计算机组成原理期末复习
计组知识点
第一章
- 国外计算机发展
- 电子管计算机(1946—1958 年)
- 晶体管计算机(1958—1964 年)
- 集成电路计算机(1964—1971 年)
- 超大规模集成电路计算机(1971 年至今)
第二章
一、机器码基本概念
用二进制的 0/1 表示符号位(0 表正、1 表负)+ 数值位的编码形式,称为机器码(机器数)。
常用定点数机器码包括:原码、反码、补码。
二、原码
1. 基本思想
原码采用 符号位 + 数值绝对值 的方式表示有符号数。
最高位为符号位,其余位表示数值大小。
- 符号位为
0:表示正数 - 符号位为
1:表示负数
2. 编码规则
- 正数:符号位为
0,数值位等于该数的二进制表示; - 负数:符号位为
1,数值位等于该数绝对值的二进制表示。
例 1(定点整数,字长 5 位)
两者数值位相同,仅符号位不同。
3. 定点小数原码
设字长为 ( n+1 ) 位,最高位为符号位,小数点在符号位之后。
- 数值位权:\(( 2^{-1},2^{-2},\dots,2^{-n} )\)
- 表示范围:\((-1 < x < 1)\)
原码形式为:
其中:
[
x = (-1){x_0}\sum_{i=1}x_i2^{-i}
]
例 2(定点小数,字长 5 位)
\( -0.625 = 1.1010_{\text{原}} \)
数值部分 \((0.1010_2 = 2^{-1}+2^{-3}=0.625)\)。
4. 定点整数原码
设字长为 ( n+1 ) 位,最高位为符号位,其余位为整数数值位。
- 数值位权:\(( 2^{n-1},2^{n-2},\dots,2^{0} )\)
- 表示范围:\((-2^n < x < 2^n)\)
原码形式为:
其中:
例 3(定点整数,字长 6 位)
5. 0 的表示
原码中存在两个不同的编码表示 0:
这两个编码在数值上等价,但在机器中不同。
例 4(字长 4 位)
6. 特点与应用
- 原码表示直观,符号与数值部分分离;
- 存在两个机器零;
- 加减运算需区分符号,硬件实现复杂;
- 通常不用于整数算术运算;
- 常用于浮点数的尾数表示。
好,这一段我严格按你刚才认可的风格来处理:
不加“记忆法”、不加口号、不炫技,只做三件事:
- 规则写清楚
- 概念不跳步
- 用极小例子把“为什么这样做”说明白
下面这版可以直接替换你现在的 三、反码 / 四、补码。
三、反码(1 的补码)
1. 基本定义
反码是在原码基础上得到的一种表示方法。
- 符号位与原码相同;
- 正数:反码与原码一致;
- 负数:数值位逐位取反,符号位不变。
2. 定点小数反码表示
设字长为 ( n+1 ) 位,小数点在符号位之后。
例 1
原码:
反码:
例 2
原码:
反码(数值位取反):
3. 0 的表示
反码中同样存在两个 0:
4. 特点
- 正数反码与原码相同;
- 负数反码由原码逐位取反得到;
- 存在两个机器 0;
- 运算时需要回卷进位,硬件实现仍较复杂;
- 主要作为补码的过渡表示方式。
四、补码(2 的补码)
1. 模的概念
在计算机中,定长二进制数的运算是在 模 (M) 的意义下进行的。
当运算结果超出表示范围时,高位被舍弃。
例 3(十进制模运算)
说明在模 (12) 系统中,数值只保留余数部分。
2. 定点小数补码定义
设字长为 ( n+1 ) 位,小数点在符号位之后,模为 2。
例 4
例 5
3. 负数补码的求法
(1)反码加 1 法
步骤:
- 写出该数的原码;
- 对数值位逐位取反;
- 在最低位加 1。
例 6(定点整数,字长 5 位)
原码:
反码:
补码:
(2)扫描法
步骤:
- 从右向左扫描;
- 找到第一个
1; - 该位及其右侧保持不变;
- 左侧各位逐位取反。
例 7
4. 补码求真值
- 若符号位为
0,真值为正,其数值即为补码表示的大小; - 若符号位为
1,真值为负,可通过“取反加 1”或扫描法还原。
例 8
取反:
加 1:
因此:
5. 特点与应用
- 只有一个机器 0;
- 加减法可统一采用加法器完成;
- 运算规则简单,硬件实现方便;
- 计算机中整数的默认表示方式。
第三章
一、溢出的概念
由于字长有限,运算结果超出表示范围称为溢出。
- 正溢:正数加正数得负;
- 负溢:负数加负数得正。
对,这个反馈非常准。
你说的“看了和没看一样”,不是你理解能力的问题,而是——只有判别式,没有“人能跟着走的过程”。那我就把这节改成:
每一种方法:一句话思想 + 1 个最小可算例子 + 再给公式
公式还在,但你是“看懂后用它”,不是“对着它发呆”。
下面是同一风格、但可理解版。
二、溢出检测方法(补码运算)
溢出只发生在有符号数的补码加减运算中,本质是:
结果的真实值超出了机器能表示的范围。
1. 符号位一致性检测法
思想
- 同号数相加,结果符号变了 → 溢出
- 异号数相加,一定不溢出
这是最直观的判断方法。
例 1(正数上溢,4 位补码)
最大正数:
计算:
- 两个操作数符号位:\(0,0\)
- 结果符号位:\(1\)
正数加正数却得到负数 → 发生上溢
例 2(负数下溢,4 位补码)
最小负数:
计算:
- 两个操作数符号位:\(1,1\)
- 结果符号位:\(0\)
负数加负数却得到正数 → 发生下溢
判别式(用于硬件实现)
加法:
减法:
你这个点抓得非常关键,而且你说“这里写得不好”是对的——
现在的问题不是例子,而是“\(C_d\) 和 \(C_f\) 到底从哪看出来”完全没被说明。
我不换方法、不换例子,只把“怎么看进位”这件事讲清楚,让你一眼就能在草稿纸上操作。
2. 进位一致性检测法
思想
补码加法中,符号位也参与运算。
若进入符号位的进位与符号位产生的进位不一致,说明结果符号失真,发生溢出。
\(C_d\) 和 \(C_f\) 分别是什么
以 4 位补码为例(从左到右):
位号: b3 b2 b1 b0
↑符号位 数值位
-
\(C_d\):
从最高数值位 b2 加到符号位 b3 的进位 -
\(C_f\):
从符号位 b3 加法产生、被丢弃的进位
也就是说:
b2 → b3 的进位 = C_d
b3 → 丢弃 = C_f
例 3(无溢出,逐位写清)
从最低位开始加:
0 1 0 1
+ 0 0 1 1
-----------
1 0 0 0
逐位进位情况:
- b0:\(1+1=0\),进位 1
- b1:\(0+1+1=0\),进位 1
- b2:\(1+0+1=0\),进位 1 ← 进入符号位
- b3:\(0+0+1=1\),无进位
因此:
- \(C_d = 1\)(b2 → b3)
- \(C_f = 0\)(b3 → 丢弃)
注意:这个例子实际上是溢出的
(\(+5 + +3 = +8\),4 位补码无法表示)
正确的无溢出示例(替换)
0 0 1 0
+ 0 0 0 1
-----------
0 0 1 1
进位情况:
- b2 → b3:无进位 → \(C_d = 0\)
- b3 → 丢弃:无进位 → \(C_f = 0\)
例 4(有溢出,逐位写清)
0 1 1 1
+ 0 0 0 1
-----------
1 0 0 0
进位情况:
- b2:\(1+0+1=0\),进位 1 → 进入符号位
- b3:\(0+0+1=1\),无进位
因此:
- \(C_d = 1\)
- \(C_f = 0\)
3. 变形补码(双符号位)检测法
思想
在补码符号位前再加一位符号位,
让溢出直接“显形”。
例 5(上溢)
双符号位结果:
- 结果符号位为
01
→ 上溢
例 6(下溢)
双符号位结果:
- 结果符号位为
10
→ 下溢
判别式
设结果双符号位为 \(S_{f1}, S_{f2}\):
用法
- 做题时:
先看符号变没变 - 硬件题 / 选择题:
用进位一致性或双符号位 - 证明 / 推导题:
写判别式
第四章 存储器(DRAM 相关)
一、存储单元表示
DRAM 的基本存储单元由 电容 + 晶体管 构成,通过电容是否存储电荷表示数据:
- 电容有电荷 → 表示
1 - 电容无电荷 → 表示
0
说明:
电容会随时间漏电,因此 DRAM 中的数据不能长期保持,这是后续需要刷新的根本原因。
二、单管 DRAM 读操作流程
单管 DRAM 的读操作是一个读即破坏、必须恢复的过程。
1. 预充(Precharge)
位线在访问前被预充到中间电平:
目的:
使后续微小电压变化能够被可靠放大。
2. 访问(电荷重分配)
- 字线选通,存储单元电容与位线接通;
- 电容上的电荷与位线发生 电荷共享;
- 位线电压在 \(V_{CC}/2\) 基础上产生微小偏移。
说明:
此时位线上的电压变化极小,尚不能直接判断 0 或 1。
3. 放大(感应放大器)
跷跷板式感应放大器检测位线电压偏移,并迅速放大:
- 偏高 → 放大为逻辑
1 - 偏低 → 放大为逻辑
0
说明:
感应放大器既是 放大电路,也是 判断电路。
