python爬B站评论(一通百通)
1.前言
由于前段时间在B站看到我关注的一个程序员UP主爬取了自己所有视频下的所有评论并录入到数据库里,进行了一波分析。
我就觉得挺有意思的,而且那时候我还不太会爬虫。正巧,赶上这机会,学习学习爬虫。
参考资源:https://www.cnblogs.com/awesometang/p/11991755.html
2.分析
样例视频:https://www.bilibili.com/video/BV1V44y1T7mY?spm_id_from=444.41.0.0
首先要先看看B站的评论是用哪种方式显示出来的。
用F12是正常能看到网页中的各个元素的,但是打开网页源代码却没有任何有关评论的信息。所以猜测大概率是通过Ajax动态加载的。
那就需要去抓包得到评论数据了。
3.抓包
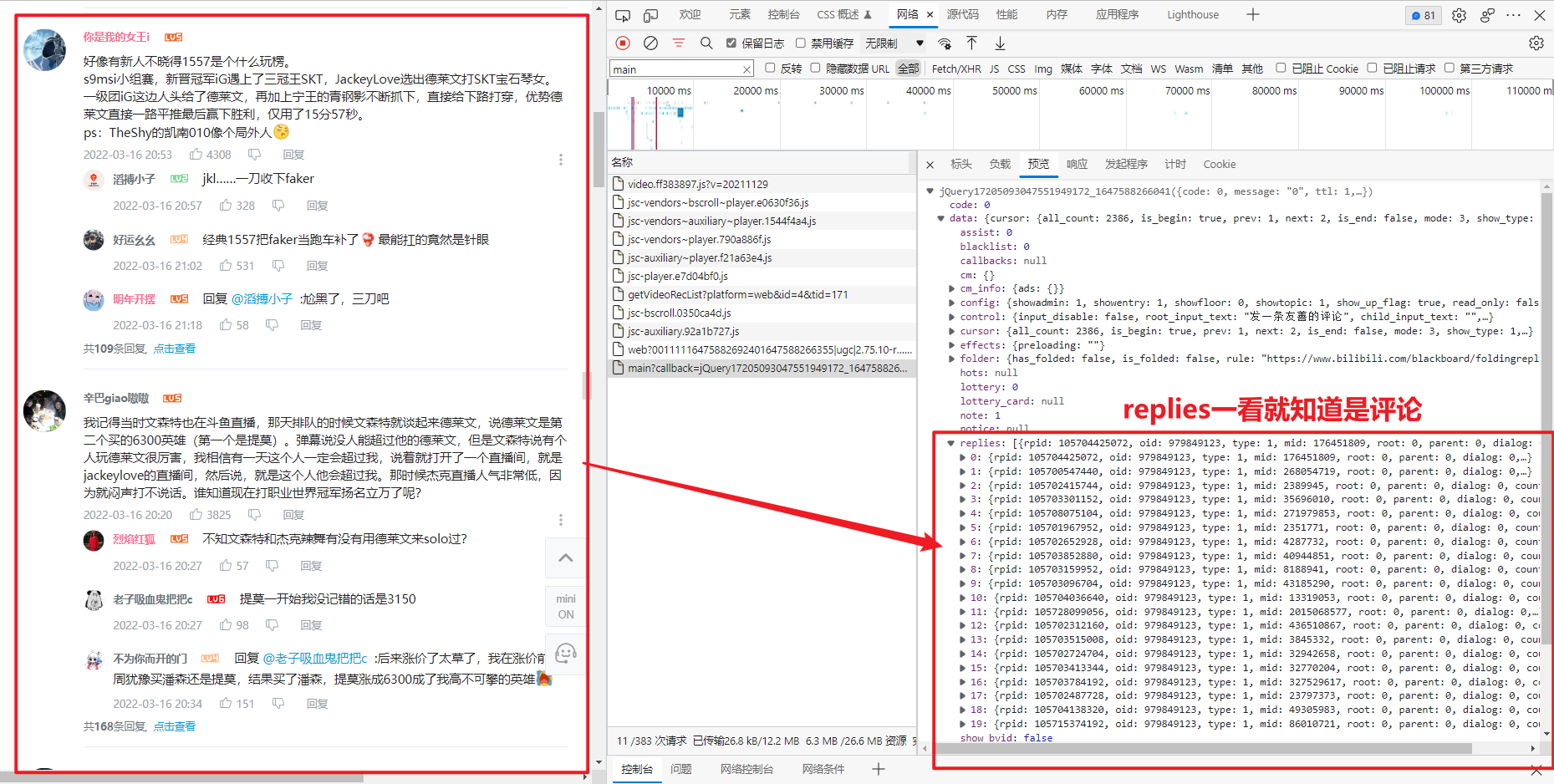
我尝试过直接在网页中使用F12来查看请求,确实可以正常找到视频的 评论 内容,但是无法抓到完整的 评论的评论 内容。
所以,F12的功能似乎并不够满足我们的需求,需要用一个专业的抓包工具——Fiddler(自行下载)

这里不做详细使用教程
3.1 抓评论的包
-
先打开Fiddler
-
清空已拦截到的所有请求,然后挂在旁边
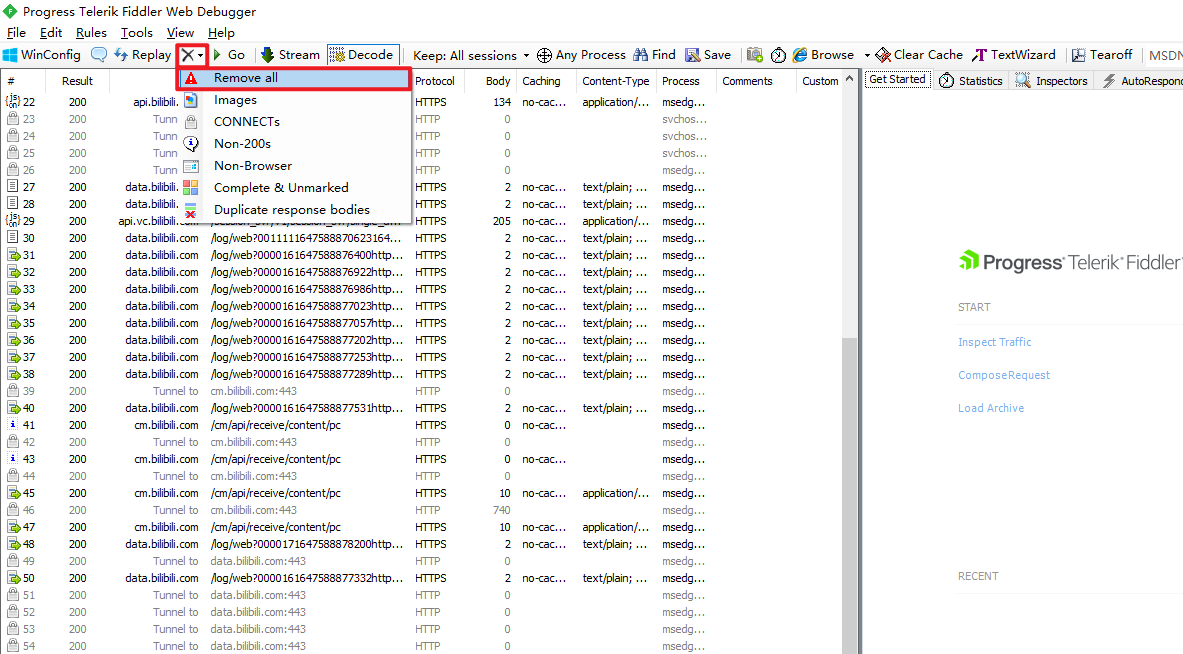
-
刷新B站视频页面,把页面拉到
评论区位置,然后就别动了(为了保证获取评论的请求能被Fiddler拦截到) -
