「2024 April」做题笔记
[省选联考 2024] 迷宫守卫
转换维度,不知道为什么脑子不清醒没有想到。
当我在为这次终于记得阶乘转二进制庆幸的时候,没想到根本是不用枚举的,直接对 DAG 计数即可。
奇行分去左边,偶行分去右边。若原图这个点为 #,就将另一边也染色。
当然也可以染成贪吃蛇的形状。
我靠这个题为什么只有紫?
你的脑海里可能会出现这样的图:
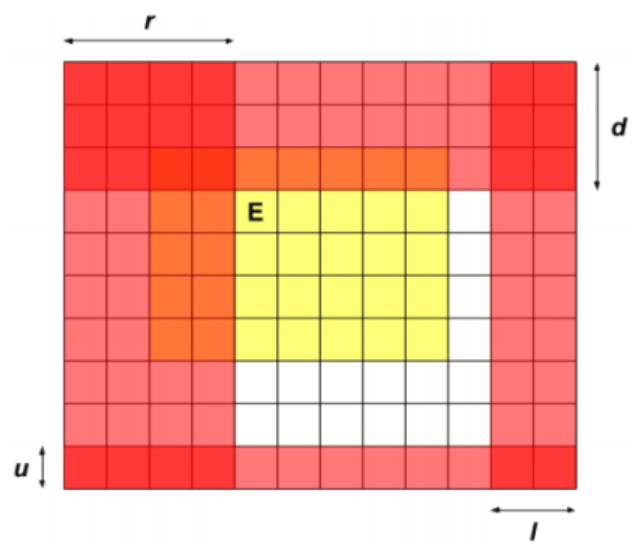
其中黄色为拯救的,红色为超出的。
只看 \(maxr,minl,maxd,minu\) 是有问题的,有可能这个点虽然现在超出了边界,但是以前已经被救了。就是图中红黄相间的部分。
很神奇的一步是:令 \(dp_{u,d,l,r}\) 为这样的最大答案。考虑其中一维扩大,那么红的和红黄相间的以前就考虑过了,现在只考虑新扩展的一行,直接判断一下统计即可。
用 short 少一半空间。
考虑每个点,容易化成 \(ans_i=\sum_{k=i}^n a_k \frac {k!} {i!(k-i)!}\) 的形式。
那么这就是 \(c=a-b\) 类 FFT 啊,直接 \(b\leftarrow n-b\) 即可。
主要是要尝试把组合数化成阶乘形式。
考场上看出同构后面的 dp 就不会了,而且不知道怎么判同构,唉,加训。
首先你需要进行类似划分集合的 dp,那这显然是不可能一步完成的。我们考虑令 \(dp_{i,j,s}\) 为用 \(j\) 步,将 \(i\) 个大小为 \(s\) 的同构块连成一个连通块的方案数,那这样后面就可以再做一个 dp 合并了。
那么 \(dp_{i,j,s}=\sum _{x|i}dp_{x,j-1,s*(i/x)}*F(i,x)*s^{i-x+1}\)。其中 \(F(i,j)\) 表示把 \(i\) 个元素划分成 \(j\) 个大小为 \(i/j\) 的圆排列的方案数。
那么 \(F(i,j)=\frac {i!} {(i/j)^jj!}\)。
然后很神奇的一步是发现 \(s\) 的次数似乎可以直接算,即\(dp_{i,j,s}=dp_{i,j,1}*s^{i+j-1}\)。
那么更新一下转移:\(dp_{i,j}=\sum_{x|i}dp_{x,j-1}*F(i,j)*(\frac i x)^{x+j-2}\)。(\(s=1\))
代入 \(F\),\(dp_{i,j}=\sum_{x|i}dp_{x,j-1}*\frac {i!} {(i/x)^xx!}*(\frac i x)^{x+j-2}\)。
其实很想用矩乘或者倍增什么的优化啊,但是这个和 \(j\) 有关。
化简一下,\(dp_{i,j}=\sum_{x|i}dp_{x,j-1}\frac {(i-1)!} {(x-1)!}\frac {i^{j-1}} {x^{j-1}}\)。
令 \(g_{i,j}=\frac {dp_{i,j}} {(i-1)!i^{j-1}}\),你会惊讶地发现 \(g_{i,j}=\sum_{x|i}\frac {g_{x,j-1}} {x}\)。感觉这个直接矩乘会很快啊,因为你只需要跑因数的时候就行了,复杂度是不是不劣于 \(n\ln\ln\log_2 n\) 啊?