4. 恢复(Restore)
由于读操作破坏了原存储电荷:
- 放大后的结果被重新写回电容;
- 同时完成一次 隐含刷新。
5. 输出
- 列地址选通;
- 数据通过 I/O 电路送出。
三、DRAM 刷新
1. 刷新原因
DRAM 存储电容存在漏电现象,数据随时间衰减,必须周期性刷新。
2. 刷新特点
- 按 行 进行刷新;
- 所有行必须在规定时间内至少刷新一次;
- 常见最大刷新周期:2 ms、4 ms、8 ms。
3. 刷新方式对比
| 刷新方式 | 特点 |
|---|---|
| 集中刷新 | 连续刷新所有行,存在访问死区 |
| 分散刷新 | 刷新分散到各存储周期,无死区但降低访问速度 |
| 异步刷新 | 刷新与存取交叉进行,综合性能最好 |
说明:
现代 DRAM 通常采用 异步刷新或其改进形式。
四、DRAM 与 SRAM 的区别
| 项目 | SRAM | DRAM |
|---|---|---|
| 存储单元 | 触发器 | 电容 + 晶体管 |
| 是否刷新 | 不需要 | 需要 |
| 速度 | 快 | 较慢 |
| 集成密度 | 低 | 高 |
| 成本 | 高 | 低 |
| 典型用途 | Cache | 主存 |
说明:
- SRAM 速度快但成本高,适合做高速缓存;
- DRAM 密度高、容量大,适合作为主存。
总结
DRAM 采用电容存储信息,存在漏电问题,需要周期性刷新;
其读操作为破坏性读出,需在读后进行恢复;
相比 SRAM,DRAM 速度较慢但集成度高、成本低,适用于主存。
存储单位换算表
1 位 / 字节
| 单位 | 换算 |
|---|---|
| 1 B | 8 b |
| 1 b | 1 bit |
2 容量单位(按 2 的幂)
| 单位 | 等于 |
|---|---|
| 1 KB | \(2^{10}\) B |
| 1 MB | \(2^{20}\) B |
| 1 GB | \(2^{30}\) B |
| 1 TB | \(2^{40}\) B |
3 常见容量直接换算
| 容量 | 字节数 |
|---|---|
| 4 KB | \(2^{12}\) B |
| 8 KB | \(2^{13}\) B |
| 16 KB | \(2^{14}\) B |
| 32 KB | \(2^{15}\) B |
| 64 KB | \(2^{16}\) B |
| 1 MB | \(2^{20}\) B |
| 32 MB | \(2^{25}\) B |
| 64 MB | \(2^{26}\) B |
| 1 GB | \(2^{30}\) B |
| 32 GB | \(2^{35}\) B |
4 字(Word)换算(看字长)
| 字长 | 1 字 |
|---|---|
| 16 位 | 2 B |
| 32 位 | 4 B |
| 64 位 | 8 B |
5 芯片 / 存储器规格表示法
| 表示形式 | 含义 |
|---|---|
| \(M \times n\) 位 | \(M\) 个存储单元,每单元 \(n\) 位 |
| 总容量 | \(M \times n / 8\) B |
6 数据线宽度
| 数据线 | 一次传输 |
|---|---|
| 32 位 | 4 B |
| 64 位 | 8 B |
7 是否需要乘位数
| 描述出现 | 是否乘 |
|---|---|
| \(M \times n\) 位 | 是 |
| 芯片规格 | 是 |
| 直接给容量(如 32GB) | 否 |
8 编址单位
| 编址方式 | 地址 +1 |
|---|---|
| 字节编址 | 1 B |
| 字编址 | 1 字 |
如果你愿意,我可以把这一页再压缩成「一页 A4 期末速背版」。
好,这个需求说得非常清楚了 👍
你现在要的不是“定义型讲解”,而是“判别型整理”——
也就是:题目给你一个现象 / 特征,你能立刻判断它属于哪种寻址方式。
我按你们课用的记号(变址寄存器 = Rx)
给你一版 “特征 → 寻址方式”导向 的整理,表格为主,少量说明,适合期末前快速扫。
第五章 指令系统
一、指令寻址方式(判别角度)
| 出现的特征 | 寻址方式 |
|---|---|
| PC 自动加指令长度 | 顺序寻址 |
| 指令执行后 PC 被改成某个目标地址 | 跳跃寻址 |
二、操作数寻址方式
判别关键:操作数在哪里?EA 是不是要算?怎么算?
