聊聊python中的UUID安全
前两天给python提了个关于UUID安全的PR被merge了,也算是成功给3.13+的python修了个小bug。UUID已经出到第8代了。这其中有一个跟其他迭代不相同的点是:UUID的迭代并不是对上一代的优化(UUIDv5和v6除外)而是针对不同的场景提出不同的更适合的新的生成算法。也就是说选用UUID算发的时候不是看谁版本数字大就选哪个,而是要根据场景进行选择。相应的,不同版本的UUID也有不同的安全隐患和攻击方式。python中UUID是标准库之一。直到目前最新版本的3.14+,他支持了UUIDv1-UUIDv8的所有接口(v2除外)。这篇文章我们会着重于审计python中生成不同版本UUID的生成逻辑,以及其对应的安全隐患。顺便纪念一下我这次给python提的PR
前置知识
UUID基础
UUID(Universally Unique Identifier)的概念和他的第1至4个版本(UUIDv1)是最初在RFC 4122里提出的。而UUIDv6,v7,v8则是在RFC 9562中被提出。众多版本里被大众所熟知的应该是它用于做token,验证码甚至是CTF竞赛里的flag内容的UUIDv4,和广泛用于现代数据库的UUIDv7。
任何版本的UUID都符合以下通式:
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
UUID是一个128位值,其中,M处代表版本(Version Field),N处代表变体(Variant Field)。具体参考:https://www.rfc-editor.org/rfc/rfc9562.html#name-variant-field 。其余位置则是由不同版本的UUID生成规则决定。
根据RFC标准。我们对UUID安全提出以下要求:

我们认为:UUID不应该被用作为敏感数据的内容,所以我们不需要保证UUID的安全。但是,对于特定版本的UUID(如UUIDv4),其设计具有足够的安全性,因此可以被用于敏感内容的存储。对于存储敏感信息的UUID,RFC提出如下要求:

我们需要保证他的两个性质。第一是不可预测“unguessable”,第二是不可碰撞“unique”。本文中,对于不同版本的UUID,我们只需攻破其中之一,我们就可以说:这个算法在此处不安全。这是本文中关于UUID安全的基本定义。这一切的前提是,有人在此处使用UUID存储敏感数据。假如实战中这个UUID的用处并不是敏感的,那么它安不安全也无所谓,就不在本文的讨论范畴里。
PRNG和CSPRNG
一般地,我们把随机数生成算法分为密码学上安全的伪随机数发生器(Cryptographically-Secure Pseudo-Random Number Generator)和(密码学上不安全的)伪随机数发生器(Pseudo-Random Number Generator)。前者的例子有环境噪声(os.urandom())后者的例子有MT19937(random.getrandbits())
PRNG相对于CSPRNG来说性能更高,但是一旦泄露了超过624*32个连续字节,就可以利用矩阵求解重建MT19937的生成器,从而预测下一个生成的随机数。而这也是本文中大部分攻击方式的起源。
明确了这些之后我们将分别审计python的标准库里不同版本的UUID的生成逻辑,我们开始:
python的UUID
UUID对象
首先,python中的不同版本的UUID生成函数最终都会返回一个UUID对象而不是字符串。这个对象大概是长这样的:
UUID(fields=(fields1, fields2, fields3, fields4, fields5, fields6), version=XXX)
这个对象被实例化后,python会将不同的fields值进行整合,并最终产生一串UUID。整合过程可以理解成规范化,即:将这些fields和版本信息分别填入128位的UUID字符串里,使其成为一个合法的UUID。整合过程中有几个关键点需要注意:
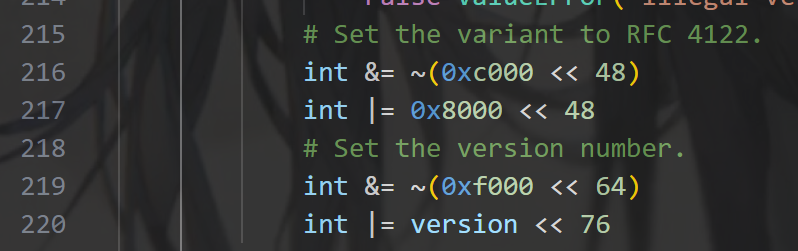
我们关注UUID对象的第216-220行。可以看到,python会通过位运算的方式,将M和N的值强行覆盖为版本和变体值填入。也就是说,在对应的fields里(field3和field4),这两个部分的高2位是无意义的(会被覆盖)所以你经常会看见fields里出现14位或者62位的bits长度(差两位成8的倍数)就是为了给这两个位置留空。
UUIDv1
UUIDv1是UUID的第一个版本,他是基于时间的(time-based)我们来看源代码:
def uuid1(node=None, clock_seq=None):
"""Generate a UUID from a host ID, sequence number, and the current time.
