
学习Word2vec
有感于最近接触到的一些关于深度学习的知识,遂打算找个东西来加深理解。首选的就是以前有过接触,且火爆程度非同一般的word2vec。严格来说,word2vec的三层模型还不能算是完整意义上的深度学习,本人确实也是学术能力有限,就以此为例子,打算更全面的了解一下这个工具。在此期间,参考了[1][2][3]的博文,尤其以[1]的注释较为精彩。本文不涉及太多原理,想要对word2vec有更深入的了解,可以阅读Mikolov在2013年的两篇文章[4][5]。同时文献[6]对word2vec中的模型和一些小技巧进行了详细说明。
目前来说,词向量还是一个比较火的东西,今天还在微博上看到一些大牛在转发斯坦福关于“深度学习和自然语言处理”的课程,里面就讲到这些。同时,在参加老板组织的一个国际会议优秀论文报告会上也发现,今年(2015)的ACL和IJCAI也有一些关于词向量的优质论文。词向量,顾名思义,就是用一个向量来表示一个单词,这个向量不是随便的一个,而是根据单词在语料中的上下文而产生,具有意义的向量。而word2vec就是根据语料来生成单词向量的一个工具。生成单词向量有什么用?最主要的一点就是用来计算相似度。直接计算两个词的余弦值便可以得到。还有一个用途就是机器翻译,如图1所示是英语的数字1-5和西班牙语的数字1-5的词向量,经过主成份分析(PCA)在二维空间上的映射。可以发现,两种语言的1-5对应的位置相差无几,这说明两种不同语言对应向量空间的结果之间具有相似性。当然,词向量的作用还有很多很多,此处不一一介绍。
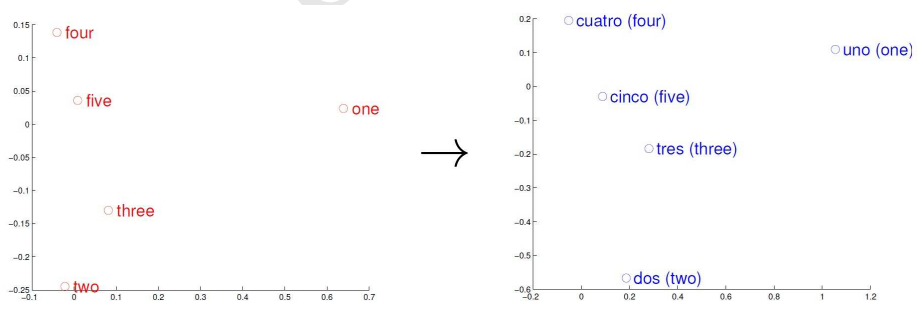
图1. 五个词在两个向量空间中的位置
说实话,之前也看过一些word2vec的讲义,大多是讲数序模型,公式推导之类的。很难理清思路,看过两三遍之后还是没能理清他具体是怎么进行的,一开始最让小白我困惑的是Skip-gram模型和CBOW模型,什么用上下文预测中间词,用中间词预测上下文,这语料哪涉及到预测啊!?后来看了源码发现,其实这是模型训练的一种思路,用这两种思路进行调参。两者的区别除了在于:
cbow模型是用上下文预测中间的词,并且参数是用的上下文词向量的和
skip-gram模型是中间的词预测上下文,并且参数是中间词的词向量
下面小白我就对word2vec的源码做一些解析,是在[1]的基础上,结合了一些自己的理解。主要包含一些辅助函数的作用,参数的设置和训练的过程:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#include <pthread.h>
// 一个word的最大长度
#define MAX_STRING 100
// 对f的运算结果进行缓存,存储1000个,需要用的时候查表
#define EXP_TABLE_SIZE 1000
// 最大计算到6 (exp^6 / (exp^6 + 1)),最小计算到-6 (exp^-6 / (exp^-6 + 1))
#define MAX_EXP 6
// 定义最大的句子长度,句子以</s>结束,如果没有结束符,则长度最长为1000
#define MAX_SENTENCE_LENGTH 1000
// 定义最长的霍夫曼编码长度
#define MAX_CODE_LENGTH 40
// 哈希,线性探测,开放定址法,装填系数0.7
const int vocab_hash_size = 30000000; // 词库中最多有30 * 0.7 = 21M个单词
typedef float real; // 浮点数精度
struct vocab_word {
long long cn; // 单词词频
int *point; // 霍夫曼树中从根节点到该词的路径,存放路径上每个非叶结点的索引
char *word, *code, codelen; // 分别是词的字面,霍夫曼编码,编码长度
};
// 训练文件、输出文件名称定义
char train_file[MAX_STRING], output_file[MAX_STRING];
// 词汇表输出文件和词汇表读入文件名称定义
char save_vocab_file[MAX_STRING], read_vocab_file[MAX_STRING];
// 声明词汇表结构体
struct vocab_word *vocab;
// binary 0则vectors.bin输出为二进制(默认),1则为文本形式
// cbow 1使用cbow框架,0使用skip-gram框架
// debug_mode 大于0,加载完毕后输出汇总信息,大于1,加载训练词汇的时候输出信息,训练过程中输出信息
// window 窗口大小,在cbow中表示了word vector的最大的sum范围,在skip-gram中表示了max space between words(w1,w2,p(w1 | w2))
// min_count 删除长尾词的词频标准
// num_threads 线程数
// min_reduce ReduceVocab删除词频小于这个值的词,因为哈希表总共可以装填的词汇数是有限的
int binary = 0, cbow = 0, debug_mode = 2, window = 5, min_count = 5, num_threads = 1, min_reduce = 1;
int *vocab_hash; // 词汇表的hash存储,下标是词的hash,内容是词在vocab中的位置,a[word_hash] = word index in vocab
// vocab_max_size 词汇表的最大长度,动态扩增,每次扩1000
// vocab_size 词汇表的现有长度,接近vocab_max_size的时候会扩容
// layer1_size 隐层的节点数/词向量大小
long long vocab_max_size = 1000, vocab_size = 0, layer1_size = 100;
// train_words 训练的单词总数(词频累加)
// word_count_actual 已经训练完的word个数
// file_size 训练文件大小,ftell得到
// classes 输出word clusters的类别数
long long train_words = 0, word_count_actual = 0, file_size = 0, classes = 0;
// alpha BP算法的学习速率,过程中自动调整
// starting_alpha 初始alpha值
// sample 亚采样概率的参数,亚采样的目的是以一定概率拒绝高频词,使得低频词有更多出镜率,默认为0,即不进行亚采样
real alpha = 0.025, starting_alpha, sample = 0;
// syn0 单词的向量输入 concatenate word vectors
// syn1 hs(hierarchical softmax)算法中隐层节点到霍夫曼编码树非叶结点的映射权重
// syn1neg ns(negative sampling)中隐层节点到分类问题的映射权重
// expTable 预先存储f函数结果,算法执行中查表
