
心灵毒鸡汤:志在山顶的人,就不要留恋沿途的风景。
废话不多说,我们开始分析:
再我们面试的时候,问到Redis经常就会问到redis的三大问题:缓存雪崩、缓存穿透、缓存击穿三者有何区别以及如何再开发中处理和避免此问题,我面试过某些应聘者得到的回答总是不全面或者混淆的,下面就跟着这篇文章大家一起学习总结下,请看以下分析内容。
缓存雪崩:
缓存雪崩是因为缓存失效导致数据未加载到内存中,或者缓存时间大面积地失效,从而导致所有请求都会去查数据库,导致数据库、CPU和内存负载过高,甚至宕机。(官方解释)
雪崩案例:微博,每日都是数以亿计的用户再查看微博信息和评论等,为了减轻数据库压力,肯定会把这些评论等信息存入到缓存服务中,试想一下,如果微博的缓存服务突然宕机或者缓存的信息突然大面积失效,那么会造成什么?缓存服务查不到数据就会去数据库查询数据,那么效率低暂且不提,如果每秒数以万计甚至更大的请求直接请求数据库,会造成什么?会造成数据负载过高,甚至会导致宕机问题产生。这就是缓存雪崩。(当然微博肯定做了各种措施应对,这里只是举个例子)。
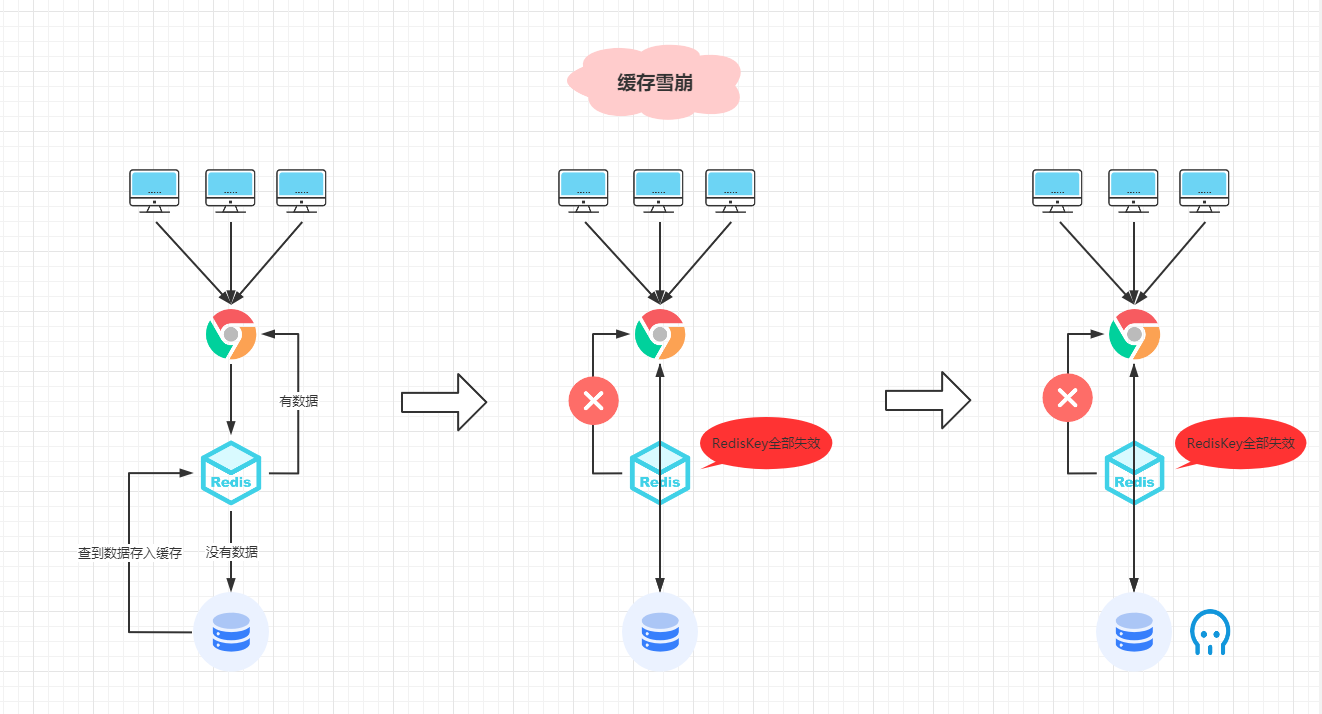
请看下面这张图:
左边:流程图是正常先查缓存如果没有数据再查DB库请求情况。
中间:为缓存大面积导致查询缓存查不到信息时候的请求情况。
右边:为直接请求数据库导致压力过大,数据库服务宕机情况。
解决方案:
- 缓存标记:记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际key的缓存;
- 缓存数据:它的过期时间比缓存标记的时间延长1倍,例:标记缓存时间30分钟,数据缓存设置为60分钟。这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用端,直到另外的线程在后台更新完成后,才会返回新缓存。
- 使用锁或队列(加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着的,这是过来300个请求299个都在阻塞的。同样会导致用户等待超时,这是个治标不治本的方法!)
