一次爬虫--Boss直聘数据爬取分析
毕业临近,笔者的心情愈发沉重。作为一名练习时长两年半的网安练习生,不具备大牛般的专业能力,面对竞争激烈的就业市场,感到前所未有的压力。身边的同学陆续拿到了offer,有的进入了名企,有的决定出国深造;而我的邮箱却依旧空空如也。
在一天晚上,和兄弟们喝酒吹牛逼的时候讨论着毕业的去向及远大的抱负,兄弟们说现在找工作简直就像打仗,要每天刷各种招聘网站,了解就业环境及薪资水平,于是便写下了这个脚本,帮助大家爬取招聘网站的招聘数据,让兄弟们更好的了解就业环境及平均薪资水平;
使用方法介绍:DrissionPage,第一次使用的话需要安装配置DrissionPage的基本环境;可以参照下面官网教程进行配置;
详情官网:DrissionPage官网介绍文档
构建爬虫的基本思路:选定目标站点,找到目标数据,分析目标数据加载来源(通过元素选择或者通过JS读取),爬取数据保存到本地;
样例代码如下:(爬取boss直聘相关岗位信息,关键词:渗透测试,应届)
目标URL:https://www.zhipin.com/web/geek/job?query=渗透测试&city=100010000&experience=102&page=1
寻找目标数据存储位置(https://www.zhipin.com/wapi/zpgeek/search/joblist.json)
