面向对象设计与构造第一单元博客作业
第一次作业总结
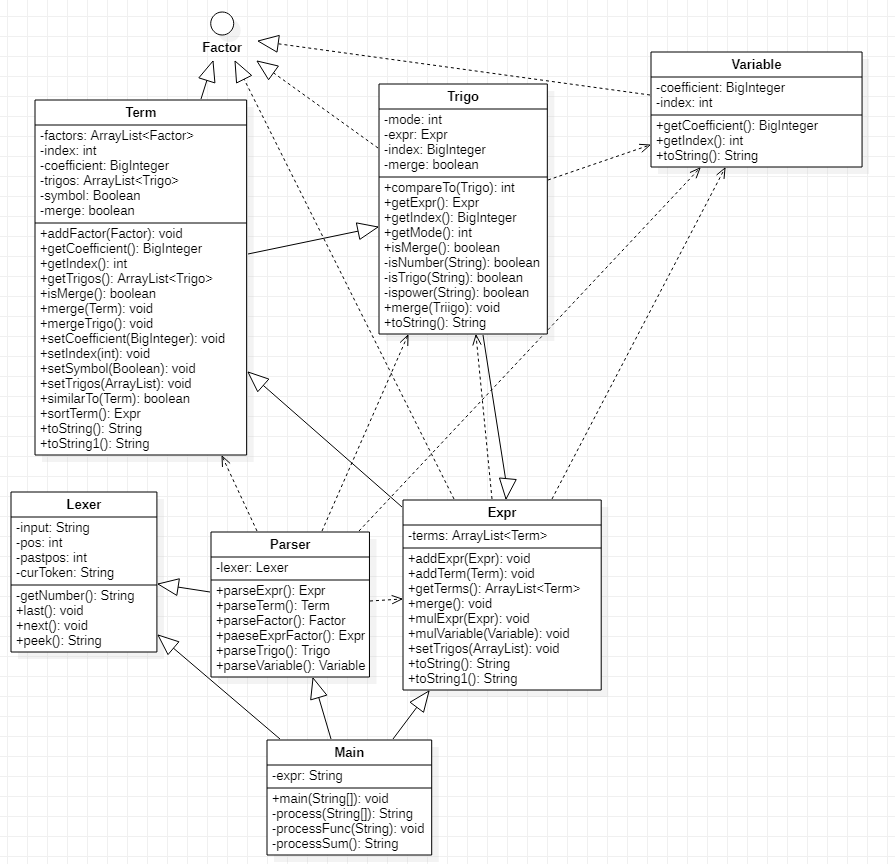
UML 图与类结构
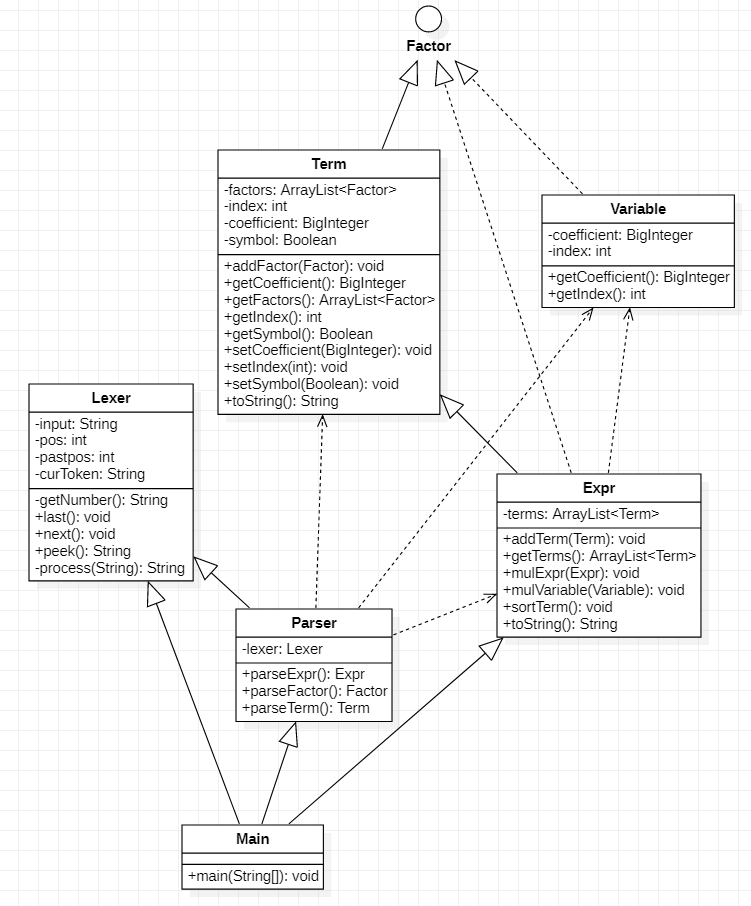
-
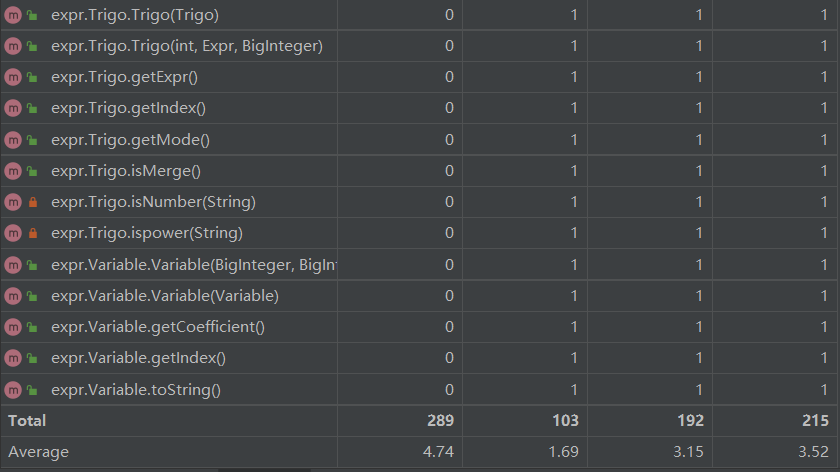
各个类的含义如下:
|- Main:主类
|- expr(package):表达式包
|- Factor (interface):因子接口
|- Variable:变量因子类(幂函数和常数因子的合并类)
|- Expr:表达式类
|- Term:项类
|- parser(package):表达式解析包
|- Lexer:词法分析类
|- Parser:语法分析类 -
parser包参考第一次课上实验采用递归下降解析表达式;Term类负责将储存的因子化简成标准项的形式,即形如
coefficient*x**index;Expr负责将储存的项合并并输出。 -
优点:主类负责数据的输入输出,parser包负责表达式解析,expr包负责表达式化简,结构简洁美观。
缺点:对表达式的处理基本都放在Term和Expr中,随着需求的增加,会使两个类变得臃肿庞大。
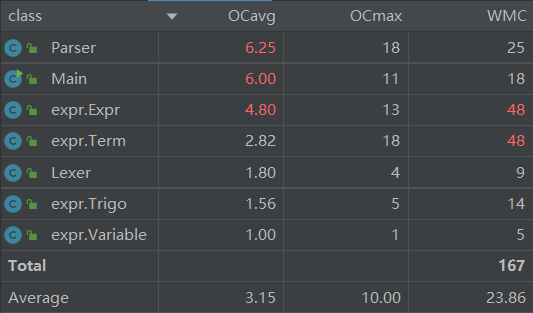
基于度量的结构分析