这时候再看Fiddler的页面,能看到已经拦截到了非常多的请求。
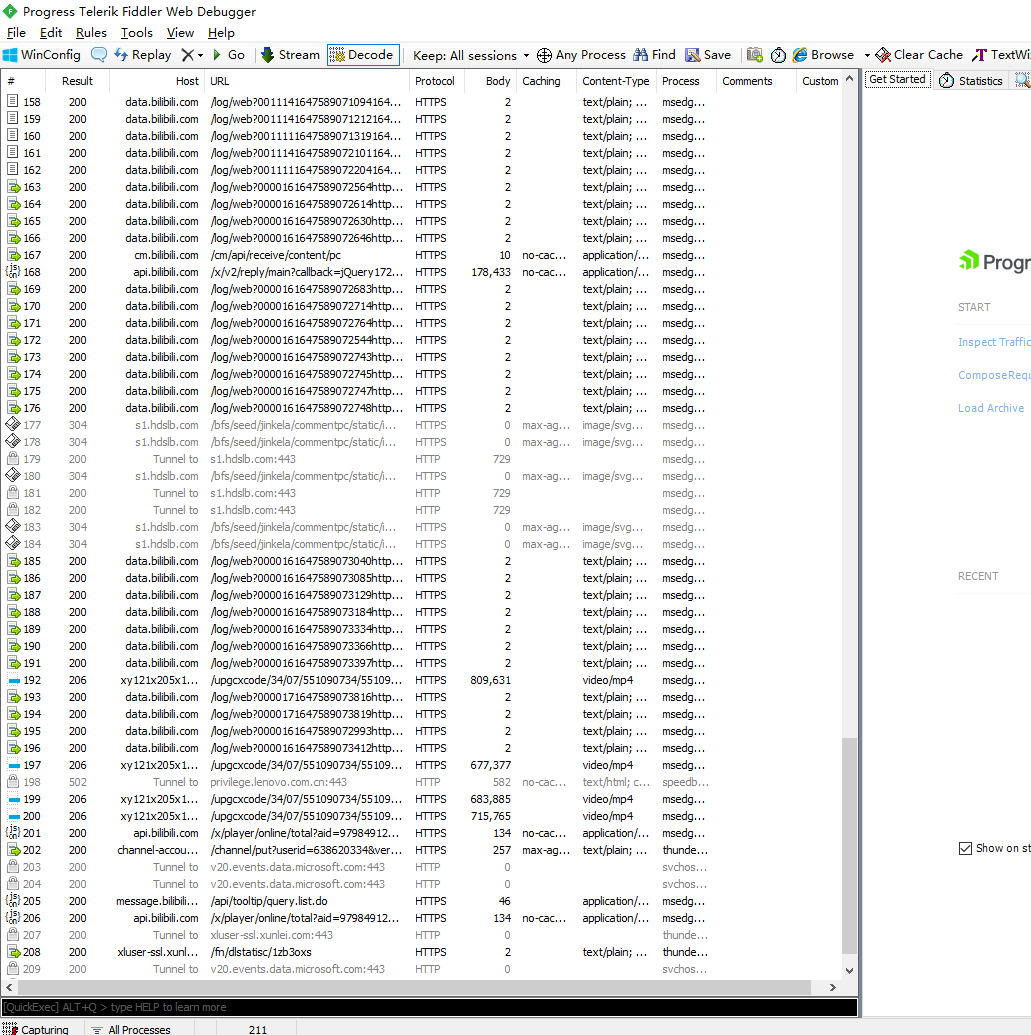
-
经过我们在F12里查看到的,我们可以知道评论的数据是
Json数据。所以我们在Fiddler拦截到的请求里找Json图标的就行。
-
随便双击一个请求,将右侧的视图栏选择到
Json
-
开始找评论。只看Json图标的请求。直到看到以下页面(可能是压缩状态,需要自己展开看)
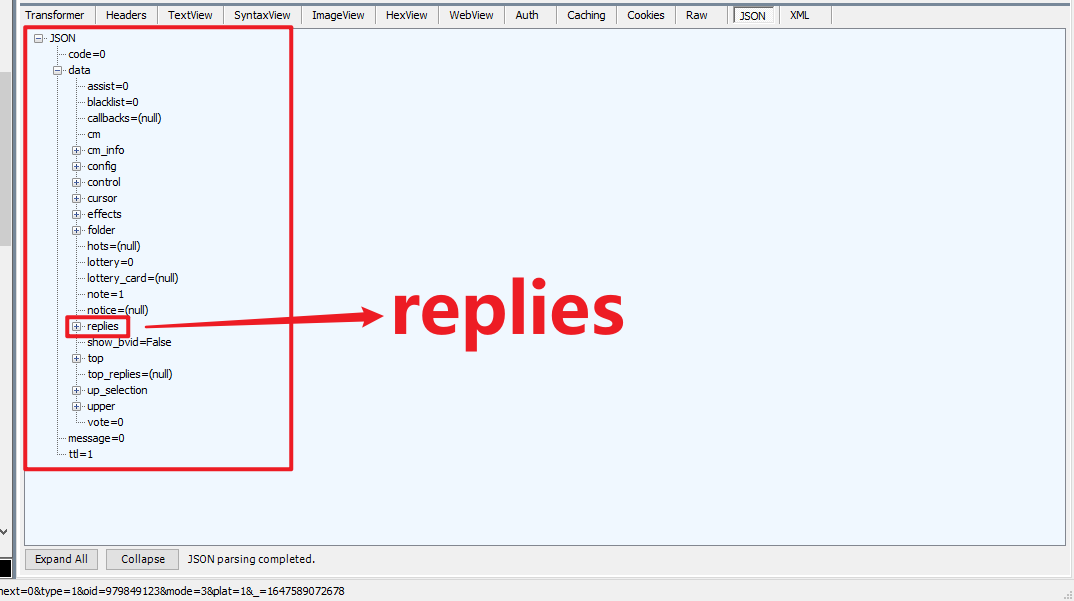
这里我就明说了,评论的请求是带 main 的,所以可以直接在Fiddler中按 CTRL + F 搜索 main
