

import java.io.*; public class Main { public static PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out)); public static BufferedReader in = new BufferedReader(new InputStreamReader(System.in)); public static StreamTokenizer st = new StreamTokenizer(in); public static int nextInt() throws IOException { st.nextToken(); return (int)st.nval; } public static long nextLong() throws IOException { st.nextToken(); return (long)st.nval; } public static void main(String[] args) throws IOException { int n = nextInt(); in.close(); out.println(n); out.flush(); out.close(); } }

这个是java大佬们最常用的输入方法了,但是在nextLong上有时会出现一些小小的bug,下面的代码是一个正常的StreamTokenizer的nextLong:
public static void main(String[] args) throws IOException { long x = nextLong(); in.close(); out.println(x); out.flush(); out.close(); }
输入:1152921504606846976,这个数是在long的范围内的(2^60)。看一下输出结果。
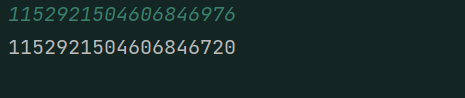
出现这种现象的原因就是精度损失。
先看一看StreamTokenizer的nval()方法的返回

可以看出来,这个方法大概是把字符串转化成double类型,而nextInt与nextLong方法则是把从字符串转化而来的double型浮点数再转化为long与int型整数。double型变量是64位,long也是64位,但是从浮点数的储存原理来看这必然会出现精度损失的问题。
先来看看浮点数在计算机中的储存方式。在我们的生活中,数的表示有两种,一种是直接写出它的值,另一种就是科学计数法了,比如1234567000000,是正常表示法,它也可也写成科学计数法:1.23456*10¹²,当然,不可能保留太多位数的有效数字,不然的话科学计数法就失去了它的意义了,故一般写成:1.23*10¹²。
在计算机中也有类似的表示方法,浮点数在计数机中就是通过这样的方式存储的。$$(-1)^{a}\times\beta\times2^{\vartheta}$$
α为符号位,表示浮点数整体的正负,β为尾码,就相当于1.23*10¹²中的1.23,θ为阶码,用来表示指数的大小。在IEEE754标准中规定,64位浮点数的储存格式为:
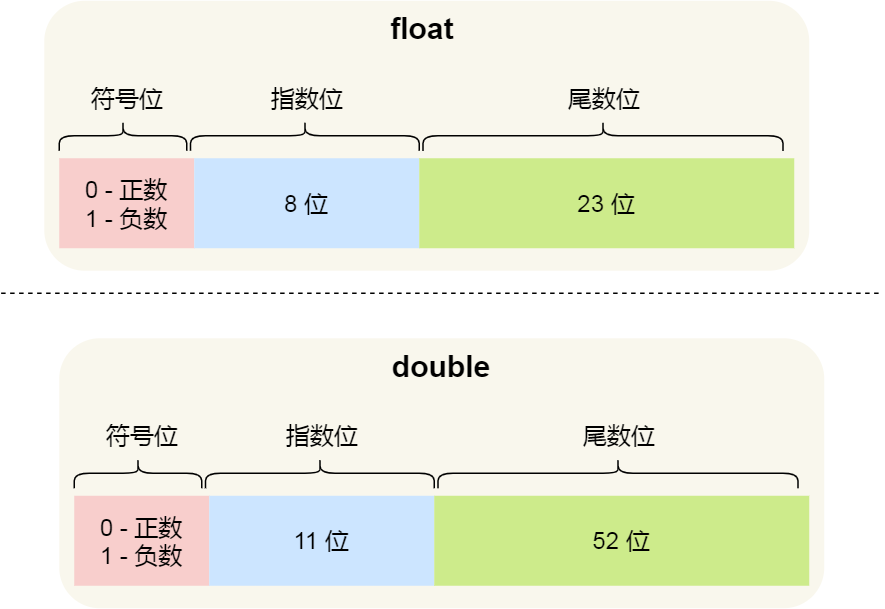
最高位为符号位,大小为一位,阶码为11位,尾码为52位。也就是说在double浮点数中,52位来表示1.23*10¹²中的1.23,而11位来表示指数,这相对于我们现实生活中的科学计数法友好得多,它有52位的有效位数不可,不容易损失精度。但是,long型整数可是有64位,double提供的有效位数相比起来不太够看,这有的时候就会出现意想不到的bug,这也解释了之前出现的那个bug,2^60 > 2^52。刚刚用十进制数举的例子:1.23*10¹² == 1230000000000 相比它原来的大小1234567000000损失了不小。
为了进一步来验证我的想法,来试着测试一下double转long精度损失的临界值,多输入几个值来测试:根据理论推测,在2^52之前应该都是准确没有精度损失的,从2^52之后就会有精度损失,先来输入(2^52) + 5 试试:

结果出乎意料,竟然是准确的。后来才发现,是忘了一点:尾码前面还有一位隐藏的1,正确的格式是:$$(-1)^{a}\times(1.\beta)\times2^{\vartheta}$$。所以一共是有53位都是用来表示尾码的,那么,推测一下,从2^53往后应该就会出现精度损失了:
先来测试一下2^53:
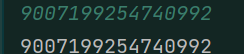
2^53 + 1:

果然,刚到2^53 + 1就出现了精度损失。
这就是使用StreamTokenizer的nval方法实现nextLong的时候可能出现的一点小bug,希望看到这篇文章的朋友以后在long的输入的时候注意一下。本人是在打ACM校赛的时候遇到的这个问题,它时认为自己的代码逻辑已经完美了,但是交上去之后全是wa加tle(单纯就是卡java,1e6的数据,一个输入加排序就超时了)
当时心态就有点炸。最后也没打好,回来之后调试也没有发现哪不对,直到我把那接近10的18次方的大数单独输入了一遍才发现了问题。希望大家能避开这个坑。
另外关于nextLong,本人也没有非常好的处理方法,在n<2^53的时候完全可以直接用nval转long,但超过这个值就不要用这个方法了,目前,我只知道两个方法:
一个用StringTokenizer读入一个字符串,然后直接pase字符串成long值:
import java.io.*; import java.util.StringTokenizer; public class Main { public static PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out)); public static BufferedReader in = new BufferedReader(new InputStreamReader(System.in)); public static StringTokenizer st = new StringTokenizer(""); public static String next() throws IOException { while(!st.hasMoreTokens()) { st = new StringTokenizer(in.readLine()); } return st.nextToken(); } public static long nextLong() throws IOException { return Long.parseLong(next()); } public static void main(String[] args) throws IOException { long x = nextLong(); in.close(); out.println(x); out.flush(); out.close(); } }
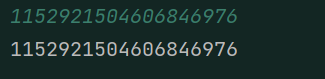
输入2^60
另一种类似于c++的快读,但是java没法自己调用寄存器(以我的认知,大佬可能有办法)也没有inline,所以达不到快读的效果,但是比Scanner肯定是要快的,甚至,通过学校的oj的结果来看,比上一种方法还快:
import java.io.*; import java.util.StringTokenizer; public class Main { public static PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out)); public static BufferedReader in = new BufferedReader(new InputStreamReader(System.in)); public static long nextLong() throws IOException { long res = 0; boolean f = true; int c = 0; while(c < 48 || c > 57) { if(c == '-') f = false; c = in.read(); } while(c >= 48 && c <= 57) { res = (res<<3) + (res<<1) + c - 48; c = in.read(); } return f ? res : -res; } public static void main(String[] args) throws IOException { long x = nextLong(); in.close(); out.println(x); out.flush(); out.close(); } }
总结,通过StreamTokenizer的nval方法实现nextLong的时候,当数值大于2^53的时候就会出现精度损失,从而出现难以意料的bug,应对方法,就是上面提到的两种1、通过StringTokenizer,直接把字符串转化为long。2、借鉴c++,低配版快读。但是这两种方法均比StreamTokenizer的nval转long慢,所以在2^53之前还是建议用StreamTokenizer。如果有更好的方案,欢迎大佬来指教。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号