集合笔记
1、集合框架体系
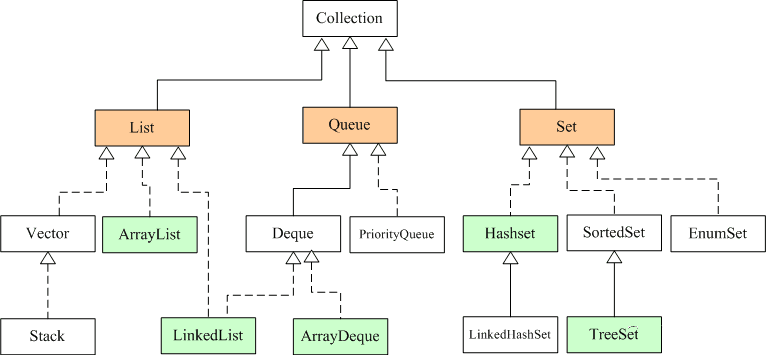
集合主要是两组:单列集合和双列集合
- Collection 接口有两个重要的子接口 List 和 Set,他们的实现子类都是单列集合
- Map 接口的实现子类是双列集合,存放的 Key-value
Java集合时间复杂度 - Alex-XYL - 博客园 (cnblogs.com)

2、Collection
2.1 Collection 接口常用方法:
Collection接口遍历元素方式:
- 使用 Iterator 迭代器
- 增强for 循环

List list = new ArrayList();
list.add("jack");
list.add("tom");
list.add("mary");
Iterator iterator = list.iterator(); // 得到集合迭代器
// has.next() 判断是否还有下一个元素
while (iterator.hasNext()) {
// next() 指针下移,将下移位置上的元素返回
System.out.println(iterator.next());
}
注意:在调用 iterator.next() 方法之前必须要调用 iterator.hasNext() 进行检测。若不调用,且下一条记录无效,直接调用 iterator.next() 会抛出 NoSuchElementException 异常。

List list = new ArrayList();
list.add("jack");
list.add("tom");
list.add("mary");
// 使用增强for循环
for (Object o : list) {
System.out.println(o);
}
说明:
- 增强for循环,不仅可以用在Collection集合中,也可以用在数组中
- 增强for,底层仍然是迭代器,可以认为是简化版的迭代器
2.2 List 接口常用方法


List 的三种遍历方式:
-
Iterator 迭代器
-
增强for循环
-
普通for循环
2.2.1 ArrayList
说明:
-
运行添加空值,并且可以添加多个,即arrayList.add(null)
-
ArrayList是由数组来实现数据存储的
-
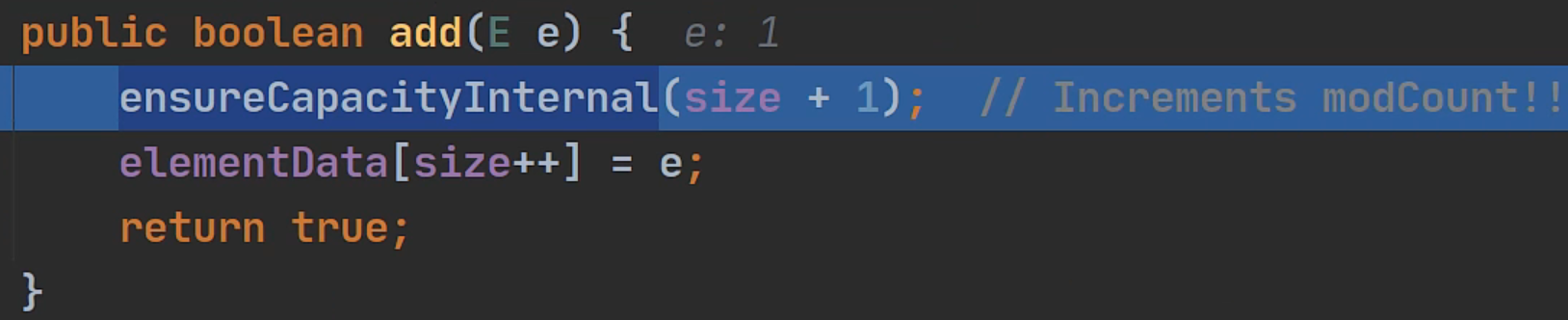
ArrayList基本等同于Vector,除了ArrayList线程不安全(但是执行效率高),多线程下情况下,不建议使用ArrayList
// ArrayList的add方法没有加synchronized关键字修饰,线程不安全 public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }
底层源码分析
-
ArrayList中维护了一个Object类型的数组elementData
transient Object[] elementData; // transient 修饰的属性不会被序列化 -
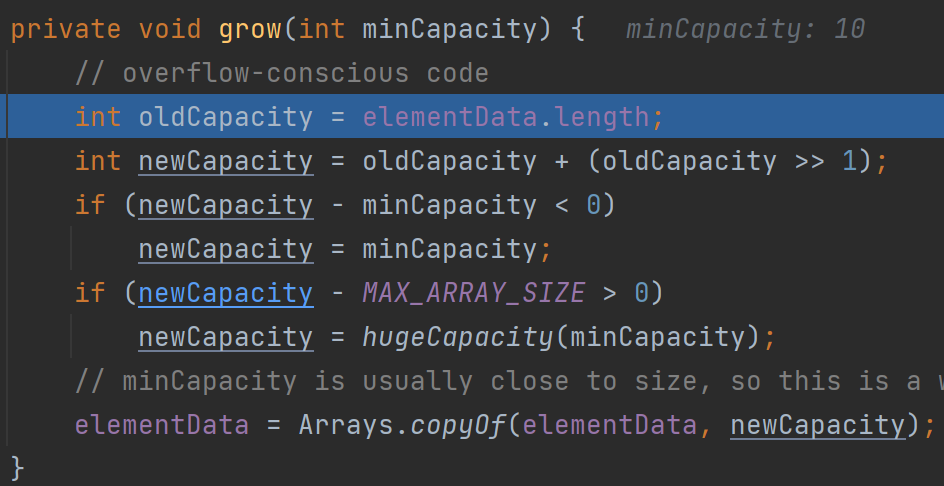
当创建ArrayList对象时,如果使用的是无参构造器,则初始elementData容量为0,第1次添加,则扩容elementData为10,如需要再次扩容,则扩容elementData为1.5倍
newCapacity = oldCapacity + (oldCapacity >> 1); -
如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容,则直接扩容elementData大小的1.5倍
1、使用无参构造器,创建和使用ArrayList
创建了一个空的数组,elementData={};

执行list.add,
(1)先确定是否要扩容
(2)然后再执行 赋值
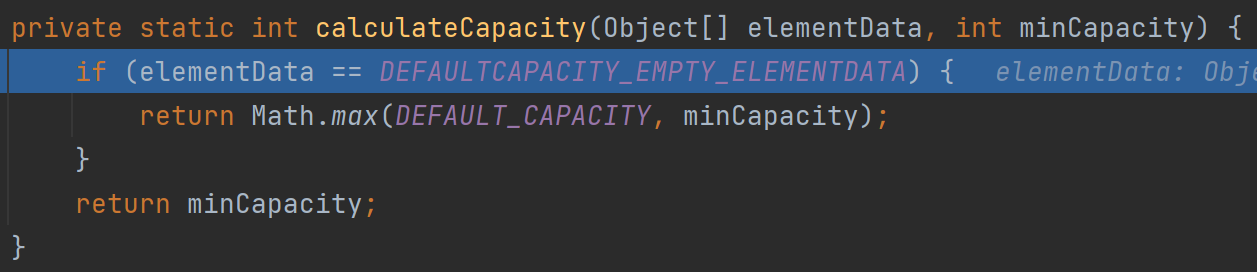
该方法确定minCapacity
(1)第一次扩容为10

