

数据采集第一次作业
作业1
1.大学排名动态网页爬取实验
实验要求
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
核心代码与运行结果
trs = soup.select("table tbody tr") # 直接定位到表格的每一行
rows = []
for tr in trs:
tds = tr.find_all("td")
cols = [td.get_text(strip=True) for td in tds] # 取纯文本并去空白
# 按页面列序取:排名/学校/省市/类型/总分
rank, name, prov, s_type, score = cols[0], cols[1], cols[2], cols[3], cols[4]
s = " ".join((name or "").split()) # 归一化空白,便于后续正则
m = re.match(r'^([\u4e00-\u9fa5]+)', s) # 从开头提取连续中文作为校名
# 如果没直接匹配到中文名,则按英文或“双一流/985/211”等切分取前段
name_cn = m.group(1) if m else re.split(r'[A-Za-z]|双一流|985|211', s)[0].strip()
rows.append([rank, name_cn, prov, s_type, score])
print("{:<4}\t{:<12}\t{:<6}\t{:<6}\t{:>6}".format("排名", "学校名称", "省市", "类型", "总分"))
for r in rows[:30]:
print("{:<4}\t{:<12}\t{:<6}\t{:<6}\t{:>6}".format(*r))
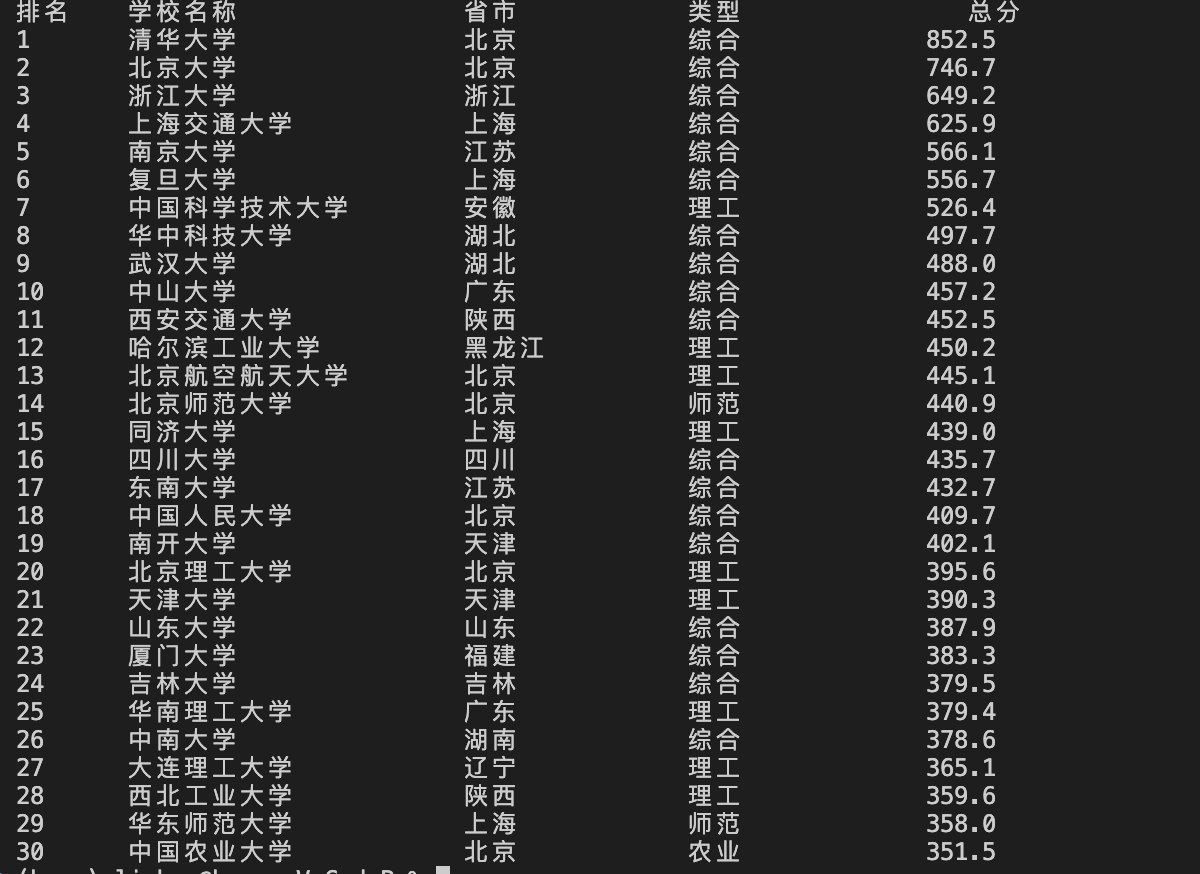
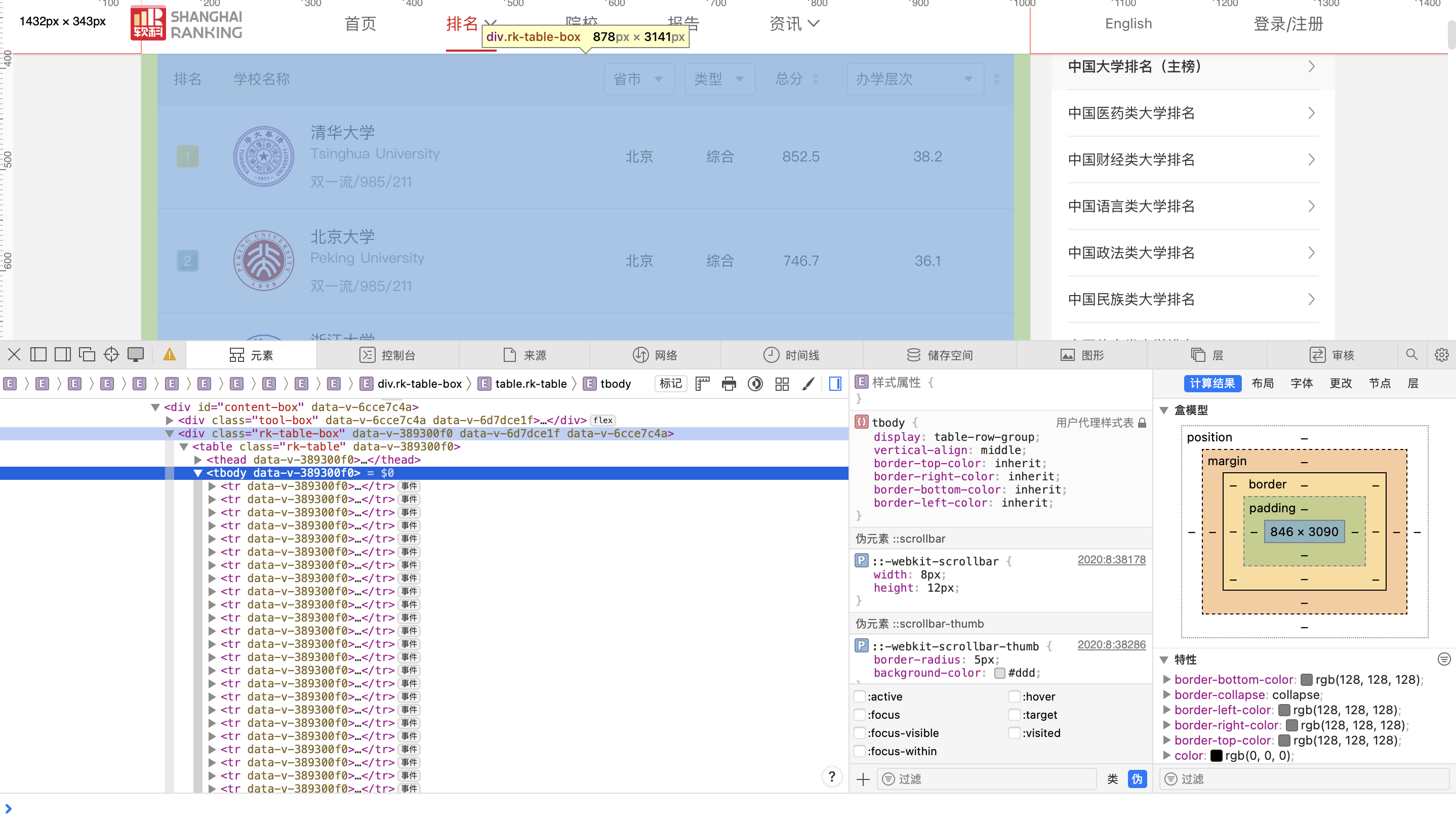
从图中我们可以发现,排名表被包在一个div.rk-table-box里,里面才是真正的表格,我们可以直接把每一行取出来,正好一行对应一所学校。
接着使用正则匹配取出连续的中文,如果中间混了别的内容,就按英文字母或“双一流/985/211”这些标记分割,取分割前的中文部分,之后的操作就很简单了。
心得
这道题刚开始是想要设计翻页的,观察软科的大学排行榜,进行翻页操作的时候,url是没有发生变化。那我们就不能简单的使用for循环来实现翻页。如果想要实现翻页功能,那就不是只用requests和BeautifulSoup库就能实现的了。
作业2
1.商城商品比价定向爬虫实验
实验要求
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
核心代码与运行结果
pair_pat = re.compile(
r'<p[^>]*class="name"[^>]*>.*?title=["\']([^"\']+)["\'].*?</p>\s*'#在<p class="name">中取 title="...":分组1为商品名
r'.{0,50}?'#中间允许最多50个任意字符
r'<p[^>]*class="price"[^>]*>.*?(?:¥|¥)\s*([0-9]+(?:\.[0-9]+)?)'# 3) 在<p class="price"> 中匹配¥或¥后的价格:分组2为价格
)
# 提取所有 (name, price) 组合
items = pair_pat.findall(html)