If 'node' is not given, getnode() is used to obtain the hardware
address. If 'clock_seq' is given, it is used as the sequence number;
otherwise a random 14-bit sequence number is chosen."""
# When the system provides a version-1 UUID generator, use it (but don't
# use UuidCreate here because its UUIDs don't conform to RFC 4122).
if _generate_time_safe is not None and node is clock_seq is None:
uuid_time, safely_generated = _generate_time_safe()
try:
is_safe = SafeUUID(safely_generated)
except ValueError:
is_safe = SafeUUID.unknown
return UUID(bytes=uuid_time, is_safe=is_safe)
global _last_timestamp
import time
nanoseconds = time.time_ns()
# 0x01b21dd213814000 is the number of 100-ns intervals between the
# UUID epoch 1582-10-15 00:00:00 and the Unix epoch 1970-01-01 00:00:00.
timestamp = nanoseconds // 100 + 0x01b21dd213814000
if _last_timestamp is not None and timestamp <= _last_timestamp:
timestamp = _last_timestamp + 1
_last_timestamp = timestamp
if clock_seq is None:
import random
clock_seq = random.getrandbits(14) # instead of stable storage
time_low = timestamp & 0xffffffff
time_mid = (timestamp >> 32) & 0xffff
time_hi_version = (timestamp >> 48) & 0x0fff
clock_seq_low = clock_seq & 0xff
clock_seq_hi_variant = (clock_seq >> 8) & 0x3f
if node is None:
node = getnode()
return UUID(fields=(time_low, time_mid, time_hi_version,
clock_seq_hi_variant, clock_seq_low, node), version=1)
我们可以发现:UUIDv1的fields里。time_low,time_mid,time_hi_version本质上是时间戳+版本,而node是MAC地址,clock_seq_hi_variant和clock_seq_low是随机产生的14位值(留两位给变体值)。
node的生成逻辑在getnode()里,我们来看:
def getnode():
"""Get the hardware address as a 48-bit positive integer.
The first time this runs, it may launch a separate program, which could
be quite slow. If all attempts to obtain the hardware address fail, we
choose a random 48-bit number with its eighth bit set to 1 as recommended
in RFC 4122.
"""
global _node
if _node is not None:
return _node
for getter in _GETTERS + [_random_getnode]:
try:
_node = getter()
except:
continue
if (_node is not None) and (0 <= _node < (1 << 48)):
return _node
assert False, '_random_getnode() returned invalid value: {}'.format(_node)
看注释。当获取MAC地址失败时,我们会随机生成48bit的node填入。这是因为有时候我们会出现一些不希望泄露MAC地址的情况,python则会调用_random_getnode()函数,随机生成48位node填入。代码如下:
def _random_getnode():
"""Get a random node ID."""
