sql 常用命令
1、mysql 服务的启动和停止
net stop mysql
net start mysql
2、登录mysql
mysql (-h IP)-u 用户名 -p 密码
3、grant 权限 on 数据库. to 用户名@登录主机 identified by "密码"*
例:增加一个用户user密码为password,让其可以在本机上登录, 并对所有数据库有查询、插入、修改、删除的权限。首先用以root用户连入mysql,然后键入以下命令:
grant select,insert,update,delete on . to user@localhost Identified by “password”;
如果希望该用户能够在任何机器上登陆mysql,则将localhost改为”%”。
4、操作数据库
1)user 数据库名
2)显示数据库列表
show databases
3)显示库中对应的表名
user 数据库名
show tables
4)显示数据库表结构
describe 表名
5)建库与删库
create database 库名(character set utf8);
drop database 库名
6)建表与删表
user 库名
create table 表名(字段列表)
drop table 表名
7)清空表中的记录
delete from 表名
8)显示表中的记录
select*from 表名
9)往表中加入记录
- insert into 表名(字段名1;字段名2.。。。) values(值1,值2.。。。)---可插入多行或单行
eg1:insert into 表名(列1,列2,列3) value(值1a,值2a,值3a;值1b,值2b,值3b) - 从一个表中复制数值粘贴到另一个表中
eg2:insert into 表1(字段名1,字段名2,字段名3,字段名4)
select 字段名1,字段名2,字段名3,字段名4 from 表2
where 字段名1-1 - 结合使用set 关键字为表中插入新的一列
insert into 表名 set id=值1,name=值2,age=值3
10)修改表中的值
update 表名 set 字段名1= 值1 where 子句1 order by 子句,limit 子句3
WHERE 子句:可选项。用于限定表中要修改的行。若不指定,则修改表中所有的行。
ORDER BY 子句:可选项。用于限定表中的行被修改的次序。
LIMIT 子句:可选项。用于限定被修改的行数。
11)增加/删除表字段
增加:alert table 表名 add 字段 类型
eg:alter table MyClass add student_mount int(4) default '0',add address varchar(11)
删除:alert table 表名 drop column age,drop column address
修改字段的注释:alert table 表名 modify column id comment '学号'
修改原字段名称及类型:alert table_name change old_field_name new_field_name field_type
11)导出数据库文件
mysqldump --opt test > mysql.test
即将数据库test数据库导出到mysql.test文本文件
例:mysqldump -u root -p用户密码 --databases dbname > mysql.dbname
12)导入数据库文件
mysqlimport -u root -p用户密码 < mysql.dbname
13)退出数据库
exit 回车
查询数据(Select) 补充
select语句除了可以查看数据库中的表格和视图的信息外,还可以查看 SQL Server的系统信息、复制、创建数据表。其查询功能强大,是SQL语言的灵魂语句,也是SQL中使用频率最高的语句。
基本select语句:
一个基本的select语句可分解成三个部分:查找什么数据(select)、从哪里查找(from)、查找的条件是什么(where)。
select 语句的一般格式如下:
** select <目标列表达式列表>**
** from 表名或视图名**
** [where <条件>]**
** [group by <分组表达式>]**
** [having <条件>]**
** [order by <排序表达式>[ASC|DESC]]**
(一)查询指定的列