考虑 \(g\) 的组合意义,发现 \(g_{i,j}=\sum_u g_{i/u,k}*g_{u,j-k}/u^k\)。那么直接倍增就好了。
那这个题就做完了。时间复杂度 \(O(n\ln\log_2 n)\)。
偷懒写的 3log。
好像可以对最上面那个 dp 式子,直接维护有值的点矩乘,因为 \(ijku\leqslant n\) 这样的式子都是 \(n*poly(\log)\) 的。
ad-hoc。
\(n\) 很小,考虑预处理所有 \(ans(l,r)\)。
如果只处理一组 \((l,r)\),考虑这样一个流程:从右到左处理,令 \(b_i\) 为比前面多出来的一部分。就比如 {a}=4 2,那么 {b}=2 2。考虑加入 \(a_{r+1}\),现在我们动态更新 {b},发现只要维护一个 \(c=a_{r+1}\),每次和 \(b\) 约掉公因子即可。
复杂度实际上是 \(n^2\) 的。因为求 \(\gcd\) 均摊 \(n\log_2 n\) 。
使用二进制 gcd 卡常。
[THUPC2022 决赛] rsraogps & [Ynoi2001] 雪に咲く花
这个贡献一看就不好直接算,考虑扫描线稍微继承一下。
右端点从左往右扫,那么你会发现对于一个左端点,答案只会变化 \(\log\) 次,并且每次的变化都只是一个后缀。
为了 \(O(1)\) 维护这个信息,我们统计答案时统计前缀,即维护前缀历史和,这个可以用懒标+时间戳之类的实现。
2log。但是题解都把 gcd 看成 \(O(1)\)。
P10197 [USACO24FEB] Minimum Sum of Maximums P
\(\max(x,y)=\frac {x+y} {2}+\frac {|x-y|} {2}\),看成绝对值方便多了。你可能会说前面那部分也不是定的,但其实可以在开头和末尾加个 \(\inf\),可以发现不影响答案。
那么现在要绝对值最小。不难发现,如果左右端点(方便起见,设 \(l<r\))及中间数的集合固定,那么中间的数一定单调不降。
这是很经典的绝对值的性质。意思是:当前能更优就更优,若为了其他的数改变排列,是肯定不优的。
即 \(cost=|l-mn|+mx-mn+|r-mx|\)。
考虑怎么排数,再找找性质?沿袭刚才那个法则,如果两个区间相互包含且都可被选,一定选小的那个。由此可以推出,\((mn,mx)\) 是否相互包含或不交。
令 \(dp_{l,r,s}\) 为选了 \([l,r]\) 的数填满了 \(s\) 集合。
转移分别是:两端点匹配(\(need=r-l+1\) 时),中间枚举子集划分(\(need=r-l+1\) 时),以及过渡转移,即 \(dp_{l,r,s}=\min(dp_{l+1,r,s},dp_{l,r-1,s})\)。
时间复杂度 \(O(3^nn+2^nn^2)\)。
当然好像也可以直接从大到小 dp。当前的数要么变成一个新的左端点,要么填入左端点最大的那个段。好像也是 \(O(2^nn^2)\) 的。
化简一下式子,\((10^n-10^0)a+(10^{n-1}-10^1)b+...=D\)。
发现最后的一坨最大值也抵不上 \(a\) 增加 \(1\),所以这个是相对独立的。但是注意到系数范围为 \([-9,9]\),所以 \(a\) 最多有两种取值。
爆搜即可,复杂度 \(10*2^{10}\)。
唉还是只会 \(n^3\)。大概是按照每个离散化区间整体考虑。
std 的巧妙在于一个一个考虑(或者说,直接 dp 答案序列),令 \(dp_{i,j}\) 为前 \(i\) 个元素,选了 \(j\) 个 \(1\) 的方案数。
那么 \(dp_{i,j}=dp_{i-1,j-1}+dp_{i-1,j}\)。
