

| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | 制作一个程序统计和分析 GitHub 的用户行为数据。 |
| 学号 | 031802542 |
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 90 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 120 | 120 |
| Analysis | 需求分析 (包括学习新技术) | 180+ | 360 |
| Design Spec | 生成设计文档 | 30 | 0 |
| Design Review | 设计复审 | 10 | 0 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| Design | 具体设计 | 0 | 0 |
| Coding | 具体编码 | 0 | 0 |
| Code Review | 代码复审 | 20 | 0 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 10 |
| Reporting | 报告 | 30 | 60 |
| Test Report | 测试报告 | 10 | 0 |
| Size Measurement | 计算工作量 | 10 | 0 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 540+ | 705 |
至2020.9.13
花了40分钟多时间学习了Github的使用,虽然依旧是云里雾里但好歹勉强会用了。同时花了20分钟左右看了代码规范。
看了样例数据发现是json文件格式同时对格式一无所知完全不知道怎么处理,询问了学长这类作业的捷径,被推荐使用pythonpython大法平安保。
2020.9.14
学长:“我曾经花了一天就学完了python。”
晚上花了2个小时多查找了有关python导入json文件的资料,以及自己再反复琢磨,大概有了以下代码:
import json
#实现读入json文件并且输出每个事件的类型
file = open('inputfile.json', 'r', encoding='utf-8')
for x in file:
y = json.loads(x)
print(y['type'])
目前对于json文件格式大致有个了解了。需要的有事件类型、用户和对应项目,目前找到了事件类型和用户(id)但找不到项目对应名字的位置。
以及对格式要求的一些交互操作完全没有了解,同时对本身python也比较陌生,还有如何存储大数据的问题。
预计明天解决:在小数据规模的情况下,统计每个人4种事件个数。
2020.9.15
稍微花了1小时整理了一下思绪:
初始化:读入文件夹,访问文件夹里的所有json文件并将数据进行处理
数据处理方法:
1.定义类pers,包含四种event的个数,表示一个用户的四种事件分别的个数
2.定义类proj,包含不定个pers类,表示一个项目由不定数量的用户管理(项目的事件个数由各个用户的事件个数统计)
3.读入处理的流程图如下:
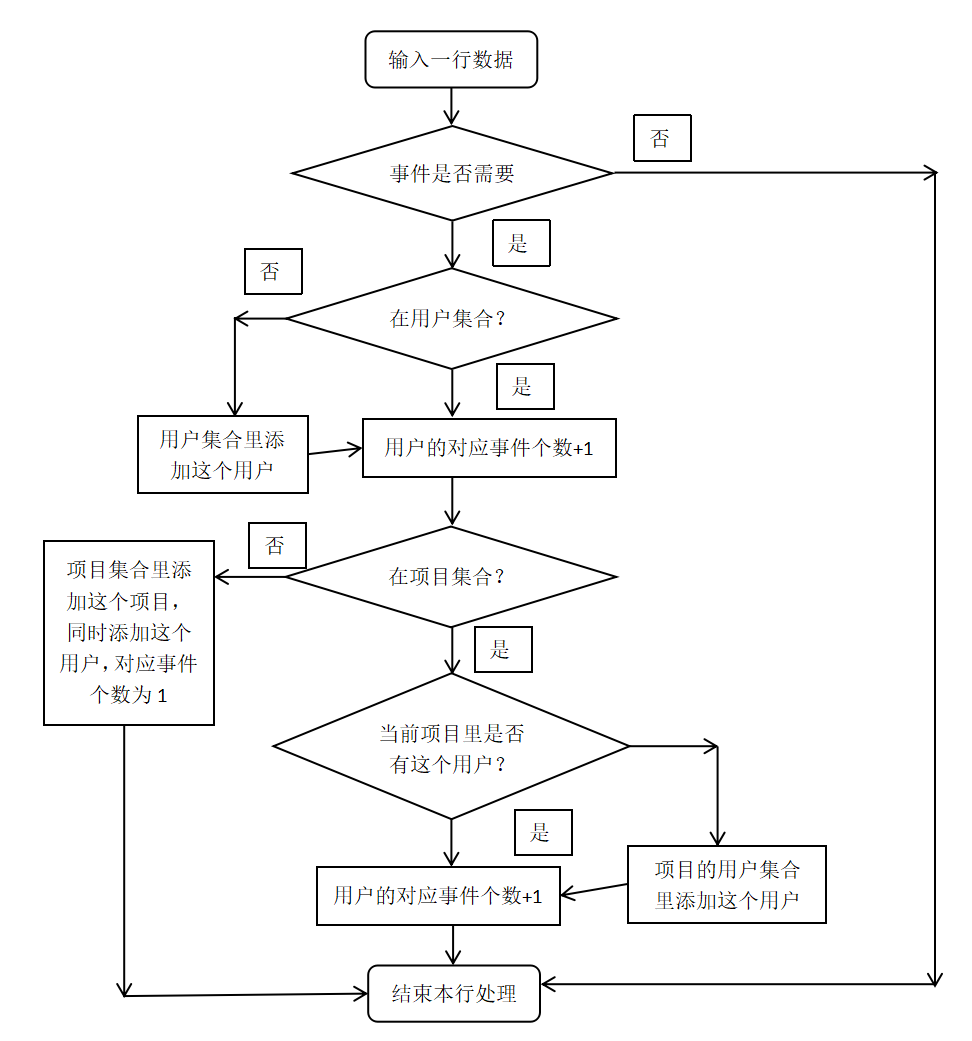
4.对于询问的处理:
(1)如果是查询用户的事件个数,直接在用户集合里查找
(2)如果是查询某项目的事件个数,查找该项目并遍历项目中的所有用户的该事件,值相加得到结果
(3)如果是查询用户在某个项目中的事件个数,查找该项目并查找用户的该事件
还花了大概不到1小时时间读了读示例代码和目前已经提交过的同学的作业的代码拓宽思路,但感觉思路有点被带偏了所以最后还是打算大体上按自己的想法写(可能有些细节会去参考,比如指令设置)。
又花了3个多小时百度以及乱搞学习,熟悉了python的最基础的使用,进度上已经能将基础的数据处理转移进类里了:
import json
def trans(x):
#将事件转化成对应标号,-1表示不合法事件
if x == 'PushEvent':
return 0
if x == 'IssueCommentEvent':
return 1
if x == 'IssuesEvent':