real *syn0, *syn1, *syn1neg, *expTable;
// start 算法运行的起始时间,会用于计算平均每秒钟处理多少词
clock_t start;
// hs 采用hs还是ns的标志位,默认采用hs
int hs = 1, negative = 0;
// table_size 静态采样表的规模
// table 采样表
const int table_size = 1e8;
int *table;
// 根据词频生成采样表,词频越高,占据在表中的数目越大,用于表示词频分布
void InitUnigramTable() {
int a, i;
long long train_words_pow = 0;
real d1, power = 0.75; // 概率与词频的power次方成正比
table = (int *)malloc(table_size * sizeof(int));
for (a = 0; a < vocab_size; a++) train_words_pow += pow(vocab[a].cn, power);
i = 0;
d1 = pow(vocab[i].cn, power) / (real)train_words_pow; // 第一个词出现的概率
for (a = 0; a < table_size; a++) {
table[a] = i;
if (a / (real)table_size > d1) {
i++;
d1 += pow(vocab[i].cn, power) / (real)train_words_pow;
}
if (i >= vocab_size) i = vocab_size - 1; // 处理最后一段概率,防止越界
}
}
// Reads a single word from a file, assuming space + tab + EOL to be word boundaries
// 每次从fin中读取一个单词
void ReadWord(char *word, FILE *fin) {
int a = 0, ch;
while (!feof(fin)) {
ch = fgetc(fin);
if (ch == 13) continue;
// ASCII值为8、9、10 和13 分别转换为退格、制表、换行和回车字符
if ((ch == ' ') || (ch == '\t') || (ch == '\n')) { // 词的分隔符
if (a > 0) {
if (ch == '\n')
ungetc(ch, fin); // 把一个字符回退到输入流中
break;
}
if (ch == '\n') {
strcpy(word, (char *)"</s>");
return;
} else continue;
}
word[a] = ch;
a++;
if (a >= MAX_STRING - 1)
a--; // 如果单词过长
}
word[a] = 0;
}
// 获取单词的哈希值
int GetWordHash(char *word) {
unsigned long long a, hash = 0;
for (a = 0; a < strlen(word); a++)
hash = hash * 257 + word[a]; // hash计算方法
hash = hash % vocab_hash_size;
return hash;
}
// Returns position of a word in the vocabulary; if the word is not found, returns -1
// 线性探索,开放定址法
int SearchVocab(char *word) {
unsigned int hash = GetWordHash(word);
while (1) {
if (vocab_hash[hash] == -1) return -1; // 没有这个词
if (!strcmp(word, vocab[vocab_hash[hash]].word)) return vocab_hash[hash]; // 返回单词在词汇表中的索引
hash = (hash + 1) % vocab_hash_size;
}
return -1; // 应该到不了这里吧……
}
// 获取单词的索引值
int ReadWordIndex(FILE *fin) {
char word[MAX_STRING];
ReadWord(word, fin);
if (feof(fin)) return -1;
return SearchVocab(word);
}
// 将单词添加到词汇表中
int AddWordToVocab(char *word) {
unsigned int hash, length = strlen(word) + 1;
if (length > MAX_STRING) length = MAX_STRING;
vocab[vocab_size].word = (char *)calloc(length, sizeof(char)); // 单词存储
strcpy(vocab[vocab_size].word, word);
vocab[vocab_size].cn = 0; // 在调用函数之外赋值1
vocab_size++; // 词汇表现有单词数
// Reallocate memory if needed
if (vocab_size + 2 >= vocab_max_size) {
vocab_max_size += 1000; // 每次增加1000个词位
vocab = (struct vocab_word *)realloc(vocab, vocab_max_size * sizeof(struct vocab_word));
}
hash = GetWordHash(word); // 获得hash表示
while (vocab_hash[hash] != -1)
hash = (hash + 1) % vocab_hash_size; // 线性探索hash
vocab_hash[hash] = vocab_size - 1; // 记录在词汇表中的存储位置
return vocab_size - 1; // 返回添加的单词在词汇表中的存储位置
}
// 比较函数,词汇表需使用词频进行排序(qsort)
int VocabCompare(const void *a, const void *b) {
return ((struct vocab_word *)b)->cn - ((struct vocab_word *)a)->cn;
}
// 对单词按照词频排序
void SortVocab() {
int a, size;
unsigned int hash;
// Sort the vocabulary and keep </s> at the first position
// 保留回车在首位
qsort(&vocab[1], vocab_size - 1, sizeof(struct vocab_word), VocabCompare); // 对词汇表进行快速排序