- 双缓存方案:主缓存:有效期按照经验值设置,主要读取的缓存,主缓存失效后从数据库加载最新值。 备份缓存:有效期长,获取锁失败时读取的缓存,主缓存更新时需要同步更新备份缓存。其实就是缓存降级策略。
缓存穿透:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,我们数据库的 id 都是1开始自增上去的,如发起为id值为 -1 的数据或 id 为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大,严重会击垮数据库。
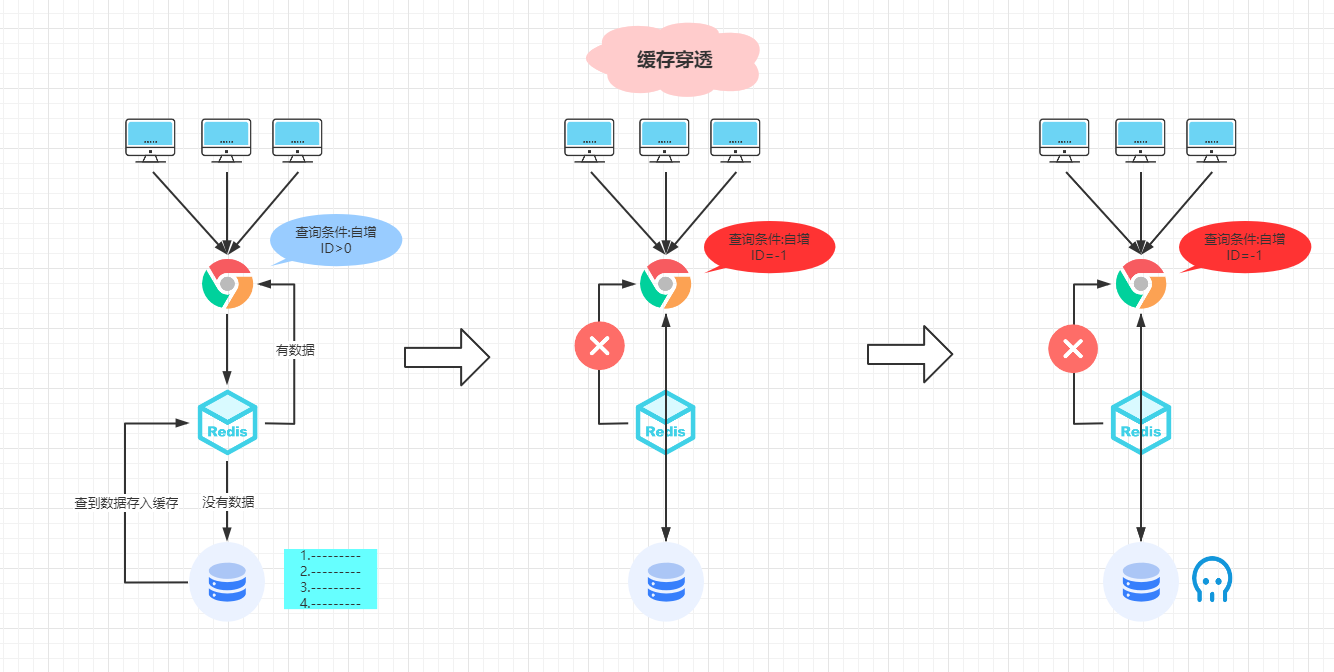
请看下面这张图:
左边:正常查询id>0的数据,先查询缓存数据,有就返回,没有再查数据库返回,然后把数据再放入缓存中。
中间:黑客攻击故意查询id<0的数据,这时候缓存肯定没有此数据,就会查询数据库,但是数据库也没有数据,就无法把查到的数据放到缓存,下次查询还是得请求数据库。
右边:假如黑客故意攻击系统,每秒以5000次得频率一直请求查询id<0的数据,由于没做处理,每次请求就都会请求数据库,这样QPS很很大,数据库承受不了那么大的请求压力,就会造成宕机等问题出现。
解决方案:
- 布隆过滤器:采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
- 空数据缓存:如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。(简单暴力)
- 接口校验:例如用户鉴权校验、入参校验等等。
缓存击穿:
一个热点数据缓存过期了,但是突然在这个时候恰好接受到了大量查询这个缓存的请求,然后大量请求去查询数据库。造成数据库压力很大,甚至出现宕机等情况。
案例分析:年前,某东飞天茅台1499一瓶每日10:00抢购活动非常火爆,那么试想以下,假如某天09:59:59此商品缓存信息失效了,那么同一瞬间那么多的访问会直接请求数据库,那么数据库面对那么大的QPS会怎样?可想而知,会出问题的。
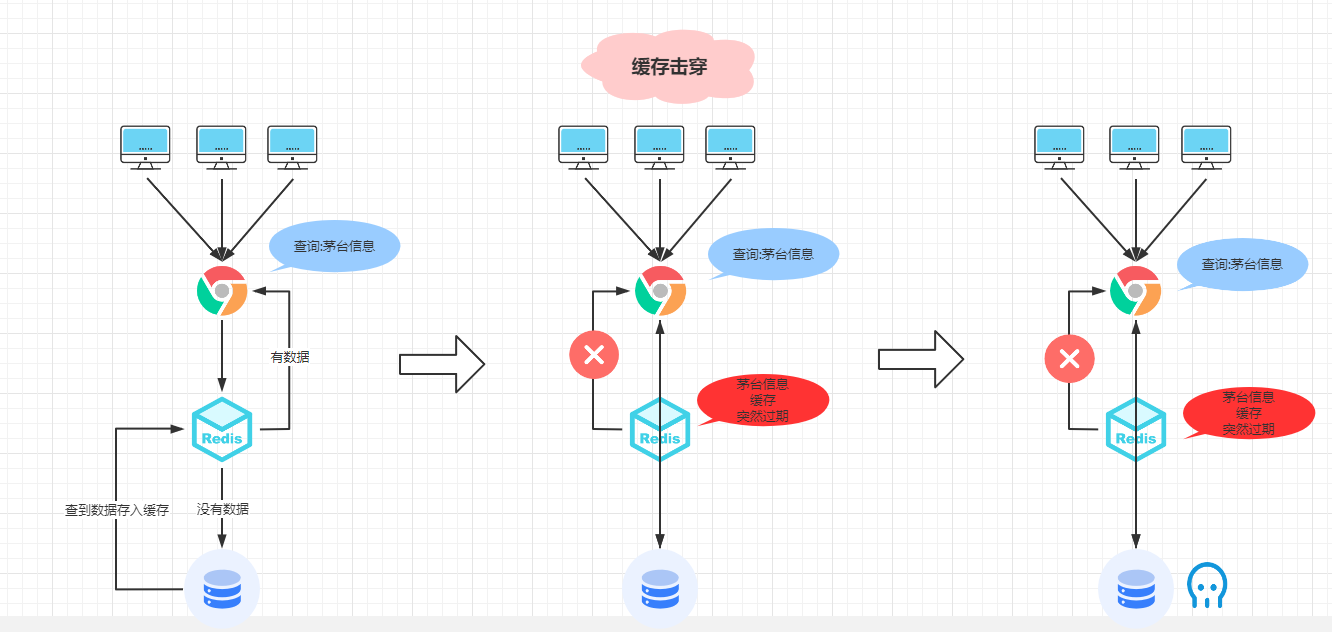
请看以下图片:
左边:正常访问茅台抢购信息,先查询缓存数据,有就返回,没有再查数据库返回,然后把数据再放入缓存中(没问题,正常流程)。