# RFC 4122, $4.1.6 says "For systems with no IEEE address, a randomly or
# pseudo-randomly generated value may be used; see Section 4.5. The
# multicast bit must be set in such addresses, in order that they will
# never conflict with addresses obtained from network cards."
#
# The "multicast bit" of a MAC address is defined to be "the least
# significant bit of the first octet". This works out to be the 41st bit
# counting from 1 being the least significant bit, or 1<<40.
#
# See https://en.wikipedia.org/wiki/MAC_address#Unicast_vs._multicast
import random
return random.getrandbits(48) | (1 << 40)
但是在RFC 9562里我们能看到:

也就是说:我们应该使用CSPRNG来生成node。而在现版本的python中我们使用了PRNG。这已经在我的PR中被修改为CSPRNG。node字段生成一次后就会缓存,因此升级为CSPRNG对性能影响不大。
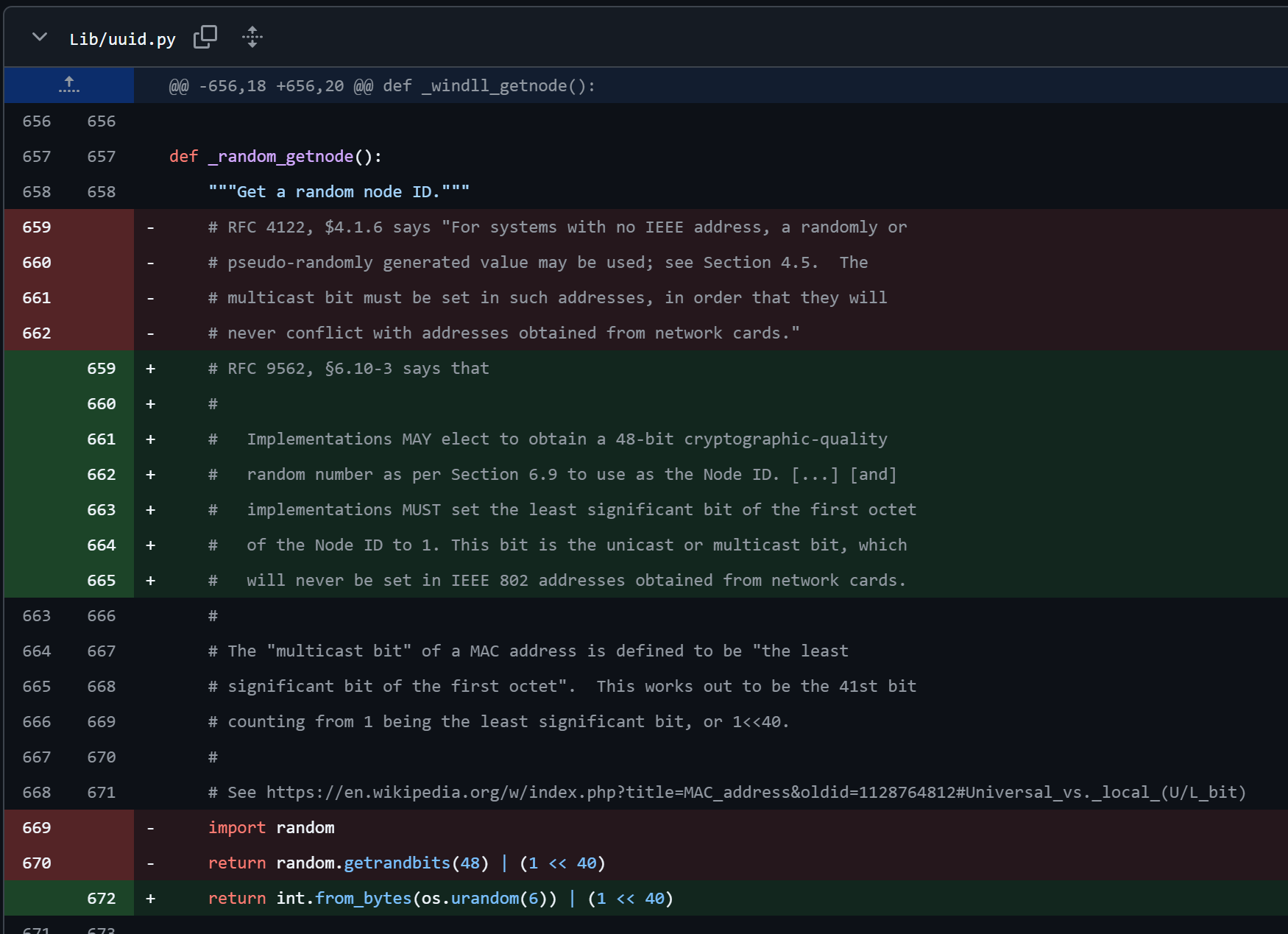
当我们收集到第一个UUIDv1时,MAC地址就已知了。由于MAC地址不会发生变化,所以后面的UUID的node字段是永远相同的。那么这一段就可预测。也就是说,我们不可预测的就只剩下了clock_seq的那两个字段和时间字段。
clock_seq的生成逻辑如下:
if clock_seq is None:
import random
clock_seq = random.getrandbits(14) # instead of stable storage
但对于随机生成的clock_seq参数。我检查了其他语言的生成逻辑,发现基本用的是CSPRNG,唯独python出于性能考虑(从最新版python的benchmark来看,CSPRNG比PRNG慢25倍)仍然用PRNG。那么一次UUIDv1就会泄露14个字节,根据MT19937的攻击方式。我们需要连续624*32//(14)+1=1427次泄露就可以预测下一个生成的clock_seq。
为了提取clock_seq中随机生成的14位字节,我们可能要对UUID进行一些处理。我们需要将高2位的变体字节抹去。提取脚本:
def extract_clock_seq(uuid_val):
# RFC 4122
clock_seq_hi = uuid_val.fields[3] # clock_seq_hi_variant (8 字节)
clock_seq_low = uuid_val.fields[4] # clock_seq_low (8 字节)
return ((clock_seq_hi & 0x3f) << 8) | clock_seq_low