return 2
if x == 'PullRequestEvent':
return 3
return -1
class Person():
def __init__(self,name):
self.name = name
self.evecnt = [0,0,0,0]
def addeve(self,event):
#添加事件
++ self.evecnt[trans(event)]
class Project():
def __init__(self,name):
self.name = name
self.group = list()
def addeve(self,pers,event):
#添加事件(如果用户不在项目中则将用户加入项目中)
Flag = 0
for i in self.group:
if group[i].name == pers.name:
++ group[i].evecnt[event]
Flag = 1
break
if Flag == 0:
temp = Person(tmp.name)
temp.addeve(event)
self.group.append(temp)
allPerson = list()
allProject = list()
file = open('inputfile.json', 'r', encoding='utf-8')
for i in file:
y = json.loads(i)
evetype=trans(y['type'])
if not evetype == -1:
tmp = Person(y['actor']['id'])
tmp.addeve(y['type'])
#添加用户
Flag=0
for j in allPerson:
if j.name == tmp.name:
j.addeve(evetype)
Flag=1
break
if Flag == 0:
allPerson.append(tmp)
#添加项目
projName = y['repo']['id']
Flag=0
for j in allProject:
if j.name == projName:
j.addeve(tmp,evetype)
Flag=1
break
if Flag == 0:
temp = Project(projName)
temp.addeve(tmp,evetype)
allProject.append(temp)
#测试输出所有用户和项目
for i in allPerson:
print(i.name)
print("**")
for i in allProject:
print(i.name)
print(":")
for j in i.group:
print(j.name)
print("--")
虽然今天还完成不了统计但感觉快了(主要是明天时间多)。
2020.9.16
下午花了大概1个多小时看了看其他目前已经提交过博客的同学的代码和样例代码,看不懂的百度,虽然还是有点云里雾里,但可以肯定的一点就是数据量大到需要把输入的数据处理完输出,之后询问再访问处理过的数据。由于之前存储方式是需要将输入数据不断比对,视情况加入,数据量大到没法一次全部输出,比对过程不断访问输出文件也是很麻烦的事情,所以之前的设计全部都得否决。
那能想到的优化办法就只有去除输入的冗余信息然后输出,之后查询的时候遍历输出信息。
又花了大概3个小时以上(其实已经有点无法估计了)的时间了解参数指令以及文件的输入输出相关内容,但由于快到ddl了所以没法很系统的学,大多数都是在复制粘贴。感谢丘总的帮助,我参考了她的博客,她也非常及时回答了我私聊的问题,当然也很感谢在群里帮忙解答的以及已经提交了作业的各个同学,你们的群里问答和博客都给我带来了不少收获。
那么先从最头疼的如何解决输入开始说起:
#指令参数初始化
def __init__(self):
self.parser = argparse.ArgumentParser()
self.data = None
self.argInit()
print(self.analyse())#开始调用指令
#指令参数添加
def argInit(self):
self.parser.add_argument('-i', '--init')