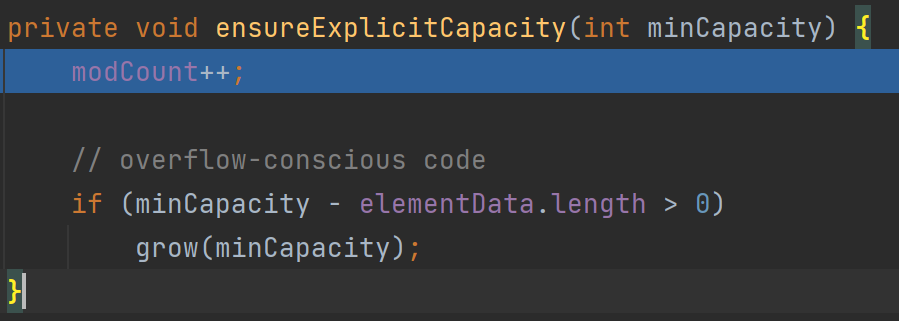
(1)modCount++ 记录集合被修改的次数,防止多线程操作出现异常
(2)如果elementData容量不够minCapacity,就调用grow()去扩容
(1)真的扩容
(2)使用扩容机制来确定要扩容到多大
1. 第一次newCapacity=10
2. 第二次及以后,按照1.5倍扩容
3. 扩容使用的是Arrays.copyof()
2、使用有参构造器,创建和使用ArrayList
创建了一个指定大小数组,this.elementData=new Object[capacity];
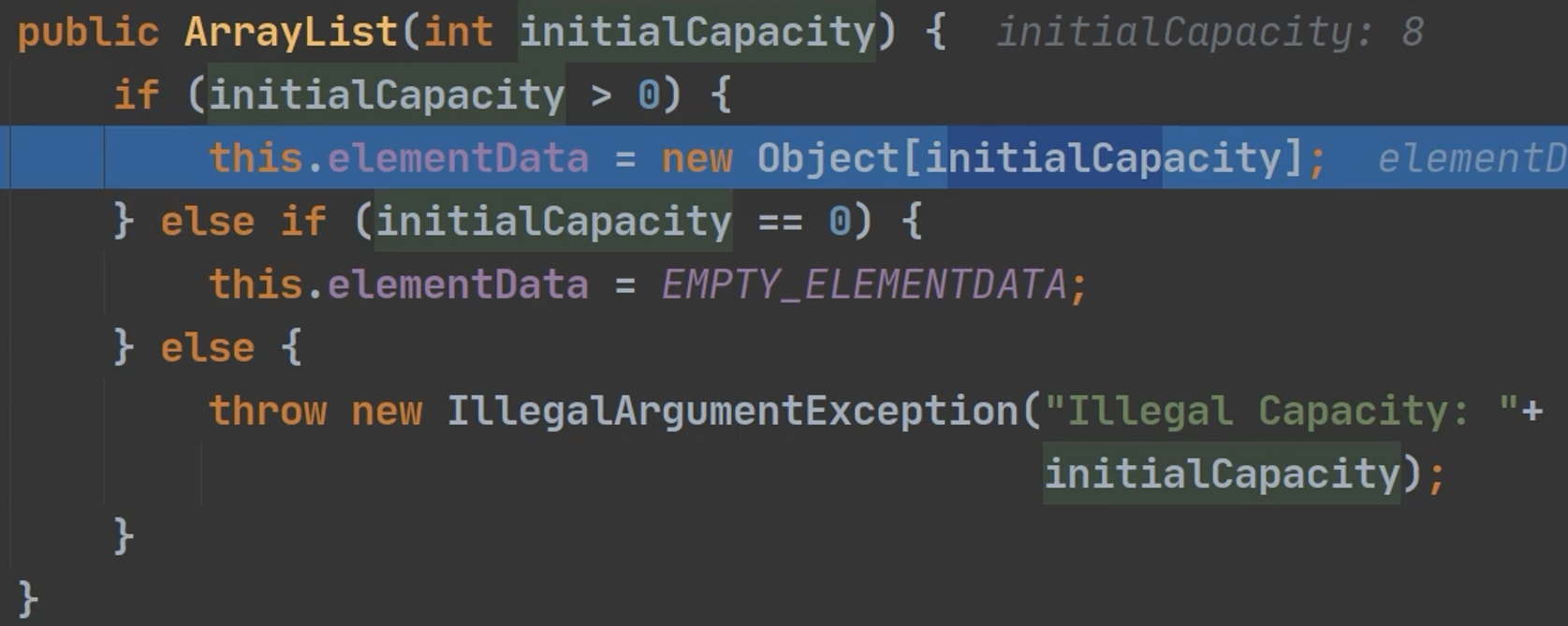
如果是有参构造器,扩容机制:
(1)第一次扩容,就按照elementData的1.5倍扩容
(2)整个执行的流程还是和前面无参构造一样
2.2.2 Vector
-
底层也是一个对象数组
protect Object[] elementData; -
Vector 是线程同步的,即线程安全,Vector类的操作方法带有synchronized关键字
Vector 构造器


