
age between 20 and 23
where约束
where字句中可以使用:
- 比较运算符:> >= < <= <> !=
- between 80 and 100——值在80到100之间
- in(80,90,100)——值是80或90或100
- like 'e%' 通配符可以是%或_, %表示任意多字符 _表示一个字符(select device_id,age,university from user_profile where university like '%北京%')
- 逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
两者关系是或,所以用or。
select device_id,gender,age,university,gpa from user_profile where university ="北京大学" or gpa >3.7
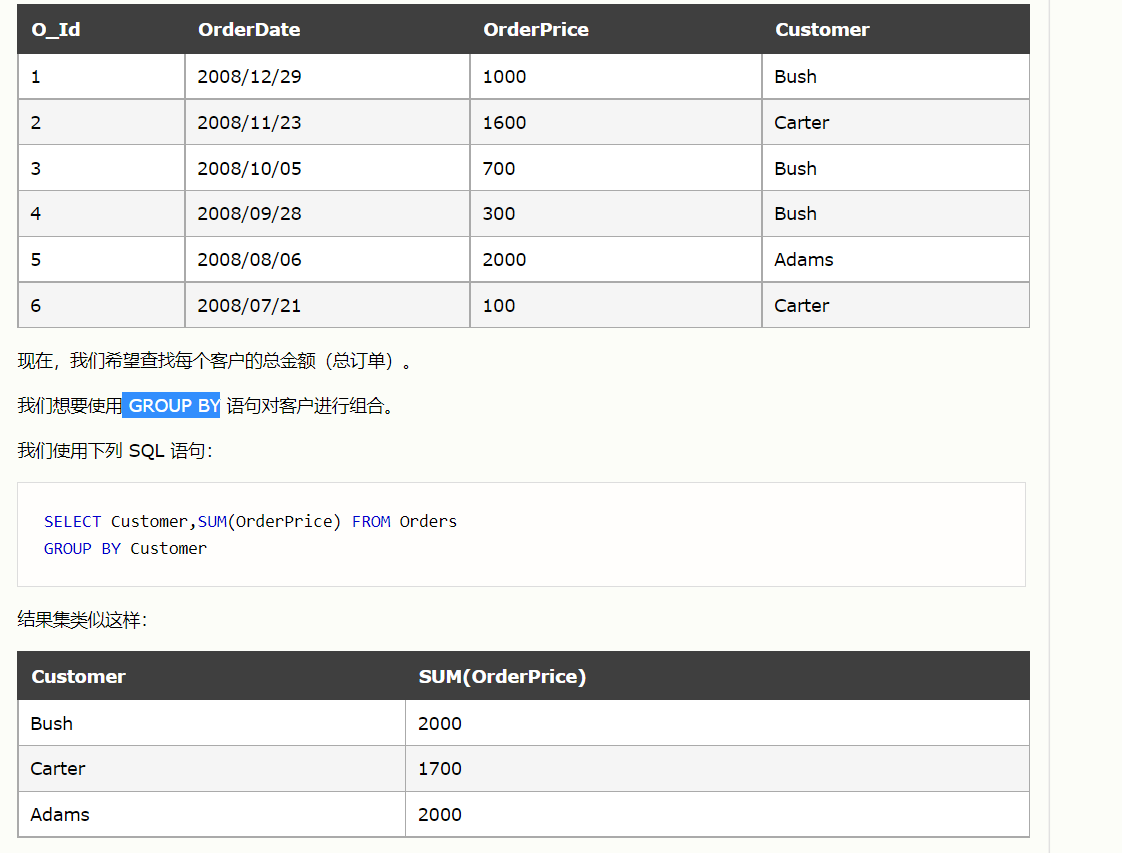
- 字符串的截取:substring(字符串,起始位置,截取字符数)
- 字符串的拼接:concat(字符串1,字符串2,字符串3,...)
- 字母大写:upper(字符串)

having函数

多表查询 - 多表连接
若一个查询同时涉及两个或两个以上的表,则称之为连接查询。
连接查询是关系数据库中最主要的查询。
连接查询包括内连接、外连接和交叉连接等。
连接查询中用于连接两个表的条件称为连接条件或连接谓词。
一般格式为:

内连接
内连接语法如下:
|
1
2
3
4
|
SELECT …FROM 表名[INNER] JOIN 被连接表ON 连接条件 |
例39.查询每个学生及其班级的详细信息。
|
1
2
|
SELECT * FROM 学生表INNER JOIN 班级表 ON 学生表.班号=班级表.班号 |
结果中有重复的列:班号。
例40.去掉例39中的重复列。
|
1
2
|
SELECT 学号, 姓名,班级表.班号, 班名 FROM 学生表 JOIN 班级表ON 学生表.班号=班级表.班号 |
例41.查询重修学生的修课情况,要求列出学生的名字、所修课的课程号和成绩。
|
1
2
3
4
|
SELECT 姓名, 课程号, 成绩FROM 学生表 JOIN 成绩表ON 学生表.学号 = 成绩表.学号WHERE 状态 = '重修' |
执行连接操作的过程
首先取表1中的第1个元组,然后从头开始扫描表2,逐一查找满足连接条件的元组,
找到后就将表1中的第1个元组与该元组拼接起来,形成结果表中的一个元组。 表2全部查找完毕后,再取表1中的第2个元组,然后再从头开始扫描表2, …
重复这个过程,直到表1中的全部元组都处理完毕为止。
表别名
可以为表提供别名,其格式如下:
<源表名> [ AS ] <表别名>
使用别名时例41可写为如下形式:
|
1
2
3
4
|
SELECT 姓名, 课程号, 成绩FROM 学生表 S JOIN 成绩表 gON S.学号 = g.学号WHERE 状态 = ‘重修’ |
注:如果为表指定了别名,则查询语句中其他所有用到表名的地方都要使用别名
例42.查询所有学生的姓名、班名和系名。
|
1
2
3
4
|
SELECT 姓名,班名,系名FROM 学生表 s JOIN 班级表 bjbON s.班号 = bjb.班号JOIN 系表 xb ON bjb.系号 = xb.系号 |
例43.查询软件工程系所有学生的情况,要求列出学生姓名和所在的系。
|
1
2
3
4
5
|
SELECT 姓名, 系名FROM 学生表 s JOIN 班级表 bjbON s.班号 = bjb.班号JOIN 系表 xb ON bjb.系号 = xb.系号WHERE 系名= '软件工程系 |
例44.有分组的多表连接查询。查询每个班的学生的考试平均成绩。
|
1
2
3
4
5
|
SELECT 班号,AVG(成绩) AS 班平均FROM 学生表 S JOIN 成绩表 gON S.学号 = g.学号GROUP BY 班号 |
例45.有分组和行过滤的多表连接查询。查询21226P班每门课程的选课人数、平均成绩、最高成绩和最低成绩。
|
1
2
3
4
5
6
7
8
|
SELECT 课程号, COUNT(*) AS Total,AVG(成绩) AS Avg成绩,MAX(成绩) AS Max成绩,MIN(成绩) AS Min成绩FROM 学生表 S JOIN 成绩表 gON S.学号 = g.学号WHERE 班号 = '21226P'GROUP BY 课程号 |
CASE函数
是一种多分支的函数,可以根据条件列表的值返回多个可能的结果表达式中的一个。
可用在任何允许使用表达式的地方,但不能单独作为一个语句执行。
分为:
简单CASE函数
搜索CASE函数
简单 CASE函数
|
1
2
3
4
5
6
|
CASE 测试表达式WHEN 简单表达式1 THEN 结果表达式1WHEN 简单表达式2 THEN 结果表达式2 …WHEN 简单表达式n THEN 结果表达式n[ ELSE 结果表达式n+1 ]END |
计算测试表达式,按从上到下的书写顺序将测试表达式的值与每个WHEN子句的简单表达式进行比较。
如果某个简单表达式的值与测试表达式的值相等,则返回第一个与之匹配的WHEN子句所对应的结果表达式的值。
如果所有简单表达式的值与测试表达式的值都不相等,
若指定了ELSE子句,则返回ELSE子句中指定的结果表达式的值;
若没有指定ELSE子句,则返回NULL。
例48. 查询班级表中的学生的班号、班名、系号和班主任号,并对系号作如下处理:
当系号为1时,显示 “计算机系”;
当系号为2时,显示 “软件工程系”;
当系号为3时,显示 “物联网系”。
|
1
2
3
4
5
6
7
|
SELECT 班号 ,班名,CASE 系号WHEN 1 THEN '软件工程系'WHEN 2 THEN '计算机系'WHEN 3 THEN '物联网系'END AS 系号,班主任号FROM 班级表 |
搜索CASE函数
|
1
2
3
4
5
6
|
CASEWHEN 布尔表达式1 THEN 结果表达式1WHEN 布尔表达式2 THEN 结果表达式2 …WHEN 布尔表达式n THEN 结果表达式n[ ELSE 结果表达式n+1 ]END |
按从上到下的书写顺序计算每个WHEN子句的布尔表达式。
返回第一个取值为TRUE的布尔表达式所对应的结果表达式的值。
如果没有取值为TRUE的布尔表达式,
则当指定了ELSE子句时,返回ELSE子句中指定的结果;
如果没有指定ELSE子句,则返回NULL。
例48用搜索CASE来做:
|
1
2
3
4
5
6
7
|
SELECT 班号 ,班名,CASEWHEN 系号=1 THEN '软件工程系'WHEN 系号=2 THEN '计算机系'WHEN 系号=3 THEN '物联网系'END AS 系号,班主任号FROM 班级表 |
例49.查询“M01F011”号课程的考试情况,列出学号、课程号和成绩,同时将百分制成绩显示为等级。
|
1
2
3
4
5
6
7
8
9
10
|
SELECT 学号,课程号,CASEWHEN 成绩 >= 90 THEN '优'WHEN 成绩 BETWEEN 80 AND 89 THEN '良'WHEN 成绩 BETWEEN 70 AND 79 THEN '中'WHEN 成绩 BETWEEN 60 AND 69 THEN '及格'WHEN 成绩 <60 THEN '不及格'END 成绩FROM 成绩表WHERE 课程号 = 'M01F011' |
CASE函数(续)
例50.统计每个班男生和女生的数量各是多少,统计结果的表头为,班号,男生数量,女生数量。
|
1
2
3
4
|
SELECT 班号,COUNT(CASE WHEN 性别=‘男’ THEN ‘男’ END) 男生数,COUNT(CASE WHEN 性别=‘女’ THEN ‘女’ END) 女生数FROM 学生表 GROUP BY 班号 |
例51.判断成绩的等级,85-100为“优”,70-84为“良”,60-69为“及格”,60以下为“不及格”,并统计每一等级的人数。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
SELECTCASEWHEN GRADE BETWEEN 85 AND 100 THEN '优'WHEN GRADE BETWEEN 70 AND 84 THEN '良'WHEN GRADE BETWEEN 60 AND 69 THEN '及格'ELSE '不及格'END 等级, COUNT(*) 人数FROM SCGROUP BYCASEWHEN GRADE BETWEEN 85 AND 100 THEN '优'WHEN GRADE BETWEEN 70 AND 84 THEN '良'WHEN GRADE BETWEEN 60 AND 69 THEN '及格'ELSE '不及格'END |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号