考虑第二维的上下界。比较偷懒的方法是模拟这个过程,求出最小值和最大值,然后注意到这个东西有连续性,所以直接用这个作为范围即可。
但是可以算出上界是 \(\min(i,c_{R_i})\),下界是 \(\max(i-(R_i-c_{R_i}),0)\),其中 \(c\) 为 \(1\) 的前缀和,\(R\) 为能到达这个点的最远位置。你可能会有疑惑是中间隔断了怎么办,但是感性理解一下,这种情况可能在之前就转不过来。
感觉还是太玄乎了。
[USACO24FEB] Infinite Adventure P
令 \(dp_{i,j,k}\) 为 \((i,j)\),\(2^k\),跳去哪。直接倍增会超出自己的范围。但是注意到还是可以照样倍增,在超范围的时候停住,记录步数就好了。那么每 \(\log\) 次至少会折半,所以查询 \(2log\)。但是这个预处理是 \(3\log\) 的。
换个维度,令 \(dp_{i,j,k}\) 为跳了 \(2^k\) 个同层点,跳到了哪,以及步数,注意还是遇到超出范围的就停止。
只要算出 \(dp_{i,j,0}\),剩下的就很好倍增了。然后这个可以使用 \(stp_{x,y,60}\) 查找。如果为 \(\inf\),那么就一定不会停止。否则,要么步数折半,要么层数加 \(1\),所以这里是 2log 的。
查询的话,类似倍增 \(2^k\) 从大到小检验步数是否合法,如果是,直接跳,要么层数加 \(1\),要么直接步数折半,所以还是 2log 的。
首先找找 \(f\) 的快速计算方式。设 \(|a|<|b|\),不妨将 \(b\) 中元素插入 \(a\) 中。设长度为 \(n-1\) 的序列 \(\{c\}\),其中 \(c_i=0\) 表示 \(a_i<a_{i+1}\),那么你会发现 00 怎么样都可以变成 010,所以若答案为 \(x\),\(\sum \lfloor \frac {s_i}{x}\rfloor \leqslant |b'|\)。
将式子改写为计算 \(f(a',b')-1> x\) 的个数。如果对 \(a'\) dp 的话有点像背包的形式,所以我们考虑分治,对极长连续段的长度分治。
令 \(w(x)\) 表示 \(\{b\}\) 中长度 \(<x\) 的子段数。那么 \(l=r\) 的时候,就是 \(\sum_{l=1}^n\sum_{r=l}^n w(\frac {r-l+1} {x})\)。如果枚举 \(x\) 再枚举 \(\frac {r-l+1} {x}\),是 \(O(n\ln n)\) 的,这时 \((l,r)\) 的个数可以 \(O(1)\) 算出。否则考虑拼接,那么就是 \(\sum L_{x,i}*R_{x,j}*w(i+j)\),其中 \(w\) 为先一段二函再一段常数,所以计算 \(\sum L_{x,i}/R_{x,j}*(1/i/i^2)\) 即可。这个随便算算就好了。(\(L/R\) 表示长度为 \(x\),\(\sum \frac {s_i/}{x}=i /j\))。
显然有凸性。暴力对每个询问做 wqs 二分 + 决策单调性,单次 \(\mathcal O (n\log _2 n)\)。
整体二分显然是不行的。(虽然好像能得很多分。)观察到 \(a_i\leqslant 30\) 的部分分,那么斜率 \(\leqslant 30\)(若 \(k>30\),wqs 中 dp 的贡献为 \(w(l,r)-k<0\))。直接枚举斜率即可。
上面的部分分提示出若斜率大那么 wqs 出来的横坐标就很小,这个结论似乎是容易感知到的。进一步观察,结合凸性,\(x\leqslant \frac {n} {k}\)。
