读取数据库内容,并在页面渲染
一、题目
-
在本地MySQL创建一个paper数据库,创建表并插入语句(建表语句在最下面)。
-
针对上表,使用SpringBoot框架写一个只接收一个参数的接口,实现功能:
- 传入一个章节id,返回该章节的标题及其子章节的详细内容(如:传入章节id:4587,返回该id对应的章节标题“第1章 绪论”及1.1 、1.2 、1.3 三个子章节的标题和内容)。
-
前端使用Vue写一个界面,在该页面有一个输入框和一个提交按钮;输入一个章节id点击按钮,展示该章节的内容(使用Axios向后端发一个请求,将返回的结果渲染在页面上)。
-
写一篇博客记录过程,及时提交(可以记录一下实现思路、使用了哪些关键技术、中间遇到了哪些困难、解决过程)。
用博客记录自己解决一个问题的过程(建议试试使用Markdown风格文档,使用Typora编辑器),可以参考这一篇:个人编程作业

- 建表语句
DROP TABLE IF EXISTS `edu_paper`; CREATE TABLE `edu_paper` ( `id` char(19) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '本段ID', `parent_id` varchar(19) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '父段落ID', `sort` varchar(19) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '排序', `title` varchar(19) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '标题', `content` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL COMMENT '内容', `is_deleted` tinyint UNSIGNED NOT NULL DEFAULT 0 COMMENT '逻辑删除 1(true)已删除, 0(false)未删除', `gmt_create` datetime NOT NULL COMMENT '创建时间', `gmt_modified` datetime NOT NULL COMMENT '更新时间', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '论文' ROW_FORMAT = Dynamic; INSERT INTO `edu_paper` VALUES ('4587', '0', '0', '第1章 绪论', '/', 0, '2021-07-19 23:07:45', '2021-07-19 23:07:47'); INSERT INTO `edu_paper` VALUES ('4588', '0', '0', '第2章 技术背景介绍', '/', 0, '2021-07-19 23:11:34', '2021-07-19 23:11:36'); INSERT INTO `edu_paper` VALUES ('8888', '4587', '1', '1.1 研究背景', '“大数据”已经成为互联网信息技术行业的流行词汇,信息技术广泛应用。大数据带来的信息风暴正在变革我们的生活、工作和思维[1]。大数据的数据来源众多,数据类型丰富,包括结构化和非结构化数据。但面对如此众多的数据,如何通过一系列的分析与挖掘,解决各种各样的难题,从数据中得到对我们有帮助的信息,需要通过长时间的研究才能得到答案。', 0, '2021-07-19 23:08:43', '2021-07-19 23:08:46'); INSERT INTO `edu_paper` VALUES ('8889', '4587', '2', '1.2 研究意义', '自然语言理解(在此指书面语言的计算机理解)也称自然语言处理,它是计算语言学的分支,是人工智能研究中一个十分活跃的领域,自然语言理解从简单的语言信息处理到理解篇章,会话,走向认知科学,经历了二十年的发展历程[2]。随着高科技的迅速发展,其应用深入人们生活的各个方面[3]。对于本课题来说,使用自然处理技术对招聘文本进行分析的价值在于,一是对于大学生学习来说,这个模型可以帮助他们加强技术的学习;二是对于大学生就业,当面对海量招聘信息无法确定最合适自己的岗位时,这个模型可以根据自身所学的技术推荐合适的岗位;三是对于学院的学科建设,由于计算机技术每年变动较大,这个模型可以帮助老师调整教学计划,跟上社会的技术变动。', 0, '2021-07-19 23:09:24', '2021-07-19 23:09:26'); INSERT INTO `edu_paper` VALUES ('8890', '4587', '3', '1.3 研究内容', '本课题是基于NLP的招聘文本分析与挖掘,使用数据预处理、文本向量化、自然语言处理(NLP)、关联分析等技术对招聘文本进行分析与挖掘。