-
代码规模分析
-
![]()
-
第一次作业较为简单,整体代码量较小,也没有臃肿庞大的类
-
-
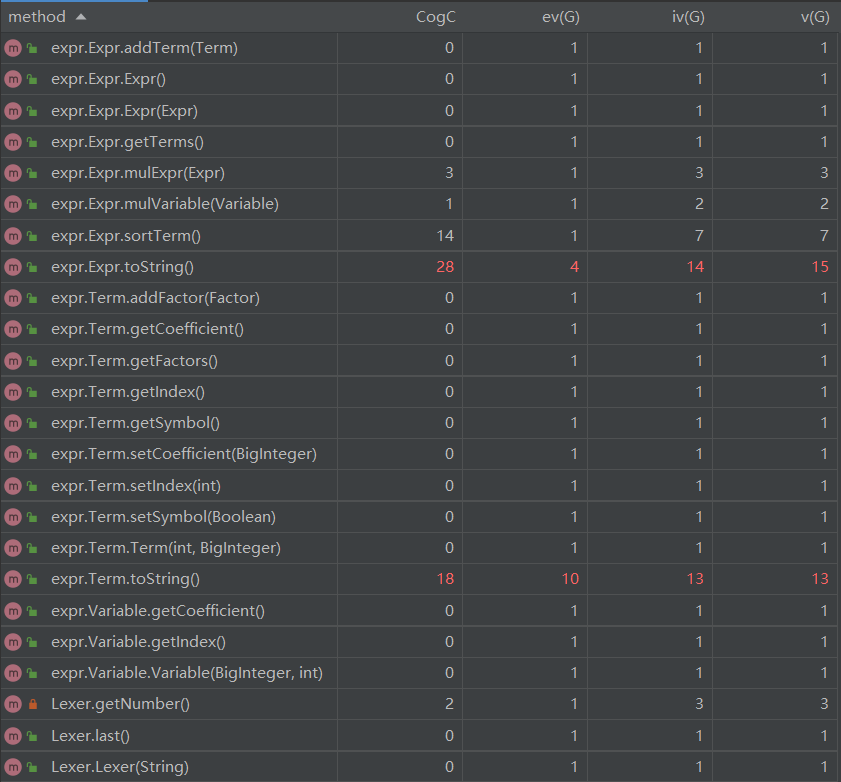
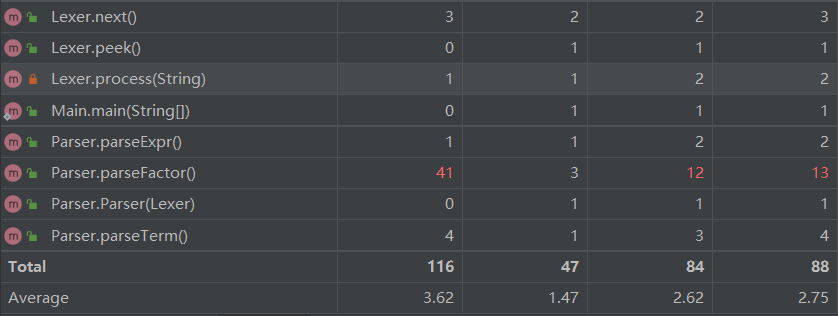
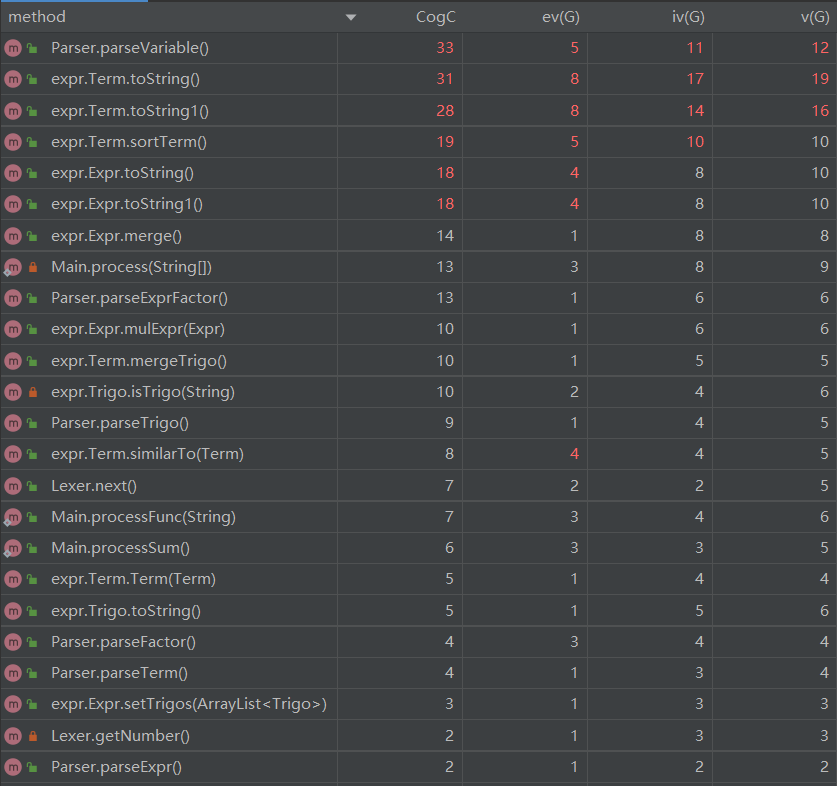
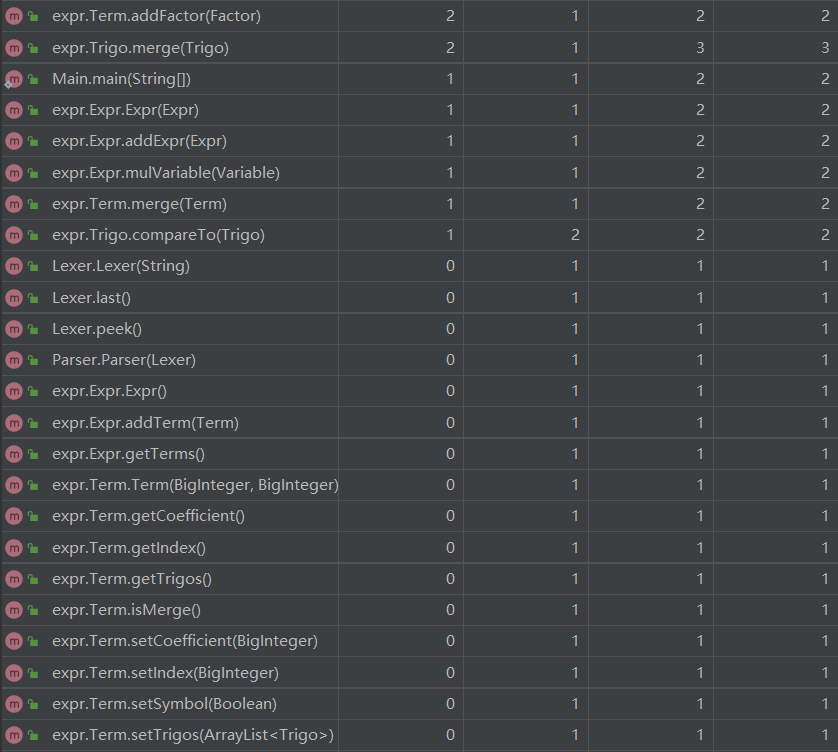
方法复杂度分析

-
-
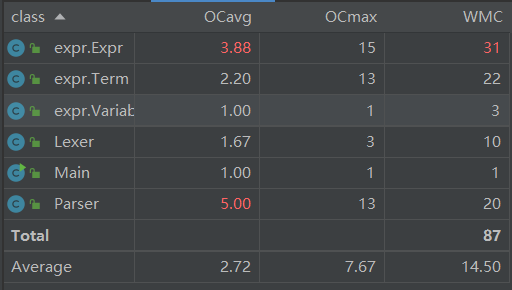
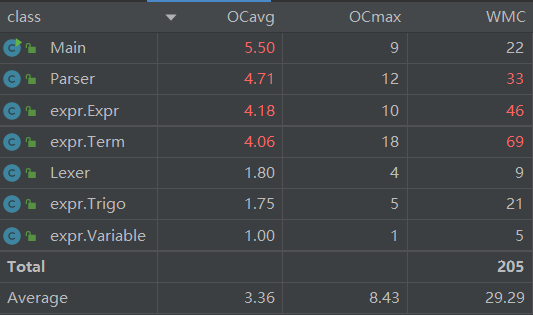
类复杂度分析
-
![]()
-
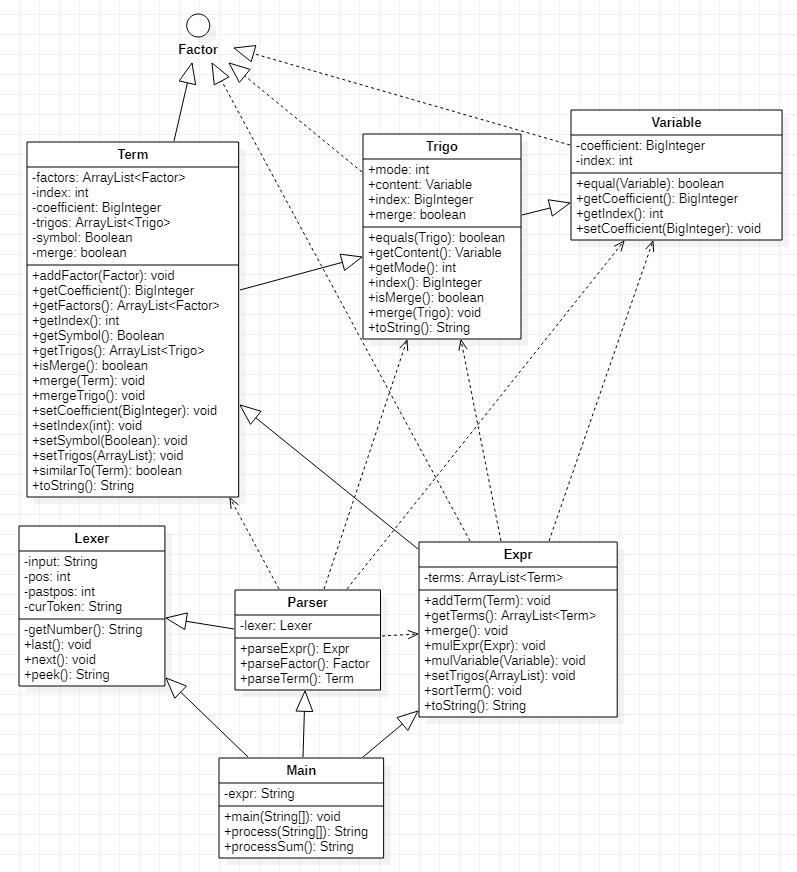
平均操作复杂度较高的是Parser类,主要是parseFactor方法包含三类因子的解析且对指数的判断较复杂
-
加权方法复杂度较高的是Expr类,主要是优化相关的方法拉高了复杂度。
-
BUG分析
-
课下出现的bug
-
Parser类解析指数时可能出现元素缺失
-
-
强测和互测出现的bug
-
本次强测和互测均未出现bug
-
-
bug出现在最复杂的类的最复杂的方法中,越复杂,越容易出bug。
Hack策略