uuids = [uuid.uuid1() for _ in range(1427)] # 这里放我们收集的UUIDv1
clock_seqs = [extract_clock_seq(u) for u in uuids] # 这是服务器生成的随机数列表
随后,我们使用pyrandcrack求解矩阵即可:https://github.com/guoql666/pyrandcracker
那么就还剩一个基于时间的三个字段。
首先,这个时间戳是纳秒级别的。也就是说,我们要准确预测到受害者主机是在那个纳秒生成的这个UUID才有可能去预测。这显然是不可能的。那么我们就要引入一种攻击方式:Sandwhich Attack(以下简称SWATK)
顾名思义,SWATK的流程就是:先获取一个UUID,随后使受害主机生成目标UUID,之后再获取一个UUID。这样,目标UUID从时间维度上看就被我们已知的两个UUID夹在中间,所以叫Sandwhich Attack(笑)
通过已知的前后两个时间戳,我们可以划定目标UUID生成时间的大致范围,从而通过爆破进行预测。Hacktrick上有更详细的讲解:https://book.hacktricks.wiki/zh/pentesting-web/uuid-insecurities.html
对于SWATK有exp:https://github.com/Lupin-Holmes/sandwich
同时一篇关于UUIDv1安全实战的blog:https://www.landh.tech/blog/20230811-sandwich-attack/
注:这些blog中受攻击UUID的clock_seq字段为固定值,也就是说他们省去了我们刚刚讨论的攻击PRNG的一步。这在实战中几乎是不可能出现的。
因此对于python UUID1,我们的Attack flow大概是长这样的:
-
获取1427个连续生成的UUID,求解MT19937矩阵。解出
clock_seq对应的两个字段内容。 -
从上述样本中任取其一获取固定不变的MAC地址(或随机node)获取node字段的值。
-
分别获取目标UUID前后的两个UUID,实施SWATK攻击爆破位于中间的时间戳,求解time字段的值。
对于这个Attack flow,我在github上上传了一些更多的指引和解释:https://github.com/LamentXU123/cve/blob/main/UUID.md
UUIDv6
UUIDv6本质上是UUIDv1的优化版。代码:
def uuid6(node=None, clock_seq=None):
"""Similar to :func:`uuid1` but where fields are ordered differently
for improved DB locality.
More precisely, given a 60-bit timestamp value as specified for UUIDv1,
for UUIDv6 the first 48 most significant bits are stored first, followed
by the 4-bit version (same position), followed by the remaining 12 bits
of the original 60-bit timestamp.
