
数据采集与融合技术第四次作业
数据采集与融合技术第四次作业
作业①:东方财富网股票数据采集(Selenium + MySQL)
1. 作业要求
-
掌握内容:
- 使用 Selenium 查找 HTML 元素
- 爬取 Ajax 动态网页数据
- 等待 HTML 元素加载等相关操作
-
技术路线:
- 使用 Selenium 框架 + MySQL 数据库存储
- 爬取东方财富网的 “沪深 A 股”、“上证 A 股”、“深证 A 股” 3 个板块的股票数据信息
-
候选网站:
- 东方财富网股票列表:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
- 东方财富网股票列表:
-
输出要求:
- 将数据存入 MySQL 数据库
- 表头使用英文命名,例如:
- 序号:
seq_no - 股票代码:
stock_no - 股票名称:
stock_name - 等等
- 序号:
本次实现中,我在数据库
stock_spider中设计了stocks表,字段包括:
board, seq_no, stock_no, stock_name, last_price, change_pct, change_amt, volume, amount, amplitude, high_price, low_price, open_price, pre_close
其中board用来标记当前记录属于哪个板块(hs_a/sh_a/sz_a)。
2. 爬取网站与总体思路
-
爬取网站:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board -
主要思路:
- 使用 Selenium 打开对应板块页面;
- 定位到股票数据所在的表格
<table>; - 遍历表格的每一行
<tr>,读取单元格<td>内容; - 将字段整理后写入 MySQL 的
stocks表; - 依次对“沪深 A 股”“上证 A 股”“深证 A 股”三大板块重复上述过程。
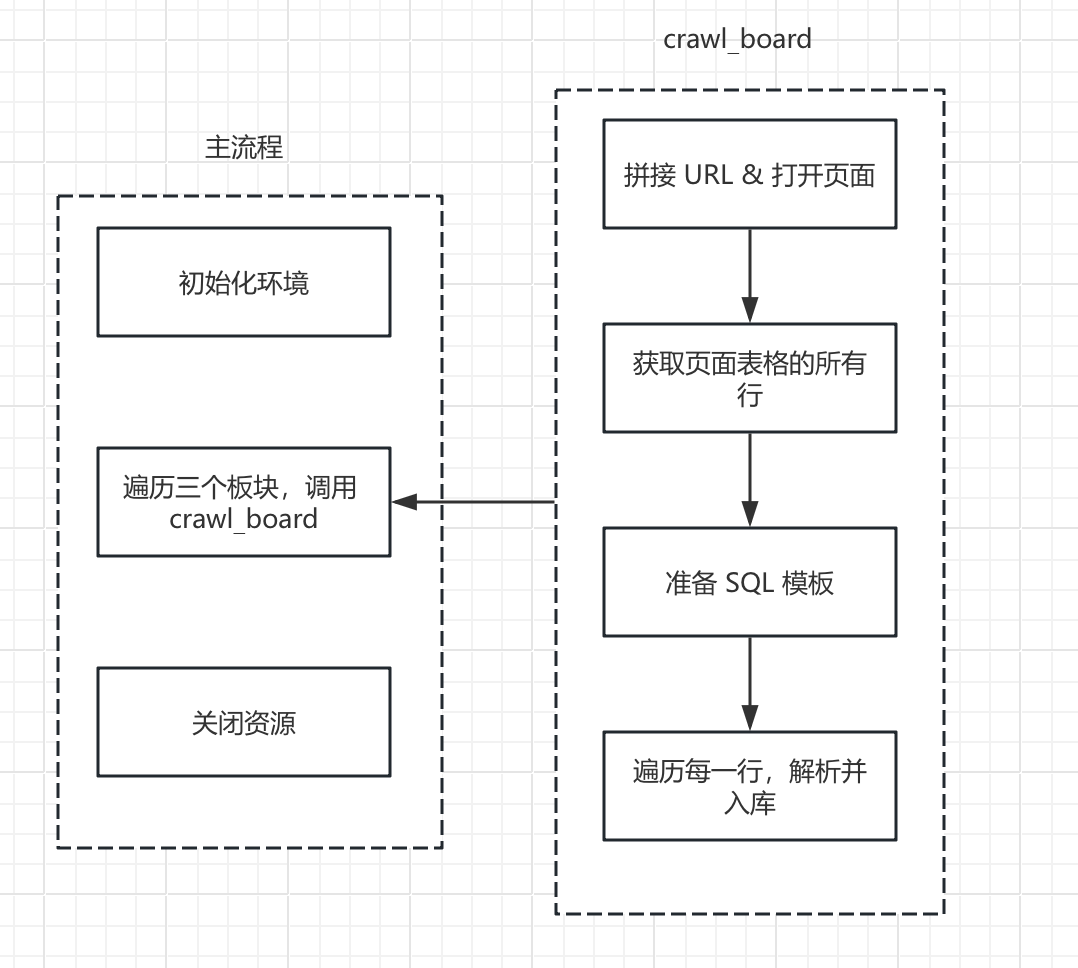
3. Step1:环境初始化(连接数据库 + 启动浏览器)
首先导入所需库,连接 MySQL,并启动 Chrome 浏览器,准备好东方财富的基础 URL:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import pymysql
# 连接 MySQL
conn = pymysql.connect(
host="127.0.0.1",
user="root",
password="Lm123456",
database="stock_spider",
charset="utf8mb4"
)
cursor = conn.cursor()
# 启动 Selenium 浏览器
driver = webdriver.Chrome()
# 东方财富股票列表基础 URL
BASE_URL = "http://quote.eastmoney.com/center/gridlist.html#"
4. Step2:分析网页结构并实现数据采集
在浏览器中打开东方财富的股票列表页面,可以看到每只股票是一行数据,每一列对应一个 <td> 单元格:
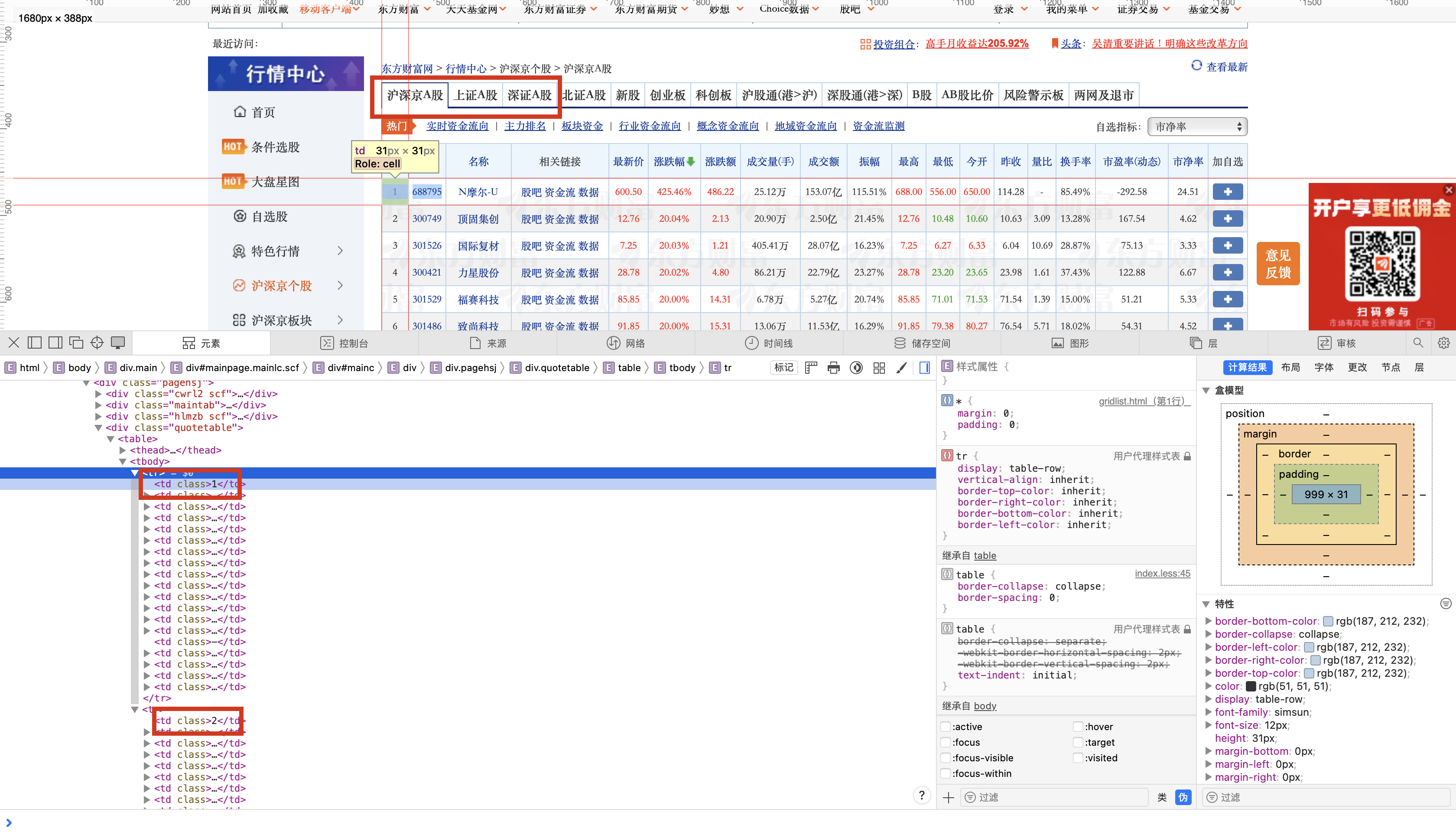
从结构上可以看出:
- 每只股票对应表格中的一行
<tr>; - 每个字段(如股票代码、名称、最新价等)都位于当前行的不同
<td>中。
因此,爬取数据时可以按如下步骤实现:
- 使用
driver.find_elements(By.CSS_SELECTOR, "table tbody tr")找到所有行; - 对每一行,用
row.find_elements(By.TAG_NAME, "td")获取所有单元格; - 按列索引依次提取“序号、股票代码、股票名称、最新价、涨跌幅、涨跌额、成交量、成交额、振幅、最高、最低、今开、昨收”等字段;
- 将这些字段封装为一条记录,并插入到 MySQL 的
stocks表中。
下面是核心爬取逻辑(crawl_board 函数片段):
def crawl_board(hash_code, board_code):
# 1) 拼接 URL,打开对应板块页面
url = BASE_URL + hash_code
