Django REST Framework教程(4): 玩转序列化器(Serializer)
Django REST Framework教程(4): 玩转序列化器(Serializer)
在前面的文章中我们以博客为例,自定义了一个简单的 ArticleSerializer 类, 并分别以函数视图(FBV)和基于类的视图(CBV)编写了博客文章列表资源和单篇文章资源的API,支持客户端以各种请求方式对文章资源进行增删查改。在本文中,我们将玩转DRF的序列化器,教你如何修改序列化器控制序列化后响应数据的输出格式, 如何在反序列化时对客户端提供过来的数据进行验证(validation)以及如何重写序列化器类自带的的create和update方法。

如果你还没阅读过前面的文章,推荐先阅读。即使你不阅读之前文章,你也会从本文中获得一些启发。
准备工作
我们的Article模型和自定义的序列化器ArticleSerializer类分别如下所示。
# blog/models.py
class Article(models.Model):"""Article Model"""STATUS_CHOICES = (('p', 'Published'),('d', 'Draft'),)title = models.CharField(verbose_name='Title (*)', max_length=90, db_index=True)body = models.TextField(verbose_name='Body', blank=True)author = models.ForeignKey(User, verbose_name='Author', on_delete=models.CASCADE, related_name='articles')status = models.CharField(verbose_name='Status (*)', max_length=1, choices=STATUS_CHOICES, default='s', null=True, blank=True)create_date = models.DateTimeField(verbose_name='Create Date', auto_now_add=True)def __str__(self):return self.title
# blog/serializers.py
class ArticleSerializer(serializers.ModelSerializer):class Meta:model = Articlefields = '__all__'read_only_fields = ('id', 'author', 'create_date')
我们自定义的序列化器ArticleSerializer类包括了Article模型的所有字段,但由于我们不希望用户自行修改id, author和create_date三个字段,我们把它们设成了仅可读read_only_fields。如果你的其它代码正确,当你发送GET请求到/v1/articles, 我们可以看HTTP=200 OK的字样和如下json格式的文章列表数据。
[GET] http://127.0.0.1:8000/v1/articles
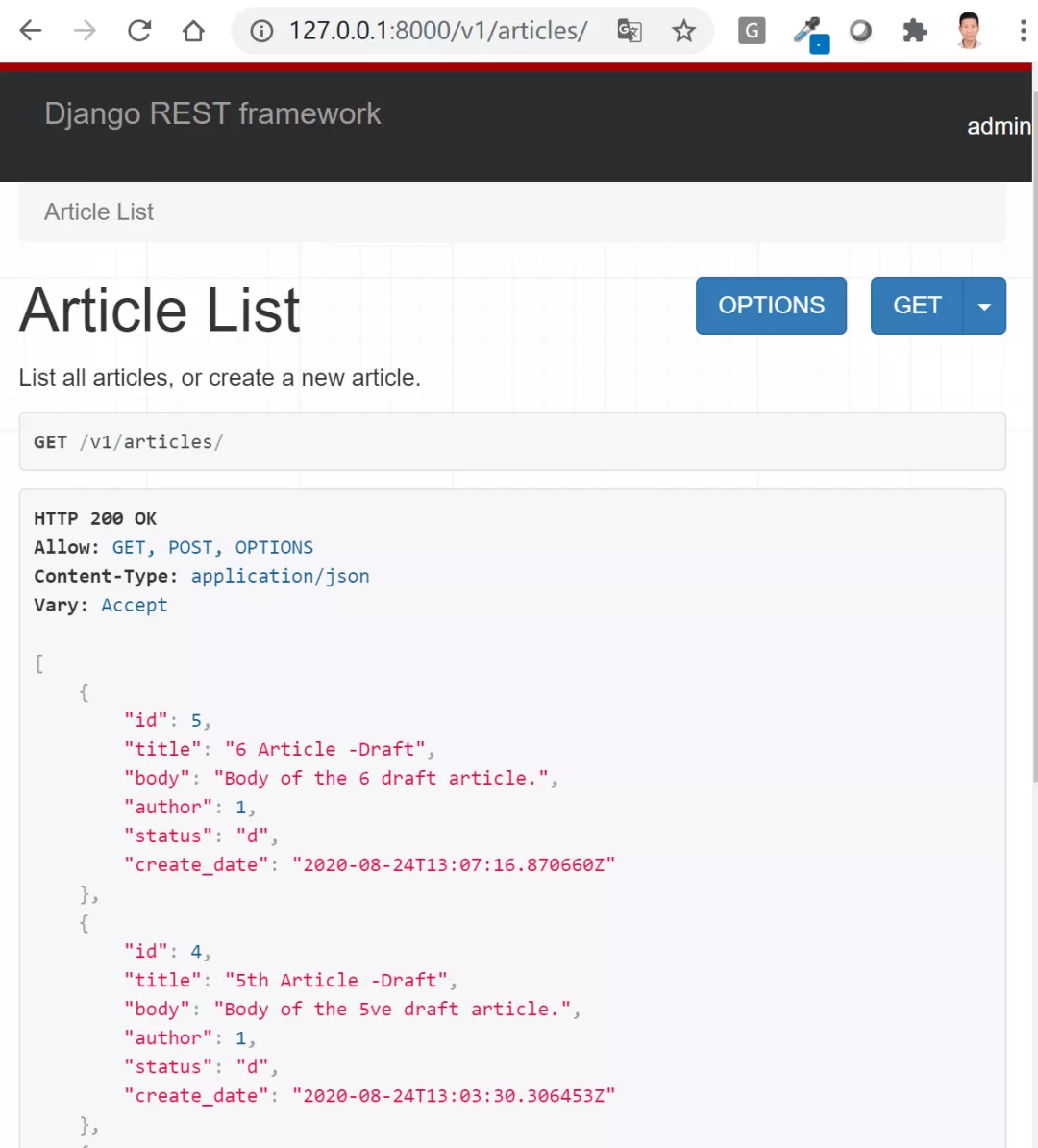
在这里你可以看到序列化后输出的json格式数据里author字段输出的是用户id,而不是用户名,status输出的是p或者d,而不是输出Published或Draft这样的完整状态,这显然对用户不是很友好的。这时我们就要修改序列化器,控制序列化后的数据输出格式,这里我们将介绍几种常用的方式。
方式1 - 指定source来源
