会员
周边
新闻
博问
闪存
众包
赞助商
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
L-mg
Powered by
博客园
博客园
|
首页
|
新随笔
|
联系
|
订阅
|
管理
学习进度三:实验 3 Spark 和 Hadoop 的安装
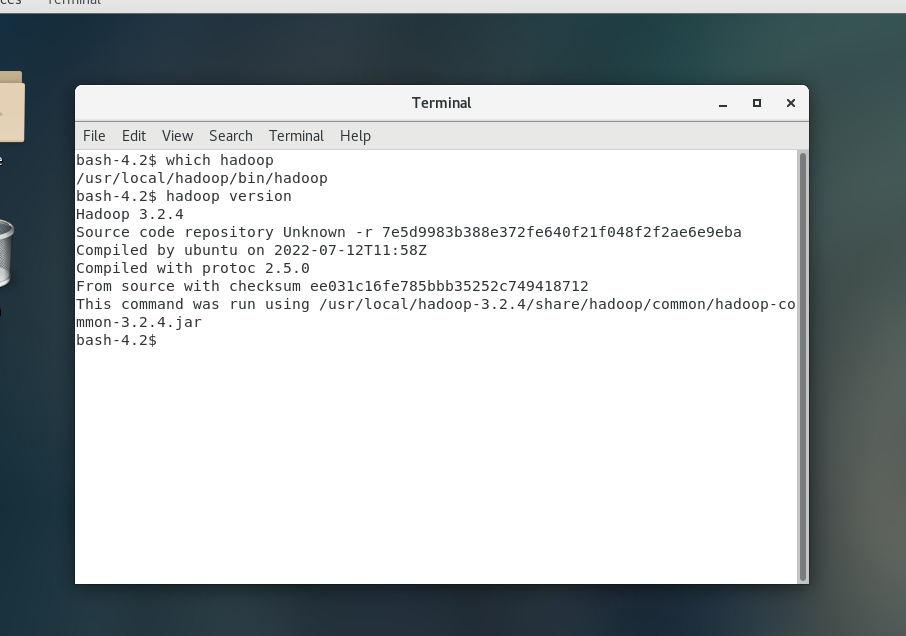