本次未采用自动化测试,用来Hack的数据一方面来自于自己出现的bug,另一方面则是针对该同学所做的优化进行Hack。
第二次作业总结
UML图与类结构
-
![]()
-
各个类的含义如下:
|- Main:主类
|- expr(package):表达式包
|- Factor (interface):因子接口
|- Variable:变量因子类(幂函数和常数因子的合并类)
|- Trigo:三角函数类
|- Expr:表达式类
|- Term:项类
|- parser(package):表达式解析包
|- Lexer:词法分析类
|- Parser:语法分析类 -
parser包采用递归下降解析表达式;Term类负责将储存的因子化简成标准项的形式,即形如
coefficient*x**index*sin(Variable)**index*cos(Variable)**index;Expr负责将储存的项合并并输出。 -
优点:整体结构沿用第一次作业,仅仅增加了三角函数类,通过扩充项类和表达式类的功能满足新增的需求,迭代简单。
缺点:Term和Expr类功能过多,特别是优化部分使得内部逻辑较为混乱,有强行拼凑的嫌疑。
基于度量的结构分析
-
代码规模分析
-
![]()
-
新增三角函数、自定义函数以及求和函数因子,代码量几乎翻倍,除了新增类之外,主要是Expr和Term类代码量的增加,但还不算臃肿庞大。