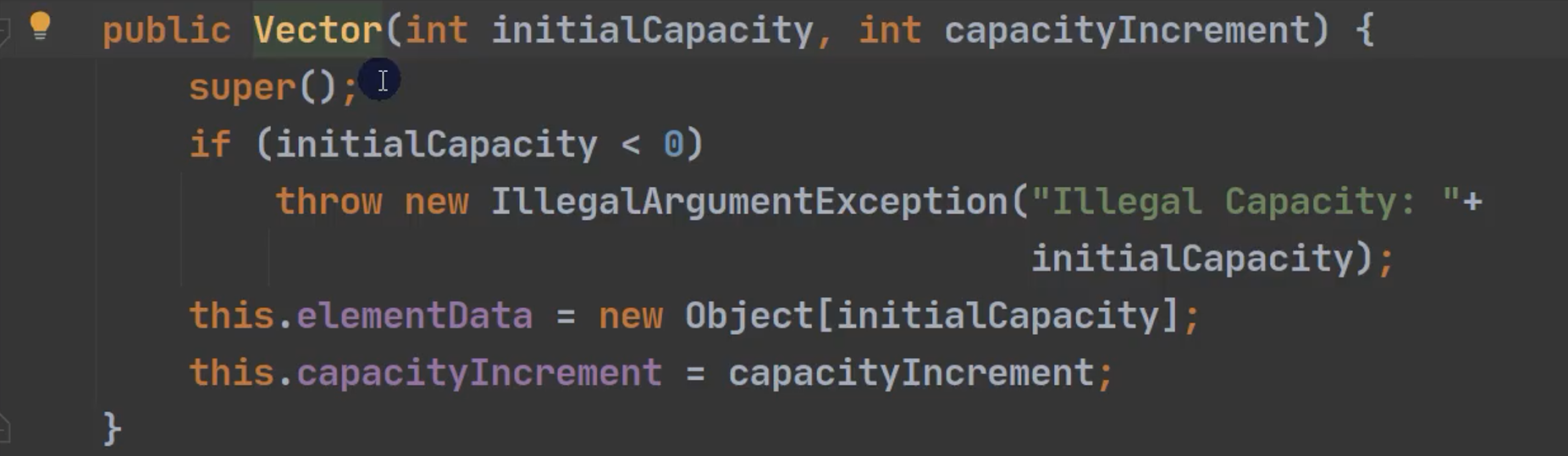
添加数据到vector集合
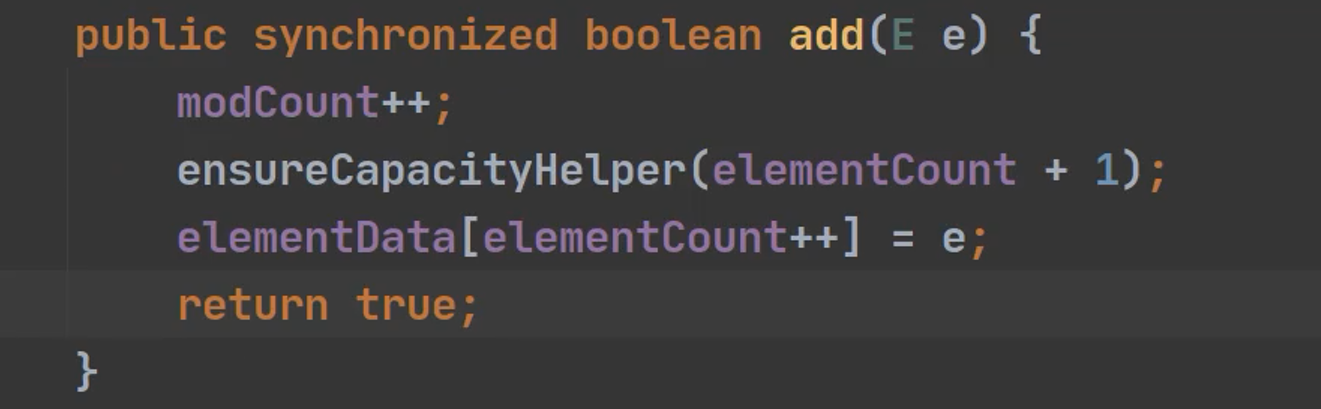
确定是否需要扩容,条件 minCapacity - elementData,length > 0
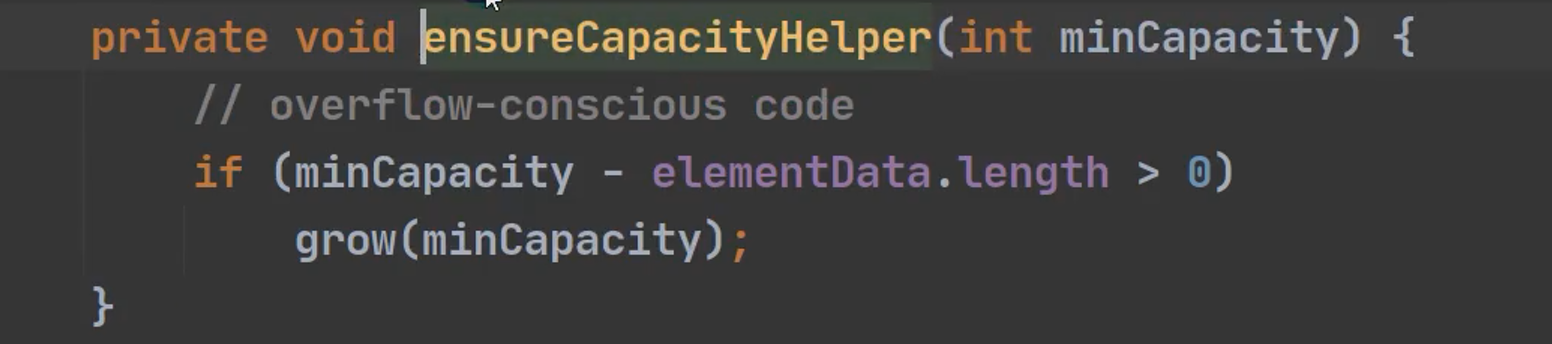
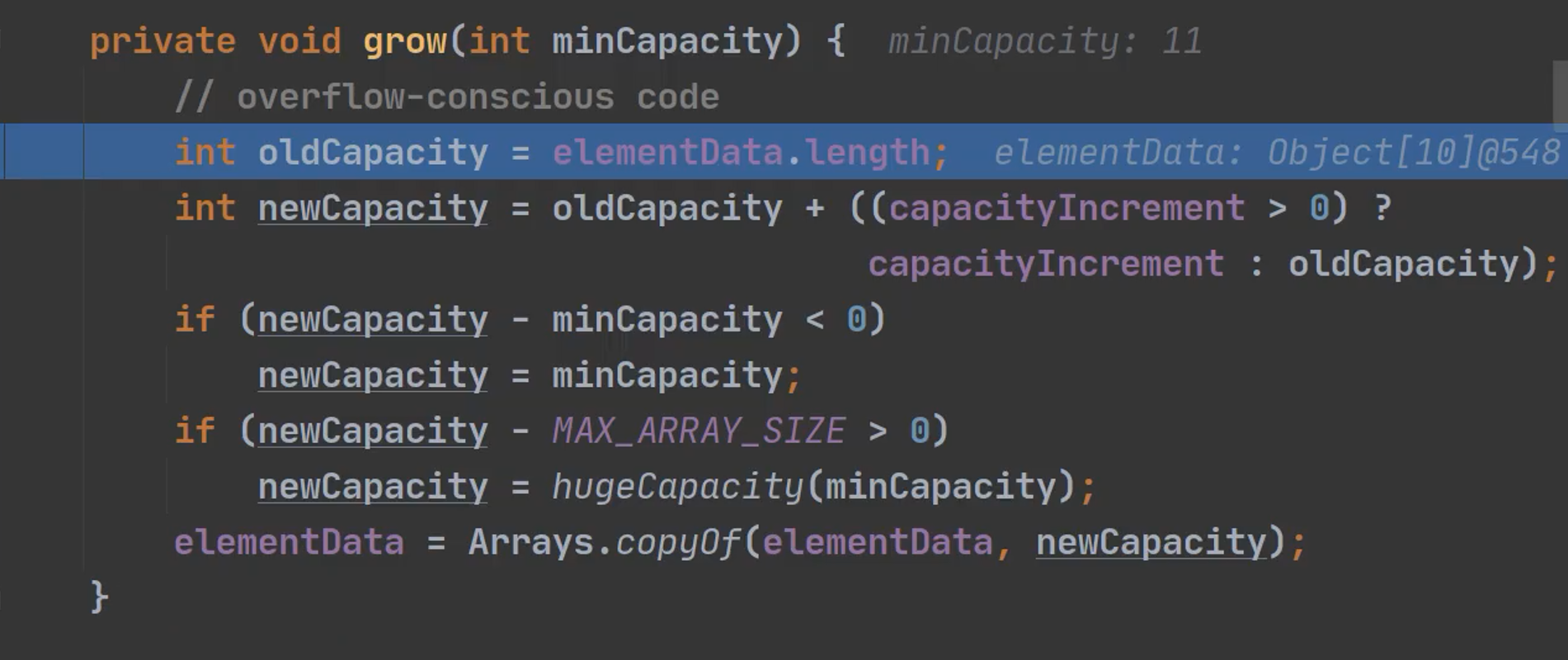
使用2倍oldCapacity 扩容 或者 指定增量扩容。
2.2.3 LinkedList
- LinkedList 底层维护了一个双向链表
- LinkedList中维护了两个属性 first 和 last分别指向首结点和尾结点
- 每个结点(Node对象),里面又维护了prev、next、item三个属性,其中通过prev指向前一个结点,通过next指向后一个结点。
- LinkedList的元素添加和删除不是通过数组完成的,效率较高
空构造函数初始化对象,这时 linkedList 的属性 first==null,last==null