driver.get(url)
# 2) 简单等待页面和数据加载完成(详见 Step3)
time.sleep(5)
# 3) 找到表格的所有行
rows = driver.find_elements(By.CSS_SELECTOR, "table tbody tr")
print("共发现行数:", len(rows))
sql = """
INSERT INTO stocks
(board, seq_no, stock_no, stock_name,
last_price, change_pct, change_amt,
volume, amount, amplitude,
high_price, low_price, open_price, pre_close)
VALUES
(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
for row in rows:
tds = row.find_elements(By.TAG_NAME, "td")
if len(tds) < 13:
# 防止空行或异常行,列数不足时直接跳过
continue
# 按网页表头顺序取值:
seq_no = tds[0].text.strip() # 序号
stock_no = tds[1].text.strip() # 股票代码
stock_name = tds[2].text.strip() # 股票名称
last_price = tds[3].text.strip() # 最新报价
change_pct = tds[4].text.strip() # 涨跌幅
change_amt = tds[5].text.strip() # 涨跌额
volume = tds[6].text.strip() # 成交量
amount = tds[7].text.strip() # 成交额
amplitude = tds[8].text.strip() # 振幅
high_price = tds[9].text.strip() # 最高
low_price = tds[10].text.strip() # 最低
open_price = tds[11].text.strip() # 今开
pre_close = tds[12].text.strip() # 昨收
data = (
board_code,
seq_no, stock_no, stock_name,
last_price, change_pct, change_amt,
volume, amount, amplitude,
high_price, low_price, open_price, pre_close
)
cursor.execute(sql, data)
conn.commit()
print(board_code, "板块入库完成!\n")
5. Step3:处理反爬机制与页面加载
实际运行时,直接用 Selenium 打开东方财富页面,往往会弹出广告或提示弹窗,例如:
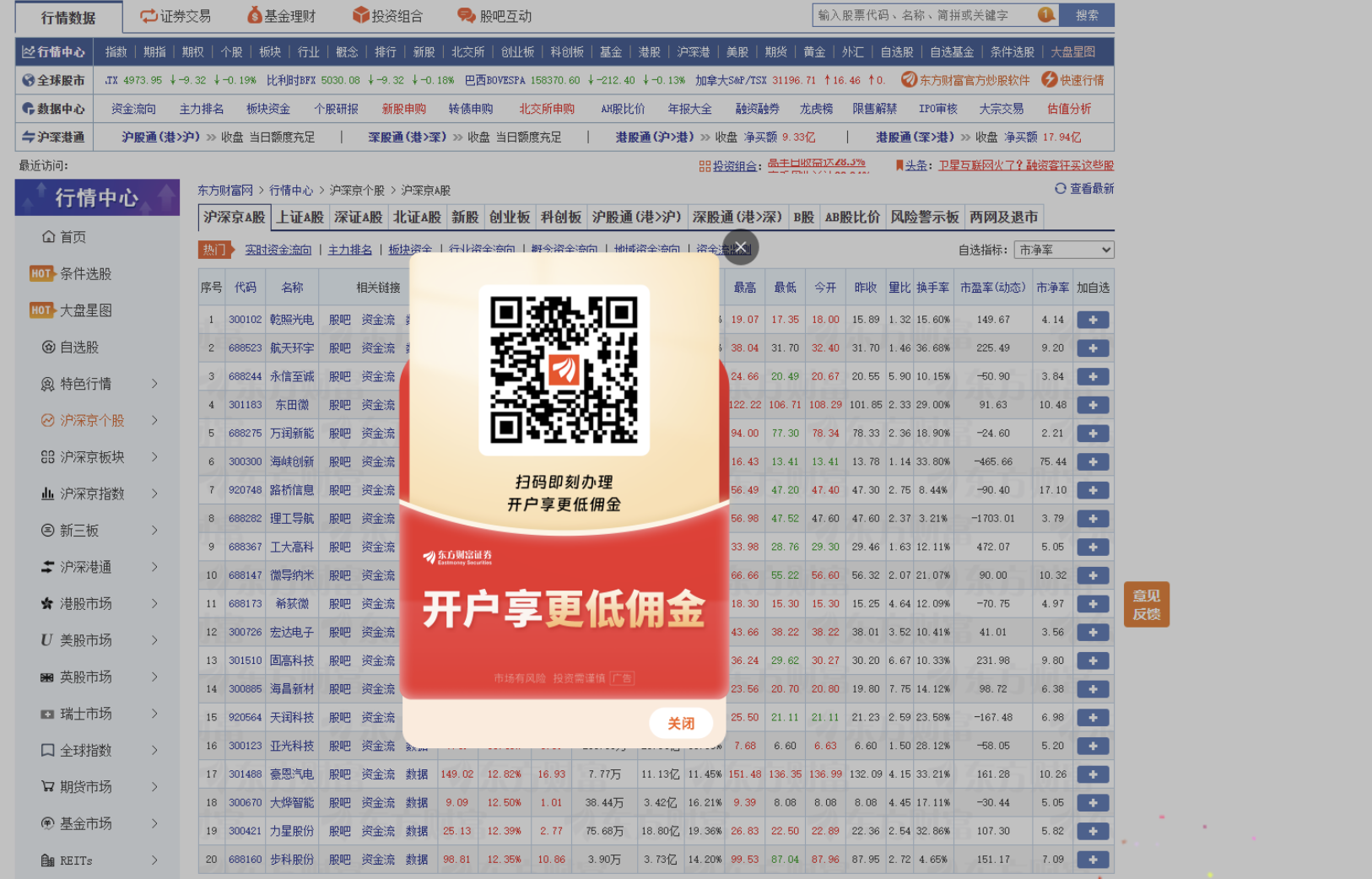
如果不处理这一点,很容易出现以下问题:
- 页面和表格还没加载完成就开始抓;
- 弹窗遮住了数据区域,导致元素无法正常获取;
最终会导致抓不到完整的股票数据。
为了让代码保持简单、逻辑清晰,这里采用了一个相对直接的处理方式:
- 每次打开板块页面之后,先调用
time.sleep(5),给浏览器和 Ajax 请求预留一定的加载时间; - 等页面元素稳定后,在浏览器中手动关闭广告弹窗(或通过 Selenium 定位关闭按钮进行点击);
- 再去查找表格
<table>,遍历行<tr>,完成数据解析与入库。
上述等待逻辑已经体现在 crawl_board 函数开头:
def crawl_board(hash_code, board_code):
# 1) 拼接 URL,打开对应板块页面
url = BASE_URL + hash_code
driver.get(url)
# 2) 简单等待页面和数据加载完成
time.sleep(5)
# 3) 后续再去查找表格行并入库
rows = driver.find_elements(By.CSS_SELECTOR, "table tbody tr")
print("共发现行数:", len(rows))
...