"""
global _last_timestamp_v6
import time
nanoseconds = time.time_ns()
# 0x01b21dd213814000 is the number of 100-ns intervals between the
# UUID epoch 1582-10-15 00:00:00 and the Unix epoch 1970-01-01 00:00:00.
timestamp = nanoseconds // 100 + 0x01b21dd213814000
if _last_timestamp_v6 is not None and timestamp <= _last_timestamp_v6:
timestamp = _last_timestamp_v6 + 1
_last_timestamp_v6 = timestamp
if clock_seq is None:
import random
clock_seq = random.getrandbits(14) # instead of stable storage
time_hi_and_mid = (timestamp >> 12) & 0xffff_ffff_ffff
time_lo = timestamp & 0x0fff # keep 12 bits and clear version bits
clock_s = clock_seq & 0x3fff # keep 14 bits and clear variant bits
if node is None:
node = getnode()
# --- 32 + 16 --- -- 4 -- -- 12 -- -- 2 -- -- 14 --- 48
# time_hi_and_mid | version | time_lo | variant | clock_seq | node
int_uuid_6 = time_hi_and_mid << 80
int_uuid_6 |= time_lo << 64
int_uuid_6 |= clock_s << 48
int_uuid_6 |= node & 0xffff_ffff_ffff
# by construction, the variant and version bits are already cleared
int_uuid_6 |= _RFC_4122_VERSION_6_FLAGS
return UUID._from_int(int_uuid_6)
_last_timestamp_v7 = None
_last_counter_v7 = 0 # 42-bit counter
UUIDv6与UUIDv1唯一不同的点在于时间戳的处理方式。UUIDv1采用1582-10-15 00:00:00作为时间戳的起点。而UUIDv6则改回了经典的1970-01-01 00:00:00。另外,二者在时间戳的处理上也有区别。但是他们的攻击流程基本一样。只是在SWATK时我们需要简单调整一下算法。在这里不做赘述。
UUIDv8
UUIDv8相比起一套标准,它更像是一套概念。他是高度定制化的。python中的UUIDv8实现如下:
def uuid8(a=None, b=None, c=None):
"""Generate a UUID from three custom blocks.
* 'a' is the first 48-bit chunk of the UUID (octets 0-5);
* 'b' is the mid 12-bit chunk (octets 6-7);
* 'c' is the last 62-bit chunk (octets 8-15).
When a value is not specified, a pseudo-random value is generated.
"""
if a is None:
import random
a = random.getrandbits(48)
if b is None:
import random
b = random.getrandbits(12)
if c is None:
import random
c = random.getrandbits(62)
int_uuid_8 = (a & 0xffff_ffff_ffff) << 80
int_uuid_8 |= (b & 0xfff) << 64
int_uuid_8 |= c & 0x3fff_ffff_ffff_ffff
# by construction, the variant and version bits are already cleared
int_uuid_8 |= _RFC_4122_VERSION_8_FLAGS
return UUID._from_int(int_uuid_8)
其中,一个安全的项目都会自定义参数a,b和c。然而,假如服务器不输入任何参数,直接采用默认配置None(即,直接调用uuid.uuid8())那么可以说,python中的UUIDv8是极不安全的。因为其每一个部分都采用了伪随机数。而根据一次泄露126个字节来看。攻击者只需要获得159个连续生成的UUIDv8就可以完全预测下一个生成的UUID。 甚至不需要因为时间戳精度问题实施SWATK。我们可以说,不自定义的UUIDv8是相当危险的。
而大部分不熟悉UUID的开发者在选择UUID时大都会根据版本号大小选择。UUIDv8作为最新版的UUID,经常成为新手的选项。然而,在此处将PRNG换为CSPRNG将必须要忍受一个15625倍的性能降低!因此,python采用的是很好破解的MT19937算法。而在一次性泄露如此多字节的情况下,不自定义参数使用UUIDv8是相当危险的。
也因此,我在最新的python3.13+里修改了文档,声明了UUIDv8函数的不安全性。

UUIDv3 UUIDv5
def uuid3(namespace, name):
"""Generate a UUID from the MD5 hash of a namespace UUID and a name."""
if isinstance(name, str):
name = bytes(name, "utf-8")
import hashlib
h = hashlib.md5(namespace.bytes + name, usedforsecurity=False)
int_uuid_3 = int.from_bytes(h.digest())
int_uuid_3 &= _RFC_4122_CLEARFLAGS_MASK
int_uuid_3 |= _RFC_4122_VERSION_3_FLAGS
return UUID._from_int(int_uuid_3)
def uuid5(namespace, name):
"""Generate a UUID from the SHA-1 hash of a namespace UUID and a name."""