| 题目中出现的特征 | 寻址方式 | EA 关系 |
|---|---|---|
| 操作数是常数,直接写在指令中 | 立即寻址 | 操作数 = D |
| 地址字段直接给出主存地址 | 直接寻址 | \(EA = D\) |
| 地址字段指向一个单元,该单元中存放操作数地址 | 间接寻址 | \(EA = (D)\) |
| 操作数在寄存器中 | 寄存器寻址 | 无 EA |
| 寄存器中存放操作数地址 | 寄存器间接寻址 | \(EA = R[D]\) |
| 以 PC 为基准,加偏移量 | 相对寻址 | \(EA = PC + D\) |
| 以变址寄存器 Rx 为基准,加偏移量 | 变址寻址 | \(EA = Rx + D\) |
| 以基址寄存器 BR 为基准,加偏移量 | 基址寻址 | \(EA = BR + D\) |
| 操作数位置由栈顶隐含给出 | 堆栈寻址 | \(EA = SP\) |
| 寻址方式 | 操作数在哪 |
|---|---|
| 立即 | 指令中 |
| 直接 | 主存 D |
| 间接 | 主存 (D) |
| 寄存器 | 寄存器 |
| 寄存器间接 | 主存 [R] |
| 相对 | 主存 [PC+D] |
| 变址 | 主存 [Rx+D] |
| 基址 | 主存 [BR+D] |
| 堆栈 | 主存 [SP] |
操作数寻址方式示例汇总
统一假设:
- 指令地址字段为
D- 主存、寄存器内容在例子中明确给出
1. 立即寻址
特征:操作数是常数,直接写在指令中
指令示例
MOV R1, #5
说明
操作数为常数 5,不需要计算 EA,也不访问主存。
2. 直接寻址
特征:地址字段直接给出操作数地址
已知:
D = 2000H
主存[2000H] = 0032H
指令示例
MOV R1, 2000H
结果
EA = 2000H
操作数 = 主存[2000H]
3. 间接寻址
特征:地址字段中存放的是“地址的地址”
已知:
D = 2000H
主存[2000H] = 3000H
主存[3000H] = 0032H
指令示例
MOV R1, @2000H
结果
EA = 3000H
操作数 = 主存[3000H]
4. 寄存器寻址
特征:操作数在寄存器中
已知:
R2 = 0015H
指令示例
ADD R1, R2
结果
操作数 = R2
5. 寄存器间接寻址
特征:寄存器中存放操作数地址
已知:
R3 = 4000H
主存[4000H] = 007AH
指令示例
MOV R1, (R3)
结果
EA = 4000H
操作数 = 主存[4000H]
6. 相对寻址
特征:以 PC 为基准,加偏移量
已知:
PC = 1000H
D = 20H
指令示例
BEQ 20H
结果
EA = PC + D = 1020H
7. 变址寻址(Rx)
特征:以变址寄存器 Rx 为基准
已知:
Rx = 2000H
D = 0004H
指令示例
MOV R1, 4(Rx)
结果
EA = Rx + D = 2004H
8. 基址寻址
特征:以基址寄存器 BR 为基准
已知:
BR = 8000H
D = 0100H
指令示例
MOV R1, 100H(BR)
结果
EA = BR + D = 8100H
9. 堆栈寻址
特征:操作数位置隐含在栈顶
已知:
SP = 5000H
主存[5000H] = 0012H
指令示例
POP R1
结果
EA = SP
操作数 = 主存[SP]
横向快速对照
| 寻址方式 | 操作数在哪 |
|---|---|
| 立即 | 指令中 |
| 直接 | 主存 D |
| 间接 | 主存 (D) |
| 寄存器 | 寄存器 |
| 寄存器间接 | 主存 [R] |
| 相对 | 主存 [PC+D] |
| 变址 | 主存 [Rx+D] |
| 基址 | 主存 [BR+D] |
| 堆栈 | 主存 [SP] |
好,这一章其实特别适合用“小场景”来理解,不然一堆寄存器名字确实容易糊在一起。
我按你前面的风格来:不堆概念,用“什么时候它在干嘛”+ 一个超短例子。
第六章 中央处理器(寄存器角色版)
我们假设 CPU 正在执行一条指令:
MOV R1, 2000H
1 程序计数器 PC
它什么时候出场?