打开blog/serializers.py,新建两个可读字段author和status字段,用以覆盖原来Article模型默认的字段,其中指定author字段的来源(source)为原单个author对象的username,status字段为get_status_display方法返回的完整状态。
class ArticleSerializer(serializers.ModelSerializer):author = serializers.ReadOnlyField(source="author.username")status = serializers.ReadOnlyField(source="get_status_display")class Meta:model = Articlefields = '__all__'read_only_fields = ('id', 'author', 'create_date')
这时你应该可以看到想要的输出数据格式了,是不是很赞?

这个看似完美,但里面其实有个错误。我们定义了一个仅可读的status字段把原来的status字段覆盖了,这样反序列化时用户将不能再对文章发表状态进行修改(原来的status字段是可读可修改的)。一个更好的方式在ArticleSerializer新增一个为full_status的可读字段,而不是简单覆盖原本可读可写的字段。
class ArticleSerializer(serializers.ModelSerializer):author = serializers.ReadOnlyField(source="author.username")full_status = serializers.ReadOnlyField(source="get_status_display")class Meta:model = Articlefields = '__all__'read_only_fields = ('id', 'author', 'create_date')
方式2 - 使用SerializerMethodField自定义方法
上面例子中文章状态status都是以Published或Draft英文字符串表示的,但是如果你想在输出的json格式数据中新增cn_status字段,显示中文发表状态。但cn_status本身并不是Article模型中存在的字段,这时你应该怎么做呢?答案是使用SerializerMethodField,它可用于将任何类型的数据添加到对象的序列化表示中, 非常有用。
再次打开blog/serializers.py,新建cn_status字段,格式为SerializerMethodField,然后再自定义一个get_cn_status方法输出文章中文发表状态即可。
class ArticleSerializer(serializers.ModelSerializer):author = serializers.ReadOnlyField(source="author.username")status = serializers.ReadOnlyField(source="get_status_display")cn_status = serializers.SerializerMethodField()class Meta:model = Articlefields = '__all__'read_only_fields = ('id', 'author', 'create_date')def get_cn_status(self, obj):if obj.status == 'p':return "已发表"elif obj.status == 'd':return "草稿"else:return ''
这时的输出数据是不是让人赏心悦目?
