软件工程寒假作业2/2
软件工程寒假作业2/2
| 这个作业属于那个课程 | 2021春软件工程实践|W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 阅读《构建之法》并提问、完成词频统计个人作业、学习使用git以及Github |
| 其他参考文献 | 《构建之法》、单元测试和回归测试、Git教程 |
目录:
Part1:阅读构建之法并提问
1.1 在结对编程这一节中,为什么说结对编程并非一致地有利?什么时候该选择结对编程?
虽然结对编程比单独编程更快的完成,但是整体的程序编写时间(程序员数目 * 花费时间)增加了。管理者在工作更快的完成以及缩短测试和调试的时间和更高的编码成本之间平衡。对于那些程序员没有完全理解的任务,他们期待更多的创造性,高复杂度,此时采用结对编程更为高效。
1.2 在了解了敏捷方法中的极限编程(XP)和Scrum后,分析它们的差别。
区别之一: 迭代长度的不同:
XP的一个Sprint的迭代长度大致为1~2周, 而Scrum的迭代长度一般为2~4周。
区别之二: 在迭代中, 是否允许修改需求:
XP在一个迭代中,如果一个User Story(用户素材, 也就是一个需求)还没有实现, 则可以考虑用另外的需求将其替换,替换的原则是需求实现的时间量是相等的。而Scrum是不允许这样做的,一旦迭代开工会完毕, 任何需求都不允许添加进来,并有Scrum Master严格把关,不允许开发团队受到干扰。
区别之三: 在迭代中,User Story是否严格按照优先级别来实现:
XP是务必要遵守优先级别的。但Scrum可以不按照优先级别来做,Scrum这样处理的理由是:如果优先问题的解决者,由于其它事情耽搁,不能认领任务,那么整个进度就耽误了。另外一个原因是,有时候一些高优先级的内容要依赖于低优先级的内容来实现,这时候就得先实现低优先级的内容。
区别之四:软件的实施过程中,是否采用严格的工程方法,保证进度或者质量:
Scrum没有对软件的整个实施过程开出工程实践的处方,要求开发者自觉保证。但XP对整个流程方法定义非常严格,规定需要采用TDD、自动测试、结对编程、简单设计、重构等约束团队的行为。
1.3 敏捷开发原则有一条是:“敏捷流程欢迎需求的变化,并利用这种变化来提高用户的竞争优势。”,那么如果用户的需求一直变化,改如何应对?
这种需求的变化是敏捷开发中所要求的,如果需求变化非常频繁:
1、降低需求变更的频率
需求调研阶段一定要深入到用户中去,体验他们的工作,深挖他们的痛点,然后抓大放小,每个阶段只解决最需要解决的问题。
迭代总结对需求变更进行深入分析,搞清楚变更的根源,是实现方案不行、需求理解错误还是搞错了调研对象?
2、减少需求变更带来的成本
明确定义每个版本的边界,先用最轻量级的方式验证商业模式(MVP),再优化产品。
1.4 讲义6用户调研中,在调研后,如何对用户的需求进行总结分析?
1,确定项目的大背景
确定项目的大背景,就是充分的了解项目的领域,客户对项目的期望值。其次,对于企业项目来讲,在确定项目目标后,还要进一步的了解客户的企业框架。当前项目在企业框架中位置,第三方接口定义等等。
2,项目本阶段的核心需求定义和确定
在确定了需求的大背景下,下一步,我们需要做的内容就是确定项目的核心功能,关键的质量,和相关的约束。从功能、质量、约束三方考虑。
3,对项目核心功能进行数据流需求调研分析,业务逻辑分析。并在这基础上编写用户用例 ,数据流转图,业务逻辑图等。
1.5 结对编程可以使软件开发更为高效、迅捷,如果结对编程的二人的能力水平差距过大,该如何做出决定?是否还有绝对编程的必要?