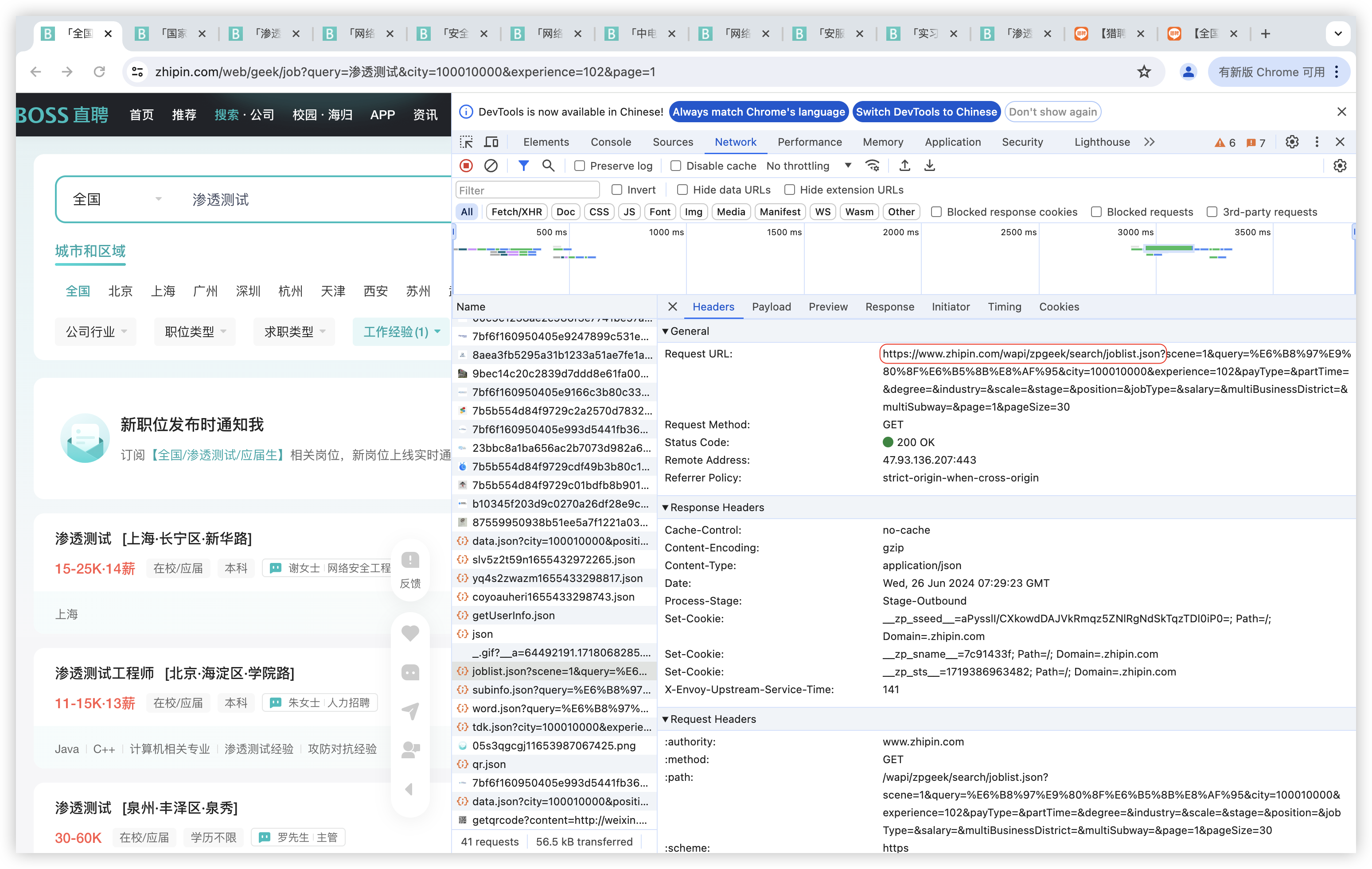
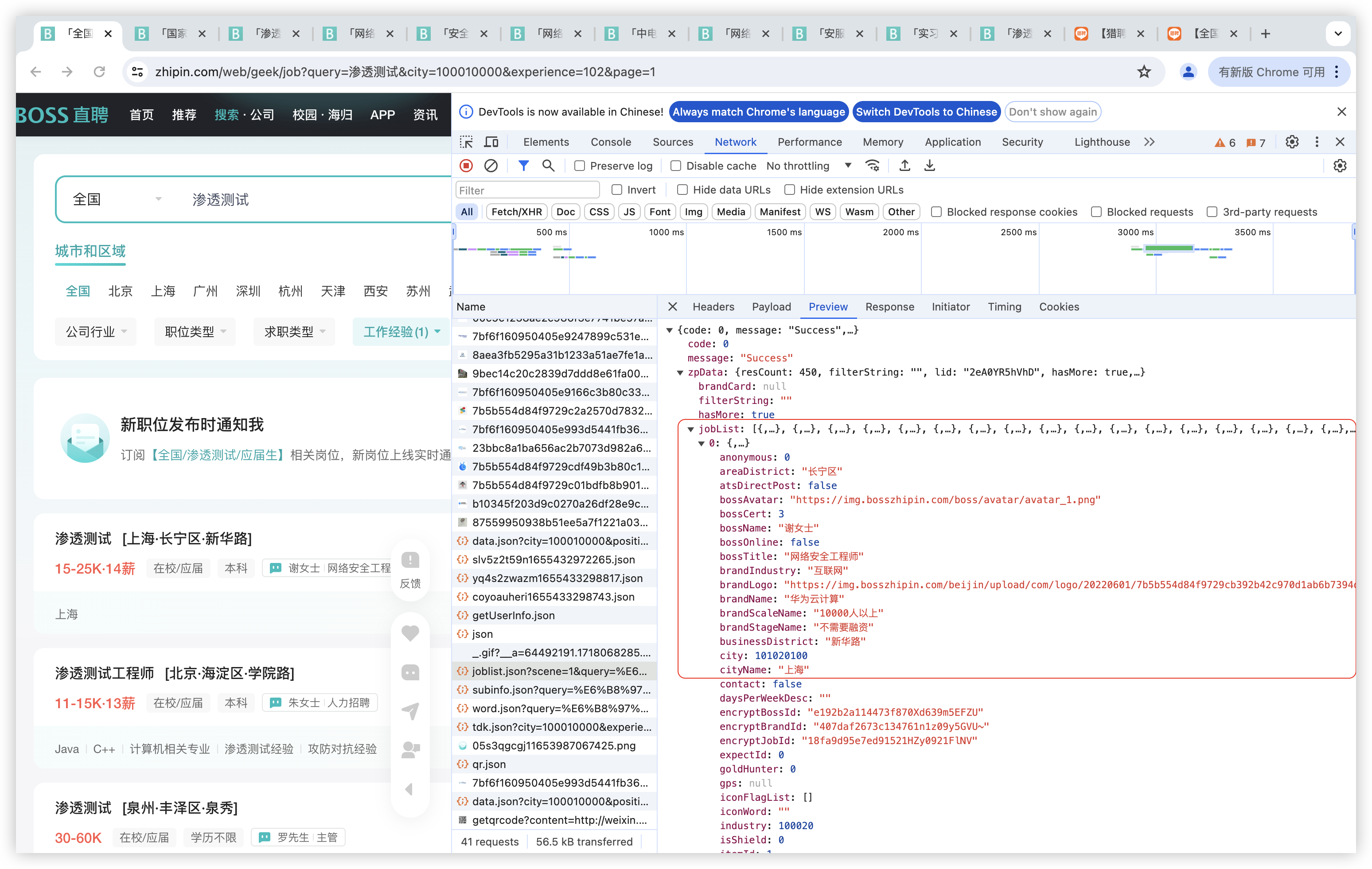
找到了招聘岗位的基本数据来源,就构造脚本:
from DrissionPage import ChromiumPage
import csv
#创建csv文件,定义字段头
f = open('BossData.csv', mode='w', encoding='utf-8',newline='')
csv_writer = csv.DictWriter(f , fieldnames=[
'jobName',
'brandName',
'cityName',
'salaryDesc',
'jobDegree',
'jobExperience',
'skills',
'welfareList'
])
csv_writer.writeheader()
page =ChromiumPage()
#监听数据所存在的json文件
page.listen.start('/wapi/zpgeek/search/joblist.json')
for i in range(1,11):
#访问目标网站,搜索岗位关键字,page参数为页码