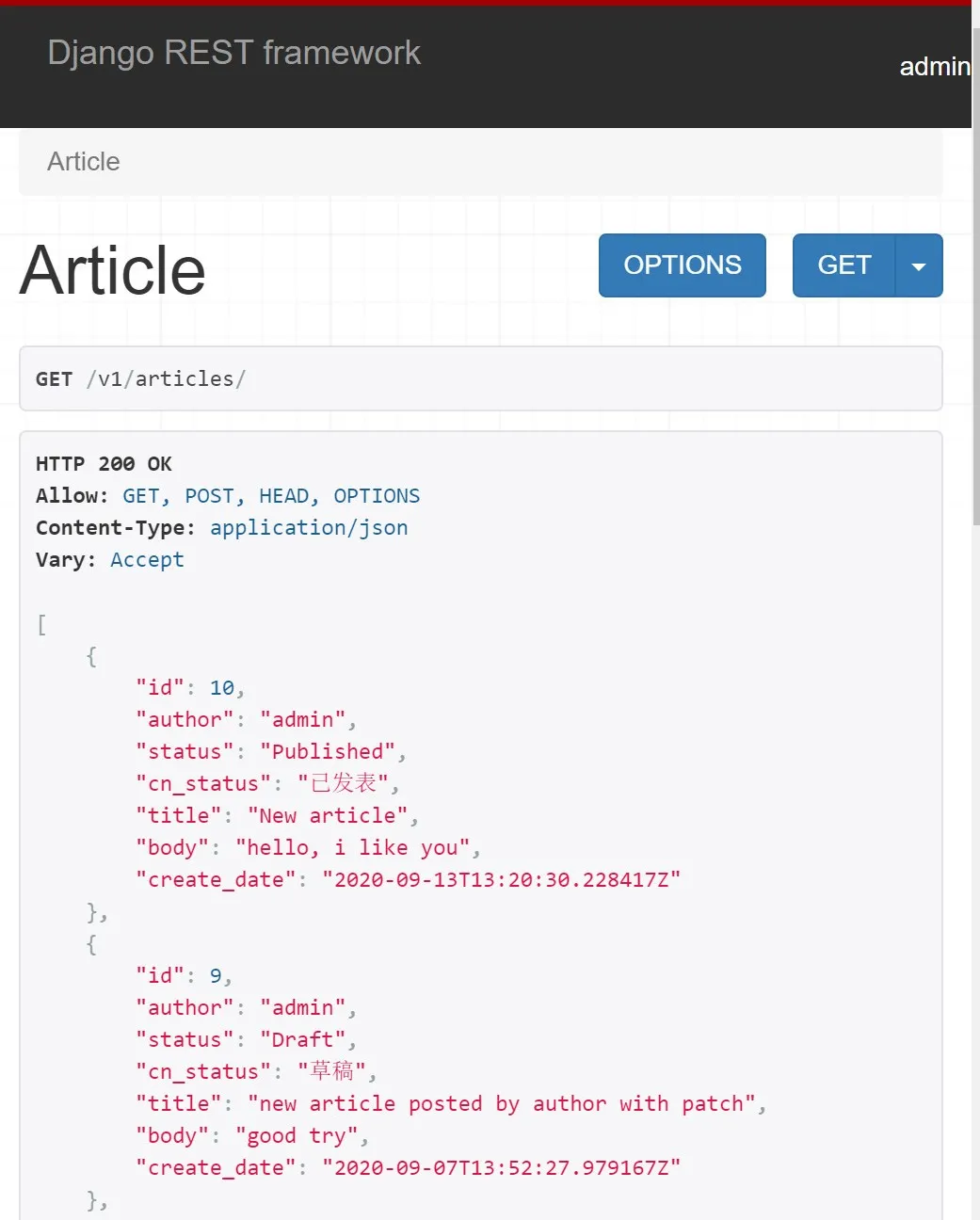
不过需要注意的是SerializerMethodField通常用于显示模型中原本不存在的字段,类似可读字段,你不能通过反序列化对其直接进行修改。
方式3 - 使用嵌套序列化器
我们文章中的author字段实际上对应的是一个User模型实例化后的对象,既不是一个整数id,也不是用户名这样一个简单字符串,我们怎样显示更多用户对象信息呢? 其中一种解决方法是使用嵌套序列化器,如下所示:
class UserSerializer(serializers.ModelSerializer):class Meta:model = Userfields = ('id', 'username', 'email')class ArticleSerializer(serializers.ModelSerializer):author = UserSerializer() # 设置required=False表示可以接受匿名用户status = serializers.ReadOnlyField(source="get_status_display")cn_status = serializers.SerializerMethodField()class Meta:model = Articlefields = '__all__'read_only_fields = ('id', 'author', 'create_date')def get_cn_status(self, obj):if obj.status == 'p':return "已发表"elif obj.status == 'd':return "草稿"else:return ''
展示效果如下所示:
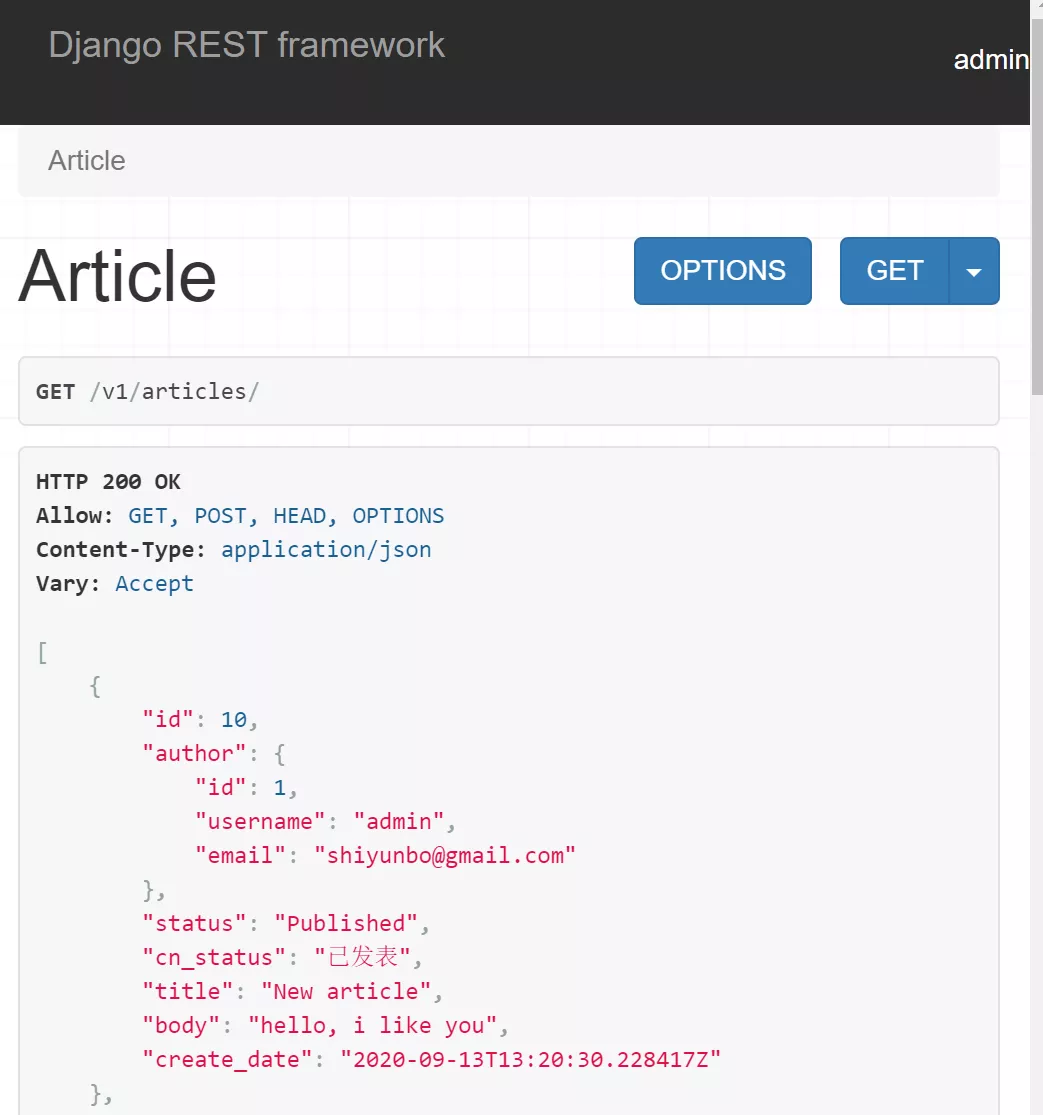
此时发送GET请求展示文章列表资源是没问题的,但如果你希望发送POST请求到v1/articles/提交新文章你将会收到author字段是required的这样一个错误。为了使我们代码正确工作,我们还需要手动指定read_only=True这个选项。尽管我们在Meta选项已经指定了author为read_only_fields, 但使用嵌套序列化器时还需要重新指定一遍。
author = UserSerializer(read_only=True)另一个解决方式是不使用嵌套序列化器,通过设置关联模型的深度depth(通常1-4)实现, 如下所示:
class ArticleSerializer(serializers.ModelSerializer):# author = UserSerializer(read_only=True)status = serializers.ReadOnlyField(source="get_status_display")cn_status = serializers.SerializerMethodField()class Meta:model = Articlefields = '__all__'read_only_fields = ('id', 'author', 'create_date')depth = 1def get_cn_status(self, obj):if obj.status == 'p':return "已发表"elif obj.status == 'd':return "草稿"else:return ''
展示效果如下。这种方法虽然简便,但使用时要非常小心,因为它会展示关联模型中的所有字段。比如下例中连密码password都展示出来了,显然不是我们想要的。