-
-
方法复杂度分析
-
![]()
![]()
![]()
-
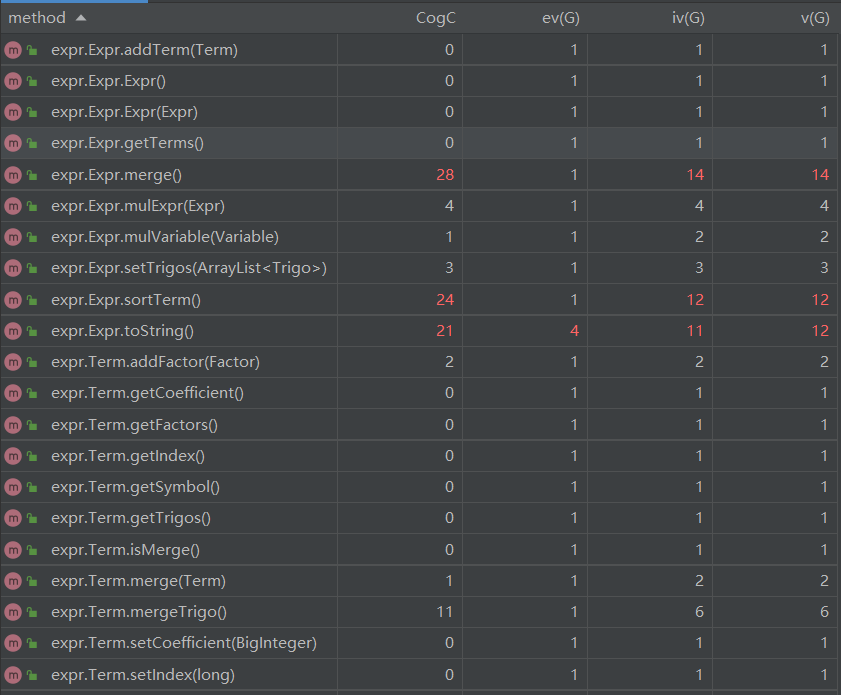
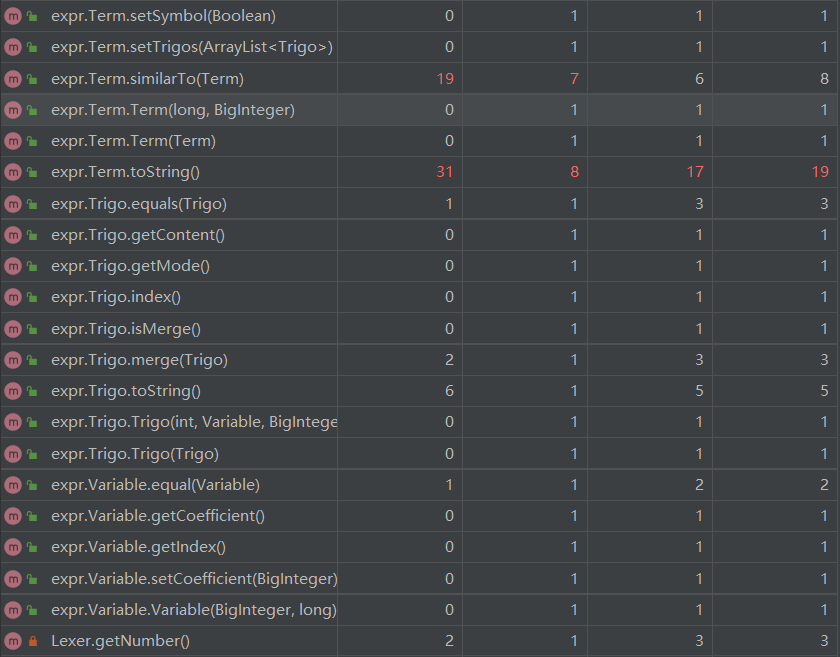
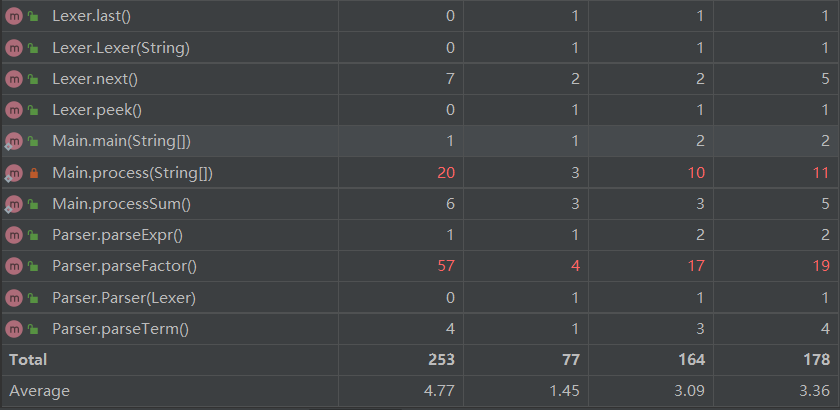
最大的方法依旧是parseFactor,增加了解析三角函数的功能,加之指数问题没有解决,雪上加霜
-
其余的方法都是化简优化相关,Expr中有Term的ArrayList,Term中有Factor和Trigo的ArrayList,遍历时需要多层for循环,除非改变储存结构,否则这个问题难以避免。
-
-
类复杂度分析
-
![]()
-
Parser和Expr的复杂度较高是作业一遗留问题未解决加之新增三角函数的解析和化简的结果。
-
Main主类的复杂度猛增的原因则是我偷懒地想要在预处理中采用字符串替换的方式解决新增的的自定义函数和求和函数的问题。
尽管事实证明这样并不能偷懒,只会带来诸多bug,这也是我第一单元最后悔做的事。
-

BUG分析
-
课下出现的bug
-
主要出现在对自定义函数和求和函数的字符串替换上
-
函数内的表达式带括号无法成功匹配
-
sum内的表达式带sin导致变量i替换出现问题
-