6. Step4:程序入口与资源释放
程序入口如下所示,会依次爬取三个板块的数据,并在最后关闭数据库连接与浏览器:
if __name__ == "__main__":
try:
# 依次爬三个板块
crawl_board("hs_a_board", "hs_a") # 沪深 A 股
crawl_board("sh_a_board", "sh_a") # 上证 A 股
crawl_board("sz_a_board", "sz_a") # 深证 A 股
finally:
# 释放资源
cursor.close()
conn.close()
driver.quit()
7. 运行结果
运行脚本后,程序会依次打开三个板块页面,将抓取到的股票列表写入到 MySQL 数据库 stock_spider 的 stocks 表中。

8. 心得体会
这次做东方财富网股票数据采集,我主要遇到了以下两个问题:
第一个卡住我的问题是 页面还没加载完就去抓表格。刚开始我用 find_elements 去取 table tbody tr,结果要么只拿到几行,要么直接是 0 行。我还以为是选择器写错了,改来改去都不对。后来我在浏览器里按 F12 打开开发者工具,一边刷新页面一边看元素变化,才发现股票数据是 Ajax 异步加载的,刚打开的时候表格是空的,过一会儿才出来。知道原因之后,我就在 driver.get(url) 后面先加了一个 time.sleep(5),再用 print(len(rows)) 看一下行数,慢慢把等待时间调到比较合适的值,至少保证表格加载出来再去解析。
第二个问题是 广告弹窗遮住了页面。有时候浏览器刚打开东方财富页面就弹出一个广告,看起来好像“什么都点不到”。我一开始还以为是 Selenium 出问题了,后来也是通过 F12 看了一下,确认表格节点其实已经在 DOM 里了,只是视觉上被挡住了。这样我就放心了:只要保证脚本能正常找到 table tbody tr,数据还是能抓到的。
作业②:使用 Selenium+MySQL 爬取中国大学MOOC课程信息
1. 实验目的与要求
-
掌握内容:
- 使用 Selenium 查找 HTML 元素
- 模拟用户登录(手机号 + 密码)
- 爬取 Ajax 动态加载网页数据
- 显式等待与隐式等待(
WebDriverWait/implicitly_wait) - 处理弹窗、防爬等简单反爬机制
-
任务说明:
- 目标网站:中国大学 MOOC(https://www.icourse163.org)
- 使用 Selenium 自动登录账号,搜索指定关键词(如“大数据”)
- 爬取课程信息(课程号/课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介等)
