读取txt文件并生成词云图
读取txt文件并生成词云图
-
(一)下载第三方模块
2.jieba:是一个分词模块,因为我是从一个txt文本里提取关键词,所以需要 jieba 来分词并统计词频。如果是已经有了现成的数据,不再需要它。
pip install wordcloud pip install jieba
-
(二)WordCloud类的使用
-
WordCloud构造方法的参数 说明 font_path 字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = ‘黑体.ttf’ width 输出的画布宽度,默认为400像素 height 输出的画布高度,默认为200像素 prefer_horizontal 词语水平方向排版出现的频率,默认 0.9 (所以词语垂直方向排版出现频率为 0.1 ) mask 如果参数为空,则使用二维遮罩绘制词云。如果 mask 非空,设置的宽高值将被忽略,遮罩形状被 mask 取代。除全白(#FFFFFF)的部分将不会绘制,其余部分会用于绘制词云。如:bg_pic = imread(‘读取一张图片.png’),背景图片的画布一定要设置为白色(#FFFFFF),然后显示的形状为不是白色的其他颜色。可以用ps工具将自己要显示的形状复制到一个纯白色的画布上再保存。 scale 按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。 min_font_size 显示的最小的字体大小 font_step 字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差。 max_words 显示的词的最大个数 stopwords 设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS background_color 背景颜色,如background_color=‘white’,背景颜色为白色。 max_font_size 显示的最大的字体大小 mode 当参数为“RGBA”并且background_color不为空时,背景为透明。 relative_scaling 词频和字体大小的关联性 color_func 生成新颜色的函数,如果为空,则使用 self.color_func regexp 使用正则表达式分隔输入的文本 collocations 是否包括两个词的搭配 colormap 给每个单词随机分配颜色,若指定color_func,则忽略该方法。
数据准备
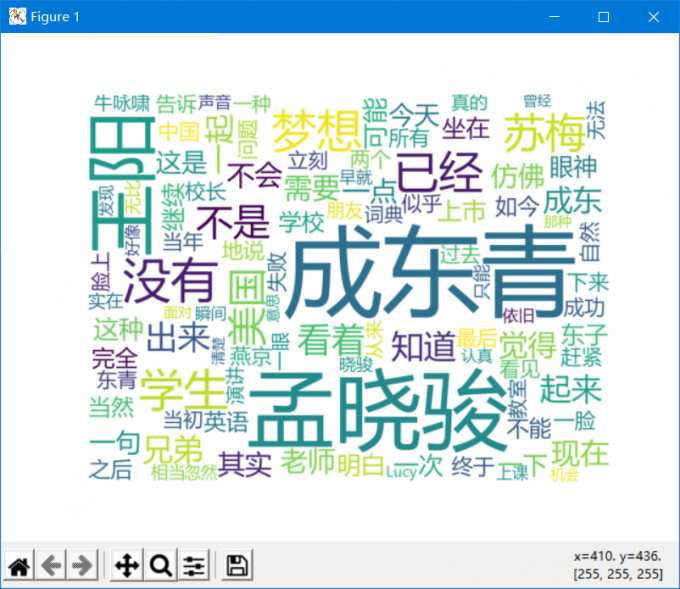
小说《中国合伙人1.txt》,约3400行 
源代码
import jieba import jieba.analyse import codecs import re from collections import Counter from wordcloud import WordCloud import matplotlib.pyplot as plt import wordcloud # 创建停用词列表 def stopwordlist(): stopwords = [line.strip() for line in open('../结巴分词/hit_stopwords.txt',encoding='UTF-8').readlines()] return stopwords # 对句子进行中文分词 def seg_depart(sentence): print('正在分词') sentence_depart = jieba.cut(sentence.strip()) # 创建一个停用词列表 stopwords = stopwordlist() # 输出结果为 outstr outstr = '' # 去停用词 for word in sentence_depart: if word not in stopwords: if word != '\t': outstr += word outstr += " " return outstr print("读取文件并生成词云图") def create_word_cloud(file): # 读取文件内容 content = codecs.open(file,'r','gbk').read() # 去停用词 content = seg_depart(content) # 结巴分词 wordlist = jieba.cut(content) wl = " ".join(wordlist) print(wl) # 配置词云图 wc = wordcloud.WordCloud( # 设置背景颜色 background_color='white', # 设置最大显示的词数 max_words=100, # 设置字体路径 font_path = 'C:\Windows\Fonts\msyh.ttc', height=1200, width=1600, # 设置字体最大值 max_font_size=300, # 设置有多少种配色方案,即多少种随机生成状态 random_state=50, ) # 生成词云图 myword = wc.generate(wl) # 展示词云图 plt.imshow(myword) plt.axis("off") plt.show() create_word_cloud("中国合伙人1.txt")
生成词云图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号