for (a = 0; a < vocab_hash_size; a++) vocab_hash[a] = -1; // 词汇重排了,哈希记录的index也乱了,所有的hash记录清除,下面会重建
size = vocab_size;
train_words = 0; // 用于训练的词汇总数(词频累加)
for (a = 0; a < size; a++) {
// Words occuring less than min_count times will be discarded from the vocab
if (vocab[a].cn < min_count) { // 清除长尾词
vocab_size--;
free(vocab[vocab_size].word);
} else {
// Hash will be re-computed, as after the sorting it is not actual
hash=GetWordHash(vocab[a].word);
while (vocab_hash[hash] != -1)
hash = (hash + 1) % vocab_hash_size;
vocab_hash[hash] = a;
train_words += vocab[a].cn; // 词频累加
}
}
vocab = (struct vocab_word *)realloc(vocab, (vocab_size + 1) * sizeof(struct vocab_word)); // 分配的多余空间收回
// 给霍夫曼编码和路径的词汇表索引分配空间
for (a = 0; a < vocab_size; a++) {
vocab[a].code = (char *)calloc(MAX_CODE_LENGTH, sizeof(char));
vocab[a].point = (int *)calloc(MAX_CODE_LENGTH, sizeof(int));
}
}
此处,有些人可能不理解为什么要重排。这里我就列一下单词和哈希值在代码里面的数据关系,就比较好理解了。所以一旦单词表重排,单词的位置相应改变,哈希记录表vocab_hash就要重新构造。

// 删除词频不大于min_reduce的词
void ReduceVocab() {
int a, b = 0;
unsigned int hash;
for (a = 0; a < vocab_size; a++){
if (vocab[a].cn > min_reduce) {
vocab[b].cn = vocab[a].cn;
vocab[b].word = vocab[a].word;
b++;
} else free(vocab[a].word);
vocab_size = b; // 最后剩下b个词,词频均大于min_reduce
// 重新分配hash索引
for (a = 0; a < vocab_hash_size; a++) vocab_hash[a] = -1;
for (a = 0; a < vocab_size; a++) {
// Hash will be re-computed, as it is not actual
hash = GetWordHash(vocab[a].word);
while (vocab_hash[hash] != -1)
hash = (hash + 1) % vocab_hash_size;
vocab_hash[hash] = a;
}
fflush(stdout);
min_reduce++;
}
// 根据词频生成霍夫曼树
void CreateBinaryTree() {
long long a, b, i, min1i, min2i, pos1, pos2, point[MAX_CODE_LENGTH]; // 最长的编码值
char code[MAX_CODE_LENGTH];
//词频记录,前一半是叶子节点,即文本中单词的词频,后一半是非叶子节点的词频
long long *count = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long));
//记录哈夫曼编码的逆序,因为是从底向上构建的
long long *binary = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long));
//记录节点的父节点
long long *parent_node = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long));
for (a = 0; a < vocab_size; a++)
count[a] = vocab[a].cn;
for (a = vocab_size; a < vocab_size * 2; a++)
count[a] = 1e15;
pos1 = vocab_size - 1;
pos2 = vocab_size;
// Following algorithm constructs the Huffman tree by adding one node at a time
for (a = 0; a < vocab_size - 1; a++) {
// 每次寻找两个最小的点做合并,最小的点的分支为0,词小的点的分支为1
//由于是已经按照词频高低排好序的,最后的两个单词就是词频最低的
//pos1控制叶子节点,pos2控制非叶子节点
//min1i是左分支,min2i是右分支
if (pos1 >= 0) {
if (count[pos1] < count[pos2]) {
min1i = pos1;
pos1--;
} else {
min1i = pos2;
pos2++;
}
} else {
min1i = pos2;
pos2++;
}
if (pos1 >= 0) {
if (count[pos1] < count[pos2]) {
min2i = pos1;
pos1--;
} else {
min2i = pos2;
pos2++;
}
} else {
min2i = pos2;
pos2++;
}
count[vocab_size + a] = count[min1i] + count[min2i];
parent_node[min1i] = vocab_size + a;
parent_node[min2i] = vocab_size + a;
binary[min2i] = 1;
}
// Now assign binary code to each vocabulary word
// 顺着父子关系找回编码
for (a = 0; a < vocab_size; a++) {
b = a;
i = 0;
while (1) {
code[i] = binary[b]; // 编码赋值
point[i] = b; // 路径赋值,第一个是自己
i++; // 码个数
b = parent_node[b];
if (b == vocab_size * 2 - 2) break;
}