for i, (name, price) in enumerate(items, 1):
name = name.strip()
if name and price:
print(f"{i}. {name} {price}")


我的思路是直接一次性同时抓到书名与价格,这样会在步骤上简单很多,我不需要一层一层找,我只需找到符合所有符合的书名-价格对即可。同时我允许书名和价格之前存在一些其他字符,这样能尽可能的爬取更多的数据。
首先,找到含class=name的属性,然后从中取出title里的内容。接下来类似,找到含class=price的属性,从中取出价格。
心得
因为部分大网站反爬机制强大,因此为了完成本次任务,选择了一个比较小的购物网站-当当网站。起初我尝试用 BeautifulSoup 逐层解析,但当当的块比较深,因此使用直接寻找成对会更快也更简单。这样把同一商品的名称-价格一起提出来,使得代码更加简单。
作业3
1.网页图片批量下载实验
实验要求
爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)的所有JPEG、JPG或PNG格式图片文件
输出信息:将自选网页内的所有JPEG、JPG或PNG格式文件保存在一个文件夹中
核心代码与运行结果
for page in range(1, 7): #抓取第1~6页
if page == 1:
page_url = f"{base_url}.htm"
else:
page_url = f"{base_url}/{7-page}.htm"
print(f"第 {page} 页:{page_url}")
response = requests.get(page_url) # 请求页面