自定义函数类似于f(y,x)的结构时,先替换y再替换x出现问题
-
-
关于深克隆、浅克隆的问题
-
-
强测和互测出现的bug
-
使用
sin(-x)=-sin(x)化简时未考虑指数的奇偶性,出现sin(-x)**2=-sin(x)**2的问题 -
形如sin(0)**0错误的化简为0
-
-
此次bug层出不穷,前前后后交了九次加之助教gg开放了我错误的测试点才勉强通过中测,虽然侥幸通过强测,互测还是被找出来两个bug。一方面是因为自己采用字符串替换处理自定义函数和求和函数,但考虑不全面;另一方面则是浅克隆问题广泛存在。最重要的是toString函数内存在一个致命bug,让我的调试过程饱受折磨,尽管修改过程中稀里糊涂地避免掉这个bug带来的问题,但它依旧存在着,并在第三次作业中继续折磨我。种种因素堆积,不仅让我此次作业痛苦不堪,也让我没有精力做过多的优化,属实是自作自受了。
Hack策略
本次采用自动化测试随机轰炸加定点爆破。随机轰炸主要是从数据的复杂性来Hack;定点爆破则是针对易错点构造bug,包括自己出现的bug和该同学所做的优化进行Hack。
第三次作业总结
UML图与类结构
-
![]()
-
各个类的含义如下:
|- Main:主类
|- expr(package):表达式包
|- Factor (interface):因子接口
|- Variable:变量因子类(幂函数和常数因子的合并类)