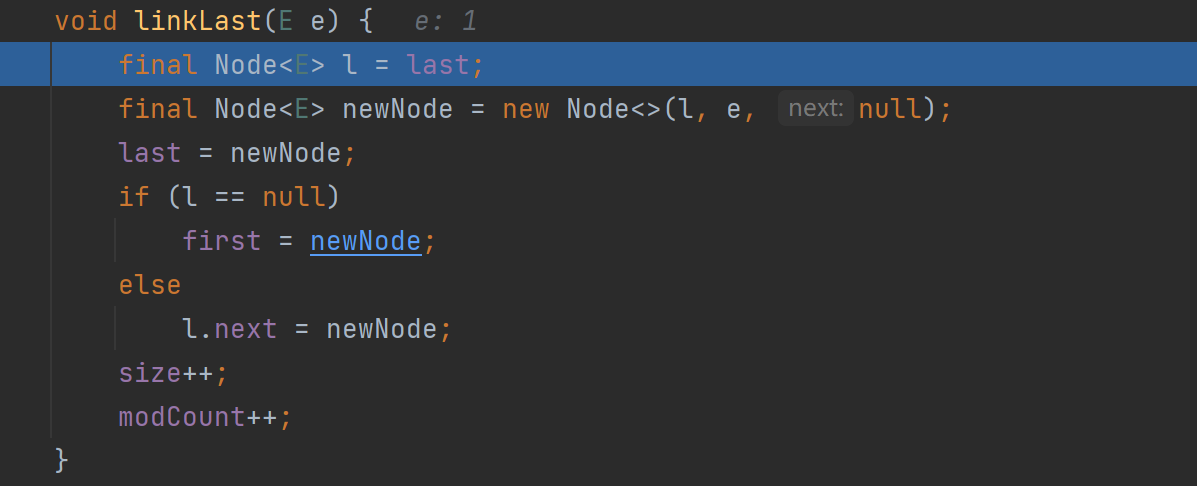
执行 添加

将新的结点加入到双向链表的最后
执行 删除

实际执行 removeFirst() {...}
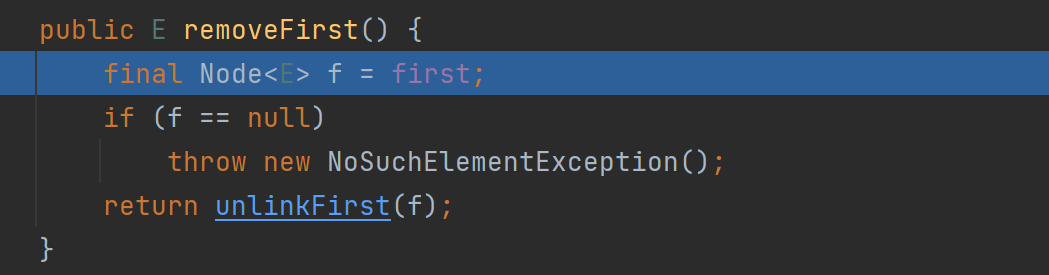
删除的具体代码 unlinkFirst() {....},将 f 指向的双向链表的第一个结点删除
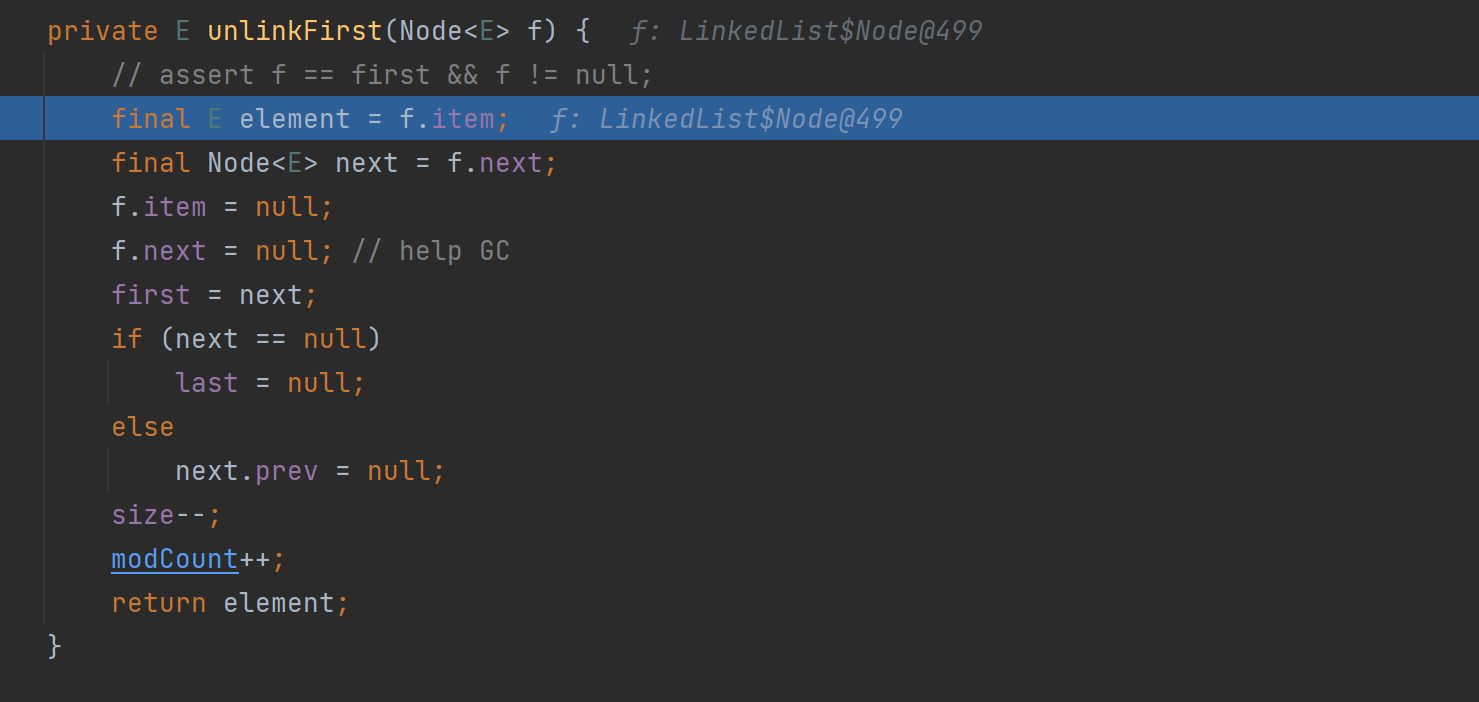
ArrayList 和 LinkedList 比较

2.3 Set接口和常用方法
-
无序(添加和取出的顺序不一致),没有索引
注意:取出的顺序虽然不是添加的顺序,但是他是固定的
-
不允许重复元素,最多包含一个null
Set接口的常用方法:和Collection接口一样
Set接口的遍历方式:
- 迭代器
- 增强for循环
- 不能使用索引方式遍历
2.3.1 HashSet
HashSet实际上是HashMap
// HashSet 构造器
public HashSet() {
map = new HashMap<>();
}
- HashSet 底层是 HashMap
- 添加一个元素时,先得到hash值,然后转成索引值
- 找到存储数据表table,看这个索引位置是否已经存放有元素
- 如果没有,直接加入
- 如果有,调用 equals 比较,如果相同,就放弃添加,如果不相同,则添加到最后
- 在JDK1.8中,如果一条链表的长度超过 TREEIFY_THRESHOLD(默认是 8 ),并且table的大小>=MIN_TREEIFY_CAPACITY(默认是64),就会进行树化(红黑树)。
源码分析:
public static void main(String[] args) {
HashSet hashSet = new HashSet(); //1
hashSet.add("java"); //2
hashSet.add("php"); //3
hashSet.add("java"); //4
System.out.println("set=" + hashSet); //5
}
-
执行构造器 HashSet()

-
执行 add() 方法

PRESENT 没有具体意义,主要起到占位的作用

执行 put() 方法,该方法会执行 hash(key) 得到key对应的hash值(不是hashcode)

hash() 方法

-
执行 putVal() 方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //定义了辅助变量 //table 就是 HashMap 的一个属性,类型是 Node[] //if语句表示如果当前table是null,或者大小==0 //就是第一次扩容,扩容大小为16 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //(1)根据key,得到hash 去计算该key应该存放到table表的哪个索引位置 // 并把这个位置的对象赋给辅助变量p //(2)判断p 是否为空 //(2.1)如果p为空,表示还没有存放元素,就创建一个Node(key="java",value=PRESENT) // 直接放在该位置 // if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; // 定义辅助变量 //如果当前索引位置对应的链表的第一个元素的准备添加的key的hash值一样 //并且满足 下面两个条件之一: //(1)准备加入的key和p指向的Node结点的key是同一个对象(地址相同) //(2)p指向的Node结点的key的equals()和准备加入的key相同(属性相同) //就不能加入 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //判断 p 是不是一棵红黑树 //如果是一棵红黑树,就调用 putTreeVal来进行添加 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else {//如果table对应索引位置,已经是一个链表,就是用for循环比较 //(1)依次和该链表的每一个元素比较,若都不相同,则加入到该链表的最后 //注意:在把元素添加到链表后,立即判断该链表是否已经超过8个结点 //(添加第9个元素时,转成红黑树) //如果达到,就调用 treeifyBin() 对当前这个链表进行树化(转成红黑树) //在转成红黑树时,要进行判断table的长度是否到达64 //否则,,先进行table扩容,再转成红黑树 //(2)在比较过程中,如果有相同的,就直接break for (int binCount = 0; ; ++binCount) {//死循环 if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; //size 就是我们每加入一个结点Node,size就++ if (++size > threshold) resize(); // 扩容函数 afterNodeInsertion(evict); //对于HashMap来说,该方法为空,留给子类实现 return null; // 返回空,表示添加成功 }
HashSet扩容机制:
-
HashSet底层是HashMap,第一次添加时,table数组扩容到16,临界值(threshold)是 16*加载因子(loadFactor,0.75)=16*0.75=12
-
如果table数组使用到了临界值12,就会扩容到 16*2=32,新的临界值就是32*0.75=24,以此类推
注意:只要添加元素就size++,并不一定要求添加在table数组第一个位置,有可能全部添加在同一条链表中,也会扩容。
-
在JDK1.8中,如果一条链表的元素个数到达TREEIFY_THRESHOLD(默认是8),并且table的大小>=MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树),否则仍然采用数组扩容机制
练习:定义一个Employee类,该类包含private成员属性name,salary,birthday(MyDate类型),要求:1.创建3个Employee放入 HashSet中;2.当name和birthday值相同时,认为员工相同,不能添加到HashSet集合中。
package set_;
import java.util.HashSet;
import java.util.Objects;
public class HashSetExercise {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add(new Employee("milan",100,new MyDate(1998,1,1)));
hashSet.add(new Employee("smith",200,new MyDate(1998,1,1)));
hashSet.add(new Employee("milan",100,new MyDate(1998,1,1)));
System.out.println("hashset=" + hashSet);
}
}
//创建Employee对象
class Employee {
private String name;
private int salary;
private MyDate birthday;
public Employee(String name, int salary, MyDate birthday) {
this.name = name;
this.salary = salary;
this.birthday = birthday;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getSalary() {
return salary;
}
public void setSalary(int salary) {
this.salary = salary;
}
public MyDate getBirthday() {
return birthday;
}
public void setBirthday(MyDate birthday) {
this.birthday = birthday;
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", salary=" + salary +
", birthday=" + birthday +
'}';
}
//如果name和birthday相同,则返回相同的hash值
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return Objects.equals(name, employee.name) && Objects.equals(birthday, employee.birthday);
}
@Override
public int hashCode() {
return Objects.hash(name, birthday);
}
}
class MyDate {
private int year;
private int month;
private int day;
public MyDate(int year, int month, int day) {
this.year = year;
this.month = month;
this.day = day;
}
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public int getDay() {
return day;
}
public void setDay(int day) {
this.day = day;
}
@Override
public String toString() {
return year + "/" + month + "/" + day;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MyDate myData = (MyDate) o;
return year == myData.year && month == myData.month && day == myData.day;
}
@Override
public int hashCode() {
return Objects.hash(year, month, day);
}
}
2.3.2 LinkedHashSet
- LinkedHashSet 是 HashSet 的子类
- LinkedHashSet 底层是一个 LinkedHashMap,底层维护了一个 数组 + 双向链表
- LinkedHashSet 根据元素的hashCode 值来决定元素的存储位置,同时使用链表维护元素的次序,使得元素看起来是以插入顺序保存的
- LinkedHashMap 不允许添加重复元素