- 使用 MySQL 存储抓取结果
-
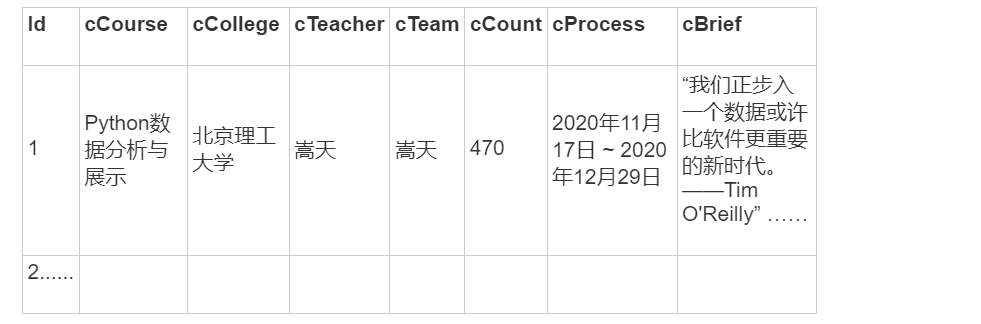
输出格式:
- 最终结果存入
t_mooc_course表,结构类似下图所示(只要字段名含义对应即可):
![MySQL 输出格式示意]()
- 最终结果存入
2. 实验环境
- 操作系统:macOS
- 主要第三方库:
seleniumpymysqlurllib(标准库中的quote)re
- 浏览器与驱动:
- Chrome 浏览器
- 对应版本的
chromedriver
3. 总体思路与流程设计
核心思路:
- 启动 Selenium Chrome 浏览器,访问中国大学 MOOC 登录页。
- 处理“同意隐私条款”的弹窗(如果出现)。
- 切换到登录 iframe,输入手机号和密码,完成登录。
- 登录完成后,进入搜索页,自动搜索关键词(例如“大数据”)。
- 等待课程搜索结果加载完成,从课程卡片中解析课程信息:
- 课程名称
- 学校名称
- 主讲教师
- 教学团队
- 参加人数
- 课程进度
- 课程简介
- 对解析出的多条数据去重、截取限定数量后,批量写入 MySQL。
- 关闭数据库连接,关闭浏览器。
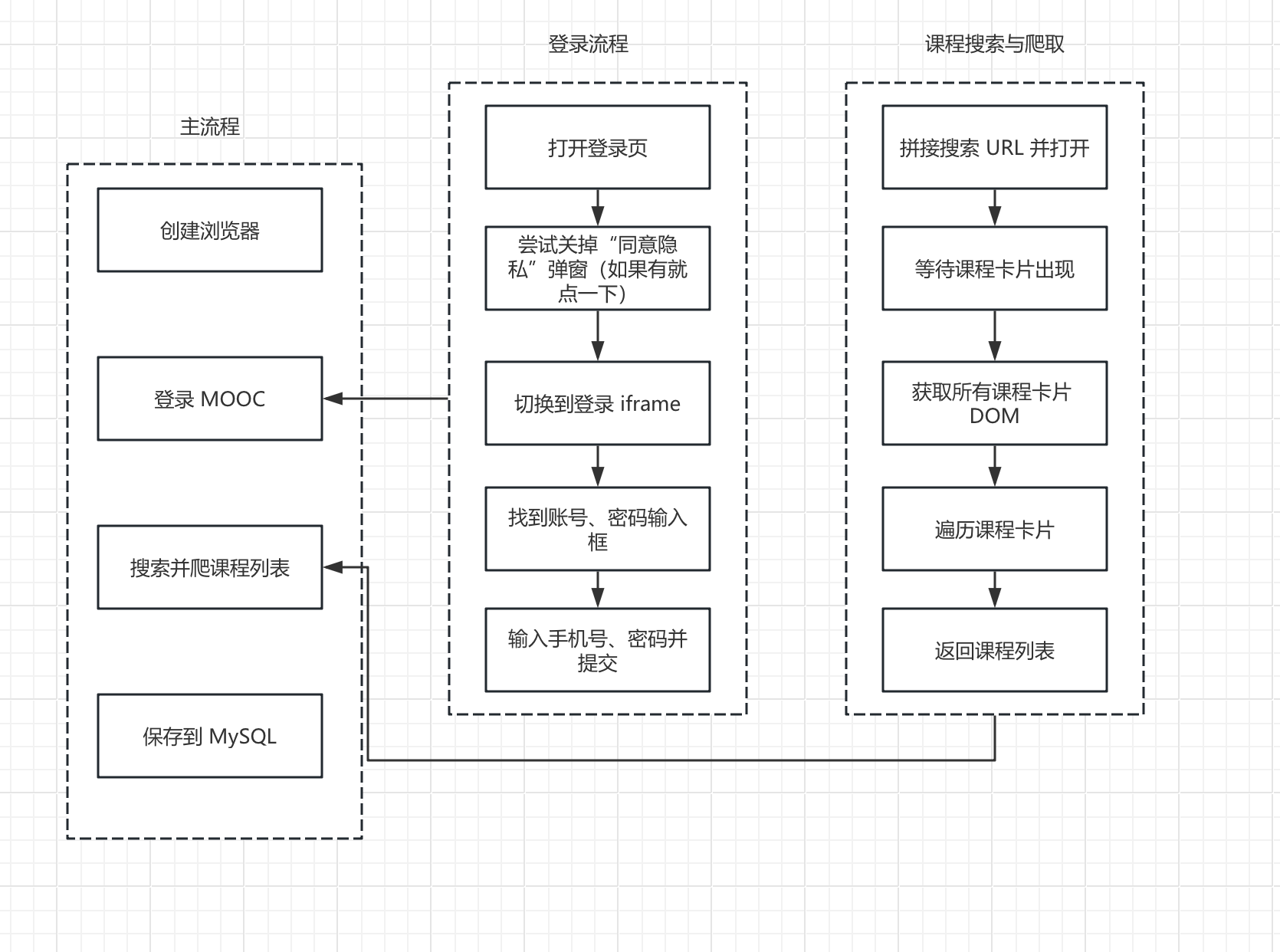
Step1:整体思路设计——自动登录 + 搜索 + 翻页爬取
本次爬虫的整体流程如下:
- 启动 Selenium 浏览器(Chrome),访问中国大学 MOOC 网站。
- 自动进行账号登录(手机号 + 密码)。
- 登录成功后,自动进入搜索页面,输入关键词(如“大数据”)并跳转到搜索结果页。
- 在搜索结果页中,定位每个课程卡片,解析课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介等信息。
- 将所有课程信息统一存入 MySQL 数据库。
示意图如下:
Step2:处理反爬取机制——关闭“同意隐私”弹窗
在用户登录完成之后,页面可能会弹出“同意隐私政策”的提示框。如果不处理该弹窗,后续的元素点击和输入可能会被遮挡,因此需要在代码中对其进行处理。
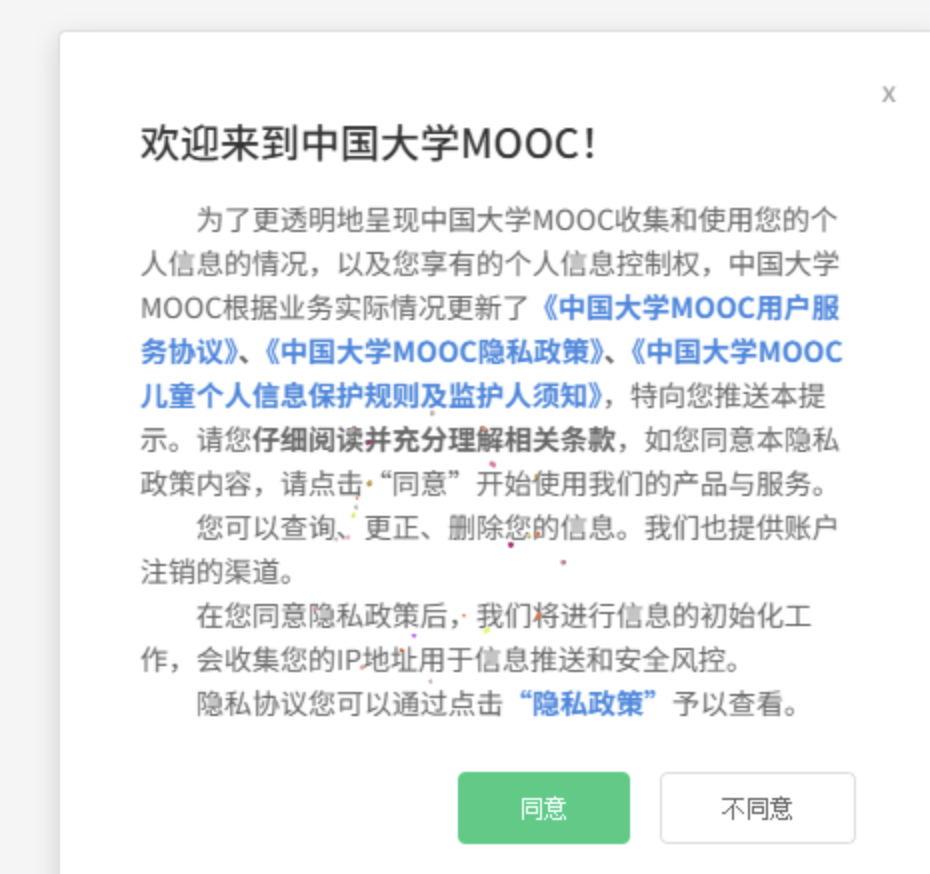
在 Selenium 中,可以通过 xpath 定位“同意”按钮,然后执行点击操作。为了防止该弹窗不存在导致报错,使用 try/except 包裹:
关掉“同意隐私”弹窗(如果有)
try:
driver.find_element(
By.XPATH, "//span[contains(text(),'同意')]/.."