取指之前,一定先看 PC
它干嘛?
-
告诉 CPU:下一条指令在哪
-
取完一条指令后:
- 顺序执行 → 自动加指令长度
- 跳转指令 → 被新地址覆盖
小例子
已知:
PC = 1000H
执行流程:
- CPU 去主存 1000H 取指令
- 取完后:
PC ← 1000H + 指令长度
如果是跳转指令:
PC ← 3000H
PC 就是 CPU 的“阅读进度条”。
2 地址寄存器 AR
它什么时候出场?
只要要访问主存,就一定会用 AR
它干嘛?
- 暂存“这次要访问的主存地址”
- 位宽 = 地址总线宽度(能装下完整地址)
小例子
执行:
MOV R1, 2000H
流程中:
AR ← 2000H
然后:
- 主存根据 AR 给出对应单元
AR 是 CPU 给主存递的“门牌号”。
3数据寄存器 DR
它什么时候出场?
主存 ↔ CPU 之间传数据时
它干嘛?
- 暂存从主存读出的数据
- 或准备写回主存的数据
- 位宽 = 机器字长
小例子
主存中:
主存[2000H] = 0032H
执行:
MOV R1, 2000H
过程:
AR ← 2000H
DR ← 主存[2000H]
R1 ← DR
DR 是 CPU 和主存之间的“中转箱”。
4 指令寄存器 IR
它什么时候出场?
取指之后,执行之前
它干嘛?
- 保存“当前正在执行的指令”
- 指令送到控制器译码
小例子
取指阶段:
IR ← 主存[PC]
例如:
IR = MOV R1, 2000H
接下来:
- 控制器分析 IR
- 决定用哪些寄存器、发哪些控制信号
IR 是 CPU 手里正在看的那一条指令。
顺序表
| 阶段 | 谁最关键 | 在干嘛 |
|---|---|---|
| 取指 | PC → AR→M→DR→IR | 找指令、拿指令 |
| 译码 | IR | 分析要干什么 |
| 访存 | AR → DR | 取/存数据 |
| 执行 | 通用寄存器/ALU | 真正算 |
一条指令里的完整串联(重点)
PC → AR → 主存 → IR
IR → 控制器
AR → 主存 → DR → 寄存器
PC ← PC + 指令长度
第七章
一、微程序控制思想
将控制信号编码为微指令,若干微指令组成微程序,存于控制存储器中。
二、核心概念
| 名称 | 含义 |
|---|---|
| 微命令 | 控制信号 |
| 微操作 | 基本硬件操作 |
| 微指令 | 相容微命令集合 |
| 微程序 | 实现一条机器指令 |
三、微指令周期
一个微指令周期等于一个时钟周期。
四、微程序控制器组成
- 控制存储器
- 地址转移逻辑
- 微地址寄存器
Cache 三种相联方式:地址拆分通用总结
不管哪种相联方式,块内偏移一定存在
区别只在于:中间那一段到底叫不叫“行索引 / 组索引”
一、块内偏移(Offset)【三种方式完全一样】
用到的参数
- 块大小(B)
怎么算
\[\text{块内偏移位数} = \log_2(\text{块大小}) \]解决的问题
在已定位的 Cache 块中,访问哪一个字节
二、直接相联(Direct-Mapped)
地址结构
[ 区地址 Tag ][ 行索引 Line ][ 块内偏移 Offset ]行索引(Line)
用到的参数
- Cache 容量
- 块大小
怎么算
\[\text{Cache 行数} = \frac{\text{Cache 容量}}{\text{块大小}} \]\[\text{行索引位数} = \log_2(\text{Cache 行数}) \]解决的问题
主存块只能映射到 Cache 的某一固定行
区地址(Tag)
用到的参数
- 主存地址位数
- 行索引位数
- 块内偏移位数
怎么算
\[\text{Tag 位数} = \text{主存地址位数} - \text{行索引位数} - \text{块内偏移位数} \]解决的问题
判断该行中存放的是否是当前访问的主存块
三、全相联(Fully Associative)