1.查询表中所有列
在select语句指定列的位置上使用*号时,表示查询表的所有列。
模板:select * from tb_name;
2.查询表中指定的列
查询多列时,列名之间要用逗号隔开。
模板: select tb_name.<字符型字段>,<字符型字段> … from tb_name;
3.指定查询结果中的列标题
通过指定列标题(也叫列别名)可使输出结果更容易被人理解。指定列标题时,可在列名之后使用AS子句AS子句的格式为:列名或计算表达式 [AS] 列标题
模板:select <字符型字段> as 列标题1,<字符型字段> as 列标题2, <字符型字段> as 列标题3 from bt_name;
4.查询经过计算的列(即表达式的值)
使用select对列进行查询时,不仅可以直接以列的原始值作为结果,而且还可以将列值进行计算后所得值作为查询结果,即select子句可以查询表达式的值,表达式可由列名、常量及算术运算符组成。
(二)选择行:选择表中的部分行或全部行作为查询的结果
** 格式: select [all|distinct] [top n[percent]]<目标列表达式列表> from 表名**
-
消除查询结果中的重复行
对于关系数据库来说,表中的每一行都必须是不同的(即无重复行)。但当对表进行查询时若只选择其中的某些列,查询结果中就可能会出现重复行。在select语句中使用distinct关键字可以消除结果集中的重复行,
** 模板:select distinct <字符型字段>[,<字符型字段>,…] from tb_name;**
eg1:SELECT DISTINCT Country FROM Customers;
eg2:SELECT COUNT(DISTINCT Country) FROM Customers; -
限制查询结果中的返回行数
使用top选项可限制查询结果的返回行数,即返回指定个数的记录数。其中:n是一个正整数,表示返回查询结果集的前n行;若带percent关键字,则表示返回结果集的前n%行。
** 模板:select top n from tb_name; /查询前 n 的数据/**
** 模板:select top n percent from tb_name; /查询前 n% tb_name的数据/ **
(三)查询满足条件的行: 用where子句实现条件查询
通过where子句实现,该子句必须紧跟在From子句之后。
格式为:select [all|distinct] [top n[percent]]<目标列表达式列表> from 表名 where <条件>;
说明:在查询条件中可使用以下运算符或表达式:
运算符 运算符标识
比较运算符 <=,<,=,>,>=,!=,<>,!>,!<
范围运算符 between… and,not between… and
列举运算符 in,not in
模糊匹配运算符 like,not like
空值运算符 is null,is not null
逻辑运算符 and,or,not
1.使用比较运算符:
模板:select * from tb_name where <字符型字段> >= n ;
2.指定范围:
用于指定范围的关键字有两个:between…and和 not between…and。
格式为:select * from tb_name where [not] between <表达式1> and <表达式2>;
查询出版时间不在2023年的书籍
eg:select * from book where 出版时间 not between '2023-1-1' and '2023-12-31'
其中:between关键字之后的是范围的下限(即低值),and关键字之后的是范围的上限(即高值)用于查找字段值在(或不在)指定范围的行。
3.使用列举:
使用in关键字可以指定一个值的集合,集合中列出所有可能的值,当表达式的值与集合中的任一元素个匹配时,即返回true,否则返回false。
** 模板:select * from tb_name where <字符型字段> [not] in(值1,值2,…,值n);**
4.使用通配符进行模糊查询:
可用like 子句进行字符串的模糊匹配查询,like子句将返回逻辑值(true或False)。
like子句的格式: select * from tb_name where <字符型字段> [not] like <匹配串>;
其含义是:查找指定字段值与匹配串相匹配的记录。匹配串中通常含有通配符%和_(下划线)。