找到一个 main?callback= 。这个就是评论的请求
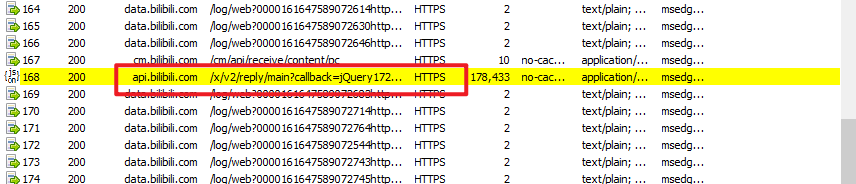
然后我们复制这个请求的 url 并在浏览器中对其进行访问。
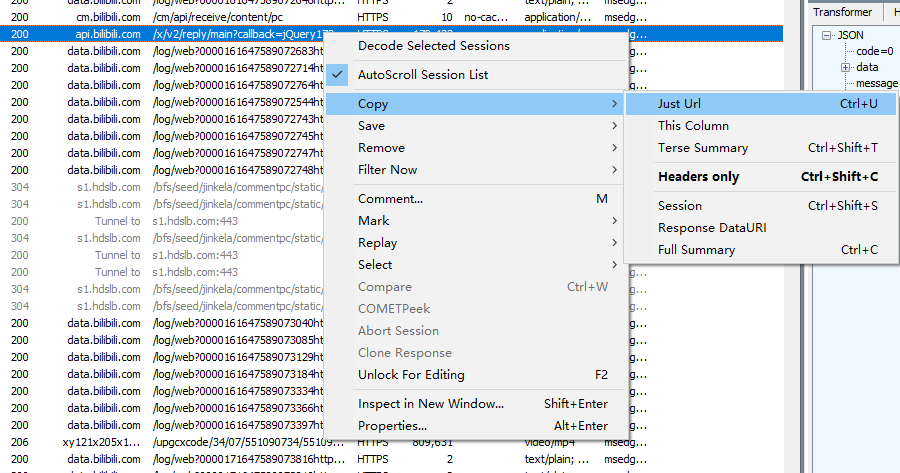
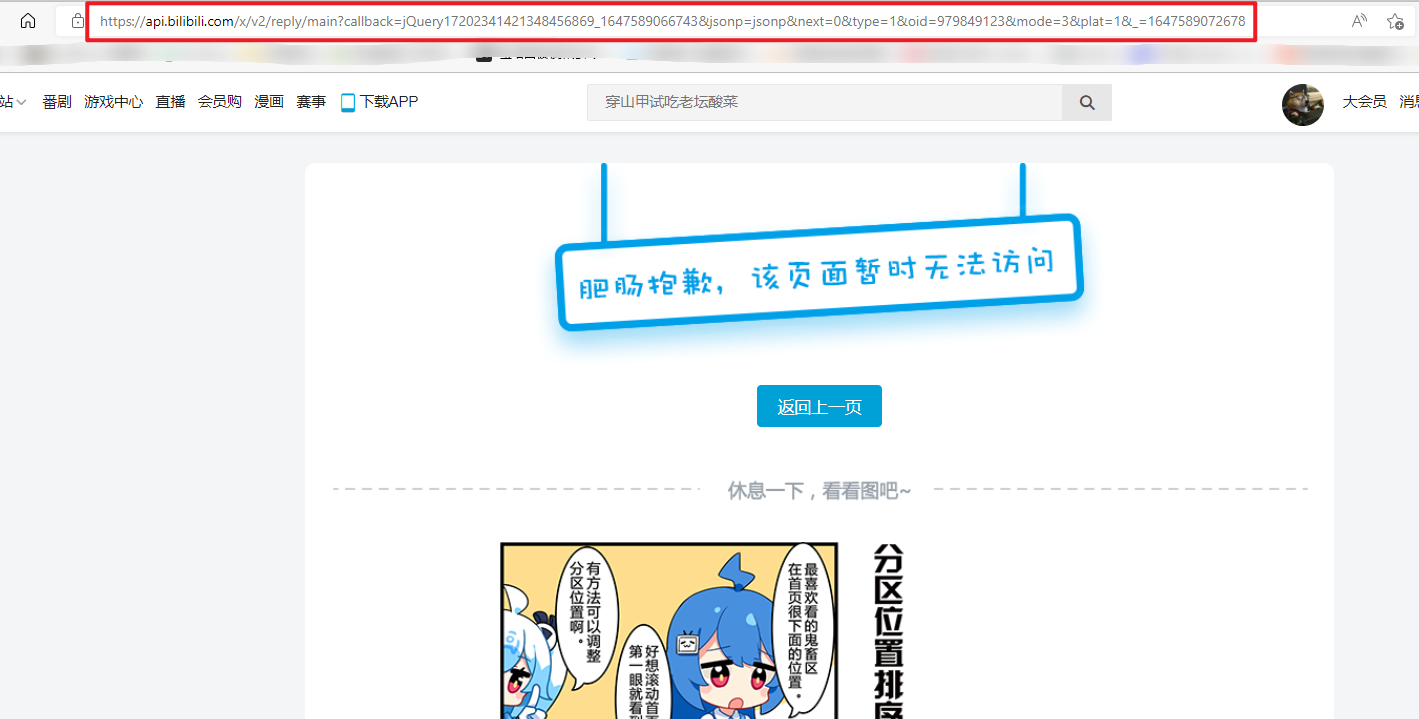
出现了一个问题,我们需要的那个请求的url无法访问,后来尝试才知道,需要删除这一小段(我也不知道为什么)

再次尝试访问:
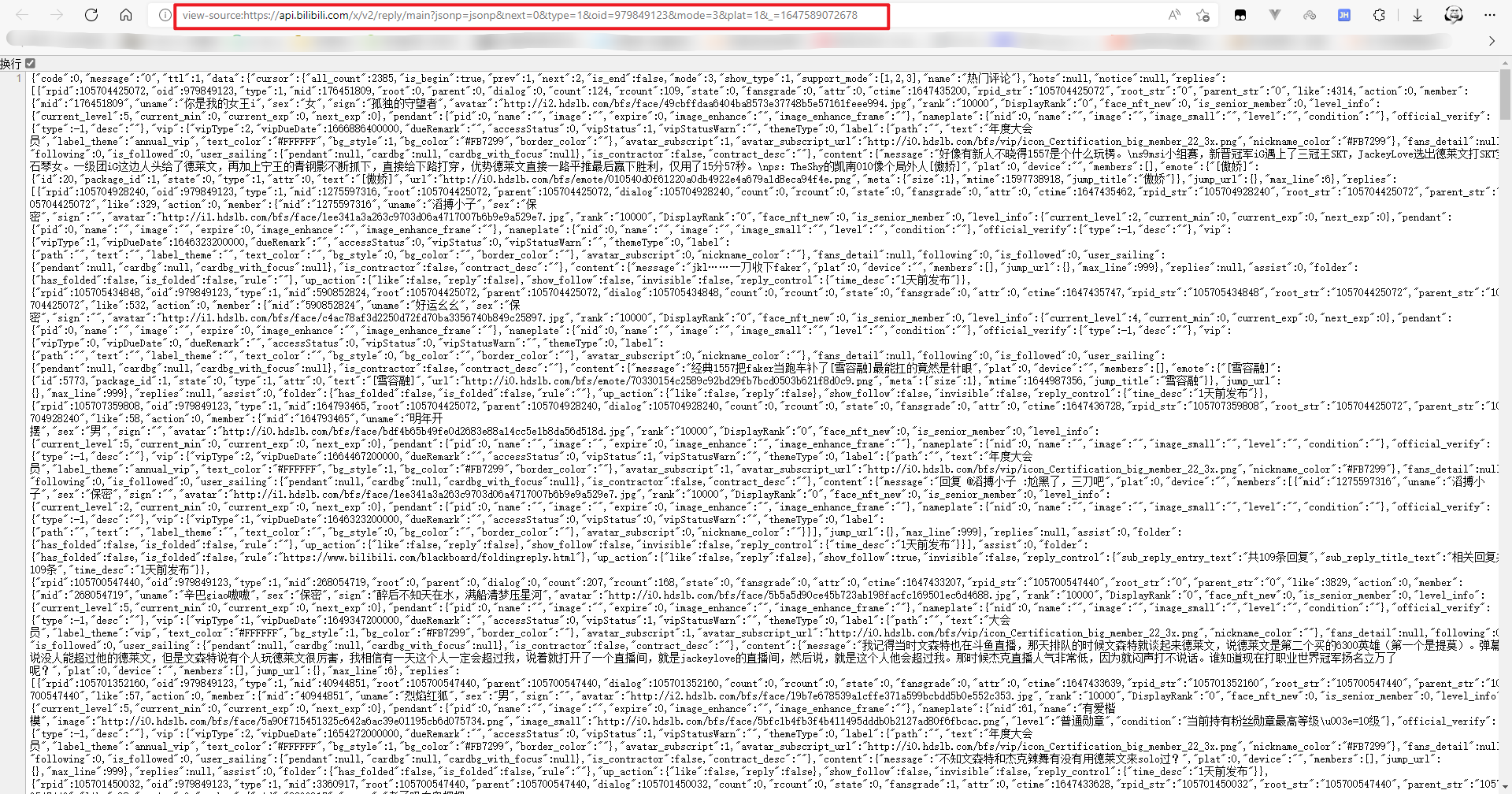
那么现在,我们就已经能够爬取到一段的评论了。可是。。。

搞了这么久,只能拿到20个评论???