).click()
time.sleep(1)
except Exception:
# 若未出现弹窗则直接忽略
pass
step3:现在要开始正式启动浏览器
def create_driver():
options = webdriver.ChromeOptions()
options.add_argument("--start-maximized")
driver = webdriver.Chrome(options=options)
driver.implicitly_wait(10)
return driver
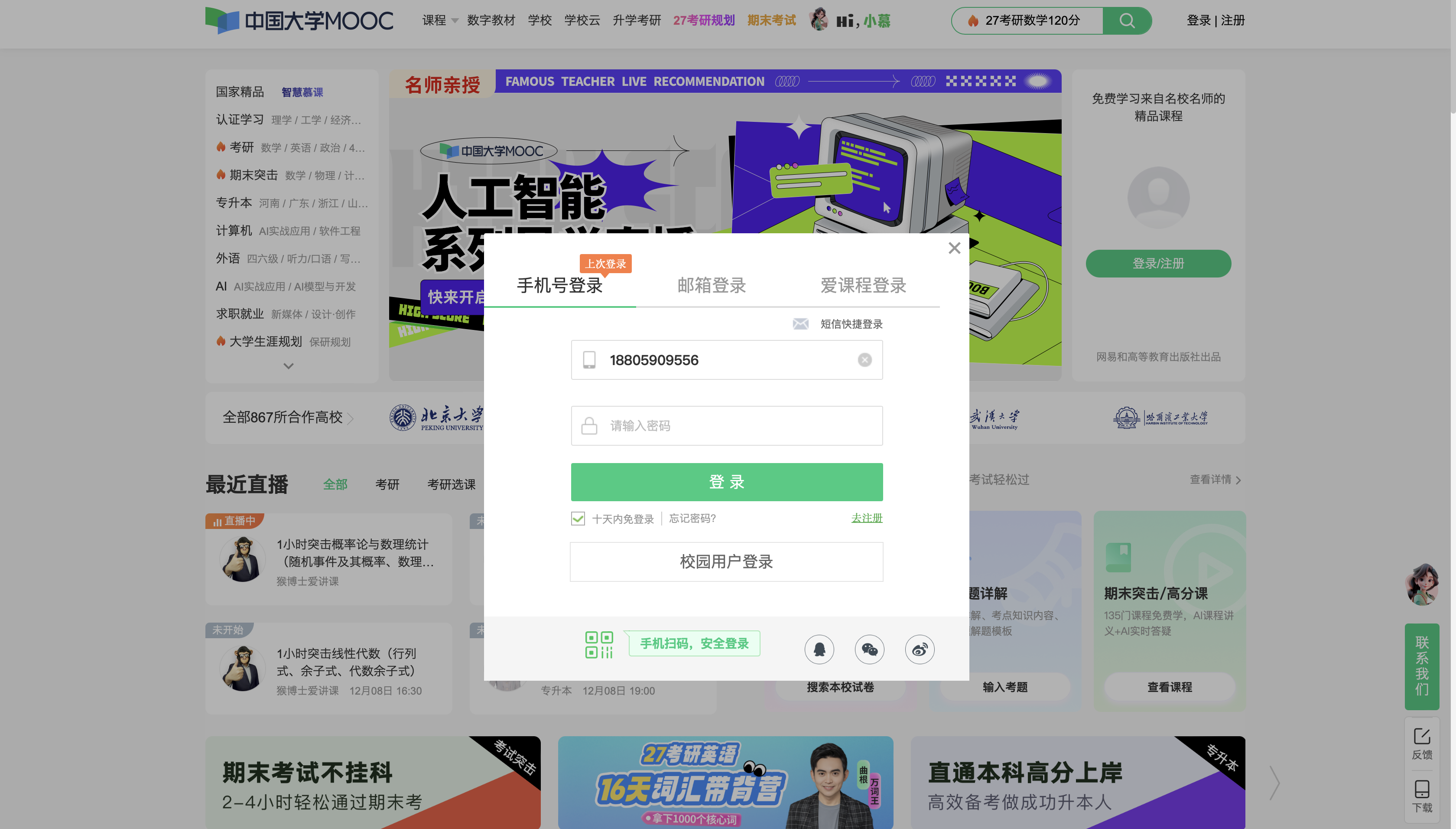
Step4:自动登录功能
进入中国大学 MOOC 网站之后,首先需要找到 登录按钮 并模拟点击。点击之后页面会弹出登录框。
这个登录框并不在主页面中,而是嵌在一个 iframe 里,因此必须先使用
driver.switch_to.frame(iframe) 将 Selenium 的“焦点”切换到该 iframe,才能在其中找到手机号和密码输入框并进行输入。
操作流程:
- 等待登录 iframe 出现,并自动切换到该 iframe。
- 在 iframe 中找到手机号输入框和密码输入框。
- 使用
send_keys()输入手机号和密码。 - 通过回车(
Keys.RETURN)提交登录表单。 - 等待登录完成后,再通过
driver.switch_to.default_content()切回主页面。
示意图如下:
对应代码实现如下:
# 切到登录 iframe
WebDriverWait(driver, 10).until(
EC.frame_to_be_available_and_switch_to_it(
(By.CSS_SELECTOR, "iframe[id^='x-URS-iframe']")
)
)
# 定位手机号输入框
phone_input = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, "phoneipt"))
)
# 定位密码输入框
pwd_input = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable(
(By.CSS_SELECTOR, "input.j-inputtext.dlemail[type='password']")
)
)
# 输入账号密码并提交
phone_input.clear()
phone_input.send_keys(PHONE)
pwd_input.clear()
pwd_input.send_keys(PASSWORD)
pwd_input.send_keys(Keys.RETURN)
# 回到主页面
time.sleep(5)
driver.switch_to.default_content()
print("登录完成,当前标题:", driver.title)
Step5:模拟搜索功能(关键词检索课程)
登录成功后,需要在页面顶部的搜索框中输入关键词(例如“大数据”),然后触发搜索。
根据页面结构,可以通过 span / input 的 class 来定位搜索输入框,最简单的做法是:
- 找到搜索输入框元素;
- 使用
send_keys(KEYWORD + Keys.RETURN)输入关键词并直接回车; - 等待页面跳转到搜索结果页。
示意界面如下:

示例代码:
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def search_keyword(driver, keyword):
"""
在首页顶部搜索框中输入关键词并回车,跳转到搜索结果页面
"""
# 等待搜索输入框可用
search_input = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable(
# 这里的选择器需要根据实际页面 class 做适配
(By.CSS_SELECTOR, "input[placeholder*='搜索']")
)
)
# 清空并输入关键词
search_input.clear()
search_input.send_keys(keyword)
# 回车触发搜索
search_input.send_keys(Keys.RETURN)
# 等待搜索结果页加载
WebDriverWait(driver, 10).until(
EC.presence_of_element_located(
(By.CSS_SELECTOR, "div._3NYsM")
)
)
print(f"关键词 [{keyword}] 搜索完成,进入结果页面")
Step6:课程详情解析(从课程卡片中提取字段)
在完成搜索并定位到课程卡片之后,就可以正式从每一张课程卡片中解析出需要的课程信息。
下图示意了课程卡片上各个关键信息的位置(课程名称、学校名称、老师、参与人数、进度、简介等):

通过对 HTML 结构进行分析,我编写了一个 parse_card(card) 函数,专门负责从单张课程卡片中抽取信息。
整体思路是:
- 封装两个小工具函数:
t(by, sel): 获取单个元素的文本内容(找不到就返回空字符串),防止报错;ts(by, sel): 获取多个元素的文本列表(过滤掉空字符串)。
- 使用 CSS 选择器精准定位课程卡片内部的各个字段,例如:
- 课程名称:
div.m7l9I div._1vfZ- - 学校名称:
div.m7l9I div._1gMZA a._3vJDG - 教师团队:
div.m7l9I div._1gMZA div._1ONN1 a._3t_C8 - 课程简介:
div.m7l9I div._3JEMz - 课程进度:
div.m7l9I div._2qY7l div.NOdDs - 参加人数:
div.m7l9I div._2qY7l div._CWjg
- 课程名称:
- 对参加人数这种带有“人参加”字样的文本,用正则表达式提取纯数字部分。
代码如下:
def parse_card(card):
"""从一张课程卡片里提取信息,出错就返回空字符串"""
# 工具函数:取单个元素文本
def t(by, sel):
try:
return card.find_element(by, sel).text.strip()
except Exception:
return ""
# 工具函数:取多个元素文本列表
def ts(by, sel):
try:
return [e.text.strip() for e in card.find_elements(by, sel)
if e.text.strip()]
except Exception:
return []
# 课程名称
cCourse = t(By.CSS_SELECTOR, "div.m7l9I div._1vfZ-")
# 学校名称
cCollege = t(By.CSS_SELECTOR, "div.m7l9I div._1gMZA a._3vJDG")
# 主讲教师 + 团队成员(可能有多个老师)
teachers = ts(By.CSS_SELECTOR, "div.m7l9I div._1gMZA div._1ONN1 a._3t_C8")
cTeacher = teachers[0] if teachers else "" # 取第一个作为主讲
cTeam = "、".join(teachers) if teachers else "" # 用顿号拼成团队字符串
# 课程简介
cBrief = t(By.CSS_SELECTOR, "div.m7l9I div._3JEMz")
# 课程进度(进行中 / 即将开课 等)
cProcess = t(By.CSS_SELECTOR, "div.m7l9I div._2qY7l div.NOdDs")
# 参加人数文本,例如 “12345人参加”
count_txt = t(By.CSS_SELECTOR, "div.m7l9I div._2qY7l div._CWjg")
# 使用正则提取数字部分作为参加人数
m = re.search(r"(\d+)", count_txt.replace(",", ""))
cCount = int(m.group(1)) if m else 0
# 返回一个元组,后面可直接写入数据库
return (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
Step7:数据库处理与结果写入(MySQL 存储)
在前面的步骤中,我们已经通过 crawl_courses() + parse_card() 得到了一批课程记录,每条记录是一个 7 元组:
(cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
接下来要做的,就是把这些数据批量写入到 MySQL 数据库中的 t_mooc_course 表中。
1)批量插入函数设计
下面的 save_to_mysql(rows) 函数负责完成整个“写库”过程:
- 通过
get_conn()获取数据库连接conn和游标cur; - 准备好
INSERT语句,字段顺序与元组顺序一一对应; - 使用
cur.executemany(sql, rows)实现 批量插入,效率比逐条插入更高;
def save_to_mysql(rows):
conn, cur = get_conn()
sql = f"""
INSERT INTO {MYSQL_TABLE}
(cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
try:
# 批量插入所有课程记录
cur.executemany(sql, rows)
conn.commit()
print(f"成功插入 {len(rows)} 条记录。")
except Exception as e:
print("插入失败:", e)
conn.rollback()
finally:
cur.close()
conn.close()
Step8:终端展示结果

Step9:心得体会
在这次中国大学 MOOC 课程数据采集的实验里,我原本以为就是把 Selenium 和示例代码串一下就能跑起来,真正动手之后才发现问题一个接一个冒出来。还好最后都是一步步排查、对着 F12 和报错信息慢慢解决的。
第一个卡住我的问题是登录。