一般都是提倡结对,但是如果一个人除了语法建议以外什么忙都帮不上,那就该换个方式来使用他的时间。如果一个有经验的伙伴被要求把速度降下来去解释一些东西,那当前的任务就肯定要多花些时间才能完成,从而影响软件的开发速度。当经验上的差距能被弥补,这通常来说是最有效的学习。当然如果经验上的差距太大,以至于没法弥补或者影响到了成功地交付,那么就应该拆散这对重新组合。
冷知识
电脑病毒的设计初衷并非是对计算机造成损害。历史上第一款电脑病毒,是由防御技术专家Fred Cohen亲手设计的。他创造电脑病毒的目的是为了证明程序对电脑感染的可行性。这款程序能够通过软盘等移动介质在不同的计算机之间传播,因而被命名为病毒。
Part2:WordCount编程
2.1 Github项目地址
2.2 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 90 | 75 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 70 | 55 |
| • Design Spec | • 生成设计文档 | 70 | 45 |
| • Design Review | • 设计复审 | 60 | 40 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 50 | 30 |
| • Design | • 具体设计 | 120 | 90 |
| • Coding | • 具体编码 | 420 | 330 |
| • Code Review | • 代码复审 | 80 | 65 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 140 | 120 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 40 | 30 |
| • Size Measurement | • 计算工作量 | 30 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 30 |
| 合计 | 1230 | 930 |
2.3 解题思路描述
作业需求中要求通过命令行来执行程序,要求能够统计字符,行数,单词数。看到单词的要求,觉得可以用正则表达式来解决。所以一开始决定的路线是,文件读取,统计各个要求的数目,文件输出。然后开始查阅资料,解决问题。
2.4 代码规范制定链接
2.5 设计与实现过程
代码分为两个类,Lib类和WordCount类,Lib类中包含了统计数目和输入文件输出文件功能。
Lib类:
1,readFromFile():通过BufferedReader和StringBuilder对象来读入数据,用read()按字符读入。
2,getCharCount():统计字符数,将读入的字符串转换为字符数组,判断是否属于ASCII码。
3,getLineCount():统计有效行数,也是用正则表达是来匹配统计。
4,getWordCount():统计单词数,正则表达式。通过split拆开字符串,匹配正则表达式。将单词存到Map,并记录单词出现的次数。为之后的排序做准备。
public static int getWordCount(String str)
{
//count为单词数
int count = 0;
//用split拆开字符串 strs字符串数组将保留拆开的单词
String[] strs = str.split(SEPARATOR_RE);
for(int i = 0; i < strs.length; i++)
{
//匹配成功单词数加1
if(strs[i].matches(WORD_RE))
{
//单词不区分大小写 将单词存到Map中供排序使用
String temp = strs[i].toLowerCase();
if(wordsMap.containsKey(temp))
{
//通过get函数获取当前单词的已出现次数
int num = wordsMap.get(temp);
wordsMap.put(temp, 1 + num);
}
//如果没有符合该单词的 将该单词的已出现次数定为1
else
{
wordsMap.put(temp, 1);
}
count++;
}
}
return count;
}
5,sortHashmap():通过比较器来排序出现频率最高的单词
public static List<Map.Entry<String, Integer>> sortHashmap()
{
List<Map.Entry<String, Integer>> list;
list = new ArrayList<Map.Entry<String, Integer>>(wordsMap.entrySet());
//通过比较器来实现排序
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>()
{
public int compare(Entry<String, Integer> m1, Entry<String, Integer> m2)
{
//按照字典序和value排序
if(m1.getValue().equals(m2.getValue()))
{
return m1.getKey().compareTo(m2.getKey());
}
else return m2.getValue()-m1.getValue();
}
});
return list;
}
6,writeToFile():用BufferedWriter将数据输出到文件。
2.6 性能改进
用BufferedWriter和BufferedReader可以加快文件的读取和输入

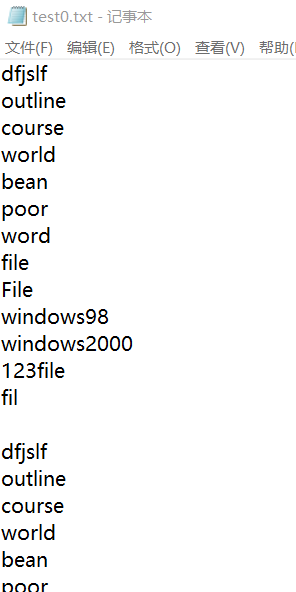
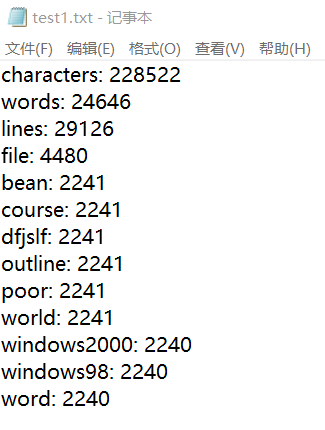
2.7 单元测试
统计字符数的测试
@Test
public void testGetCharactersCount() {
String str = "word\nfile\nFile\nwindows98\nwindows2000\n123file\r\nfil\n\n";
int loopTimes = 10000;
String testStr = "";
for(int i = 0; i < loopTimes; i++) {
testStr += str;
}
//调用Lib的字符数统计方法
assertEquals(Lib.getCharCount(testStr), 510000);
}
统计有效行数的测试
@Test
public void testGetLineCount() {
String str = "word\nfile\nFile\nwindows98\nwindows2000\n123file\r\nfil\n\n";
int loopTimes = 10000;
String testStr = "";
for(int i = 0; i < loopTimes; i++) {
testStr += str;
}
//调用Lib的行统计方法
assertEquals(Lib.getLineCount(testStr), 70000);
}
统计单词数的测试
@Test
public void testGetWordCount() {
String str = "word\nfile\nFile\nwindows98\nwindows2000\n123file\r\nfil\n\n";
int loopTimes = 10000;
String testStr = "";
for(int i = 0; i < loopTimes; i++) {
testStr += str;
}
//调用Lib的单词统计方法
assertEquals(Lib.getWordCount(testStr), 0);
}
测试截图
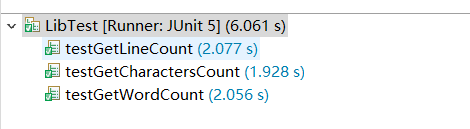
2.8 异常处理说明
FileNotFoundException和IOException分别用于文件无法找到错误和输出错误。
2.9 心路历程与收获
这个作业让我了解了更多关于java的文件输入输出和正则表达式的知识,以及了解了Github的使用,还了解了单元测试的重要性和单元测试的方法。这次作业中,有一些问题还是无法解决,在之后的学习过程中,要更加努力,学习新知识,查询资料,解决学习中所遇到的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号