|- Trigo:三角函数类
|- Expr:表达式类
|- Term:项类
|- parser(package):表达式解析包
|- Lexer:词法分析类
|- Parser:语法分析类 -
parser包采用递归下降解析表达式;Term类负责将储存的因子化简成标准项的形式,即形如
coefficient*x**index*sin(Expr)**index*cos(Expr)**index;Expr负责将储存的项合并并输出。 -
优点:与第二次作业的结构完全一致,外部封装简洁明了;此次完全采用深克隆,而非像第二次那样强行绕开浅克隆导致的bug;化简逻辑较之第二次更加清晰,更加结构化。
缺点:内部逻辑更加庞大臃肿,有意识地梳理Expr类的功能,却导致Term承担过多。
基于度量的结构分析
-
代码规模分析
-
![]()
-
本次新增多层嵌套表达式和函数调用,因为之前采用的就是递归下降所以基本不用变动,甚至主要增加的内容是我为了区分三角函数内的x**2与三角函数外的x*x而重写了两边toString函数。
(操作简单但行为愚蠢)
-
-
方法复杂度分析
-
![]()
![]()
![]()
-
本次作业增量开发的任务很少,因此对原有架构进行了优化,只怪自己太过愚笨,对指数的处理醒悟太晚,否则进一步优化。
-
toString是一个贯穿三次作业的问题,其中还有一个致命的bug