页面上明明能看到手机号和密码输入框,但 Selenium 一直报 NoSuchElementException,死活定位不到。一开始我以为是 CSS 选择器写错了,各种改选择器都不行。后来我打开 F12 认真看 DOM 结构,才发现登录框其实是嵌在一个 iframe 里面的,如果不先 switch_to.frame(),Selenium 根本“看不见”里面的元素。意识到这一点之后,我改成用 frame_to_be_available_and_switch_to_it 等 iframe,再去找 phoneipt 和密码输入框,登录部分一下子就顺了,这也让我真正理解了 iframe 对元素定位的影响。
第二个问题是“同意隐私”的弹窗。
有时候一登录就弹出一个“同意隐私”的提示,正好挡在中间,脚本要么点不到后面的控件,要么整个流程直接乱掉。刚开始我还以为是页面抽风,后来仔细在页面里搜了一下“同意”两个字,发现可以用 XPath://span[contains(text(),'同意')]/.. 精准定位按钮。为了防止有时候弹窗根本不出现,我又在外面包了一层 try/except,有弹窗就点击关闭,没有就直接跳过,这样脚本在不同情况下都能稳稳地走完。
第三个问题是课程卡片解析和防重复。
MOOC 页面上的 class 名基本都是 _3NYsM、_1vfZ- 这种看不出含义的名字,我只好对着 F12 一层一层点 div,逐个确认哪个是课程名、哪个是学校、哪些是老师的链接。把这些字段都解析出来之后,又发现有些课程会重复出现,于是我就用 (课程名, 学校) 作为 key 存到一个 set 里做去重,只保留第一条。参加人数是“xxxx人参加”这种字符串,我又配合 re.search 把纯数字提出来,这样后面在数据库里做统计会方便很多。
整体做下来,我最大的体会是:遇到问题不要一上来怀疑“网页又出 bug 了”,而是先学会用 F12 看结构、用报错信息和打印日志定位问题,多试几种思路,很多坑其实都能自己填上。
作业③:华为云大数据实时分析处理(Flume 日志采集实验)
1. 实验目的
- 熟悉 Xshell 远程登录与基本命令行操作;
- 掌握华为云 MapReduce、Kafka、Flume、DLI(Flink)、RDS、DLV 等大数据相关服务的基本使用;
- 完成一次完整的实时数据流处理链路:
Python 造数 → Flume 采集 → Kafka 消息队列 → Flink(DLI) 实时计算 → MySQL(RDS) 落库 → DLV 实时可视化。
2. 实验环境
- 华为云账号及控制台权限;
- 已开通:
- MapReduce 服务(MRS 集群)
- 数据湖探索 DLI
- 云数据库 RDS(MySQL)
- 数据可视化 DLV
- 本地工具:Xshell(或类似 SSH 客户端),用于远程登录 MRS Master 节点。
3. 实验任务概览
-
环境搭建:
- 任务一:开通 MapReduce 服务
-
实时分析开发实战:
- 任务一:Python 脚本生成测试数据
- 任务二:配置 Kafka
- 任务三:安装 Flume 客户端
- 任务四:配置 Flume 采集数据
三、实验步骤说明
本次实验参考《华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx》,依次完成如下步骤,搭建一条完整的实时数据处理链路。
3.1 环境搭建:开通 MapReduce 服务 & 数据可视化服务
-
开通 MapReduce 服务(MRS 集群)
- 登录华为云控制台,进入 MapReduce 服务(MRS) 页面。
- 根据文档创建包含 Kafka、Flume 等组件的集群,配置节点规格、网络、登录方式等。
- 集群创建完成后,记录:
- Master 节点弹性公网 IP;
- 集群名称、ID 以及所在 VPC 信息。
![开通 MRS]()
-
开通数据可视化服务(DLV)
- 在华为云控制台中开通 数据可视化 DLV 服务。
- 确保 DLV 与后续使用的 RDS、DLI(Flink)处于可达的网络环境(同一区域或已打通 VPC)。
- 后续大屏展示将依赖该服务进行实时可视化。
![开通 DLV]()
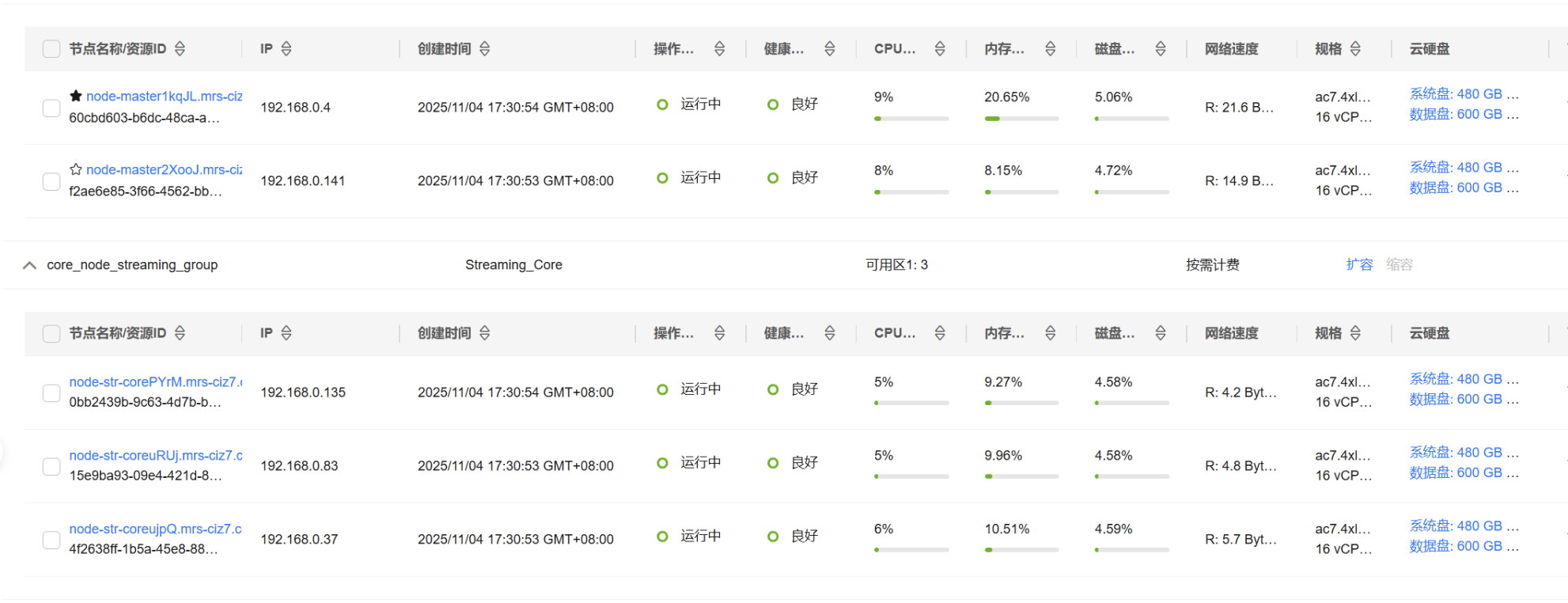
2. 实时分析开发实战
2.1 Python 脚本生成测试数据
本步骤的目标是:在服务器上持续生成模拟业务日志,作为后续 Flume → Kafka → Flink 实时处理链路的原始数据来源。
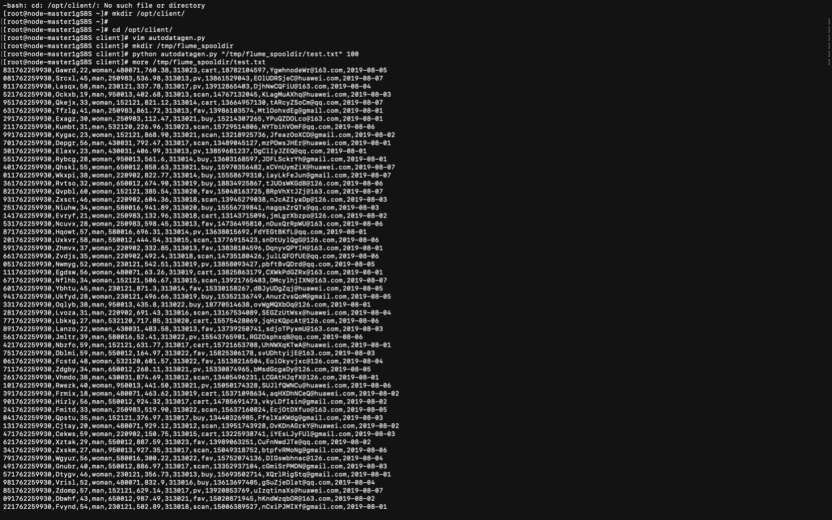
2.1.1 编写 Python 脚本
- 使用 Xshell 登录到 MRS 集群 Master 节点;
- 在指定目录(如
/opt/client/或/opt/client/logdata/)中创建脚本文件,例如:
![image]()
2.1.2 创建存放测试数据的目录 - 在服务器上为日志文件准备专用目录,便于 Flume 后续统一采集:
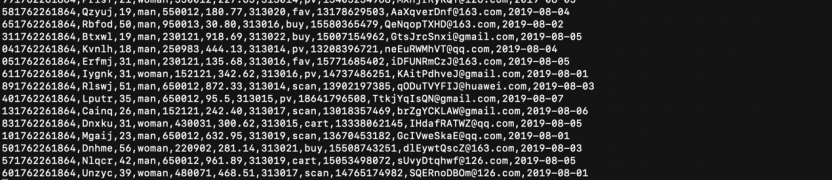
2.1.3 执行脚本测试 - 执行 Python 脚本,让其开始生成模拟数据
2.1.4 使用 more 命令查看生成的数据 - 脚本运行一段时间后,使用 more 或 tail -f 检查日志文件内容,确认格式正确