考虑根分。\(x\) 小可以暴力每层线段树优化 dp / 决策单调性,\(k\) 小可以枚举斜率线段树优化 dp / 决策单调性。可以做到 \(\mathcal O (n\sqrt n \log_2 n+m\log_2 n)\)。注意到后面那部分空间是根号的。所以要稍微对询问进行排序。
考虑线段树优化 dp 的操作是形如:后缀加 \(1\),在后面加入一个数,查询全局最大值。直接维护单调栈,发现后缀加只会在当前数和当前数的前面造成影响,因此直接维护差分,然后用链表维护,使用并查集找到单调栈上对应的元素,还维护当前的最小值、最大值、和最大值位置即可。可以优化到 \(\mathcal O (n\sqrt n \alpha(n))\)。
还是太智慧了。
将编号翻转答案不变,把两个答案加起来,由于每条边概率也是相同的,所以现在可以看成 \(x=0,d_1=1\),最后答案乘上 \(d_1+(n-0.5)x\)。
转化一下题意,观察线段。发现每次要么删两端的线段,要么选三个线段合并。由于概率相同,所以每个时刻所有线段的期望长度是一样的!设为 \(d\)。则操作一次 \(d'=d+\frac {1} {2n-2}\times \frac {2n-2} {2n}\times d=\frac {n+1} {n}d\),直接递推就好了。
[AGC007F] Shik and Copying String
适度 ad-hoc 益脑,沉迷 ad-hoc 伤身。
首先策略肯定是从后往前做,找到最靠后的 \(S\) 的元素到达这个位置。
观察一个时刻每个颜色开头的位置,发现每次这样的位置会后移 \(ans\) 次。
队列维护这样的位置。每次如果最后面的的影响不到当前的位置,即 \(x-len\geqslant i\),那么弹出。
答案为队列历史大小最大值加 \(1\),所以要特判 \(S=T\)。
这个题还可以啊!
显然二分,但是后面你发现贪心不太可行。不妨先想一个复杂度大一点的 dp,那么令 \(dp_{x,i,j}\) 为以 \(x\) 为根,根到第一个叶子的距离为 \(i\),到最后一个叶子的距离为 \(j\) 是否可行。那么 \(dp_{x,i,q}=dp_{ls,i,j}\&dp_{rs,p,q}\&[j+p+lval+rval\leqslant mid]\)。
显然 bool 转 int,那么 \(dp_{x,i}\) 为到最后一个叶子合法的最小距离。
那显然这是单调不增的。转移的时候双指针就好了。
并且注意到有很多空状态,所以维护所有状态。具体地,设儿子状态数为 \(p\) 和 \(q\),那么排除显然不合法的状态后(\(l1>l2,r1>r2\)),当前状态数为 \(2\min(p,q)\)。
算上二分显然复杂度 2log。但是我偷懒写的 3log。
唉,想到最后也没想到简洁做法。
容易看出 \(V\log\) FFT 做法,但显然不是本题主旨。
考虑前缀和。那么 \(pre(s_2-s_1+s_4-s_3+s_6-s_5)=0(s_2>s_1,s_4>s_3,s_6>s_5)\)。考虑 meet-in-the-middle,现在难点在于维护偏序。
可以分讨 5 种情况,也是能做的!但是更简洁地,顺序遍历 \(s_4\),每次加入 \(s_2-s_1-s_3\),然后查询 \(x_6-x_5\),即 \(n^3\)。
送我上 GM 的题。
处理出支配的两个位置,如果两个元素他们这两个位置交叉那么会提供固定的贡献 \(1\),否则可看成一个点。随便构造即可。
水黑,模拟赛拿了 70 pts 就不想思考了。
事实上继承那里可以线段树直接不动,然后修改稍微推一推就是区间查询和单点赋值,还有区间清空。可以用 multiset 维护所有的 \(l\) 和 \(r\)。
水黑,维护一个翻转的状态就好了。
CF986F Oppa Funcan Style Remastered
水黑,但是假算碾题。
我觉得这个题不好想到啊!
