python--“re”详解
一、什么是正则表达式?
正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。
正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
二、正则表达式的基本语法。
1.备选字符集
语法:[可选字符列表]
强调:1. 无论备选字符集包含多少字符,只能选1个
2. 必须选1个!
比如:6位数字的密码: [0123456789][0123456789][0123456789][0123456789][0123456789][0123456789]
简化:1. 当备选字符连续时,可用-表示范围的区间
比如:[0123456789]-->[0-9]
[0-9][0-9][0-9][0-9][0-9][0-9]
[a-z]-->1位小写字母
[A-Z]-->1位大写字母
[A-Za-z]-->1位字母,大小写都行
[0-9a-zA-Z]-->1位字母或数字都行
反选:[^不能选的字符列表]
比如:[^47] 强调:^作“除了”使用时,只能放在开头
强调:1. 无论备选字符集包含多少字符,只能选1个
2. 必须选1个!
比如:6位数字的密码: [0123456789][0123456789][0123456789][0123456789][0123456789][0123456789]
简化:1. 当备选字符连续时,可用-表示范围的区间
比如:[0123456789]-->[0-9]
[0-9][0-9][0-9][0-9][0-9][0-9]
[a-z]-->1位小写字母
[A-Z]-->1位大写字母
[A-Za-z]-->1位字母,大小写都行
[0-9a-zA-Z]-->1位字母或数字都行
反选:[^不能选的字符列表]
比如:[^47] 强调:^作“除了”使用时,只能放在开头
语法:X|Y
表达式X|Y等价于[XY]
2、预定义字符集
为常用的字符集专门提供的简化写法!
“\d”-->[0-9]-->1位数字 “\D”------一位非数字字符
“\w”-->[0-9a-zA-Z_]-->1位字母,数字或_ “\W”------匹配任何非单词字符,等价于[^0-9a-zA-Z_]
“\s”-->1位空字符:匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 “\S”--------匹配非空白字符,等价于 [^\f\n\r\t\v]
“\d”-->[0-9]-->1位数字 “\D”------一位非数字字符
“\w”-->[0-9a-zA-Z_]-->1位字母,数字或_ “\W”------匹配任何非单词字符,等价于[^0-9a-zA-Z_]
“\s”-->1位空字符:匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 “\S”--------匹配非空白字符,等价于 [^\f\n\r\t\v]
“\b”----匹配一个单词边界。比如,“er\b”可以匹配"never"中的"er",但不能匹配“verb”中的“er”。 “\B”--------匹配非单词边界。比如,"er\B"能匹配"verb"中的"er",但是不能匹配“never”中的“er
”
“ . “: 除换行回车外的任何一个字符,如:
“ . “: 除换行回车外的任何一个字符,如:
.
3. 数量词:规定相邻的字符集可出现的次数
确定数量:3种:
{n}--> 必须反复出现n位
{n,m}--> 最少出现n次,最多出现m次
{n,}-->至少出现n次,多了不限!
比如:/^\d{6}$/——6位数字
{n}--> 必须反复出现n位
{n,m}--> 最少出现n次,最多出现m次
{n,}-->至少出现n次,多了不限!
比如:/^\d{6}$/——6位数字
不确定数量:3种
* 大于等于0次
+ 至少出现一次
? 0次或1次
4. 指定匹配位置:
^表达式: 必须以表达式的规则为开头
表达式$: 必须以表达式的规则为结尾
比如:选择字符串开头的空格?^\s*
选择结尾空格?\s*$
选择开头或结尾的空格?^\s*|\s*$
*预告:今后只要在程序中执行验证:都要前加^后加$*
表示从头到尾完整匹配。
比如:test():
^\d{6}$——从头到尾必须只能是6位数字
5.预判
^表达式: 必须以表达式的规则为开头
表达式$: 必须以表达式的规则为结尾
比如:选择字符串开头的空格?^\s*
选择结尾空格?\s*$
选择开头或结尾的空格?^\s*|\s*$
*预告:今后只要在程序中执行验证:都要前加^后加$*
表示从头到尾完整匹配。
比如:test():
^\d{6}$——从头到尾必须只能是6位数字
5.预判
在进行正式匹配正则表达式之前,先预读整个字符串,进行初步匹配,如果预判都不能通过,则不再验证。
(?:pattern) 非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。
(?=pattern) 非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?!pattern) 非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。
(?<=pattern) 非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。 “(?<=95|98|NT|2000)Windows”目前在python3.6中re模块测试会报错,用“|”连接的字符串长度必须一样,这里“95|98|NT”的长度都是2,“2000”的长度是4,会报错。
