

第一次爬虫与测试
一、requests库的get()函数访问搜狗主页20次,打印返回状态,text()内容,计算text()属性和content属性所返回网页内容的长度。
1>返回状态。

import requests
from bs4 import BeautifulSoup
def JudgeState(r):
x = r.status_code
print("获得响应的状态码:", x , end="")
if x == 200 :
print("------请求成功")
if x == 301:
print("资源(网页等)被永久转移到其它URL")
if x == 404:
print("请求的资源(网页等)不存在")
if x == 500:
print("内部服务器错误")
return ''
r = requests.get("https://cn.bing.com/",timeout = 30)
for i in range(1,21): #访问搜狗网站20次,查看连接状态
print("第{}次".format(i))
JudgeState(r)
1.1运行结果:

二、游戏测试
测试方法:运用try和expect
from random import random
def main():
printInfo()
probA,probB,m,n = getInput()
winsA,winsB = simNGames(m,n,probA,probB)
printSummary(winsA,winsB)
def printInfo():
print("这个程序模拟两个选手A和B的羽毛球竞技比赛")
print("程序需要两个选手的能力值0-1")
print("规则:三局两胜--21分制")
try:
printInfo(x)
except:
print('printInfo error')
def getInput():
a = eval(input("请输入选手A的能力值(0-1):"))
b = eval(input("请输入选手B的能力值(0-1):"))
m=eval(input("比赛的局数:"))
n = eval(input("模拟比赛的场次:"))
return a,b,m,n
try:
getInput(x)
except:
print('getInput error')
def printSummary(winsA,winsB):
n = winsA + winsB
print("竞技分析开始,共模拟{}场比赛".format(n))
print("选手A获胜{}场比赛,占比{:0.1%}".format(winsA,winsA/n))
print("选手B获胜{}场比赛,占比{:0.1%}".format(winsB,winsB/n))
try:
printSummary(500)
except:
print('printSummary error')
def simNGames(m,n,probA,probB):
winsA,winsB = 0,0
wa,wb=0,0
for i in range(n):
for i in range(m):
scoreA,scoreB = simOneGame(probA,probB)
if scoreA > scoreB:
wa += 1
else:
wb += 1
if wa==2:
winsA+=1
wa,wb=0,0
break
if wb==2:
winsB+=1
wa,wb=0,0
break
return winsA,winsB
try:
simNGames(1000, 0.1)
except:
print('simNgame error')
def simOneGame(probA,probB):
scoreA,scoreB = 0,0
serving = "A"
while not gameOver(scoreA,scoreB):
if serving == "A":
if random() < probA:
scoreA += 1
else:
serving = "B"
else:
if random() < probB:
scoreB += 1
else:
serving = "A"
return scoreA,scoreB
try:
simOneGame( 0.1)
except:
print('simOneGame errror')
def gameOver(a,b):
if(a>=20 or b>=20):
if(abs(a-b)==2 and a<=29 and b<=29):
return True
(2)访问网页主页
① 导入库
from requests import get
② 设定url, 并使用get方法请求页面得到响应
url = "http://www.baidu.com"
r = get(url, timeout=3)
print("获得响应的状态码:", r.status_code)