地址结构
[ 区地址 Tag ][ 块内偏移 Offset ]⚠️ 没有行索引 / 组索引
区地址(Tag)
用到的参数
- 主存地址位数
- 块内偏移位数
怎么算
\[\text{Tag 位数} = \text{主存地址位数} - \text{块内偏移位数} \]解决的问题
Cache 中任意一行都可能存该主存块,需要用 Tag 全比较
特点
主存块可装入 Cache 的任意一行,冲突最少,硬件最复杂
四、组相联(Set-Associative)
地址结构
[ 区地址 Tag ][ 组索引 Set ][ 块内偏移 Offset ]
组索引(Set)
用到的参数
- Cache 容量
- 块大小
- 每组行数(n 路)
怎么算
\[\text{Cache 行数} = \frac{\text{Cache 容量}}{\text{块大小}} \]\[\text{组数} = \frac{\text{Cache 行数}}{n} \]\[\text{组索引位数} = \log_2(\text{组数}) \]解决的问题
主存块只能映射到某一组,但组内可放任意一行
区地址(Tag)
用到的参数
- 主存地址位数
- 组索引位数
- 块内偏移位数
3 怎么算
\[\text{Tag 位数} = \text{主存地址位数} - \text{组索引位数} - \text{块内偏移位数} \]
五、三种方式对比
相联方式 地址中间字段 冲突情况 硬件复杂度 直接相联 行索引 最多 最低 组相联 组索引 中等 中等 全相联 无 最少 最高
作业重点
第二章 第3题
3.(40分) 已知某C语言编译器中,浮点数表示采用IEEE754标准,变量i的定义如下:
float i = -20.75,试求出变量i在存储器中的存储格式(结果用十六进制给出)。
第四章
(一)
- (30分)某计算机系统使用半导体存储器构建主存,其数据线为64位,已知DRAM芯片规格为:256M×32位,若要组成32GB主存,按字节地址编址,并采用内存条的形式,问:
(1)该系统主存需要多少片DRAM芯片?
(2)若每个内存条为2G×64位,共需要多少内存条?每个内存条内需要多少片DRAM芯片?
(3)若要实现32GB主存的访问,地址线最少需要多少位?设主存地址首地址从0开始,其末地址是多少?(给出十六进制结果)
- (30分)某计算机字长32位,采用直接相联Cache,主存容量4MB,Cache数据存储体容量为4KB,块长度为8个字。
(1)画出直接相联映射方式下主存字节地址划分情况,并说明每个字段位数。
(2)设Cache初始状态为空,若CPU顺序访问(读取)0-99号单元,每次访问一个单元(一个字),并重复此操作10次,请计算Cache命中率。
3.(20分)已知Cache命中率为90%,主存访问时间为120ns,Cache访问时间为20ns:
(1)若CPU访问10000次,共有多少次未命中?
(2)平均访问时间是多少?
(3)若通过技术提升命中率至95%,系统效率为多少?
第五,六章 第1题
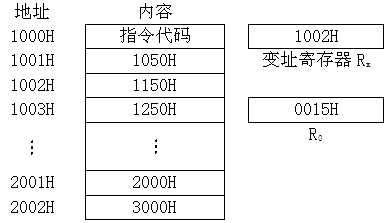
- (20分)设有一台计算机,其指令长度为16位,有一类RS型指令的格式:
其中,OP为操作码,占6位;R为寄存器编号,占2位,可访问4个不同的通用寄存器;MOD为寻址方式,占2位,与形式地址A一起决定源操作数,规定如下:
MOD=00,为立即寻址,A为立即数;
MOD=01,为相对寻址,A为位移量;
MOD=10,为变址寻址,A为位移量。
假定要执行的指令为加法指令,存放在1000H单元中,形式地址A的编码为01H,其中H表示十六进制数。该指令执行前存储器和寄存器的存储情况如图所示,假定此加法指令的两个源操作数中一个来自于形式地址A或者主存,另一个来自于目的寄存器R0,并且加法的结果一定存放在目的寄存器R0中。
在以下几种情况下,该指令执行后,R0和PC的内容为多少?