说明:
-
在LinkedHashSet 中维护了一个hash表和双向链表(LinkedHashSet 有 head 和 tail)
-
每一个结点有 before 和 after 属性,这样可以形成双向链表
-
在添加一个元素时,先求 hash 值,再求索引,确定该元素在 table 的位置,然后将添加的元素加入到双向链表(如果已存在,不添加,原则和HashSet一样)
tail.next = newElement;
newElement.pre = tail;
tail = newElement;
-
这样的话,我们遍历LinkedHashSet 也能保证插入顺序和遍历顺序一致
package set_;
import java.util.LinkedHashSet;
import java.util.Set;
public class LinkedHashSetSource {
public static void main(String[] args) {
// 分析一下 LinkedHashSet 底层机制
Set set = new LinkedHashSet();
set.add(new String("AA"));
set.add(456);
set.add(456);
set.add(new Customer("刘",1001));
set.add(123);
set.add("KXY");
System.out.println("linkedHashSet=" + set);
// 解读
//1. LinkedHashSet 元素加入顺序和取出顺序一致
//2. LinkedHashSet 底层维护的是一个LinkedHashMap(是HashMap的子类)
//3. LinkedHashSet 底层结构(数组+双向链表)
//4. 第一次添加时,直接将 数组table 扩容到16,存放的结点类型是 LinkedHashMap$Entry
//5. 数组是 HashMap$Node[] 存放的元素是 LinkedHashMap$Entry类型 数组多态:数组存放子类型元素
/* Entry 继承了 Node
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
*/
}
}
class Customer {
private String name;
private int no;
public Customer(String name, int no) {
this.name = name;
this.no = no;
}
@Override
public String toString() {
return "Customer{" +
"name='" + name + '\'' +
", no=" + no +
'}';
}
}
2.3.3 TreeSet

package set_;
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSet_ {
public static void main(String[] args) {
//1. 使用TreeSet提供的一个构造器,可以传入一个比较器(匿名内部类)
// 并指定顺序规则
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//下面调用String的compareTo方法进行字符串大小比较
//return ((String) o1).compareTo(((String) o2));
//按照字符串长度大小排序
return ((String) o1).length() - ((String) o2).length();
}
});
treeSet.add("jack");
treeSet.add("tom");
treeSet.add("sp");
treeSet.add("a");
System.out.println("treeSet = " + treeSet);
/*
1. 构造器把传入的比较器对象,赋给了 TreeSet底层TreeMap的一个属性this.comparator
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2.在调用 treeSet.add("tom")时,在底层会执行到
if (cpr != null) { //cpr 就是我们的匿名内部类(对象)
do {
parent = t;
cmp = cpr.compare(key, t.key); //动态绑定到匿名内部类的compare()方法
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //如果相等,即返回0,这个key加入不了
return t.setValue(value);
} while (t != null);
}
*/
}
}
2.3.4 TreeMap
package map_;
import java.util.Comparator;
import java.util.TreeMap;
import java.util.TreeSet;
public class TreeMap_ {
public static void main(String[] args) {
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//下面调用String的compareTo方法进行字符串大小比较
//return ((String) o1).compareTo(((String) o2));
//按照字符串长度大小排序
return ((String) o1).length() - ((String) o2).length();
}
});
treeMap.put("jack","杰克");
treeMap.put("tom","汤姆");
treeMap.put("kristina","克瑞斯提诺");
treeMap.put("smith","史密斯");
System.out.println("TreeMap="+treeMap);
/*
1.构造器,把传入的实现了Comparable接口的匿名内部类(对象),传给TreeMap的comparator
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2.调用put方法
2.1 第一次添加,把k-v封装到Entry对象,放入root
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
2.2 以后添加
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do { //遍历所有的key,给当前key找到适当的位置
parent = t;
cmp = cpr.compare(key, t.key); //动态绑定到匿名内部类的compare()
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //替换value
return t.setValue(value);
} while (t != null);
}
*/
}
}
3、Map
package map_;
import java.util.HashMap;
import java.util.Map;
public class Map_ {
public static void main(String[] args) {
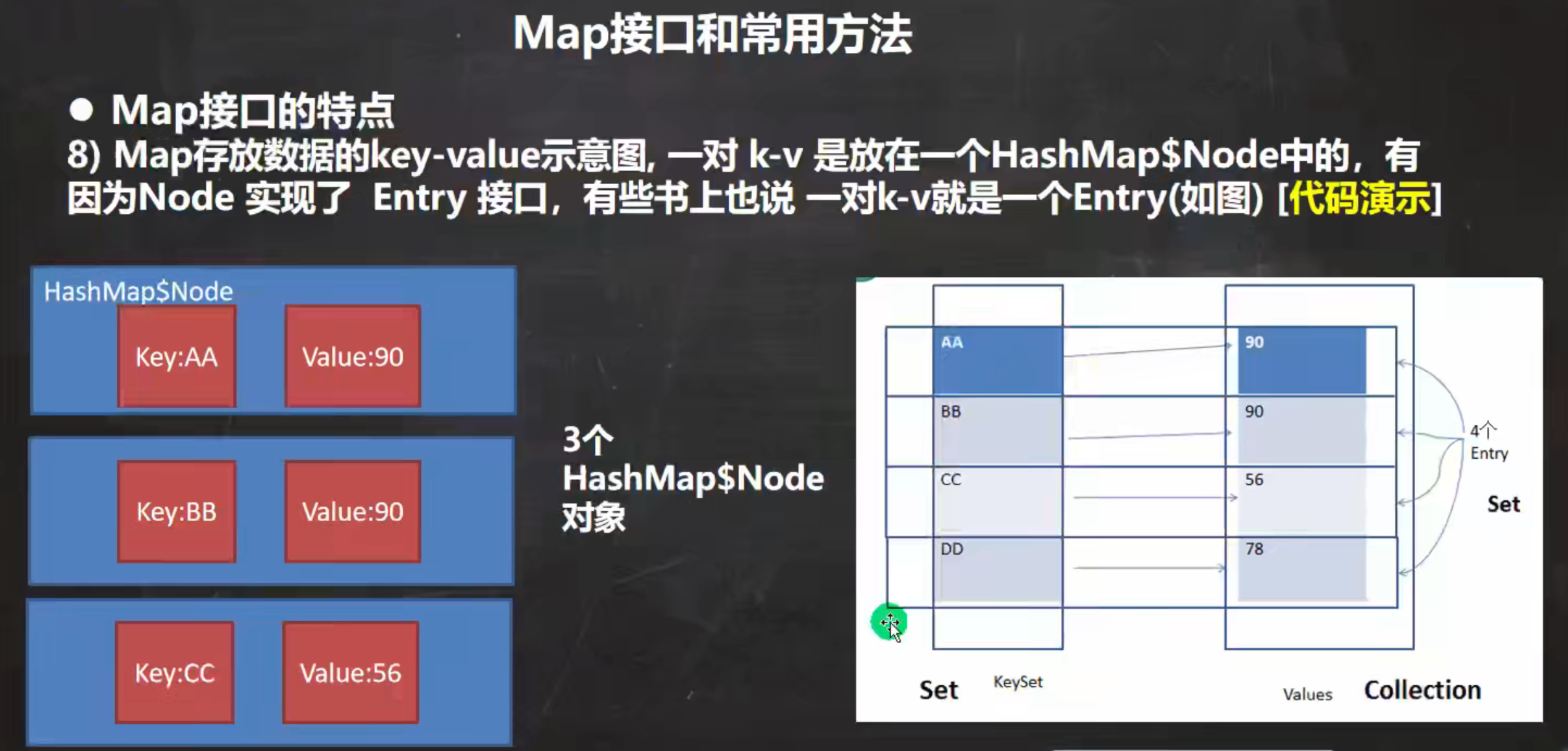
//1. Map 中的 key 和 value 可以是任何引用类型的数据,会封装到HashMap$Node 对象中
Map map = new HashMap();
map.put("No1","111");
map.put("No2","222");
//2. Map 中的 key 不允许重复,原因和HashSet一样
map.put("No1","333"); // 当有相同的key,会替换掉原有的 value
//3. Map 中的 value 可以重复
map.put("No4","111");
//4. Map 的key可以为 null,value也可以为null,注意 key为null 有且只有一个,value为null可以有多个
map.put(null,null);
map.put(null,"444"); //替换 key为null的value
map.put("No5",null);
map.put("No5",null);
//5. key 和 value 之间一一对应,通过一个key 总能找到对应的 value
System.out.println(map.get("No4"));
}
}
package map_;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapSource_ {
public static void main(String[] args) {
Map map = new HashMap();
map.put("No1","111");
map.put("No2","222");
//1. k-v 最后是 HashMap$Node node = newNode(hash,key,value,null)
//2. k-v 为了方便程序员的遍历,还会创建 EntrySet 集合,该集合存放的元素的类型是 Entry,
// 而一个Entry 对象就有key 和 value,即 EntrySet<Entry<key,value>>
//3. entrySet 中,定义的类型是 Map.Entry,但实际上存放的还是 HashMap$Node
// 这时因为 HashMap$Node implements Map.Entry 接口多态
//4. 当把 HashMap$Node 对象存放到 entrySet就方便我们的遍历,因为 Map.Entry 提供了重要方法
// getKey() getValue()
Set set = map.entrySet();
System.out.println(set.getClass());
for (Object obj : set) {
//System.out.println(obj.getClass()); //HashMap$Node
//为了从 HashMap$Node 取出k-v
//1. 先做一个向下转型
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey() + "-" + entry.getValue());
}
Set set1 = map.keySet();
System.out.println(set1.getClass());
Collection values = map.values();
System.out.println(values.getClass());
}
}
Map接口的常用方法:
- put:添加
- remove:根据键删除映射关系
- get:根据键获取值
- size:获取元素个数
- isEmpty:判断个数是否为0
- clear:清除
- containsKey:查找键是否存在
Map接口的遍历方法:
- keySet:获取所有的键
- values:获取所有的值
- entrySet:获取所有的键值对
package map_;
import java.util.*;
public class MapFor {
public static void main(String[] args) {
Map map = new HashMap();
map.put("No1","111");
map.put("No2","222");
map.put("No3","333");
map.put("No4","444");
map.put("No5","555");
//第一种:先取出所有key,通过key 取出对应value
Set keySet = map.keySet();
//(1) 增强for
System.out.println("------方式一------");
for (Object key : keySet) {
System.out.println(key + "-" + map.get(key));
}
//(2) 迭代器
System.out.println("------方式二------");
Iterator iterator = keySet.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
//第二种:直接取出value
Collection values = map.values();
//(1) 增强for
for (Object value : values) {
System.out.println(value);
}
//(2) 迭代器
Iterator iterator1 = values.iterator();
while (iterator1.hasNext()) {
Object value = iterator1.next();
System.out.println(value);
}
//第三种:通过EntrySet来获取
Set entrySet = map.entrySet();
//(1) 增强for
for (Object entry : entrySet) {
//将entry 转成 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey()+"-"+m.getValue());
}
//(2) 迭代器
Iterator iterator2 = entrySet.iterator();
while (iterator2.hasNext()) {
Object entry = iterator2.next();
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey()+"-"+m.getValue());
}
}
}
3.1 HashMap