主要内容为:提取所需数据,去除“脏数据”,对数据进行分句分词操作。进行文本向量化操作。利用K-Means聚类算法获取技术名词列表。', 0, '2021-07-19 23:10:39', '2021-07-19 23:10:42'); INSERT INTO `edu_paper` VALUES ('8891', '4588', '1', '2.1 Word2vec', 'Word2vec是Google在2013年提出的用于快速有效地训练词向量的模型[4]。通过将文本数据输入到一个学习模型中,Word2vec输出的词向量可以表示为一大段文本,甚至整篇文章[5]。word2vec有连续词袋模型(Continuous bag-of-words,CBOW)和Skip - Gram两种模型。word2vec能够将文本词语转化为向量空间中的向量,而向量的相似度可以表示文本语义的相似度[6]。Xxxxxxx', 0, '2021-07-19 23:12:22', '2021-07-19 23:12:25'); INSERT INTO `edu_paper` VALUES ('8892', '4588', '2', '2.2 K-Means聚类', 'K-Means算法是聚类算法中主要算法之一,它是一种基于划分的聚类算法[7]。K-Means算法因其在大型数据集聚类方面的效率而闻名[8]。', 0, '2021-07-19 23:13:26', '2021-07-19 23:13:29'); INSERT INTO `edu_paper` VALUES ('8893', '4588', '3', '2.3 关联分析', '关联规则是数据挖掘中一种重要的挖掘方法,可发现被研究对象与对研究对象有影响的各因素之间的关联关系[9]。', 0, '2021-07-19 23:14:17', '2021-07-19 23:14:19'); SET FOREIGN_KEY_CHECKS = 1;
二、实现过程
-
实现思路
-
要先在配置文件中配置MySQL驱动(用yaml配置文件)。然后连接数据库,建表。
spring: datasource: username: root password: admin url: jdbc:mysql://localhost:3306/paper?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8 driver-class-name: com.mysql.cj.jdbc.Driver -
建表成功,数据库中存放论文的数据。
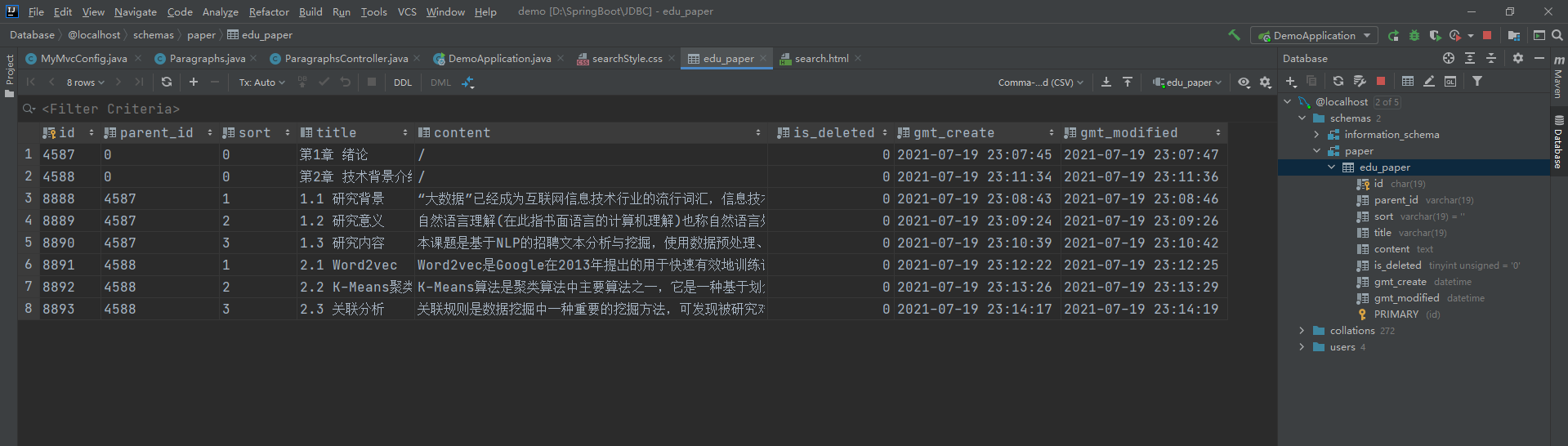
-
建一个简易的前端页面。
- 用户在前端页面上输入章节id,点击按钮之后,前端接收id,输入框中的信息能发送到后端。必须用
form标签包围,才能跳转到/paragraph,执行ParagraphsController.java。
//这个文件是 search.html <!DOCTYPE html> <html lang="en" xmlns:th="http://www.thymeleaf.org"> <head> <meta charset="UTF-8"> <title>SearchParagraph</title> <link rel="stylesheet" th:href="searchStyle.css"> </head> <body> <form th:action="@{/paragraphs}" class="box"> 请输入章节ID:(如:4587)<br><br> <input type="text" name="id" th:placeholder="${msg1}"> //传递id的值 <button>查询</button> <pre style="word-wrap: break-word;font-size: 23px" th:text="${para}" class="wordsBox"></pre> </form> </body> </html>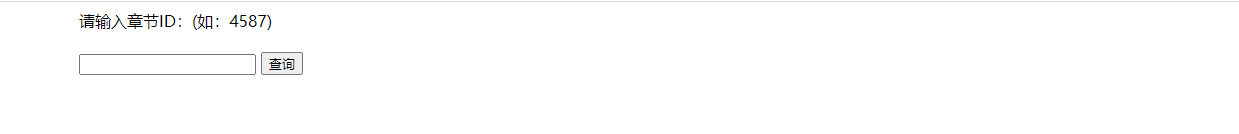
- 用户在前端页面上输入章节id,点击按钮之后,前端接收id,输入框中的信息能发送到后端。必须用
-
在启动文件的同级目录下建一个config/MyMvcConfig.java文件,用于地址访问。(localhost:8080/search.html)会跳到search.html页面。