因为B站的评论不是一次性全部获取到的,你拉到底,它才会帮你请求后一段的评论数据。整这样👿

没关系,和前面的步骤一样。
清空已拦截的请求-->拉到底-->寻找评论请求
那每一段的评论都不一样,那么每一个请求指定是有某些参数是不一样的。我们可以多抓几个,找到规律。

这里面可以看出来,只有 next 的值是不一样的。
但为什么是 0、2、3 呢,不够规律啊。那我们在看看 next=1 时是什么数据。
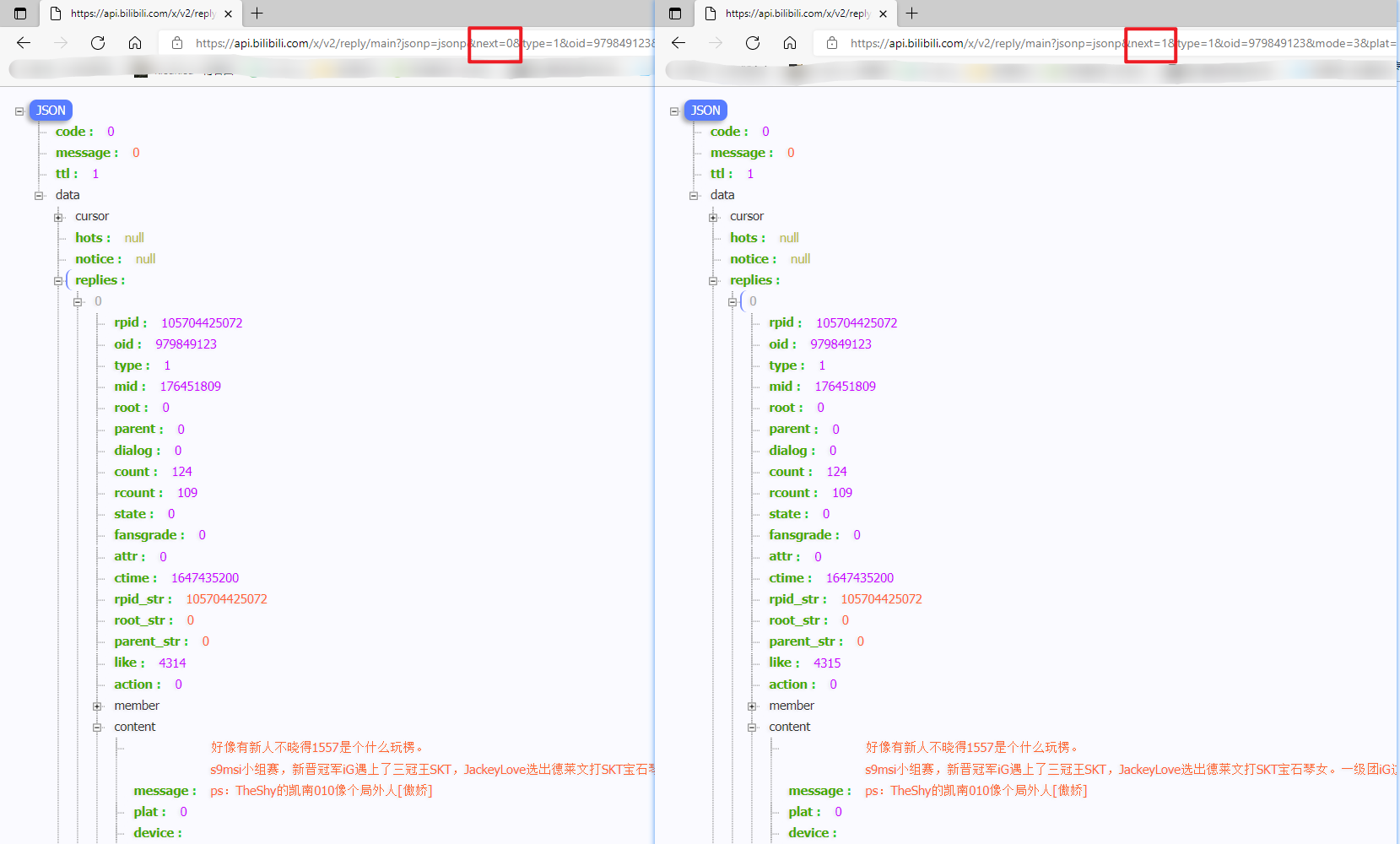
发现 next=1 和 next=0 的数据是一样的。那 0 可能是默认请求的,实际请求的就是 1 。
这样看的话,规律就找到了。
不断递增 next 的值,就可以把所有的评论都拿到手。

3.2 抓评论的评论的包
由于在网页中使用F12是拿不到 评论的评论 的包,所以我们使用 Fiddler 再试一次。
原理和前面一样。
清空已拦截的请求-->点击“点击查看”-->寻找评论的评论请求
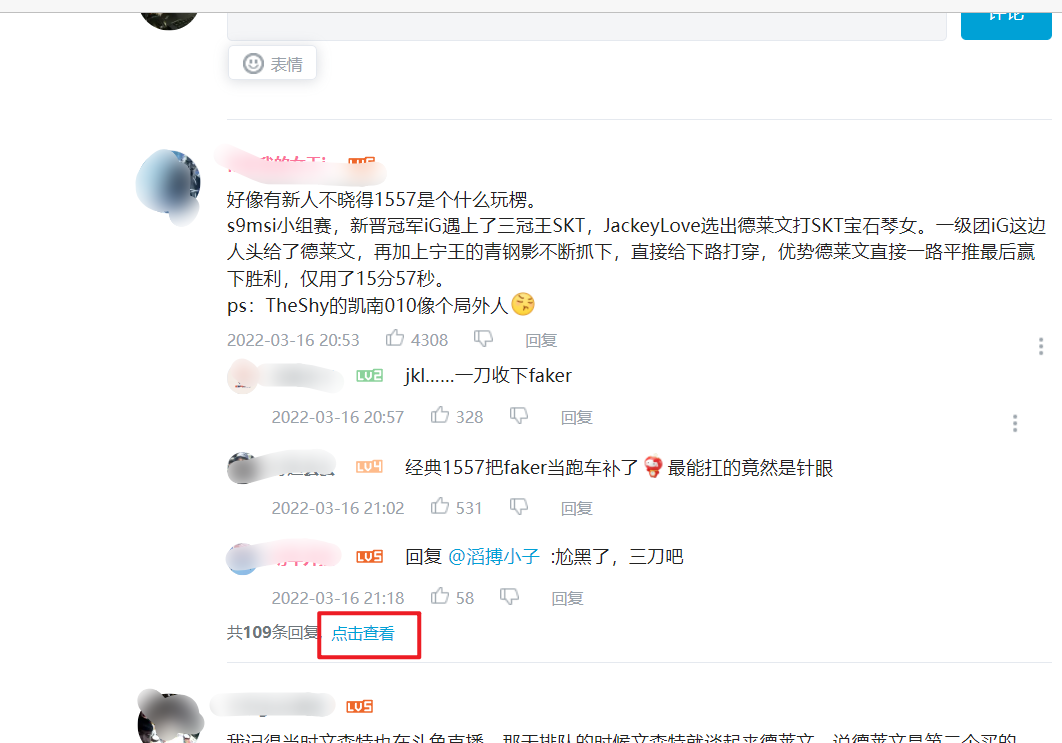
这时再看 Fiddler ,已经拦截到一些请求了
其中有一个和前面很相似的一个 url !!! reply?callback= ? main?callback=
那就一定是它了。
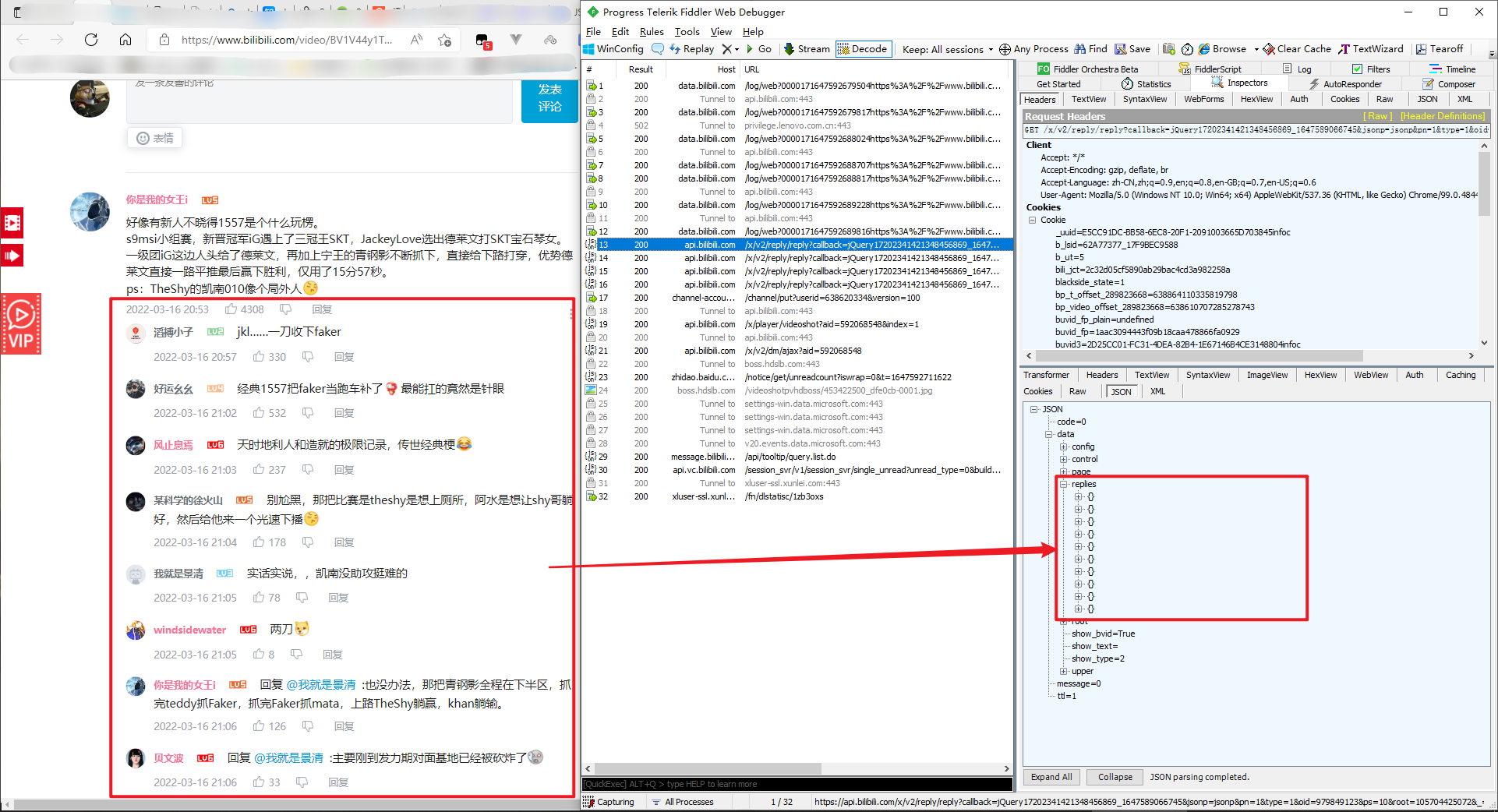
再用刚才的分析法,找到每一页 评论的评论 的请求规律。

这里面可以看出 pn 应该就是我们要找的那个规律。
可是,最后面那串数字怎么也不一样。
我们尝试删除那一段奇怪的数字
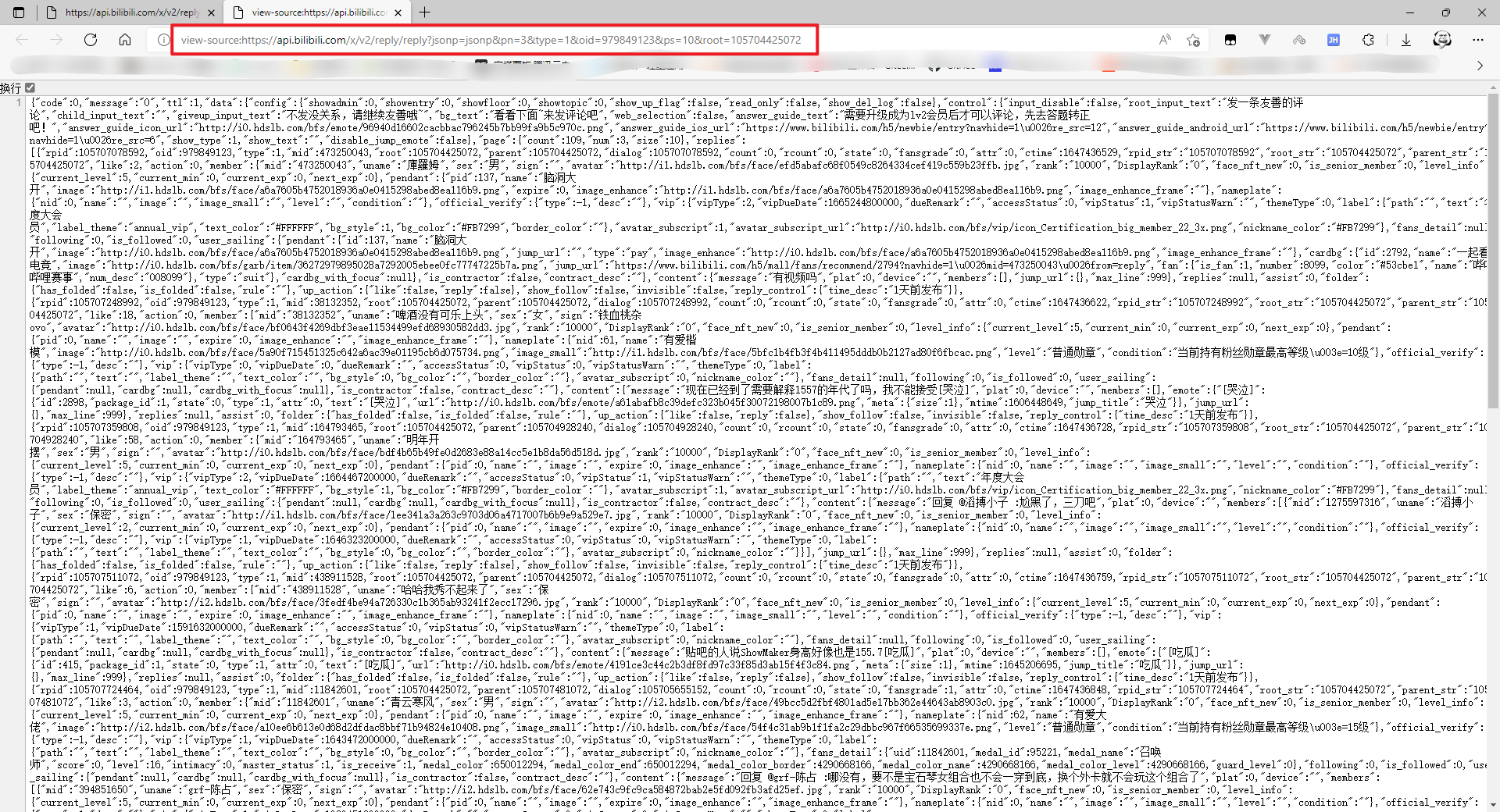
居然也能访问,而且数据都正常,那么后面那一小串奇怪的文字咱就不要了。(加上也无妨,不影响)
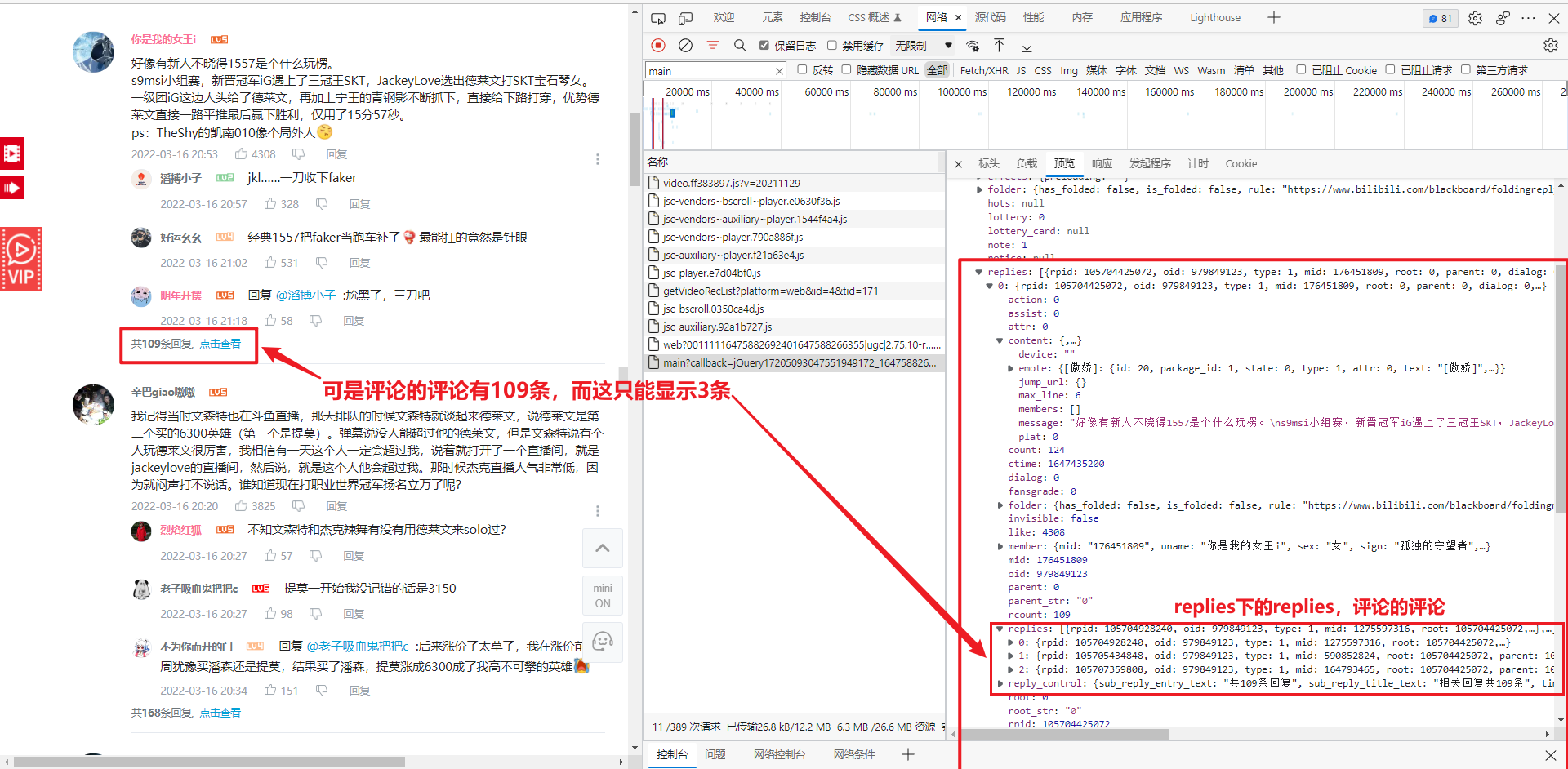