其中: %:代表任意长度(包括0)的字符串
5.使用null的查询
当需要判定一个表达式的值是否为空值时,使用 is null关键字。
当不使用not时,若表达式的值为空值,则返回true,否则返回false;当使用not时,结果刚好相反。
模板:select * from tb_name where <字符型字段> is [not] null;
6.多重条件查询:使用逻辑运算符
逻辑运算符and(与:两个条件都要满足)和or(或:满足其中一个条件即可)可用来联接多个查询条件。and的优先级高于or,但若使用括号可以改变优先级。
**模板:select * from tb_name where <字符型字段> = ‘volues’ and <字符型字段> > n; **
(四)对查询结果排序
order by子句可用于对查询结果按照一个或多个字段的值(或表达式的值)进行升序(ASC)或降序(DESC)排列,默认为升序。
格式:order by {排序表达式[ASC|DESC]}[,…n];
其中:排序表达式既可以是单个的一个字段,也可以是由字段、函数、常量等组成的表达式,或一个正整数。
模板:select * from tb_name order by <排序表达式> <排序方法>;
(五)使用统计函数:又称集函数,聚合函数
在对表进行检索时,经常需要对结果进行计算或统计,T-SQL提供了一些统计函数(也称集函数或聚合函数),用来增强检索功能。统计函数用于计算表中的数据,即利用这些函数对一组数据进行计算,并返回单一的值。
常用统计函数表
函数名 功能
AVG 求平均值
** count 求记录个数,返回int类型整数**
** max 求最大值**
** min 求最小值**
** sum 求和**
-
SUM和AVG
功能:求指定的数值型表达式的和或平均值。
模板:select avg(<字符型字段>) as 平均数,sum(<字符型字段>) as 总数 from tb_name where <字符型字段> =’字符串’; -
Max和Min
功能:求指定表达式的最大值或最小值。
模板:select max(<字符型字段>) as 最大值,min(<字符型字段>) as 最小值 from tb_name; -
count
该函数有两种格式:count()和count([all]|[distinct] 字段名),为避免出错,查询记录个数一般使用count(),而查询某字段有几种取值用count(distinct 字段名)。
(1).count():
功能:统计记录总数。
**模板:select count() as 总数 from tb_name;**
(2).count([all]|[distinct] 字段名)
功能:统计指定字段值不为空的记录个数,字段的数据类型可以是text、image、ntext、uniqueidentifier之外的任何类型。
模板:select count(<字符型字段>) as 总数 from tb_name;
(六)对查询结果分组
group by子句用于将查询结果表按某一列或多列值进行分组,列值相等的为一组,每组统计出一个结果。该子句常与统计函数一起使用进行分组统计。
格式为:group by 分组字段[,…n][having <条件表达式>];
1.在使用group by子句后
select列表中只能包含:group by子句中所指定的分组字段及统计函数。
2.having子句的用法
having子句必须与group by 子句配合使用,用于对分组后的结果进行筛选(筛选条件中常含有统计函数)。
3. 分组查询时不含统计函数的条件
通常使用where子句;含有统计函数的条件,则只能用having子句。
模板:select <字符型字段>,count(*) as 列标题 from tb_name where <字符型字段>=’字符串’ group by <字符型字段>;
eg:查询每个地址对应的学生名单
select addr,group concat(name) from student group byaddr
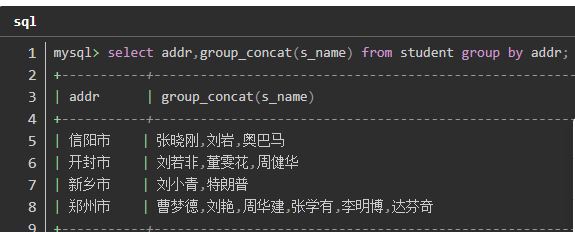
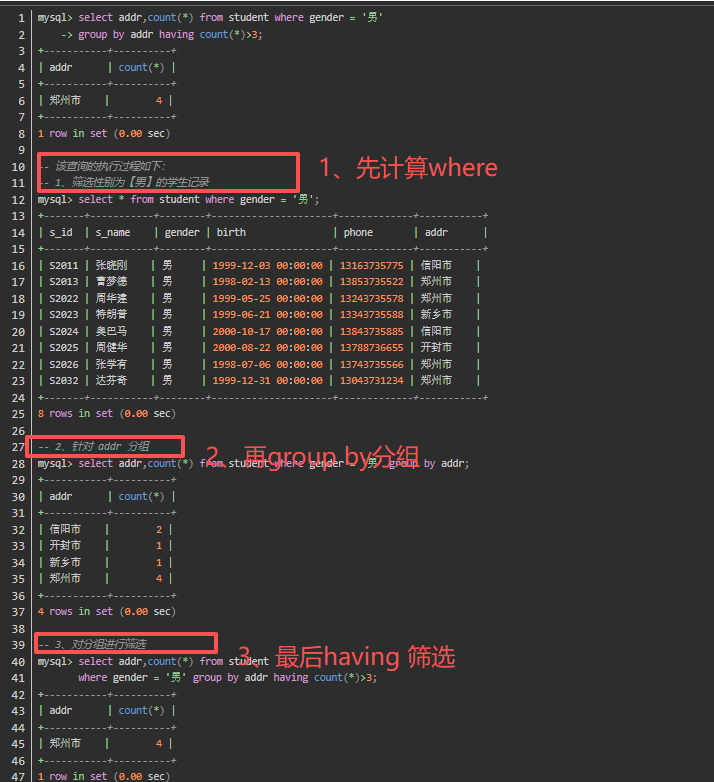
4.结合where 和having 使用时,where> group by> having

 浙公网安备 33010602011771号
浙公网安备 33010602011771号