@Controller @Configuration public class MyMvcConfig implements WebMvcConfigurer { @Override public void addViewControllers(ViewControllerRegistry registry) { registry.addViewController("/search.html").setViewName("search"); } } -
用Spring Boot将前后端连接,让前端可以接收后端的数据,后端也可以接收前端的数据。
- 后端接收到前端的id,到数据库中寻找id对应的数据(章节的标题及其子章节的内容),并将数据返回给前端。
- 前端接收后端发送的数据,并显示在页面上。
@Controller public class ParagraphsController { @Autowired JdbcTemplate jdbcTemplate; //直接访问这个地址,会直接启动这个方法。 @GetMapping("/paragraphs") //接收name = "id"的值并赋给id。Model model用来将数据显示在前端。 public String paragraphs(@RequestParam("id") String id, Model model) { if (!StringUtils.isEmpty(id)) { //章节id继续显示在输入框中。 model.addAttribute("msg1", id); //获取数据库中所有数据 String sql = "select * from edu_paper"; List<Map<String, Object>> list = jdbcTemplate.queryForList(sql); List<String> stringList = new ArrayList<>(); //遍历集合,找到id对应的章节。 for (Map<String, Object> map : list) { //找到id对应的章节 if (map.get("id").equals(id)) { stringList.add(map.get("title").toString()); } //找到对应章节后再找子章节(子章节的id一定比章节标题的id大) if (map.get("parent_id").equals(id)) { stringList.add(map.get("title").toString()); stringList.add(map.get("content").toString()); } } if (stringList.isEmpty()){ model.addAttribute("para","[无此id]"); return "search"; } //将收集到的段落添加到字符串中发送给前端,用<pre>标签包围,保证以字符串原格式显示。 String string = ""; for (String str : stringList) { string += (str + "\n\n"); } //把值传到前端页面,并显示在页面上。 model.addAttribute("para", string); return "search"; }else { model.addAttribute("para","[id为空]"); return "search"; } } }
-
-
使用的关键技术
- MySQL数据库。(安装了MySQL服务,为了让数据库内容可视化,又安装了Navicat(其实没用到),连接数据库。)
- Spring Boot框架(Java工程师必备)
- 前端(html和css,做了一个简易页面)
-
遇到的困难
- 对Spring Boot是完全陌生的概念。
- 后端从数据库中获取到匹配的数据要发送给前端时,数据之间的回车被吃了,数据全部黏在一起,没有分开。
-
解决过程
-
花了挺多时间去学,去理解了Spring Boot的一些知识,学会了前后端分开,并且能相互连接。(后来才发现,我用的是模板引擎,还不算是前后端分离)以足够完成《第一个小目标》。
-
用pre标签可以显示字符串的原格式,可以将字符串原封不动的输出(包括\n) 。但是,pre标签内的文字超出盒子也不会换行,所以要手动在css中设置pre的格式。
pre{ width: 1300px; /*height: 1300px;*/ word-wrap: break-word; white-space: pre-wrap; }
-
三、完成情况
完成的方法比较笨,能满足基本功能,但如果数据库太大,有可能会出现问题。
整个作业中用了MySQL、Spring Boot、前端。因为时间有点匆忙,没有用到Vue和Axios。找时间学习并完善一下。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号