1.安装 Hadoop 和 Spark
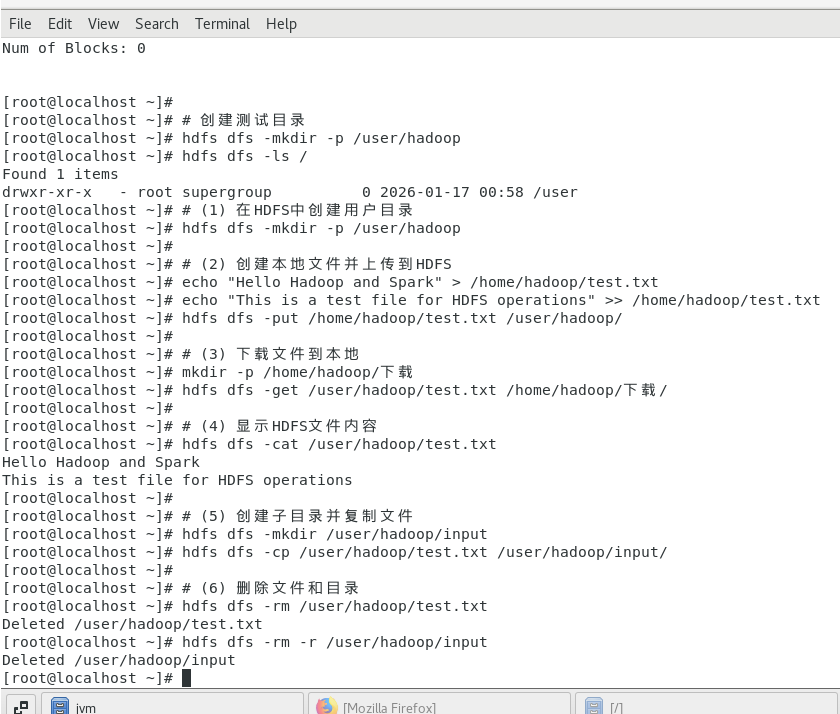
2.HDFS 常用操作
3. Spark 读取文件系统的数据
准备工作
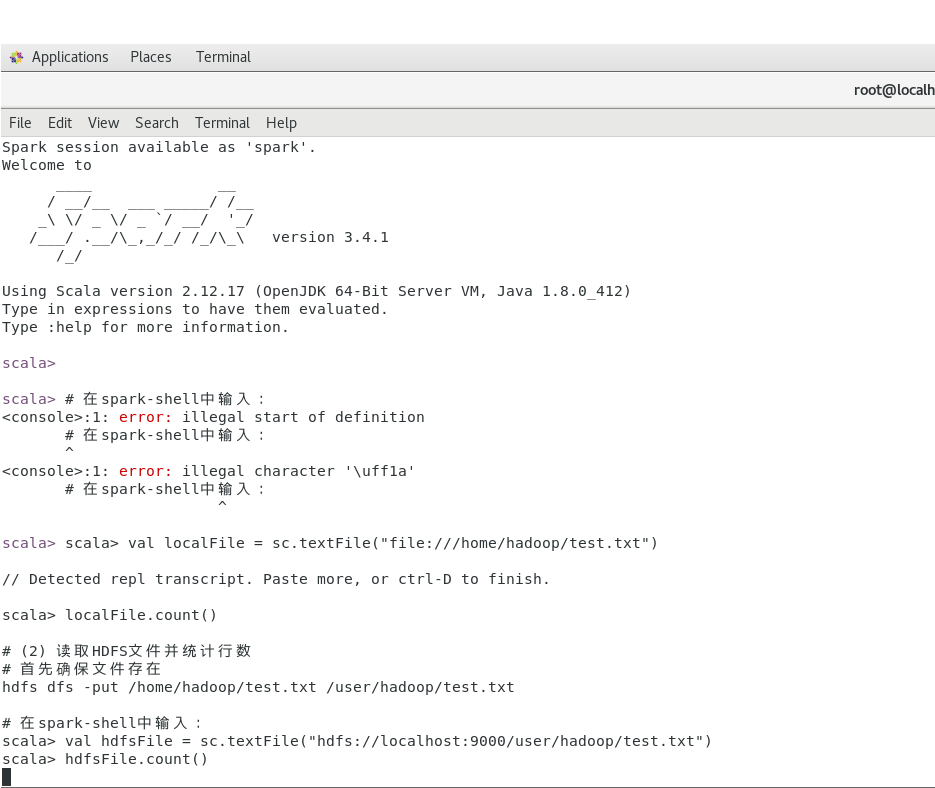
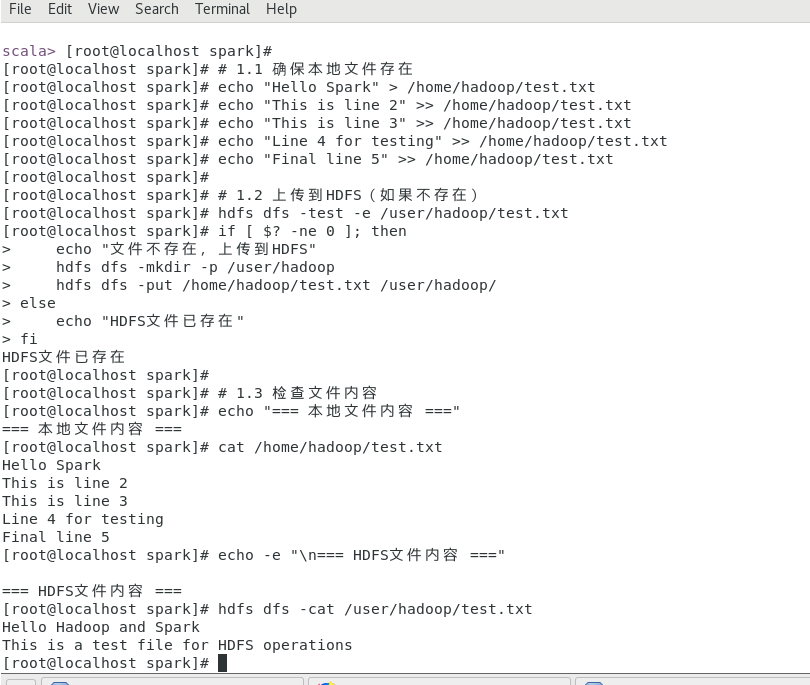
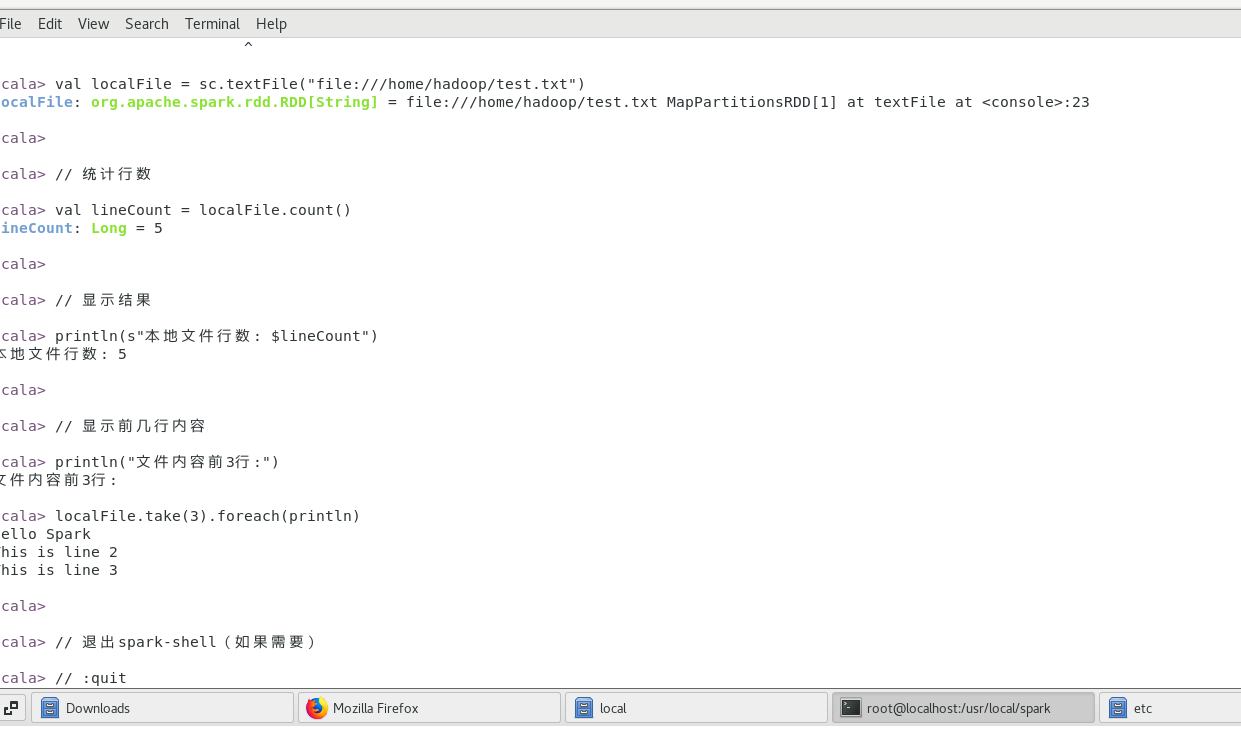