首先考虑不修改会到哪里,然后一种策略是在最后的时候移动到终点,不过显然不一定最优。
倒着考虑,每次遇到一条边,就等价于交换两条线的步数(\(swap(dp_i,dp_{j})\)),然后可以加线,那么就是 \(dp_i=\min(dp_i,dp_j+1)\)。
所以得到了 \(n^2\) 的暴力。优化的话,观察到 \(|dp_i-dp_j|\leqslant 1\),交换两个数,大的那边只会有可能被另一边的更新,小的那边可能会使另一边的一个等差数列减 \(1\)。可以使用线段树维护。
被骗了。
你可能会想到只用考虑 \(\sqrt n\) 范围内的质因子,因为超出了不可能不合法,但是这样完全做不出来啊!
直接正难则反,令 \(f_i\) 为平方因子为 \(i\) 的方案数,直接 dp 即可。
CF1081G Mergesort Strikes Back
感觉不是很难啊,小 T 为什么想这么久。虽然我没想出来,被骗了。
你可能会发现中途每个位置是啥概率是不等的,所以即使发现了这个和前面的最大值有关也做不出来。
不妨直接考虑底层贡献,那么同一块显然是 \(\frac {n(n-1)} {4}\)。块之间,注意到前缀最大值大的肯定会被放在后面,令两个数在其块内的下标为 \(x,y\),那么 \(x\) 赢就是 \(\frac {x-1}{2(x+y)}\),\(y\) 赢就是 \(\frac {y-1} {2(x+y)}\),加起来只和 \(x+y\) 有关,所以可以用 \(O (n)\) 的时间处理两个块。
注意到块长差距不会很大(更精确的,或许只是 \(1\)),所以维护一下 \(cnt\) 统一处理就做完了。
这种字符串题一般有很强的性质,建议手玩捏。
我能猜出结论但是证不出来。和 border 有关,设为 BAB。那么手玩一下发现 BA,B|BAB \(\rightarrow\) BAB,BA|BABBA \(\rightarrow\) BABBA,BAB|BABBABAB \(\rightarrow\) BABBABAB,BABBA|BABBABABBABBA。
搞笑呢?border \(>\frac n 2\) 咋办?发现这个多出来的部分就是周期啊!所以 S|S \(\rightarrow\) SU|SU \(\rightarrow\) SU,S|SUS \(\rightarrow\) SUS,SU|SUSSU。
一半的部分呈斐波拉契式增长,就是每次把 \(f_{i-2}\) 加在后面。这个随便胡一胡统计一下就好了。注意特判周期整除的情况,此时是 \(A^{\infty}\)。
到时候来证。
很巧妙的题。注意到 \(x\),取因子的补集 \(y\),那么 \(xy=\prod b_i^2\),所以答案等于总方案数 + 等于的数量。
dp 即可。
其实早该意识到没有 polylog 做法的。
然后 bitset,把询问弄成一个 bitset,然后边的状态的话注意空间是开不下的,但是可以分块打表!