源码分析:
无参构造
-
执行构造器 HashMap(),初始化加载因子 loadFactor = 0.75,HashMap$Node[] table=null

-
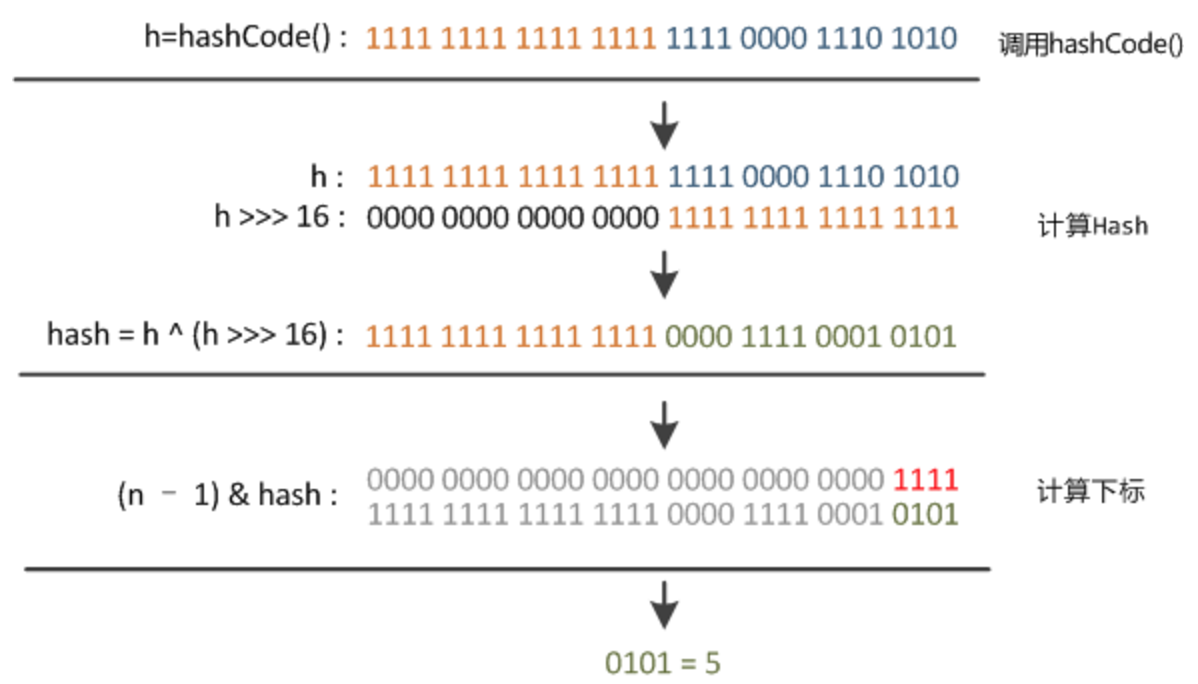
执行 put() 会调用 hash(),计算 key 的 hash值 (h = key.hashCode()) ^ (h >>> 16)

hash()