前面我们介绍的都是如何通过修改序列化器来控制输出数据的展现形式,下面我们将着重看下如何在反序列化时对客户端提供过来的数据进行验证(validation)以及如何重写序列化类自带的的save和update方法。由于官方文档中有更好的例子,我们将会使用这些案例。
数据验证 (Validation)
在反序列化数据时,在尝试访问经过验证的数据或保存对象实例之前,总是需要调用 is_valid()方法。如果发生任何验证错误,.errors 属性将包含表示结果错误消息的字典,如下所示:
serializer = CommentSerializer(data={'email': 'foobar', 'content': 'baz'})serializer.is_valid()# Falseserializer.errors# {'email': [u'Enter a valid e-mail address.'], 'created': [u'This field is required.']}
字典中的每个键都是字段名称,值是与该字段对应的任何错误消息的字符串列表。non_field_errors 键也可能存在,并将列出任何常规验证错误。可以使用 REST framework 设置中的 NON_FIELD_ERRORS_KEY 来自定义 non_field_errors 键的名称。
当反序列化项目列表时,错误将作为表示每个反序列化项目的字典列表返回。
引发无效数据的异常 (Raising an exception on invalid data)
.is_valid() 方法使用可选的 raise_exception 标志,如果存在验证错误,将会抛出 serializers.ValidationError 异常。