建出广义 SAM,区间内分成两部分,前一部分到 \(r\) 的距离 \(>|T|\),所以比后缀字典序一定是对的,可以用广义 SAM 建出 SA 数组,主席树二分查询第 \(k\) 大,然后二分找出刚好大于的。
后一部分 \(\sum \leqslant 2e5\),直接暴力就好了。
std 是观察到答案只能是 \(|T|\) 加上一个字母,然后依次枚举,剩下的就是对 endpos 的二维偏序要求,然后就做完了。
考虑长链剖分,维护 \(d(i,j)\) 表示 \(i\) 子树深度为 \(j\) 有多少点。思考如何合并答案。
考虑根号分治,对于短链长度 \(>\sqrt n\) 的情况,只会出现 \(\sqrt n\) 次,这时暴力 dp 即可。
\(<\sqrt n\) 的情况,似乎不太好维护 \(d|dis\) 的个数?其实可以设 \(f(i,j)\) 表示这样的答案,每次这个祖先上贡献即可。但是要限制在不同子树,所以要微调一下,贡献在祖先对应的儿子上,到时候枚举儿子即可。
记录一种长度为 \(n-1\) 的符号序列 \(T\) 的个数为 \(f(T)\),那么答案即为 \(\sum f^2(T)\)。
不妨容斥一下转为钦定哪些符号必须是小于号,因为这样的贡献是简易的,即为 \(\binom {n} {a_1,a_2,a_3...}\),其中 \(\{a_i\}\) 钦定的小于号划分成的集合。
那么答案即为 \(\sum _S \sum_{S\subseteq T1}\sum_{S\subseteq T2} (-1)^{|T1-S|}(-1)^{|T2-S|}f(T1)f(T2)\)。
\(=\sum_{T_1}\sum_{T_2} (-1)^{|T1|}(-1)^{|T2|}f(T1)f(T2)2^{|T1\cap T2|}\)。
这其实是不易维护的,因为分界线的值并不能直接计算 \(f\)。
考虑取补集,这样计算 \(f\) 更容易一些。那么取补集再转化成交就是 \(2^{n+1}\sum_{T_1}\sum_{T_2}(-\frac 1 2)^{|T_1|+1}(-\frac 1 2)^{|T_2|+1}f(T_1)f(T_2)2^{T1\cap T2}\)。
(怎么 \(T_1\) 和 \(T1\) 混用?)
那这前面一堆本质上就是划分连续块。可以多项式求逆(\(\frac {1} {1-f(x)}\))解决。
现在的瓶颈是 \(2^{T1\cap T2}\),注意到这相当于枚举 \(T1\) 和 \(T2\) 的共同子集 \(S\),然后它们 组合成 \(T1\) 和 \(T2\),那么就相当于 \(S\) 的生成函数有标号组合,得到 \(T1\) 和 \(T2\) 后再组合,所以两次求逆即可。
注意要同时算两个集合,所以在第一次组合时将系数平方即可。
[ARC156E] Non-Adjacent Matching
简单题。先猜 \(a_i+a_{i+1}\leqslant \frac {all} 2\) 的结论,然后据此计数即可。
最后算三个的情况时是枚举两边的最大值和三个数的和,这样应该会好做一些。
将容斥系数改为 \(-1\) 的连通块大小次方即可。
运用 prufer 序列计数,注意点数和度数是要匹配的,所以从后往前背包点数和度数即可。
考虑离线怎么做。从左到右扫右端点,若使考虑更新一个回文串的最后出现位置,是不方便使用 DS 维护且是 \(n^2\) 的。想到线段树维护左端点的答案,那么能否转化为区间加之类的?
考虑回文串可以划分为 \(\log\) 段等差数列,并且这些等差数列除了首项其他的上一次出现次数是可以很快知道的,就是 \(n-len_1+1\),\(len_1\) 为首项长度。
解释一下,因为等差数列中后一项的长度大于前一项的一半,根据回文串的性质我们知道这只会在头尾出现。
求出首项上一次出现位置末尾 \(pos\),那么 \([pos-len_1+2,i-len_1+1]\) 这些位置都是要加 \(1\) 的。非首项的贡献为 \([pos_{las}-len_{las}+2,i-{len_{now}+1}]\),发现这些区间刚好能拼起来。
所以贡献区间是 \([pos-len_1+2,i-len_{minn}+1]\),然后就做完了。求 \(pos\) 的话每次在 PAM 上添加 \(i\) 查询子树最大值即可。