// 以下要注意的是,同样的位置,point总比code深一层
vocab[a].codelen = i; // 编码长度赋值,少1,没有算根节点
vocab[a].point[0] = vocab_size - 2; // 逆序,把第一个赋值为root(即2*vocab_size - 2 - vocab_size)
for (b = 0; b < i; b++) { // 逆序处理
vocab[a].code[i - b - 1] = code[b]; // 编码逆序,没有根节点,左子树0,右子树1
vocab[a].point[i - b] = point[b] - vocab_size; // 其实point数组最后一个是负的,用不到,point的长度是编码的真正长度,比code长1
}
}
free(count);
free(binary);
free(parent_node);
}
// 装载训练文件到词汇表数据结构
void LearnVocabFromTrainFile() {
char word[MAX_STRING];
FILE *fin;
long long a, i;
for (a = 0; a < vocab_hash_size; a++) vocab_hash[a] = -1;
fin = fopen(train_file, "rb");
if (fin == NULL) {
printf("ERROR: training data file not found!\n");
exit(1);
}
vocab_size = 0;
AddWordToVocab((char *)"</s>"); // 首先添加的是回车
while (1) {
ReadWord(word, fin);
if (feof(fin)) break;
train_words++;
if ((debug_mode > 1) && (train_words % 100000 == 0)) {
printf("%lldK%c", train_words / 1000, 13);
fflush(stdout);
}
i = SearchVocab(word);
if (i == -1) { // 如果这个单词不存在,我们将其加入hash表
a = AddWordToVocab(word);
vocab[a].cn = 1;
} else vocab[i].cn++; // 否则词频加一
if (vocab_size > vocab_hash_size * 0.7) ReduceVocab(); // 如果超出装填系数,将词汇表扩容
}
SortVocab(); // 所有词汇加载完毕后进行排序,词频高的靠前
if (debug_mode > 0) {
printf("Vocab size: %lld\n", vocab_size);
printf("Words in train file: %lld\n", train_words);
}
file_size = ftell(fin); // 文件大小
fclose(fin);
}
// 输出单词和词频到文件
void SaveVocab() {
long long i;
FILE *fo = fopen(save_vocab_file, "wb");
for (i = 0; i < vocab_size; i++) fprintf(fo, "%s %lld\n", vocab[i].word, vocab[i].cn);
fclose(fo);
}
// 读入词汇表文件到词汇表数据结构
void ReadVocab() {
long long a, i = 0;
char c;
char word[MAX_STRING];
FILE *fin = fopen(read_vocab_file, "rb");
if (fin == NULL) {
printf("Vocabulary file not found\n");
exit(1);
}
for (a = 0; a < vocab_hash_size; a++) vocab_hash[a] = -1;
vocab_size = 0;
while (1) {
ReadWord(word, fin);
if (feof(fin)) break;
a = AddWordToVocab(word);
fscanf(fin, "%lld%c", &vocab[a].cn, &c);
i++;
}
SortVocab();
if (debug_mode > 0) {
printf("Vocab size: %lld\n", vocab_size);
printf("Words in train file: %lld\n", train_words);
}
fin = fopen(train_file, "rb"); // 还得打开以下训练文件好知道文件大小是多少
if (fin == NULL) {
printf("ERROR: training data file not found!\n");
exit(1);
}
fseek(fin, 0, SEEK_END);
file_size = ftell(fin);
fclose(fin);
}
// 网络结构初始化,就是把所有参数初始化
void InitNet() {
long long a, b;
// posix_memalign() 成功时会返回size字节的动态内存,并且这块内存的地址是alignment(这里是128)的倍数
// syn0 存储的是就是单词向量
a = posix_memalign((void **)&syn0, 128, (long long)vocab_size * layer1_size * sizeof(real));
if (syn0 == NULL) {printf("Memory allocation failed\n"); exit(1);}
if (hs) { // hierarchical softmax
// hs中,用syn1
a = posix_memalign((void **)&syn1, 128, (long long)vocab_size * layer1_size * sizeof(real));
if (syn1 == NULL) {printf("Memory allocation failed\n"); exit(1);}
for (b = 0; b < layer1_size; b++)
for (a = 0; a < vocab_size; a++)
syn1[a * layer1_size + b] = 0;
}
if (negative>0) { // negative sampling
// ns中,用syn1neg
a = posix_memalign((void **)&syn1neg, 128, (long long)vocab_size * layer1_size * sizeof(real));
if (syn1neg == NULL) {printf("Memory allocation failed\n"); exit(1);}
for (b = 0; b < layer1_size; b++)