page.get(f'https://www.zhipin.com/web/geek/job?query=%E6%B8%97%E9%80%8F%E6%B5%8B%E8%AF%95&city=100010000&experience=102&page={i}')
#等待浏览器资源加载
resp = page.listen.wait()
#读取返回包body内容
Jsondata = resp.response.body
Joblist = Jsondata['zpData']['jobList']
for job in Joblist:
dit = {
'jobName': job['jobName'],
'brandName': job['brandName'],
'cityName': job['cityName'],
'salaryDesc': job['salaryDesc'],
'jobDegree': job['jobDegree'],
'jobExperience': job['jobExperience'],
'skills': ' '.join(job['skills']),
'welfareList': ' '.join(job['welfareList'])
}
csv_writer.writerow(dit)
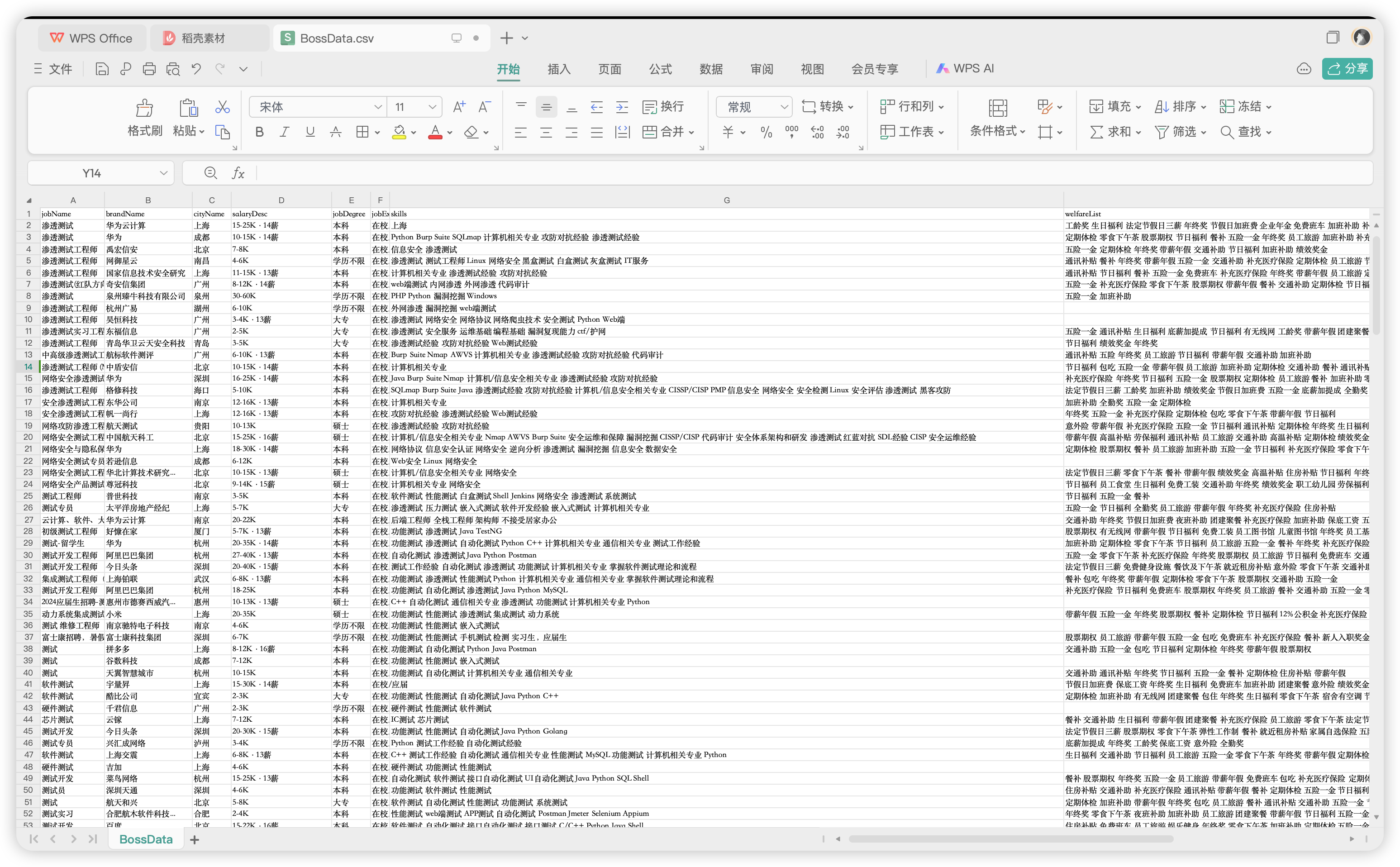
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号