self.parser.add_argument('-u', '--user')
self.parser.add_argument('-r', '--repo')
self.parser.add_argument('-e', '--event')
看了很多人的写法看的脑阔有点疼,最后发现还是样例写的比较简洁(实际上是网上的代码也差不多,但是要一点点复制下来改,所以懒得整了)。
这样一来之后就可以用 parser.parse_args() 的这几个参数了(格式如下):
#初始化
if self.parser.parse_args().init:
#init返回的是输入数据文件夹位置
read(self.parser.parse_args().init)
return 0
else:
#访问已处理数据
if self.data is None:
self.data = open('data.json', 'r', encoding = 'utf-8')
return solve(self.data,
self.parser.parse_args().user,
self.parser.parse_args().repo,
self.parser.parse_args().event)
处理输入数据(文件搜索也是参考样例写的光速跑):
def read(path):
#初始化data文件以防重复写入
with open('data.json', "w", encoding='utf-8') as f2:
f2.write('')
#搜索path路径下的所有json文件
for root, dic, files in os.walk(path):
for file in files:
if file[-5:] == '.json':
json_path = file
filedir = open(path + '\\' + json_path, 'r', encoding='utf-8')
with open(json_path, encoding = 'utf-8') as f:
for i in f:
y = json.loads(i)
evetype = trans(y['type'])
#如果事件合法,将事件需要的信息提取出来写入data文件
if not evetype == -1:
#提取关键数据到dict1
dict1 = {}
dict1['event'] = evetype
dict1['user'] = y['actor']['login']
dict1['repo'] = y['repo']['name']
#再把dict1输出到data
dict2 = json.dumps(dict1)
with open('data.json', "a", encoding='utf-8') as f2:
f2.write(str(dict2) + '\n')
对于每个询问的解决方法(因为看过丘总的解法印象很深所以写的时候完全被她的思路带跑了):
def solve(data, user, repo, event):
ans = 0
for i in data:
y = json.loads(i)
if not len(user) == 0:
if not user == y['user']:
continue
else:
pass
else:
pass
if not repo == None:
if not repo == y['repo']:
continue
else:
pass
if trans(event) == y['event']:
ans = ans + 1
else:
pass
return ans
单纯拿了几行数据试手,至少目前还没发现什么问题(这个是已经初始化之后输入的结果):

今天主要解决了代码的核心问题——小规模数据能正确运行,(如果明天还没截止的话)明天解决Github相关工作以及性能测试。
2020.9.17
今天是真的没空了所以只做了Github的提交(而且提交的很不像样):

还是做的太仓促了,以后得好好规划一下时间,不能最后几天赶工。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号