2.2配置Kafka
2.2.1设置环境变量
2.2.2在kafka中创建topic
2.2.3查看topic信息
![image]()

2.3安装Flume运行环境
2.3.1解压“MRS_Flume_ClientConfig.tar”文件
2.3.2查看解压后文件

2.3.3安装Flume客户端

2.3.4重启Flume服务

2.4配置Flume采集数据
可以看到已经消费出了数据
有数据产生,表明Flume到Kafka目前是打通的。
测试完毕,在新打开的窗口输入exit关闭窗口,在原窗口输入 Ctrl+c退出进程。
2.5 MySQL中准备结果表与维度表数据
2.5.1创建维度表并插入数据
执行成功后可以在下面看到执行消息
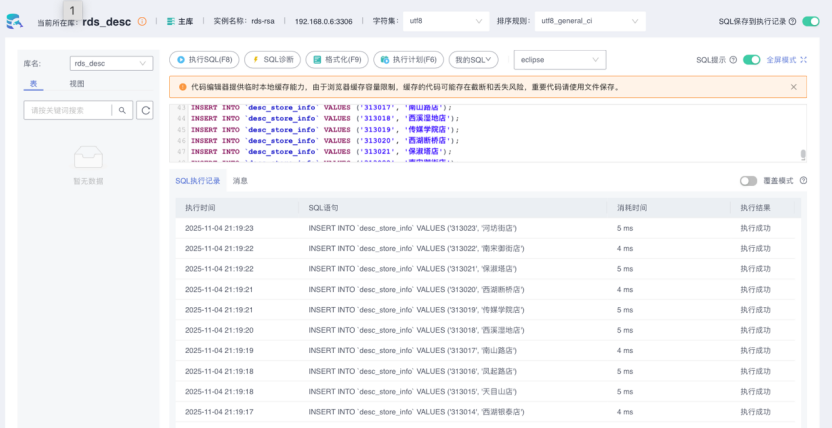
2.5.2创建Flink作业的结果表
执行成功后,点击左侧的刷新按钮可以看到已经创建的表
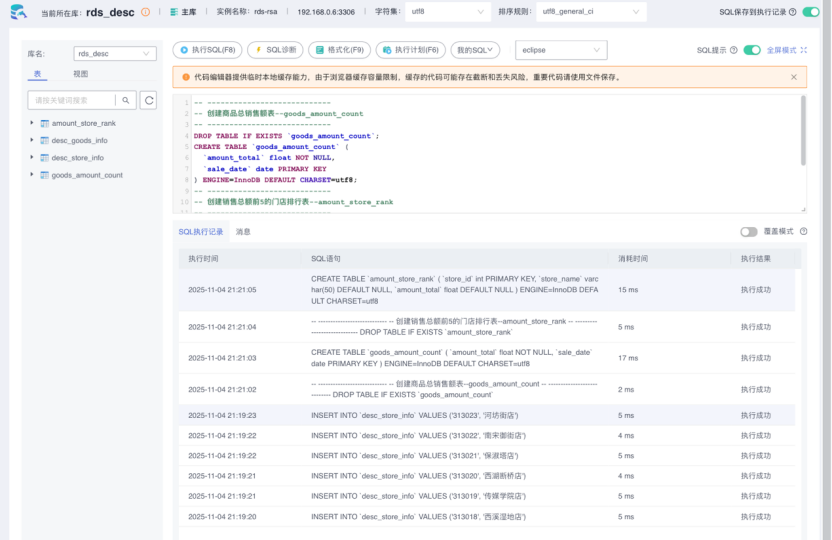
2.6使用DLI中的Flink作业进行数据分析
2.6.1测试网络连通性
测试DLI与Kafka网络是否连通
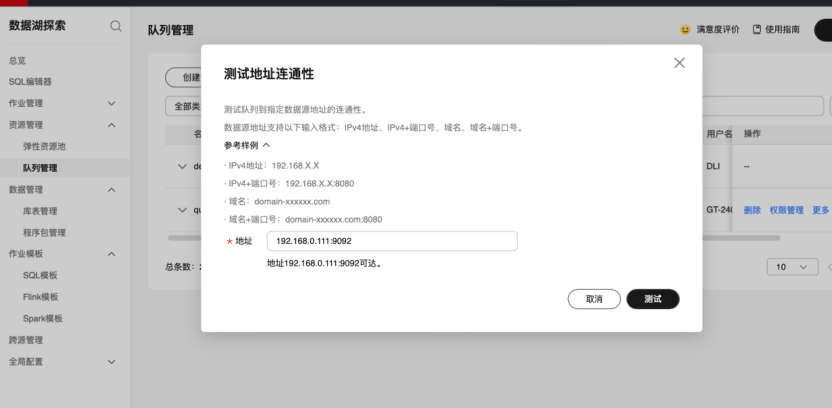
说明可连通
测试mysql端口连通性
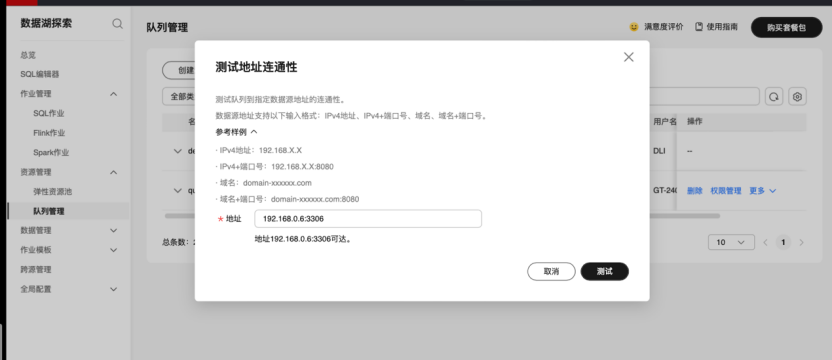
说明可连通
2.6.2查看作业运行详情
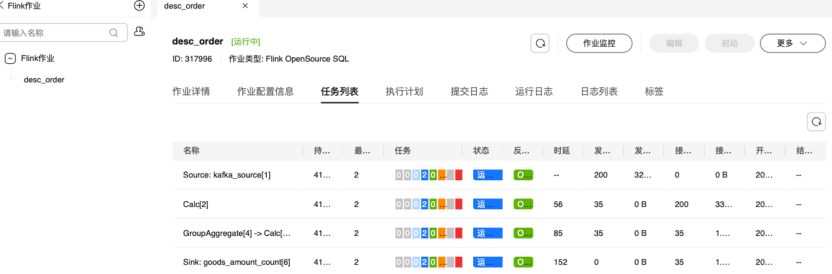
2.6.3验证数据分析

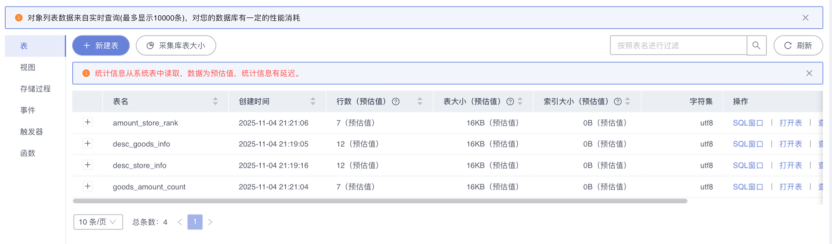
登录MySQL后点击数据库的名称或后面的“库管理”进入到库管理界面,可以看到结果表中有数据进来:
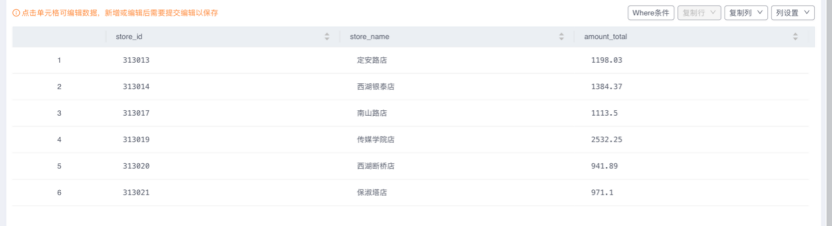
点击表名后面的“SQL查询”可以看到表中的数据:
2.7 DLV数据可视化
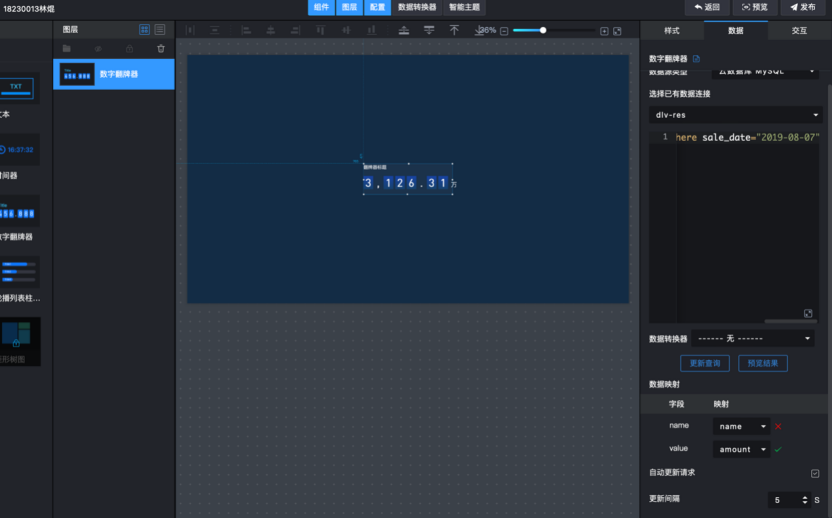
2.7.1展示实时交易总金额
从左侧选择文本组件中的数字翻牌器,会自动添加到大屏中:
2.7.2展示销售额排行前5的门店信息

销售总额和门店销售额都应该是实时变化的。根据业务端生成的数据,经过实时流处理后存储到数据库中再通过大屏实时展示。
2.7.3定时执行数据生成脚本

心得体会
这次做华为云大数据实时分析处理实验,说实话跟之前那种“单机跑个脚本”完全不是一个难度。整个链路从 Python 造数,到 Flume → Kafka → Flink(DLI)→ MySQL(RDS)→ DLV 大屏,中间任何一个环节有问题,后面基本都是“空转”,一开始我是完全抓不到头绪的。
刚开始踩坑最多的是 环境和网络。一开始 DLI 连 Kafka 总是报错,我以为是 Flume 或 Kafka 配错了,反复检查配置文件都没发现问题。后来才想到可能是网络没打通,于是按照文档里提示,用 DLI 的诊断工具去测 VPC 互通、Kafka 端口连通,才发现之前没有正确配置跨源连接和安全组。把对等连接状态、安全组端口(Kafka、MySQL)都重新检查一遍,连通性测试变绿之后,Flink 作业才真正开始有数据流入。
第二个坑是 Flume 和 Kafka 对接。Flume 配置里涉及到 source、channel、sink,一开始我只是“照着配”,结果 Flume 启动成功,但 Kafka 里迟迟没有数据。后来我学会了几件事:
1)先在本地用 more 命令确认 Python 脚本生成的数据文件确实有内容;
2)再看 Flume 的日志,重点关注 sink 那一段有没有报错;
3)对照 Kafka 的 topic 名称、broker 地址,逐行核对 Flume 的配置。最后发现是自己 topic 名字写错了一个字母,改完之后,用 Kafka 消费者去监听,终于看到实时刷新的消息,才确认“Flume → Kafka” 这一段真打通了。
还有一个收获比较大的地方是 DLI + DLV 这一块。以前对 Flink SQL 和 Serverless 计算的概念比较抽象,这次是第一次完整走了一遍:在 DLI 里写 Flink SQL,从 Kafka 读流数据,关联 MySQL 维度表,结果再写回 MySQL 的结果表。刚开始作业老是执行失败,我就去看作业详情里的日志,按着报错提示去检查字段类型、表名是否一致。等到 MySQL 结果表里真正看到实时更新的数据,再去 DLV 绑定数据源、拖拽数字翻牌器和排行榜组件,大屏上的“总交易额”和“Top5 门店销售额”能跟着脚本实时跳动,那个瞬间会觉得之前折腾网络和配置还是挺值的。
总体来说,这个实验让我第一次真正体会到“实时数仓”的感觉:前面任何一环的小问题,最后都会表现为“结果不更新”或者“大屏不动”,逼着我从网络、配置、日志三个角度去排查。相比一开始只是照着文档点来点去,现在我对 MapReduce 集群、Kafka topic、Flume 通道、Flink 作业、RDS 和 DLV 之间的关系清晰了很多,也更有信心以后自己搭一条小型的实时数据链路。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号