说明:HashMap中key的存储索引计算:首先根据key的值计算出hashcode的值,然后根据hashcode计算出hash值,最后通过hash&(length-1)计算得到存储的位置。
-
执行putVal()
简要流程如下:
- 首先根据 key 的值计算 hash 值,找到该元素在数组中存储的下标;
- 如果数组是空的,则调用 resize 进行初始化;
- 如果没有哈希冲突直接放在对应的数组下标里;
- 如果冲突了,且 key 已经存在,就覆盖掉 value;
- 如果冲突后,发现该节点是红黑树,就将这个节点挂在树上;
- 如果冲突后是链表,判断该链表是否大于 8 ,如果大于 8 并且数组容量小于 64,就进行扩容;如果链表节点大于 8 并且数组的容量大于 64,则将这个结构转换为红黑树;否则,链表插入键值对,若 key 存在,就覆盖掉 value。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; //辅助变量 //如果底层数组为null或者length==0,就扩容 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //取出hash值对应table索引位置的Node,如果为null, //直接把加入的k-v创建成Node加入该位置即可 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; //如果key的hash值相同,并且key是同一个对象或者key equals 为true,则不添加 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //如果当前table已有的Node是红黑树,就按照红黑树的方式处理 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); //如果table已有的Node是一条链表,就循环比较 else { for (int binCount = 0; ; ++binCount) { //死循环 //没有找到,就加到链表最后,break,进入++modCount if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); //如果整个链表元素超过8个,就树化 //即 添加第9个元素时树化 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st //treeifyBin并不是立刻树化,前提条件: //table大小要 > 64 //若不满足,会先进行扩容 treeifyBin(tab, hash); break; } //如果存在hash值相同,并且key为同一个对象或者equals为true, //直接break,替换值后直接返回结果 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; //替换对应的值 afterNodeAccess(e); return oldValue; } } ++modCount; //每增加一个Node,就modCount++,size++ //如果size大于临界值,就扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } -
扩容:HashMap 在容量超过负载因子所定义的容量之后,就会扩容。 HashMap 的大小扩大为原来数组的两倍,并将原来的对象放入新的数组中。
void resize(int newCapacity) { //传入新的容量 Entry[] oldTable = table; //引用扩容前的Entry数组 int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了 threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了 return; } Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组 transfer(newTable); //!!将数据转移到新的Entry数组里 table = newTable; //HashMap的table属性引用新的Entry数组 threshold = (int)(newCapacity * loadFactor);//修改阈值 }这里就是使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。
void transfer(Entry[] newTable) { Entry[] src = table; //src引用了旧的Entry数组 int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组 Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素 if (e != null) { src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象) do { Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置 e.next = newTable[i]; //标记[1] newTable[i] = e; //将元素放在数组上 e = next; //访问下一个Entry链上的元素 } while (e != null); } } }
有参构造
-
执行构造器
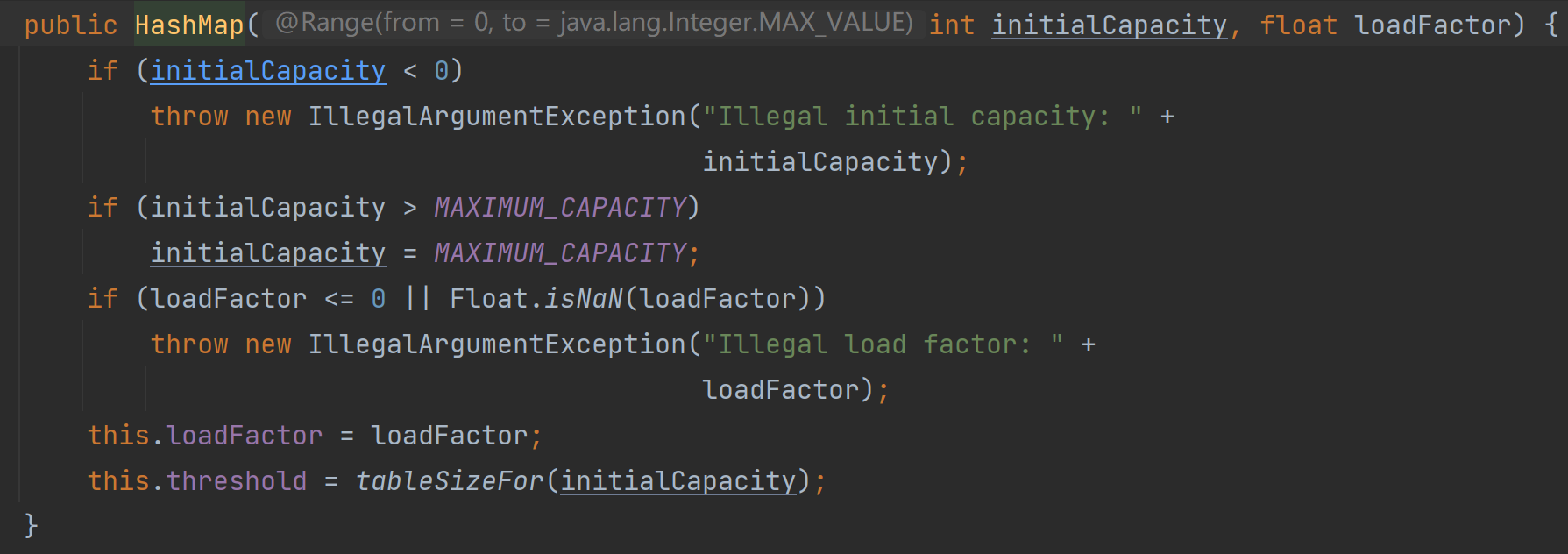
tableSizeFor(int cap)函数作用是使 cap 变为大于等于他的2幂次
n |= n >>>1作用:使n中为1的下一位变为1同理
n |= n >>>2使n中为1的下2位变为1...
最后 n 全部变为1,即00...11111111=2^8-1
返回 n + 1,即2^8
补充:HashMap为什么线程不安全
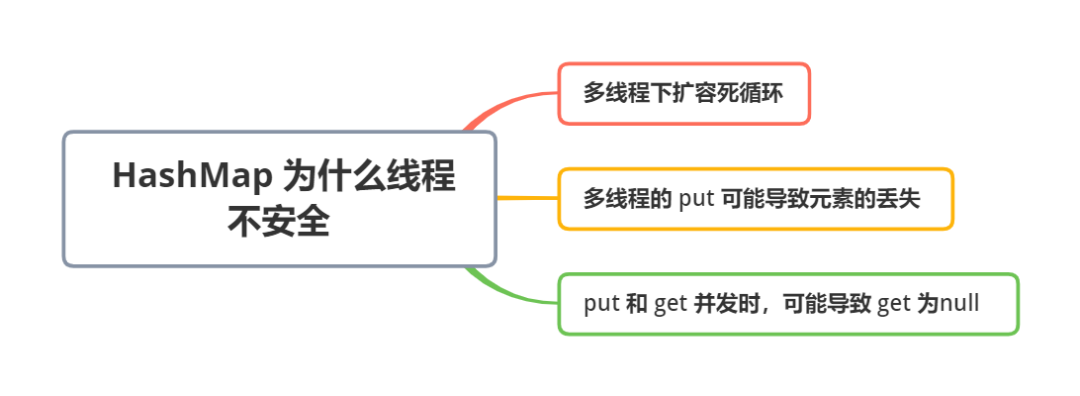
- 多线程下扩容死循环。JDK1.7中的 HashMap 使用头插法插入元素,在多线程的环境下,扩容的时候有可能导致环形链表的出现,形成死循环。因此,JDK1.8使用尾插法插入元素,在扩容时会保持链表元素原本的顺序,不会出现环形链表的问题。
- 多线程的put可能导致元素的丢失。多线程同时执行 put 操作,如果计算出来的索引位置是相同的,那会造成前一个 key 被后一个 key 覆盖,从而导致元素的丢失。此问题在JDK 1.7和 JDK 1.8 中都存在。
- put和get并发时,可能导致get为null。线程1执行put时,因为元素个数超出threshold而导致rehash,线程2此时执行get,有可能导致这个问题。此问题在JDK 1.7和 JDK 1.8 中都存在。
具体分析:面试官:HashMap 为什么线程不安全? (qq.com)
3.2 HashTable

- 底层有数组 Hashtable$Entry[] 初始化大小为11
- 临界值 threshold 8 = 11*0.75
- 扩容:newCapacity = (oldCapacity << 1)+1,即:capacity*2+1
HashMap 与 Hashtable 对比
-
部分对比

-
HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75
-
HashMap扩容时是当前容量翻倍即:capacity*2,Hashtable扩容时是容量翻倍+1即:capacity*2+1
-
两者计算hash的方法不同
-
Hashtable:使用key的hashcode对table数组的长度直接进行取模
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; -
HashMap:对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸
static final int hash(Object key) { int h; //二次hash return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; //对table数组长度取摸 if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { ... } ... }
-
3.3 Properties


3.4 ConcurrentHashMap
JDK1.8 中的ConcurrentHashMap 选择了与 HashMap 相同的数组+链表+红黑树结构;在锁的实现上,抛弃了原有的 Segment 分段锁,采用CAS + synchronized实现更加低粒度的锁。
-
put()方法执行逻辑:
大致可以分为以下步骤:
- 根据 key 计算出 hash值。
- 判断是否需要进行初始化。
- 定位到 Node,拿到首节点 f,判断首节点 f:
- 如果为 null ,则通过cas的方式尝试添加。
- 如果为
f.hash = MOVED = -1,说明其他线程在扩容,参与一起扩容。 - 如果都不满足 ,synchronized 锁住 f 节点,判断是链表还是红黑树,遍历插入。
- 当在链表长度达到8的时候,数组扩容或者将链表转换为红黑树。
-
get()方法:
get 方法不需要加锁。因为 Node 的元素 val 和指针 next 是用 volatile 修饰的,在多线程环境下线程A修改结点的val或者新增节点的时候是对线程B可见的。
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; //可以看到这些都用了volatile修饰 volatile V val; volatile Node<K,V> next; } -
ConcurrentHashMap 的并发度:在JDK1.7中,并发度默认是16,这个值可以在构造函数中设置。如果自己设置了并发度,ConcurrentHashMap 会使用大于等于该值的最小的2的幂指数作为实际并发度,也就是比如你设置的值是17,那么实际并发度是32。
4、Collections