for (a = 0; a < vocab_size; a++)
syn1neg[a * layer1_size + b] = 0;
}
for (b = 0; b < layer1_size; b++)
for (a = 0; a < vocab_size; a++)
syn0[a * layer1_size + b] = (rand() / (real)RAND_MAX - 0.5) / layer1_size; // 随机初始化word vectors
CreateBinaryTree(); // 创建霍夫曼树
}
void *TrainModelThread(void *id) {
// word 向sen中添加单词用,句子完成后表示句子中的当前单词
// last_word 上一个单词,辅助扫描窗口
// sentence_length 当前句子的长度(单词数)
// sentence_position 当前单词在当前句子中的index
long long a, b, d, word, last_word, sentence_length = 0, sentence_position = 0;
// word_count 已训练语料总长度
// last_word_count 保存值,以便在新训练语料长度超过某个值时输出信息
// sen 单词数组,表示句子
long long word_count = 0, last_word_count = 0, sen[MAX_SENTENCE_LENGTH + 1];
// l1 ns中表示word在concatenated word vectors中的起始位置,之后layer1_size是对应的word vector,因为把矩阵拉成长向量了
// l2 cbow或ns中权重向量的起始位置,之后layer1_size是对应的syn1或syn1neg,因为把矩阵拉成长向量了
// c 循环中的计数作用
// target ns中当前的sample
// label ns中当前sample的label
long long l1, l2, c, target, label;
// id 线程创建的时候传入,辅助随机数生成
unsigned long long next_random = (long long)id;
// f e^x / (1/e^x),fs中指当前编码为是0(父亲的左子节点为0,右为1)的概率,ns中指label是1的概率
// g 误差(f与真实值的偏离)与学习速率的乘积
real f, g;
// 当前时间,和start比较计算算法效率
clock_t now;
real *neu1 = (real *)calloc(layer1_size, sizeof(real)); // 隐层节点
real *neu1e = (real *)calloc(layer1_size, sizeof(real)); // 误差累计项,其实对应的是Gneu1
FILE *fi = fopen(train_file, "rb");
fseek(fi, file_size / (long long)num_threads * (long long)id, SEEK_SET); // 将文件内容分配给各个线程
while (1) {
if (word_count - last_word_count > 10000) {
word_count_actual += word_count - last_word_count;
last_word_count = word_count;
if ((debug_mode > 1)) {
now=clock();
printf("%cAlpha: %f Progress: %.2f%% Words/thread/sec: %.2fk ", 13, alpha,
word_count_actual / (real)(train_words + 1) * 100,
word_count_actual / ((real)(now - start + 1) / (real)CLOCKS_PER_SEC * 1000));
fflush(stdout);
}
alpha = starting_alpha * (1 - word_count_actual / (real)(train_words + 1)); // 自动调整学习速率
if (alpha < starting_alpha * 0.0001) alpha = starting_alpha * 0.0001; // 学习速率有下限
}
if (sentence_length == 0) { // 如果当前句子长度为0
while (1) {
word = ReadWordIndex(fi);
if (feof(fi)) break; // 读到文件末尾
if (word == -1) continue; // 没有这个单词
word_count++; // 单词计数增加
if (word == 0) break; // 是个回车
// 这里的亚采样是指 Sub-Sampling,Mikolov 在论文指出这种亚采样能够带来 2 到 10 倍的性能提升,并能够提升低频词的表示精度。
// 低频词被丢弃概率低,高频词被丢弃概率高
if (sample > 0) {
real ran = (sqrt(vocab[word].cn / (sample * train_words)) + 1) * (sample * train_words) / vocab[word].cn;
next_random = next_random * (unsigned long long)25214903917 + 11;
if (ran < (next_random & 0xFFFF) / (real)65536) continue;
}
sen[sentence_length] = word;
sentence_length++;
if (sentence_length >= MAX_SENTENCE_LENGTH) break;
}
sentence_position = 0; // 当前单词在当前句中的index,起始值为0
}
if (feof(fi)) break; // 照应while中的break,如果读到末尾,退出
if (word_count > train_words / num_threads) break; // 已经做到了一个thread应尽的工作量,就退出
word = sen[sentence_position]; // 取句子中的第一个单词,开始运行BP算法
if (word == -1) continue; // 如果没有这个单词,则继续
// 隐层节点值和隐层节点误差累计项清零
for (c = 0; c < layer1_size; c++) neu1[c] = 0;
for (c = 0; c < layer1_size; c++) neu1e[c] = 0;
next_random = next_random * (unsigned long long)25214903917 + 11;
b = next_random % window; // b是个随机数,0到window-1,指定了本次算法操作实际的窗口大小