在线的话改成主席树即可。并且可以差分转为单修区查。
将两个串 \(s_1t_1s_2t_2...\) 拼起来,问题转化为将串划分为最少的偶回文串,然后注意字母相同的划分不提供贡献。
写出如下形式 dp:\(dp_{i}=\min\{dp_{j-1}\}+[[i,j]不完全相同] ([i,j] 是回文串)\)。
尝试利用上题提到的性质。由于后一个串都会在 \(i-del\) 的末尾出现一次,那其实如果一个串有等差数列的后继,我们之前在 \(i-del\) 的地方应该已经从相同的地方转过一次,所以直接利用 \(i-del\) 的值即可。唯一没包括到的等差数列的末尾,直接特殊转过来即可。
需要注意的是不能直接用 \(dp_{i-del}\) 因为 \(dp\) 可能还包含其他转移。所以把这个值记录在 PAM 节点上即可。
点分治,统计经过根的路径。暴力可以枚举所有链,在 SAM 上跑,那么是 \(n^2\) 的。
考虑这个根,在原串的位置 \(p\),那么答案就是 \(L_p*R_p\),其中 \(L_p\) 表示是 \([1,p]\) 的后缀的经过根的半截字符串的个数。\(R_p\) 同理。
考虑 \(L\) 怎么求,\(R\) 同理。“是后缀” 想到 SAM,那么操作形如每次在字符串的前面加一个字母,求出 SAM 所在节点,对其打标记。对于一个 \(p\),答案即为 \(p\) 在 SAM 上的节点到根的标记总和。
如何在前面加一个字符?若 \(i<sam[now].len\),直接判断这个字符能否匹配,若可以还是这个节点,否则直接寄掉。若相等,考虑 fail 树的某个儿子是否满足条件即可。
所以设 \(trans[p][c]\) 即可,可以线性处理。
这样做的复杂度是 \(O(n+siz)\)。结合 \(O(siz^2)\) 暴力,若 \(siz<\sqrt n\) 直接暴力,那么考虑与一个点相合的个数不超过 \(\sqrt n\) 个,若 \(siz>\sqrt n\),那么直接用前者,稍微感觉一下发现时间复杂度 \(O(n\sqrt n)\)。
下次再来打。
倍增的细节好难想清楚啊。(
考虑 \(l=r\),直接 AC 自动机即可。
否则,考虑若 \(2^k\) 是高位那么 \(w(l,r)\) 是 \(w(l+2^k,r+2^k)\) 取反,想到把这个拆成 \(\log\) 个区间。
具体地,先 \(l\) 一直加 lowbit,直到 \(l\) 是 \(r\) 二进制的子集,再 \(r\) 一直减 lowbit 即可。
设 \(f(x,i,0/1)\) 表示 AC 自动机节点 \(x\),经过 \(2^i\) 步,当前 “0” 状态是否被取反到达哪个位置。
然后最后设 \(g(x,i,0/1)\) 表示次数,最后转移一下即可。
最多随便贪心,最少不是优先选多或少的而是看能否组成 \(k\)。那这个经典 \(n\sqrt n\)。
原来典题这个还能优化!
如果个数少是可以使用 bitset 优化的。那么我们小于阈值 \(T\) 用这个做法,大于阈值 T 直接跑 bitset。那么复杂度是 \(O(nT+\frac {n^2} {Tw})\),取 \(T=\sqrt {\frac {n} {w}}\),复杂度 \(O(n\sqrt{\frac {n} {w}})\)。
可能直观来说交替选是一种不错的选择,考虑两种交替选的方案,他们的权值和是 \(2\binom {n} {2}-3n\),那么答案 \(\geqslant \binom n 2 -\frac 3 2 n\)。
考虑贡献是 \(\binom n 2-\sum \binom {n0} {2}-2\sum \binom {n1} {2}\)。\(n0,n1\) 表示联通块大小。那 \(n0,n1\) 都是根号级别,直接 dp 即可。
有点卡空间,可以用 vector 释放内存的机制,每次在 \(x\) dfs 第一个儿子回来的时候建立 \(x\) 的 dp 值,儿子向上转移了就把儿子的空间释放了,这样当前存在的空间只会是父亲到现在的一条链中不是第一个儿子的个数,但这样也会被这样的图卡掉。
所以我们将儿子按照最大深度从大到小排序即可。应该是只会有最多 \(\sqrt n\) 个 dp数组同时存在,所以就做完了。
是不是想复杂了。
这怎么没想到?