if isinstance(name, str):
name = bytes(name, "utf-8")
import hashlib
h = hashlib.sha1(namespace.bytes + name, usedforsecurity=False)
int_uuid_5 = int.from_bytes(h.digest()[:16])
int_uuid_5 &= _RFC_4122_CLEARFLAGS_MASK
int_uuid_5 |= _RFC_4122_VERSION_5_FLAGS
return UUID._from_int(int_uuid_5)
这两个算法在设计上都采用了很安全的哈希算法。uuid3和uuid5基于对一套固定输入的哈希值,因此每一个输入产生的UUIDv3都是固定的,UUIDv5也相同。它们之间的区别在于前者采用MD5,而后者采用sha1。
对这两个算法,除了老生常谈的哈希碰撞(爆破)和原始输入泄露之外我想不到攻击方式。
UUIDv4
最安全的UUID版本。
def uuid4():
"""Generate a random UUID."""
int_uuid_4 = int.from_bytes(os.urandom(16))
int_uuid_4 &= _RFC_4122_CLEARFLAGS_MASK
int_uuid_4 |= _RFC_4122_VERSION_4_FLAGS
return UUID._from_int(int_uuid_4)
采用了安全的随机数发生器,完全随机生成了一个UUID出来。这个真没得攻击了。
UUIDv7
def uuid7():
"""Generate a UUID from a Unix timestamp in milliseconds and random bits.
UUIDv7 objects feature monotonicity within a millisecond.
"""
# --- 48 --- -- 4 -- --- 12 --- -- 2 -- --- 30 --- - 32 -
# unix_ts_ms | version | counter_hi | variant | counter_lo | random
#
# 'counter = counter_hi | counter_lo' is a 42-bit counter constructed
# with Method 1 of RFC 9562, §6.2, and its MSB is set to 0.
#
# 'random' is a 32-bit random value regenerated for every new UUID.
#
# If multiple UUIDs are generated within the same millisecond, the LSB
# of 'counter' is incremented by 1. When overflowing, the timestamp is
# advanced and the counter is reset to a random 42-bit integer with MSB
# set to 0.
global _last_timestamp_v7
global _last_counter_v7
nanoseconds = time.time_ns()
timestamp_ms = nanoseconds // 1_000_000
if _last_timestamp_v7 is None or timestamp_ms > _last_timestamp_v7:
counter, tail = _uuid7_get_counter_and_tail()
else:
if timestamp_ms < _last_timestamp_v7:
timestamp_ms = _last_timestamp_v7 + 1
# advance the 42-bit counter
counter = _last_counter_v7 + 1
if counter > 0x3ff_ffff_ffff:
# advance the 48-bit timestamp
timestamp_ms += 1
counter, tail = _uuid7_get_counter_and_tail()
else:
# 32-bit random data
tail = int.from_bytes(os.urandom(4))
unix_ts_ms = timestamp_ms & 0xffff_ffff_ffff
counter_msbs = counter >> 30
# keep 12 counter's MSBs and clear variant bits
counter_hi = counter_msbs & 0x0fff
# keep 30 counter's LSBs and clear version bits
counter_lo = counter & 0x3fff_ffff
# ensure that the tail is always a 32-bit integer (by construction,
# it is already the case, but future interfaces may allow the user
# to specify the random tail)
tail &= 0xffff_ffff
int_uuid_7 = unix_ts_ms << 80
int_uuid_7 |= counter_hi << 64
int_uuid_7 |= counter_lo << 32
int_uuid_7 |= tail
# by construction, the variant and version bits are already cleared
int_uuid_7 |= _RFC_4122_VERSION_7_FLAGS
res = UUID._from_int(int_uuid_7)
# defer global update until all computations are done
_last_timestamp_v7 = timestamp_ms
_last_counter_v7 = counter
return res
从安全性上来讲,UUIDv7相比UUIDv1和UUIDv6采用了CSPRNG。这使得tail字段的随机性无懈可击。即使time-based的部分可能受到SWATK,但是在无法破解随机数发生器部分的前提下,这个算法是安全的。
UUIDv2
python标准库似乎不支持UUIDv2。v2同v1差不多,但是它将V1中的部分时间信息换成了主机名,有隐私风险。所以没有被python实现。
结语
最后分享一个搜资料的时候发现的很难绷的东西:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号