// cbow 框架
if (cbow) { //train the cbow architecture
// in -> hidden
// 从输入层到隐层所进行的操作实际就是窗口内上下文向量的加和
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue; // 这个单词没有
for (c = 0; c < layer1_size; c++) neu1[c] += syn0[c + last_word * layer1_size];
}
// hs
if (hs) for (d = 0; d < vocab[word].codelen; d++) { // 这里的codelen其实是少一个的,所以不会触及point里面最后一个负数
f = 0;
l2 = vocab[word].point[d] * layer1_size; // 路径上的点
// Propagate hidden -> output
// 准备计算f
for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1[c + l2];
// 不在expTable内的舍弃掉,作者说计算精度有限,怕有不好印象,但这里改成太小的都是0,太大的都是1,运行结果还是有差别的
// if (f <= -MAX_EXP) continue;
// else if (f >= MAX_EXP) continue;
if (f <= -MAX_EXP) f = 0;
else if (f >= MAX_EXP) f = 1;
// 从expTable中查找,快速计算
else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))];
// g 实际为负梯度中公共的部分与 Learning rate alpha 的乘积

g = (1 - vocab[word].code[d] - f) * alpha;
// Propagate errors output -> hidden
// 记录累积误差项
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2];
// Learn weights hidden -> output
// 更新隐层到霍夫曼树非叶节点的权重
for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * neu1[c];
}
// NEGATIVE SAMPLING
if (negative > 0) for (d = 0; d < negative + 1; d++) {
if (d == 0) { // 当前词的分类器应当输出1
target = word;
label = 1;
} else { // 采样使得与target不同,不然continue,label为0,也即最多采样negative个negative sample
next_random = next_random * (unsigned long long)25214903917 + 11;
target = table[(next_random >> 16) % table_size];
if (target == 0) target = next_random % (vocab_size - 1) + 1;
if (target == word) continue;
label = 0;
}
l2 = target * layer1_size;
f = 0;
for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1neg[c + l2];
// 这里直接上0、1,没有考虑计算精度问题
if (f > MAX_EXP) g = (label - 1) * alpha;
else if (f < -MAX_EXP) g = (label - 0) * alpha;
// g 并非梯度,可以看做是一个乘了学习率的 error(label与输出f的差)。损失函数Loss=-log Likehood = -label•logf-(1-lable)•log(1-f),推导同上。
else g = (label - expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha;
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1neg[c + l2];
for (c = 0; c < layer1_size; c++) syn1neg[c + l2] += g * neu1[c];
}
// hidden -> in
// 根据隐层节点累积误差项,更新word vectors
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
for (c = 0; c < layer1_size; c++) syn0[c + last_word * layer1_size] += neu1e[c];
}
} else { //train skip-gram
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) { // 预测非中心的单词(邻域内的单词)
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
l1 = last_word * layer1_size;
// 每次循环neu1e都被置零了
for (c = 0; c < layer1_size; c++) neu1e[c] = 0;
// HIERARCHICAL SOFTMAX
if (hs) for (d = 0; d < vocab[word].codelen; d++) {
f = 0;
l2 = vocab[word].point[d] * layer1_size;
// Propagate hidden -> output
// 待预测单词的 word vecotr 和 隐层-霍夫曼树非叶节点权重 的内积
for (c = 0; c < layer1_size; c++) f += syn0[c + l1] * syn1[c + l2];
// 同cbow中hs的讨论
// if (f <= -MAX_EXP) continue;
// else if (f >= MAX_EXP) continue;
if (f <= -MAX_EXP) f = 0;
else if (f >= MAX_EXP) f = 1;
// 以下内容同之前的cbow
else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))];
// g 就是梯度中的公共部分与学习率的乘积,此处损失函数的计算方式有别于CBOW模型,具体参考文献[6]。
g = (1 - vocab[word].code[d] - f) * alpha; // 这里的code[d]其实是下一层的,code错位了,point和code是错位的!