先考虑如何计算最大价值。考虑操作后会形成若干连续颜色段,我们在颜色段的底端统计,那就要求来自不同子树,那么对于一个点,答案上界为 \(\min(siz-1,2(siz-\max(maxsonsiz,a_i)))\)。
发现儿子的决策和父亲的决策是独立的,所以每个点都能取到上界。
考虑维护答案。\(x\) 是这个点到根节点的任意一个点,首先如果 \(2siz_{x}\) 已经大于等于 \(siz_{fa}\),那么 \(fa\) 答案不会变化了。否则只有 \(\log\) 次。树剖线段树上二分找到这个点,令 \(t_i\) 为 \([2siz_i\geqslant siz_{fa}]\),操作涉及改变 \(t_i\),修改 \(fa\) 处的答案。还有记录当前重儿子方便算答案,发现都是可以维护的。
打完才发现其实一点也不难打。一个优化是把 \(a_x\) 建成新点 \(x+n\) 挂在 \(x\) 上,这样就不用考虑 \(a_x\) 为最大值的情况了。
考虑从小到大填数,那么每次可填的区间限制大抵只会减少,但是存在 \(mex=i\) 的问题,此时这些区间是不能包含 \(i\) 的。
但是注意到此时 \(i\) 和 \(1\sim i-1\) 的决策区间不交,所以不会影响到 \(i\)。也就是说,要么包含,要么相离。所以从小到大能选就选即可。
其实猜到结论了,但是我没有去证。。。
比较简单的 F,要是放在现在的 AGC 说不定就是 A 或者 B 了。
发现从根开始,肯定要去找比它小的。找不到就 g 了。
那么直接模拟 dp 即可。
前面有好多题的博客都没写,现在来补一点。
EBaby's First Suffix Array Problem
直接用原来的 \(sa\) 统计,然后转化成二维偏序即可。
注意 \(x\leqslant \min(y,z)\) 可以拆成 $x\leqslant y $ 并且 \(x\leqslant z\)。
懒得写题解了。
这个下传太花时间了,能不能不下传呢?
考虑把所有点看成 \(-1\),一个点操作就加 \(1\),那么一个点能被染到大抵是和 \(\geqslant0\)。
假设最后 \(x\) 的染色到达了 \(y\),那么就是 \(x\sim y\) 的路径上值 \(\geqslant 0\),也就是说,\(y\) 的后缀 \(\max\geqslant 0\)。
那么染白就是刚好将上面的信息与子树阻断,那么就是子树置为 \(-1\),然后阻断一下上面来的贡献,也就是再减去根的后缀最大值即可。
树剖维护即可。
其实这个思路的 motivation 是,发现修改 \(O(n)\),查询 \(O(1)\),所以就想到平衡修改和查询了。
若会取模取最大值和次大值即可,现在探讨不取模的情况。
应该是可以线段树直接做?但是会被卡空间。。。所以改成平衡树。
考虑本题双向匹配一定是最优的,能否只维护双向匹配?答案是可以的。那么就做完了。
联通块想到点分治,那么每个点可以用 \((mn,mx)\) 二元组表示。
但是如何将这些修改打到符合条件的询问上?(即 \(x\) 能到根)似乎不是很好做。
考虑直接查询?那么多个点分治根的贡献怎么合并呢?
但是发现点分治的合理性在于如果 \(x\) 和当前根不连通,所有答案就一定在下一个子树里。
但是如果联通呢?发现所有答案一定会在当前子树里。
那么就做完了。数颜色也不用真的去数,发现是 \(l\geqslant qry_l\) 的形式,直接动态在当前颜色最大的地方加一即可。
全局加肯定是有性质的。具体地,设原来的最大子段和为 \(y\),区间长度为 \(x\),全局加上了 \(k\),那么就是 \(kx+y\)。也就是说只用看 \((x,y)\) 即可。
考虑线段树维护凸包 \(L/R/ans\),形如凸包闵可夫斯基和,取并,和拼接,都是可以做的,所以做完了。
离线询问指针移做到单 log。
卡空间,所以离线一层一层做,但是懒得实现了。
upd: PKUSC2024 D2T2 我也这样被卡了,孩子,这并不好笑。
到时候来补。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号