HashMap面试小抄
1.存储结构
HashMap的底层数据结构是什么?
JDK1.7中,由 “数组+链表” 组成,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的。
JDK1.8中,由 “数组+链表+红黑树” 组成,
- 当链表超过 8 且数据总量超过 64 才会转红黑树。
- 将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,
为什么在解决 hash 冲突的时候,不直接用红黑树?而选择先用链表,再转红黑树?
因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡,而单链表不需要。当元素小于 8 个的时候,此时做查询操作,链表结构已经能保证查询性能。当元素大于 8 个的时候, 红黑树搜索时间复杂度是 O(logn),而链表是 O(n),此时需要红黑树来加快查询速度,但是新增节点的效率变慢了。
不用红黑树,用二叉查找树可以么?
可以。但是二叉查找树在特殊情况下会变成一条线性结构(这就跟原来使用链表结构一样了,造成很深的问题),遍历查找会非常慢。
为什么链表改为红黑树的阈值是 8?
当使用良好的哈希码时,树结构是很少使用到的,理想的情况下,在随机的哈希码下,节点在链表中出现的频率符合泊松分布,在数组调整阈值为 0.75 的时候,该泊松分布的平均参数约为 0.5,因为数组调整的阈值大小对平均参数有很大影响。如果忽略这个影响,列表长度 k 出现的次数按照泊松分布依次为:
0: 0.60653066;
1: 0.30326533;
2: 0.07581633;
3: 0.01263606;
4: 0.00157952;
5: 0.00015795;
6: 0.00001316;
7: 0.00000094;
8: 0.00000006;
更大:不足千万分之一
可以看到链表中元素个数为 8 时的概率已经非常小,再多的就更少了,所以原作者在选择链表元素个数时选择了 8,是根据概率统计而选择的。
默认加载因子是多少?为什么是 0.75,不是 0.6 或者 0.8 ?
在数组定义好长度之后,负载因子越大,所能容纳的键值对个数越多。
默认的loadFactor是0.75,0.75是对空间和时间效率的一个平衡选择,一般不要修改,除非在时间和空间比较特殊的情况下 :
- 如果内存空间很多而又对时间效率要求很高,可以降低负载因子Load factor的值 。
- 相反,如果内存空间紧张而对时间效率要求不高,可以增加负载因子loadFactor的值,这个值可以大于1。
2.索引计算
HashMap 中 key 的存储索引是怎么计算的?
首先根据key的值计算出hashcode的值,然后根据hashcode计算出hash值,最后通过hash&(length-1)计算得到存储的位置。看看源码的实现:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
/*
h = key.hashCode() 为第一步:取hashCode值
h ^ (h >>> 16) 为第二步:高位参与运算
*/
}
这里的 Hash 算法本质上就是三步:取key的 hashCode 值、根据 hashcode 计算出hash值、通过取模计算下标。
我们来看下详细过程,以JDK1.8为例,n为table的长度。

JDK1.8 为什么要 hashcode 异或其右移十六位的值?
这么做可以在数组 table 的 length 比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
为什么 hash 值要与length-1相与?
- 把 hash 值对数组长度取模运算,模运算的消耗很大,没有位运算快。
- 当 length 总是等于 2 的n次方时,h& (length-1) 运算等价于对length取模,也就是 h%length,但是 & 比 % 具有更高的效率。
HashMap数组的长度为什么是 2 的幂次方?
这样做效果上等同于取模,在速度、效率上比直接取模要快得多。除此之外,2 的 N 次幂有助于减少碰撞的几率。如果 length 为2的幂次方,则 length-1 转化为二进制必定是11111……的形式,在与h的二进制与操作效率会非常的快,而且空间不浪费。例如:
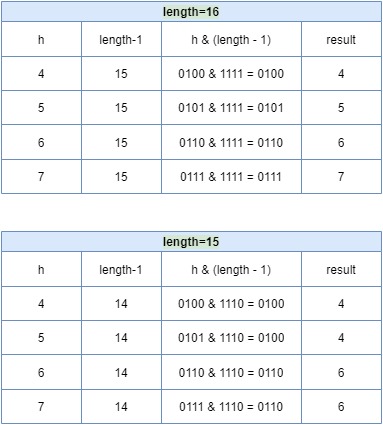
当 length =15时,6 和 7 的结果一样,这样表示他们在 table 存储的位置是相同的,也就是产生了碰撞,6、7就会在一个位置形成链表,4和5的结果也是一样,这样就会导致查询速度降低。
3.put方法
简要流程如下:
- 首先根据 key 的值计算 hash 值,找到该元素在数组中存储的下标;
- 如果数组是空的,则调用 resize 进行初始化;
- 如果没有哈希冲突直接放在对应的数组下标里;
- 如果冲突了,且 key 已经存在,就覆盖掉 value;
- 如果冲突后,发现该节点是红黑树,就将这个节点挂在树上;
- 如果冲突后是链表,判断该链表是否大于 8 ,如果大于 8 并且数组容量小于 64,就进行扩容;如果链表节点大于 8 并且数组的容量大于 64,则将这个结构转换为红黑树;否则,链表插入键值对,若 key 存在,就覆盖掉 value。
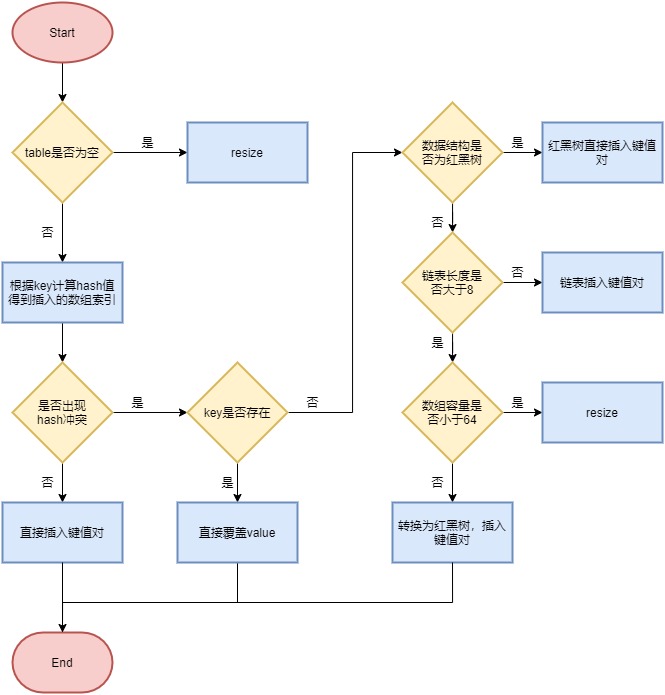
JDK1.7 和1.8 的put方法区别是什么?
区别在两处:
-
解决哈希冲突时,JDK1.7 只使用链表,JDK1.8 使用链表+红黑树,当满足一定条件,链表会转换为红黑树。
-
链表插入元素时,JDK1.7 使用头插法插入元素,在多线程的环境下有可能导致环形链表的出现,扩容的时候会导致死循环。因此,JDK1.8使用尾插法插入元素,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了,但JDK1.8 的 HashMap 仍然是线程不安全的,具体原因会在另一篇文章分析。
4.扩容机制
HashMap 的扩容方式?
Hashmap 在容量超过负载因子所定义的容量之后,就会扩容。方法是将 Hashmap 的大小扩大为原来数组的两倍,并将原来的对象放入新的数组中。
JDK1.8做了两处优化:
-
resize 之后,元素的位置在原来的位置,或者原来的位置 +oldCap (原来哈希表的长度)。如下图所示:
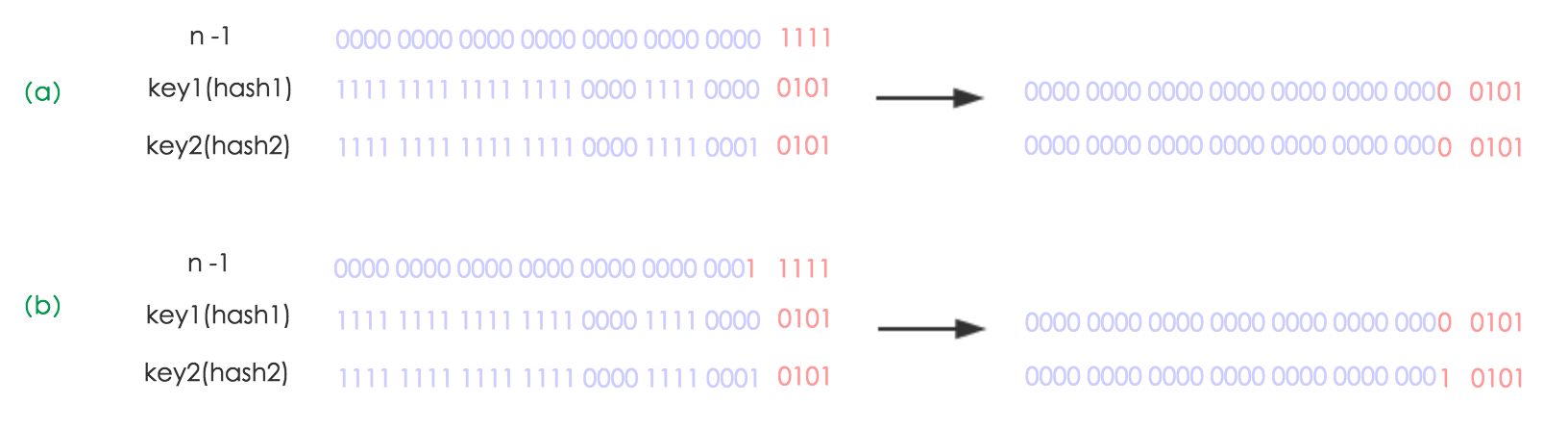
元素在重新计算 hash 之后,因为 n 变为 2倍,那么 n-1 的 mask 范围在高位多 1 bit(红色),因此新的index就会发生这样的变化:

-
JDK1.7 中 rehash 的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置(头插法)。JDK1.8 不会倒置,使用尾插法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号