// Propagate errors output -> hidden
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2];
// Learn weights hidden -> output
for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * syn0[c + l1];
}
// NEGATIVE SAMPLING
if (negative > 0) for (d = 0; d < negative + 1; d++) {
if (d == 0) {
target = word;
label = 1;
} else {
next_random = next_random * (unsigned long long)25214903917 + 11;
target = table[(next_random >> 16) % table_size];
if (target == 0) target = next_random % (vocab_size - 1) + 1;
if (target == word) continue;
label = 0;
}
l2 = target * layer1_size;
f = 0;
for (c = 0; c < layer1_size; c++) f += syn0[c + l1] * syn1neg[c + l2];
// 以下内容同之前的cbow
if (f > MAX_EXP) g = (label - 1) * alpha;
else if (f < -MAX_EXP) g = (label - 0) * alpha;
else g = (label - expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha;
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1neg[c + l2];
for (c = 0; c < layer1_size; c++) syn1neg[c + l2] += g * syn0[c + l1];
}
// Learn weights input -> hidden
for (c = 0; c < layer1_size; c++) syn0[c + l1] += neu1e[c];
}
}
sentence_position++;
if (sentence_position >= sentence_length) {
sentence_length = 0;
continue;
}
}
fclose(fi);
free(neu1);
free(neu1e);
pthread_exit(NULL);
}
void TrainModel() {
long a, b, c, d;
FILE *fo;
// 创建多线程
pthread_t *pt = (pthread_t *)malloc(num_threads * sizeof(pthread_t));
printf("Starting training using file %s\n", train_file);
starting_alpha = alpha;
// 优先从词汇表文件中加载,否则从训练文件中加载
if (read_vocab_file[0] != 0) ReadVocab(); else LearnVocabFromTrainFile();
// 输出词汇表文件,词+词频
if (save_vocab_file[0] != 0) SaveVocab();
if (output_file[0] == 0) return;
InitNet(); // 网络结构初始化
if (negative > 0) InitUnigramTable(); // 根据词频生成采样映射
start = clock(); // 开始计时
for (a = 0; a < num_threads; a++) pthread_create(&pt[a], NULL, TrainModelThread, (void *)a);
for (a = 0; a < num_threads; a++) pthread_join(pt[a], NULL);
// 训练结束,准备输出
fo = fopen(output_file, "wb");
if (classes == 0) { // 保存 word vectors
// Save the word vectors
fprintf(fo, "%lld %lld\n", vocab_size, layer1_size); // 词汇量,vector维数
for (a = 0; a < vocab_size; a++) {
fprintf(fo, "%s ", vocab[a].word);
if (binary) for (b = 0; b < layer1_size; b++) fwrite(&syn0[a * layer1_size + b], sizeof(real), 1, fo);
else for (b = 0; b < layer1_size; b++) fprintf(fo, "%lf ", syn0[a * layer1_size + b]);
fprintf(fo, "\n");
}
} else {
// Run K-means on the word vectors
// 运行K-means算法
int clcn = classes, iter = 10, closeid;
int *centcn = (int *)malloc(classes * sizeof(int));
int *cl = (int *)calloc(vocab_size, sizeof(int));
real closev, x;
real *cent = (real *)calloc(classes * layer1_size, sizeof(real));
for (a = 0; a < vocab_size; a++) cl[a] = a % clcn;
for (a = 0; a < iter; a++) {
for (b = 0; b < clcn * layer1_size; b++) cent[b] = 0;
for (b = 0; b < clcn; b++) centcn[b] = 1;
for (c = 0; c < vocab_size; c++) {
for (d = 0; d < layer1_size; d++) cent[layer1_size * cl[c] + d] += syn0[c * layer1_size + d];
centcn[cl[c]]++;
}
for (b = 0; b < clcn; b++) {
closev = 0;
for (c = 0; c < layer1_size; c++) {
cent[layer1_size * b + c] /= centcn[b];
closev += cent[layer1_size * b + c] * cent[layer1_size * b + c];
}
closev = sqrt(closev);
for (c = 0; c < layer1_size; c++) cent[layer1_size * b + c] /= closev;
}
for (c = 0; c < vocab_size; c++) {
closev = -10;
closeid = 0;
for (d = 0; d < clcn; d++) {
x = 0;
for (b = 0; b < layer1_size; b++) x += cent[layer1_size * d + b] * syn0[c * layer1_size + b];
if (x > closev) {
closev = x;
closeid = d;
}
}
cl[c] = closeid;
}
}
// Save the K-means classes
for (a = 0; a < vocab_size; a++) fprintf(fo, "%s %d\n", vocab[a].word, cl[a]);
free(centcn);
free(cent);
free(cl);
}
fclose(fo);
}
int ArgPos(char *str, int argc, char **argv) {
int a;
for (a = 1; a < argc; a++) if (!strcmp(str, argv[a])) {
if (a == argc - 1) {
printf("Argument missing for %s\n", str);
exit(1);
}
return a;
}
return -1;
}
int main(int argc, char **argv) {
int i;
if (argc == 1) {
printf("WORD VECTOR estimation toolkit v 0.1b\n\n");
printf("Options:\n");
printf("Parameters for training:\n");
printf("\t-train <file>\n"); // 指定训练文件
printf("\t\tUse text data from <file> to train the model\n");
printf("\t-output <file>\n"); // 指定输出文件,以存储word vectors,或者单词类
printf("\t\tUse <file> to save the resulting word vectors / word clusters\n");
printf("\t-size <int>\n"); // word vector的维数,对应 layer1_size,默认是100
printf("\t\tSet size of word vectors; default is 100\n");