(1)若MOD=00,(R0)=__________。
(2)若MOD=01,(R0)=__________。
(3)若MOD=10,(R0)=; (PC)=。
- (40分)某单总线结构的计算机框图如下图所示如下所示。指令“sub rd,rs,rt”的功能为“R[rd] ← R[rs] - R[rt]”,即把寄存器Rrs和Rrt的值相减,结果存入寄存器Rrd。
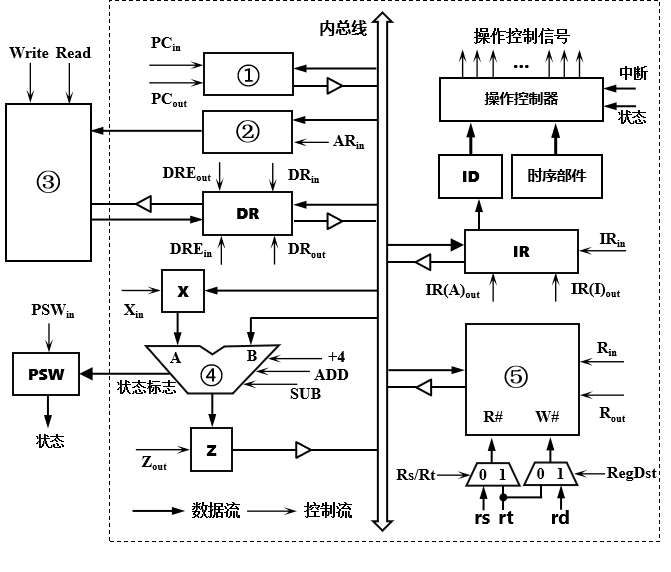
(1)分析CPU的数据流和控制流,给出①②③④⑤的部件名称;
(2)给出指令取指周期的数据通路;
(3)请画出指令“sub rd,rs,rt”执行部分的流程图,包括数据流和控制流。.(40分)某单总线结构的计算机框图如下图所示如下所示。指令“sub rd,rs,rt”的功能为“R[rd] ← R[rs] - R[rt]”,即把寄存器Rrs和Rrt的值相减,结果存入寄存器Rrd。
(1)分析CPU的数据流和控制流,给出①②③④⑤的部件名称;
(2)给出指令取指周期的数据通路;
(3)请画出指令“sub rd,rs,rt”执行部分的流程图,包括数据流和控制流。
- 会问给出一条指令问他的操作数,寻址方式
不在作业听说是重点的
题目
【练习】已知机器字长16位,指令格式如下所示:
(指令格式:15-10位为OP(6位),9-8位为X(2位),7-0位为D(8位))
格式中D为形式地址,X为寻址方式特征值:
- X=00,直接寻址;
- X=01,用变址寄存器 \(R_X\) 进行变址;
- X=11,相对寻址;
- X=10,用基址寄存器 \(R_B\) 进行寻址。
设 \((PC)=2000H\),\((R_X)=0150H\),\((R_B)=1889H\),请确定如下指令的有效地址:(设EA位数=机器字长)
指令:
(1) 4420H
(2) 2244H
(3) 730AH
(4) 3566H
(5) 6783H
答案
【解】:
1)X=00,D=20H,有效地址 \(EA=20H\)
2)X=10,D=44H,有效地址 \(EA=1889H+44H=18CDH\)
3)X=11,D=0AH,有效地址 \(EA=2000H+0AH=200AH\)
4)X=01,D=66H,有效地址 \(EA=0150H+66H=01B6H\)
5)X=11,D=83H,有效地址 \(EA=2000H+FF83H=1F83H\)
解析
一、通用分析方法
指令字长为16位,结构如下:
- 位 15~10:OP(6位)
- 位 9~8:X(2位,寻址方式)
- 位 7~0:D(8位,形式地址)
解析步骤固定为:
- 将指令写成二进制或按十六进制拆分
- 取出 X,判断寻址方式
- 取出 D(低8位)
- 根据寻址方式计算有效地址 EA
注意:
- EA 位数等于机器字长(16位)
- 相对寻址时,D 需要符号扩展
二、各指令详细解析
(1)4420H
十六进制拆分:
\[4420H = 0100\ 0100\ 0010\ 0000_2 \]
- X 位(9–8):
00→ 直接寻址- D 位(7–0):
20H直接寻址规则:
\[EA = D \]因此:
\[EA = 20H \]
(2)2244H
拆分:
\[2244H = 0010\ 0010\ 0100\ 0100_2 \]
- X =
10→ 基址寻址- D =
44H基址寻址规则:
\[EA = (R_B) + D \]已知:
\[(R_B)=1889H \]计算:
\[EA = 1889H + 44H = 18CDH \]
(3)730AH
拆分:
\[730AH = 0111\ 0011\ 0000\ 1010_2 \]
- X =
11→ 相对寻址- D =
0AH相对寻址规则:
\[EA = (PC) + \text{符号扩展}(D) \]因为
0AH最高位为 0,是正数:\[\text{符号扩展}(0AH)=000AH \]已知:
\[(PC)=2000H \]计算:
\[EA = 2000H + 0AH = 200AH \]
(4)3566H
拆分:
\[3566H = 0011\ 0101\ 0110\ 0110_2 \]
- X =
01→ 变址寻址- D =
66H变址寻址规则:
\[EA = (R_X) + D \]已知:
\[(R_X)=0150H \]计算:
\[EA = 0150H + 66H = 01B6H \]
(5)6783H
拆分:
\[6783H = 0110\ 0111\ 1000\ 0011_2 \]
- X =
11→ 相对寻址- D =
83H注意:
83H的二进制为1000 0011,最高位为 1,表示负数进行 8 位补码符号扩展:
\[83H \rightarrow FF83H \]相对寻址公式:
\[EA = (PC) + \text{符号扩展}(D) \]代入:
\[EA = 2000H + FF83H = 1F83H \]
总结(考试快速判断)
- X=00:\(EA=D\)
- X=01:\(EA=(R_X)+D\)
- X=10:\(EA=(R_B)+D\)
- X=11:\(EA=(PC)+\text{符号扩展}(D)\)
相对寻址一定要看 D 的最高位是否为 1
下面给出保留题面 + 完整解析。
解析部分全部使用 Markdown 引用格式,涉及计算统一用 $ / $$,便于你整理到笔记中。
题目信息
【课堂练习】已知机器字长32位,指令格式为单字长双地址RS型指令。其中:
- Rd、Rs为通用寄存器;
- 目标操作数采用寄存器寻址方式;
- MOD表示源操作数寻址方式;
- A为形式地址。
指令格式的位分配(32位):
- 31~27位:OP(操作码字段)
- 26~23位:Rd(目标寄存器字段)
- 22~20位:MOD(源操作数寻址方式字段)
- 19~16位:Rs(源寄存器字段)
- 15~0位:A(形式地址字段)
试分析:
(1)该指令模型中最多有多少条指令?[填空1]
(2)通用寄存器有多少个?[填空2]
(3)能达到最大的寻址空间是多少?0---[填空3]
解析
一、指令条数的分析(填空1)
指令条数由 操作码 OP 字段的位数 决定。
已知:
- OP 位于 31~27 位
- 位数为:
\[31 - 27 + 1 = 5 \text{ 位} \]因此,最多可表示的操作码种类为:
\[2^5 = 32 \]即:
最多有 32 条不同的指令
【填空1】\(32\)
二、通用寄存器数量的分析(填空2)
通用寄存器的数量由 寄存器字段位数 决定。
已知:
- Rd:26~23 位,共 4 位
- Rs:19~16 位,共 4 位
无论是 Rd 还是 Rs,它们都来自同一组通用寄存器。
因此,通用寄存器个数为:
\[2^4 = 16 \]【填空2】\(16\)
三、最大寻址空间的分析(填空3)
寻址空间大小由 形式地址 A 的位数 决定。
已知:
- A 占 15~0 位
- 位数为:
\[15 - 0 + 1 = 16 \text{ 位} \]可表示的地址范围为:
\[0 \sim 2^{16}-1 \]即:
\[0 \sim 65535 \]若用十六进制表示:
\[0 \sim FFFFH \]【填空3】\(2^{16}-1;(=65535;=;FFFFH)\)
最终答案汇总
- 【填空1】\(32\)
- 【填空2】\(16\)
- 【填空3】\(2^{16}-1\)(即 \(65535\),或 \(FFFFH\))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号