(?<!pattern) 非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。这个地方不正确,有问题 .此处用或任意一项都不能超过2位,如“(?<!95|98|NT|20)Windows正确,“(?<!95|980|NT|20)Windows 报错,若是单独使用则无限制,如(?<!2000)Windows 正确匹配。 同上,这里在python3.6中re模块中字符串长度要一致,并不是一定为2,比如“(?<!1995|1998|NTNT|2000)Windows”也是可以的。
(?<!pattern) 非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。这个地方不正确,有问题 .此处用或任意一项都不能超过2位,如“(?<!95|98|NT|20)Windows正确,“(?<!95|980|NT|20)Windows 报错,若是单独使用则无限制,如(?<!2000)Windows 正确匹配。 同上,这里在python3.6中re模块中字符串长度要一致,并不是一定为2,比如“(?<!1995|1998|NTNT|2000)Windows”也是可以的。
6.分组
()括号里面的内容当作一个分组,当做一个整体
比如:(a|bc)de 表示ade 或者cdef
给分组起别名:
语法格式: (?P<name> 分组内容)
eg:(?P<mark>123abc) 这里的意思是给123abc这个分组起了个别名叫mark
我们可以通过<?P=mark>的方式来访问到该分组。
7.贪婪模式和懒惰模式
贪婪模式:默认情况下,正则表达式会匹配最大的符合条件的字符串, *、+和?限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
比如
匹配字符串:123abc
匹配规则:r"\d*[a-z]*?" 匹配结果为123
匹配guize:r"\d*?[a-z]*" 匹配·结果为abc
8.python中re模块的常用方法
在python中,Pattern对象无法通过实例化来创建,只能通过re.compile()方法来返回一个pattern对象。
pattern对象,即我们定义的匹配规则。
1、re.match(pattern,str[,flags])这个函数是从str的开头开始,尝试匹配pattern,一直向后匹配,如果遇到无法匹配的字符或者到达str的末尾,立刻返回None,匹配成则返回一个match对象。
import re
s="HelloWorld" p=re.compile(r"Hello") m=p.match(s)
print(m.group())
print(m.span())
执行结果为:
Hello
(0,5)
"""对于p=re.compile(r"Hello")这一语句,re.compile(r"Hello")会返回一个Pattern对象,并把这个对象的引用赋值给p这个变量,此时,p就指向了pattern这个对象""" """对于m=p.match(s)这一语句,p.match(s),如果存在匹配结果,则返回一个match对象,如果不存在匹配结果,则返回None"""
下面,我们来详细讲一下Match对象中的方法
group() //返回一个字符串或者元组
span() //返回匹配规则在字符串中的位置
groups() //用于分组的数据
现在,我们可以知道,在Pattern中也有一个match()方法,它和re中的match()方法,作用完全相同
参数列表 使用场景
re.match() pattern(匹配规则),str(需要匹配的字符串),flags 使用不同的规则去匹配字符串
p.match() str(需要匹配的字符串) 使用同一规则去匹配一组字符串
2、re.search(pattern,str[,flags])
search()方法与match()方法极其类似,区别在于match()方法只从str的开始位置匹配,search()方法会扫描整个str查找匹配.
match()方法只有在str开始的位置匹配成功才会返回一个match对象,如果不是开始位置匹配的话,match()就返回一个None。
search()方法的返回对象和match()返回对象是一样的。
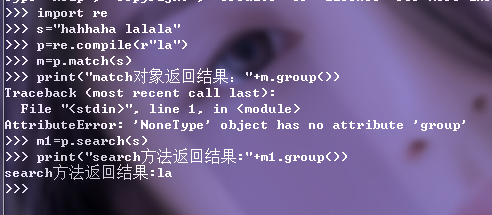
import re s="hahhaha lalala" p=re.compile(r"la") m=p.match(s)
print("match对象返回结果:"+m.group())
m1=p.search(s)
print("search方法返回结果:"+m1.group())
执行结果为:
3.findall(pattern,str[,flags])//搜索整个str,以列表的形式返回匹配的全部子串
import re s="hahhaha lalala" p=re.compile(r"la")print("findall对象返回结果:"+str(re.findall(p,s)))##注意findall方法返回的是一个列表 m1=p.search(s) print("search方法返回结果:"+m1.group())
执行结果:

4、re.split(pattern,str[,maxsplit])//按照能够匹配的子串将str分割后返回列表。maxsplit用于指定最大分割次数,不指定则默认将全部分割。
import re p=re.compile(r"\d+")
l=re.split(p,"A1B2C3D4") print(str(l))
执行结果为:

5.re.sub(pattern,repl,str[,count])
使用repl替换str中每一个匹配的子串后返回一个被替换后的字符串。当repl是一个方法时。这个方法只接受一个参数(Match对象),并返回一个字符串。count用于指定最多替换的次数,不指定时,全部替换。
在我身后,微笑地活下去吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号