soup = BeautifulSoup(response.text, 'html.parser') # 解析HTML
images = soup.find_all('img') # 提取所有<img>标签
for img in images:
src = img.get('src') # 读取图片链接
src = urljoin(page_url, src) # 与页面URL拼成绝对路径
img_name = src.split('/')[-1] # 以URL最后一段作为文件名
img_response = requests.get(src, allow_redirects=True) # 下载图片数据
# 将图片内容写入本地文件
with open(os.path.join(folder, img_name), 'wb') as f:
f.write(img_response.content)
print(f"下载图片:{img_name}")
print(f"第 {page} 页完成。\n")
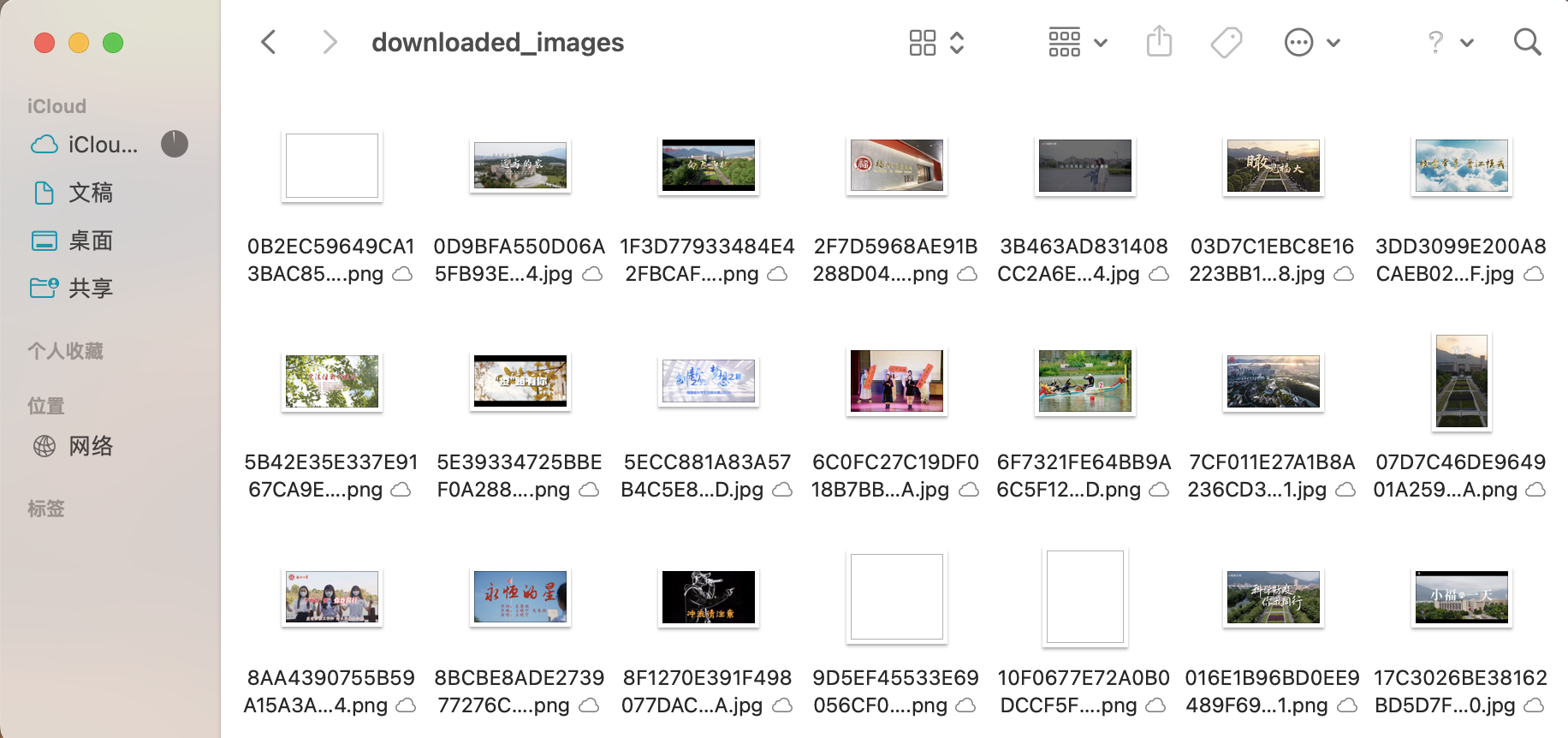

首先福大这个网站跟任务一的软科网站不同,他是可以通过循环来实现分页,看来福大的网站还是友好的。然后我遍历了页面里的所有img,取出他们的src,然后再组合成完整的路径,确保下载不出错。
心得
我感觉这个任务其实相比前两个任务来说并没有太大区别,三个任务都是request抓页面,然后定位块,抽取字段的操作,但对于不同的页面其实有不同的方法,这也表现了正则表达式的多样性。这个任务三可能就是多了个翻页吧,但有点意思的是,福大这个网站第一页居然对应的是6.htm,居然是倒过来的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号