print("响应内容的编码方式:", r.encoding)
运行结果:
获得响应的状态码: 200
响应内容的编码方式: ISO-8859-1
③ 获取网页内容
url_text = r.text
print("网页内容:", r.text)
print("网页内容长度:", len(url_text))
运行结果:
网页内容: <!DOCTYPE html><!--STATUS OK--><html> <head> ... 京ICPè¯030173å· ... </body> </html>
网页内容长度: 2381
完成对简单的html页面的相关计算要求
【html页面如下】要求获取其中的head、body,id为first的标签内容。
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id=first>我的第一个段落。</p > </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> </tr> </table> </html>
根据作业要求,将该html代码储存到电脑上,用打开文件方式打开该html)
import requests
from bs4 import BeautifulSoup
f = open("D:\\桌面\\pytest\\test.html",'r',encoding="utf-8")
r = f.read()
f.close()
soup = BeautifulSoup(r,"html.parser")
print("(1)head标签:\n",soup.head)
print("(2)body标签内容:\n",soup.title)
print("(3)id为first的标签对象:\n",soup.find(id='first'))
print("(4)获取该html中的中文字符:",soup.title.string,soup.find('h1').string,\
soup.find(id='first').string)
三、爬中国大学排名网站内容,并存为csv。
要求获取如下图的数据:
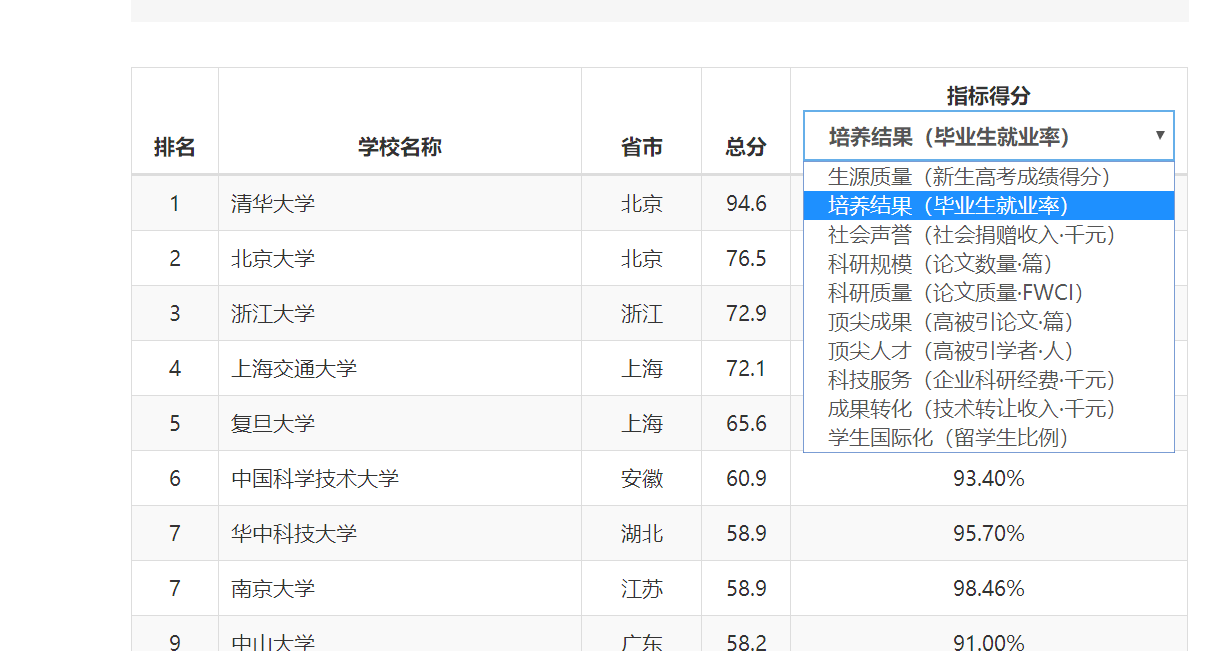
具体代码如下:
import requests
from bs4 import BeautifulSoup
def GetHTMLText(url):
try :
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = "utf-8"
return r.text
except:
return ""
def FindUnivList(soup):
data = soup.find_all('tr')
lth = data[0].find_all('th')
thead = []
for th in lth[:4]: #前四个表格标题(第五个特殊,下面处理)
thead.append(th.string)
tOptions = data[0].find_all('option') #处理第五个特殊的表格标题
for tOption in tOptions:
thead.append(tOption.string)
allUniv.append(thead)
for tr in data: #获取数据内容
ltd = tr.find_all('td')
if len(ltd) == 0:
continue
tbodies = []
for td in ltd:
if td.string is None: #对无数据内容处理
tbodies.append('')
continue
tbodies.append(td.string)
allUniv.append(tbodies)
def main():
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"
html = GetHTMLText(url)
soup = BeautifulSoup(html,"html.parser")
FindUnivList(soup)
#储存为csv
f = open('2016中国大学排名.csv','w',encoding='utf-8')
for row in allUniv:
f.write(','.join(row)+'\n')
f.close()
allUniv = []
main()
关于在获取数据时,对于无数据内容的处理:
例如,某所大学的得分指标没有,这时如果不进行处理就会出现如下错误
TypeError: sequence item 5: expected str instance, NoneType found
具体解决方法见上述代码。
结果如下:(只显示部分)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号