3.3 评论和评论的评论是怎么关联的
学过数据库肯定会知道,要渲染某条评论和这条评论的评论,那么肯定有通过某个东西将他们关联到一起。
这个东西肯定是在保存评论到数据库中时用某个字段联系到一起的。
我们需要找到这个联系,才能知道每个评论和它的子评论。
不弄清关联的话,就无法弄清楚每条评论和它的子评论了。也就无法爬取所有的 评论的评论 了。
我们就找 第一个评论和它的子评论 来研究。

现在,我们已经知道了所有的请求方式和他们之间的联系了。开爬!
4.爬评论
代码写的有点糙,可以自行优化。
# 发送请求
import requests
# 将数据存入数据库
import MySQLdb
# 每次请求停1s,太快会被B站拦截。
import time
# 连接数据库
conn = MySQLdb.connect(host="localhost", user='root', password='admin', db='scholldatabase', charset='utf8')
cursor = conn.cursor()
# 预编译语句
sql = "insert into bilibili(rpid,root,name,avatar,content) values (%s,%s,%s,%s,%s)"
# 爬虫类(面向对象)
class JsonProcess:
def __init__(self):
self.Json_data = ''
# 请求头
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'
}
# 发送爬取请求
def spider(self, URL):
url = URL
response = requests.get(url, headers=self.headers, verify=False)