-
-
类复杂度分析
-
![]()
-
类的数量从第一次作业到第二次作业增加一个Trigo,从第二次作业到第三次作业完全没变。一个很重要的原因就是被toString中的bug折磨三次作业,虚空debug到第三周才终于解决,在此耗费太多精力使我没有心思思考重构的问题,只能一路将错就错走下去。代价就是每个类逐渐变得臃肿庞大。
-

BUG分析
-
课下出现的bug
-
关于深克隆、浅克隆的问题
-
从第一次作业开始每次都折磨我的bug:为了让输出首项为正,我的Expr的toString采用先寻找一个正项输出然后将其remove的方法,导致我第二次作业调试时IDEA自动调用toString函数使得正常运行与调试结果不同,且调试中出现“莫名其妙”的缺项,最终关闭自动调用toString函数后勉强避免这个bug;到了第三次作业,我的化简过程调用了toString函数,使得这个bug无可避免,最终在nymgg的指导下找到了这个bug才最终解决问题。
-
-
强测和互测出现的bug
-
错误地对BigInteger使用了Integer.parseInt方法(第一次作业的遗留)
-
没有好好阅读指导书
-
自定义函数嵌套无法解析
-
求和函数内出现类似
i**2的结构导致表达式中出现常数的次幂无法解析
-
-
-