(1)在 spark-shell 中读取 Linux 系统本地文件“/home/hadoop/test.txt ”,然后统计出文件的行数;
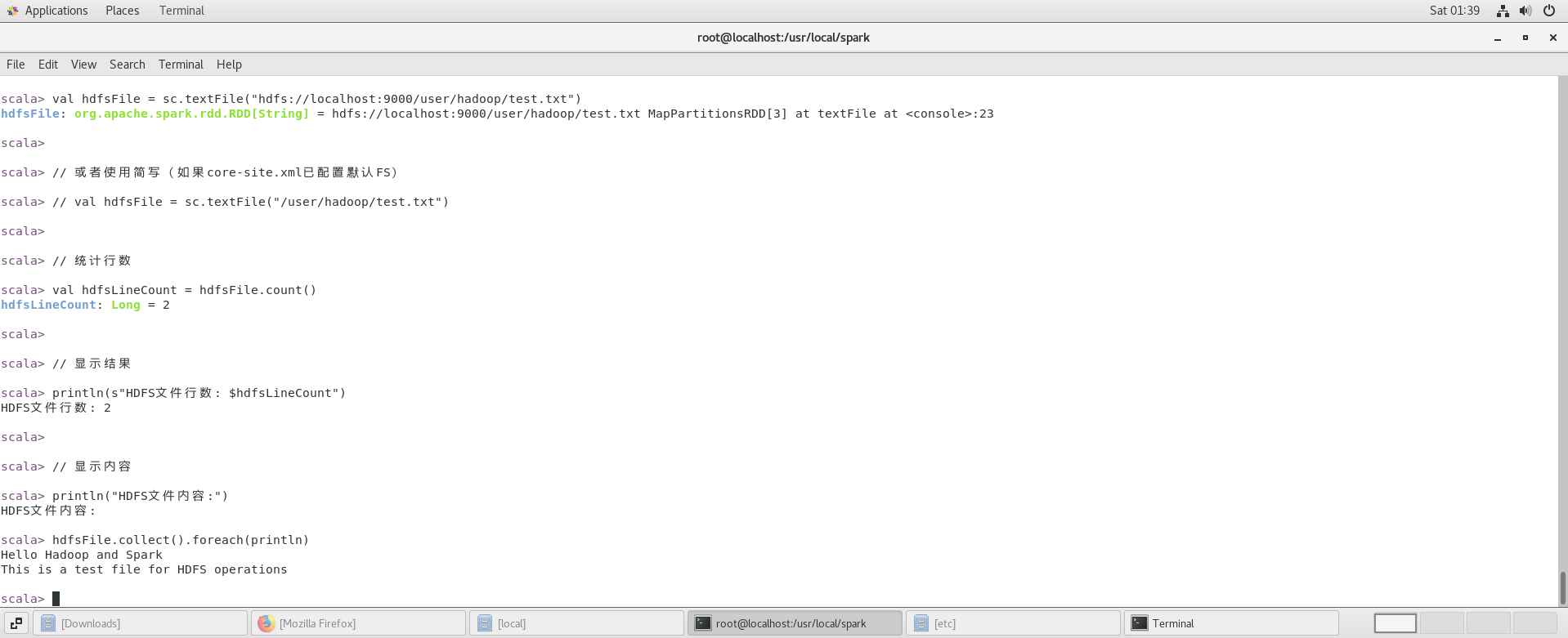
(2)在 spark-shell 中读取 HDFS 系统文件“/user/hadoop/test.txt ”(如果该文件不存在,请先创建),然后,统计出文件的行数;
(3)编写独立应用程序,读取 HDFS 系统文件“/user/hadoop/test.txt ”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包,并将生成的 JAR 包通过 spark-submit 提交到 Spark 中运行命令。
发表于
2026-01-17 18:20
吖呵
阅读(
0
) 评论(
0
)
收藏
举报
刷新页面
返回顶部