response.encoding = 'utf-8'
self.Json_data = response.json()['data']['replies']
# 爬取子评论
def getSecondReplies(root):
reply = JsonProcess()
# 页数
pn = 1
# 不知道具体有多少页的评论,所以使用死循环一直爬
while True:
url = f'https://api.bilibili.com/x/v2/reply/reply?jsonp=jsonp&pn={pn}&type=1&oid=979849123&ps=10&root={root}&_=1647581648753'
# 没爬一次就睡1秒
time.sleep(1)
reply.spider(url)
# 如果当前页为空(爬到头了),跳出子评论
if reply.Json_data is None:
break
# 组装数据,存入数据库
for node in reply.Json_data:
rpid = node['rpid']
name = node['member']['uname']
avatar = node['member']['avatar']
content = node['content']['message']
data = (rpid, root, name, avatar, content)
try:
cursor.execute(sql, data)
conn.commit()
except:
pass
print(rpid, ' ', name, ' ', content, ' ', avatar, ' ', root)
# 每爬完一次,页数加1
pn += 1
# 爬取根评论
def getReplies(jp, i):
# 不知道具体有多少页的评论,所以使用死循环一直爬
while True:
url = f'https://api.bilibili.com/x/v2/reply/main?jsonp=jsonp&next={i}&type=1&oid=979849123&mode=3&plat=1&_=1647577851745'
jp.spider(url)
# 如果当前页为空(爬到头了),跳出循环,程序结束。
if jp.Json_data is None:
break
# 组装数据,存入数据库。
for node in jp.Json_data:
print('===================')
rpid = node['rpid']
name = node['member']['uname']
avatar = node['member']['avatar']
content = node['content']['message']
data = (rpid, '0', name, avatar, content)
try:
cursor.execute(sql, data)
conn.commit()
except:
pass
print(rpid, ' ', name, ' ', content, ' ', avatar)
# 如果有子评论,爬取子评论
if node['replies'] is not None:
print('>>>>>>>>>')
getSecondReplies(rpid)
# 每爬完一页,页数加1
i += 1
if __name__ == '__main__':
JP = JsonProcess()
getReplies(JP, 1)
print('\n================存储完成================\n')
conn.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号