原有的结构基本完全胜任第三次作业的需求,出现的bug在仔细阅读指导书后完全可以避免,甚至只需要很少的修改,但奈何自己在虚空debug的过程中心态爆炸,最终结果不尽人意。
Hack策略
本次依旧采用自动化测试随机轰炸加定点爆破。
架构设计体验
我的架构设计最困难的时候在第一次作业,由于假期的pre学习了正则表达式,作业下发伊始便开始用正则表达式开始写,但整个过程如同在沼泽中行走,进展缓慢,最终决定用预解析完成第一次作业先拿到分数。当周四完成第一次实验后,get到了递归下降的用法,迅速进行了重构。说它失败吧,这次架构胜任了三次作业,仅仅在第二次作业时增加了三角函数类,迭代很成功;但也不能说它成功,由于后面完全沿用第一次的架构,导致每个类都在逐渐变得复杂。只能说一次定型有好有坏。
心得体会
收获:
-
面向对象的架构设计与编程思想
-
递归下降算法
-
评测机的编写,包括构造数据和自动化测试
-
体会程序的可扩展性与迭代开发
反思:
-
切切实实体会到了前面写下的bug带来的蝴蝶效应,第二单元要有意识去避免
-
不要试图偷懒!不要试图偷懒!不要试图偷懒!所有偷过的懒都会变成巴掌打在脸上
-
第三次是最简单的迭代,却也是第三次没有强测满分。人的精力有限,debug耗费的精力会在其他方面带来损失,写程序时要谨慎小心


 浙公网安备 33010602011771号
浙公网安备 33010602011771号