这些异常由 REST framework 提供的默认异常处理程序自动处理,默认情况下将返回 HTTP 400 Bad Request 响应。
# Return a 400 response if the data was invalid.
serializer.is_valid(raise_exception=True)
字段级别验证 (Field-level validation)
您可以通过向您的 Serializer 子类中添加 .validate_<field_name> 方法来指定自定义字段级的验证。这些类似于 Django 表单中的 .clean_<field_name> 方法。这些方法采用单个参数,即需要验证的字段值。
您的 validate_<field_name> 方法应该返回已验证的值或抛出 serializers.ValidationError 异常。例如:
from rest_framework import serializersclass ArticleSerializer(serializers.Serializer):title = serializers.CharField(max_length=100)def validate_title(self, value):"""Check that the article is about Django."""if 'django' not in value.lower():raise serializers.ValidationError("Article is not about Django")return value
注意:如果在您的序列化器上声明了 <field_name> 的参数为 required=False,那么如果不包含该字段,则此验证步骤不会发生。
对象级别验证 (Object-level validation)
要执行需要访问多个字段的任何其他验证,请添加名为 .validate() 的方法到您的 Serializer 子类中。此方法采用单个参数,该参数是字段值的字典。如果需要,它应该抛出 ValidationError 异常,或者只返回经过验证的值。例如:
from rest_framework import serializersclass EventSerializer(serializers.Serializer):description = serializers.CharField(max_length=100)start = serializers.DateTimeField()finish = serializers.DateTimeField()def validate(self, data):"""Check that the start is before the stop."""if data['start'] > data['finish']:raise serializers.ValidationError("finish must occur after start")return data
验证器 (Validators)
序列化器上的各个字段都可以包含验证器,通过在字段实例上声明,例如:
def multiple_of_ten(value):if value % 10 != 0:raise serializers.ValidationError('Not a multiple of ten')class GameRecord(serializers.Serializer):score = IntegerField(validators=[multiple_of_ten])...
DRF还提供了很多可重用的验证器,比如UniqueValidator,UniqueTogetherValidator等等。通过在内部 Meta 类上声明来包含这些验证器,如下所示。下例中会议房间号和日期的组合必须要是独一无二的。
class EventSerializer(serializers.Serializer):name = serializers.CharField()room_number = serializers.IntegerField(choices=[101, 102, 103, 201])date = serializers.DateField()class Meta:# Each room only has one event per day.validators = UniqueTogetherValidator(queryset=Event.objects.all(),fields=['room_number', 'date'])
重写序列化器的create和update方法
假设我们有个Profile模型与User模型是一对一的关系,当用户注册时我们希望把用户提交的数据分别存入User和Profile模型,这时我们就不得不重写序列化器自带的create方法了。下例演示了如何通过一个序列化器创建两个模型对象。
class UserSerializer(serializers.ModelSerializer):profile = ProfileSerializer()class Meta:model = Userfields = ('username', 'email', 'profile')def create(self, validated_data):profile_data = validated_data.pop('profile')user = User.objects.create(**validated_data)Profile.objects.create(user=user, **profile_data)return user
同时更新两个关联模型实例时也同样需要重写update方法。
def update(self, instance, validated_data):profile_data = validated_data.pop('profile')profile = instance.profileinstance.username = validated_data.get('username', instance.username)instance.email = validated_data.get('email', instance.email)instance.save()profile.is_premium_member = profile_data.get('is_premium_member',profile.is_premium_member)profile.has_support_contract = profile_data.get('has_support_contract',profile.has_support_contract)profile.save()return instance
因为序列化器使用嵌套后,创建和更新的行为可能不明确,并且可能需要相关模型之间的复杂依赖关系,REST framework 3 要求你始终显式的编写这些方法。默认的 ModelSerializer .create() 和 .update() 方法不包括对可写嵌套表示的支持,所以我们总是需要对create和update方法进行重写。
小结
-
改变序列化输出数据的格式可以通过指定字段的source来源,使用SerializerMethodField自定义方法以及使用嵌套序列化器。
-
反序列化时需要对客户端发送的数据进行验证。你可以通过自定义validate方法进行字段或对象级别的验证,你还可以使用自定义的validators或DRF自带的验证器。
-
当你使用嵌套序列化器后,多个关联模型同时的创建和更新的行为并不明确,你需要显示地重写create和update方法。
下篇我们将重点介绍Django REST Framework教程(5):认证 (Authentication),欢迎关注我们的微信公众号【Python Web与Django开发】。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号