中间:9:59:59缓存的茅台抢购信息失效了,这时候去查缓存肯定没有此数据,就会查询数据库,数据库有数据,会将查到的数据放到缓存,用于下次查询使用。
右边:单个访问数据库可以顶得住,但是这是茅台抢购,每秒的访问数亿计,QPS那么大,数据库服务再这一瞬间无法支撑那么大的请求,瞬间就把数据库击垮了,然后宕机了。
解决方案:
- 热点数据永不过期:可以将热点数据设置为永远不过期;
- 互斥锁:基于 redis or zookeeper 实现互斥锁,等待第一个请求构建完缓存之后,再释放锁,进而其它请求才能通过该 key 访问数据。
总结:
经过以上的介绍,Redis的雪崩,击穿,穿透,三者其实都差不多,但是又有一些小的区别,在面试缓存中必问的,千万不要把三者搞混了,因为缓存雪崩、穿透和击穿,是缓存面临的最大的问题,要么不出现,一旦出现就是致命性的问题,所以面试官一定会问你。如果你没有答出来或者答得很模糊,其实是很掉分的。
大家一定要结合实际,思考产生的原因,以及如何避免产生此问题,发生了如何解决此问题,如果你答得很有条理,那么作为面试官就会对你有一个不错的印象,那么离offer也就越近,切记死记硬背,招聘是解决问题处理问题的,单单死记硬背不可取。
技术总结:(此处借鉴)
一般避免以上情况发生我们从三个时间段去分析下:
-
事前:
Redis高可用,主从+哨兵,Redis cluster,避免全盘崩溃。 -
事中:本地
ehcache缓存 +Hystrix限流+降级,避免MySQL被打死。 -
事后:
Redis持久化RDB+AOF,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
限流组件,可以设置每秒的请求,有多少能通过组件,剩余的未通过的请求,怎么办?走降级!可以返回一些默认的值,或者友情提示,或者空白的值。
好处:
数据库绝对不会死,限流组件确保了每秒只有多少个请求能通过。 只要数据库不死,就是说,对用户来说,3/5 的请求都是可以被处理的。 只要有 3/5 的请求可以被处理,就意味着你的系统没死,对用户来说,可能就是点击几次刷不出来页面,但是多点几次,就可以刷出来一次。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号