// 窗口大小,在cbow中表示了word vector的最大的叠加范围,在skip-gram中表示了max space between words(w1,w2,p(w1 | w2))
printf("\t-window <int>\n");
printf("\t\tSet max skip length between words; default is 5\n");
printf("\t-sample <float>\n"); // 亚采样拒绝概率的参数
printf("\t\tSet threshold for occurrence of words. Those that appear with higher frequency");
printf(" in the training data will be randomly down-sampled; default is 0 (off), useful value is 1e-5\n");
printf("\t-hs <int>\n"); // 使用hs求解,默认为1
printf("\t\tUse Hierarchical Softmax; default is 1 (0 = not used)\n");
printf("\t-negative <int>\n"); // 使用ns的时候采样的样本数
printf("\t\tNumber of negative examples; default is 0, common values are 5 - 10 (0 = not used)\n");
printf("\t-threads <int>\n"); // 指定线程数
printf("\t\tUse <int> threads (default 1)\n");
printf("\t-min-count <int>\n"); // 长尾词的词频阈值
printf("\t\tThis will discard words that appear less than <int> times; default is 5\n");
printf("\t-alpha <float>\n"); // 初始的学习速率,默认为0.025
printf("\t\tSet the starting learning rate; default is 0.025\n");
printf("\t-classes <int>\n"); // 输出单词类别数,默认为0,也即不输出单词类
printf("\t\tOutput word classes rather than word vectors; default number of classes is 0 (vectors are written)\n");
printf("\t-debug <int>\n"); // 调试等级,默认为2
printf("\t\tSet the debug mode (default = 2 = more info during training)\n");
printf("\t-binary <int>\n"); // 是否将结果输出为二进制文件,默认为0,即不输出为二进制
printf("\t\tSave the resulting vectors in binary moded; default is 0 (off)\n");
printf("\t-save-vocab <file>\n"); // 词汇表存储文件
printf("\t\tThe vocabulary will be saved to <file>\n");
printf("\t-read-vocab <file>\n"); // 词汇表加载文件,则可以不指定trainfile
printf("\t\tThe vocabulary will be read from <file>, not constructed from the training data\n");
printf("\t-cbow <int>\n"); // 使用cbow框架
printf("\t\tUse the continuous bag of words model; default is 0 (skip-gram model)\n");
printf("\nExamples:\n"); // 使用示例
printf("./word2vec -train data.txt -output vec.txt -debug 2 -size 200 -window 5 -sample 1e-4 -negative 5 -hs 0 -binary 0 -cbow 1\n\n");
return 0;
}
// 文件名均空
output_file[0] = 0;
save_vocab_file[0] = 0;
read_vocab_file[0] = 0;
// 参数与变量的对应关系
if ((i = ArgPos((char *)"-size", argc, argv)) > 0) layer1_size = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-train", argc, argv)) > 0) strcpy(train_file, argv[i + 1]);
if ((i = ArgPos((char *)"-save-vocab", argc, argv)) > 0) strcpy(save_vocab_file, argv[i + 1]);
if ((i = ArgPos((char *)"-read-vocab", argc, argv)) > 0) strcpy(read_vocab_file, argv[i + 1]);
if ((i = ArgPos((char *)"-debug", argc, argv)) > 0) debug_mode = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-binary", argc, argv)) > 0) binary = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-cbow", argc, argv)) > 0) cbow = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-alpha", argc, argv)) > 0) alpha = atof(argv[i + 1]);
if ((i = ArgPos((char *)"-output", argc, argv)) > 0) strcpy(output_file, argv[i + 1]);
if ((i = ArgPos((char *)"-window", argc, argv)) > 0) window = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-sample", argc, argv)) > 0) sample = atof(argv[i + 1]);
if ((i = ArgPos((char *)"-hs", argc, argv)) > 0) hs = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-negative", argc, argv)) > 0) negative = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-threads", argc, argv)) > 0) num_threads = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-min-count", argc, argv)) > 0) min_count = atoi(argv[i + 1]);
if ((i = ArgPos((char *)"-classes", argc, argv)) > 0) classes = atoi(argv[i + 1]);
vocab = (struct vocab_word *)calloc(vocab_max_size, sizeof(struct vocab_word));
vocab_hash = (int *)calloc(vocab_hash_size, sizeof(int));
expTable = (real *)malloc((EXP_TABLE_SIZE + 1) * sizeof(real));
// 提前产生e^-6 到 e^6 之间的f值 ,便于提高运算效率
for (i = 0; i < EXP_TABLE_SIZE; i++) {
expTable[i] = exp((i / (real)EXP_TABLE_SIZE * 2 - 1) * MAX_EXP); // Precompute the exp() table
expTable[i] = expTable[i] / (expTable[i] + 1); // Precompute f(x) = x / (x + 1)
}
TrainModel();
return 0;
}
[1] http://blog.sina.com.cn/s/blog_64ac3ab10102uwjo.html
[2] http://xiaoquanzi.net/?p=156
[3] http://bbs.byr.cn/#!article/ML_DM/12813?au=wechat
[4] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and t heir compositionality[C]//Advances in Neural Information Processing Systems. 2013: 3111-3119.
[5] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[6] http://techblog.youdao.com/?p=915

 浙公网安备 33010602011771号
浙公网安备 33010602011771号