MySql索引
主键索引
非主键索引
回表与覆盖索引
索引维护
页分裂与页合并
主键的选择
最左前缀匹配原则
最左前缀
匹配原则
匹配原因解释
索引内字段顺序
索引下推
索引的使用
使用不到索引的情况
不推荐使用索引的情况
参考资料
innoDB索引模型
InnoDB 使用 B+树作为索引模型,数据存储在B+树中,每一个索引对应一颗B+树。
主键索引
也叫聚簇索引(clustered index),其叶子节点存储内容为对应整行数据,因此**使用主键索引,可直接查询到对应数据*
非主键索引
也叫二级索引(secondary index),其叶子节点存储内容为主键的值
回表与覆盖索引
回表:由于非主键索引的叶子节点没有直接存储行数据,因此需要再根据叶子节点的主键值,再到主键索引中去搜索行数据
覆盖索引:查询内容在非主键索引树上的节点中:
- 查询内容只有主键:主键是非主键索引的叶子节点,不用回表
- 查询内容与条件构成了联合索引:构成联合索引后,索引列会在索引的节点中,从节点中可直接得到数据,也不用回表
如有列a b c d e,其中a为主键,构建了联合索引 index_bcd(b, c, d),当where中使用b去查询主键a时,或使用符合最左前缀原则方式查询bcd时,均是利用覆盖索引
索引维护
页分裂与页合并
页分裂
行数据存储在数据页中,页中的行数据以主键顺序排列,当插入的数据的主键不是递增,并且目标插入页与后一页都满了时,会触发页分裂,
innoDB会创建一个新数据页,移动目标插入页的部分数据到新数据页,最后重新定义页之间的关系
页分裂也影响插入的性能,同时降低了页空间利用率
页合并
被删除的行被标记为删除(标记为删除的空间可被新插入行数据使用),而不是物理删除,当被标记为删除的行达到页空间的50%时(利用率50%以下),innoDB会尝试寻找利用率小于50%的相邻页来合并
主键的选择
使用自增主键:
- 考虑性能:避免页分裂导致写数据的性能下降
- 考虑空间占用 :主键是非主键索引的叶子节点,主键越短,普通索引占用空间越少
最左前缀匹配原则
最左前缀
最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
- 如有列a b c d e,其中a为主键,当有联合索引index_bcd(b, c, d)时,where中的字段b一定需要在最左(不被优化时),才能使用到联合索引
- 如有列name age, 联合索引index_name_age(name, age), where中模糊查询 like 'a%'一样可以使用到联合索引(a是匹配的最左M个字符),like '%a'将不能使用到索引
匹配原则
以最左边为起点开始向右依次匹配,直到遇到范围查询(>、<、between、like)停止匹配,其后字段无法使用索引
有联合索引index_abcd(a, b, c, d)(相当于有索引index_a、index_ab、index_abc、index_abcd)
- 当where条件为a = 1 and b = 2 and c > 3 and d = 4时,d使用不到索引
- 当where条件为b = 2 and c = 3时,不符合最左前缀匹配原则,使用不到索引
- 当where条件使用为in与=,且是全字段匹配时,字段abcd顺序可以任意,查询优化器会进行优化,如a = 1 and b = 2 and c = 3 and d = 4与b = 2 and c = 3 and a = 1 and d = 4一样,均可使用到索引
- 当where条件为a = 1 and c = 3时,不是依次匹配,a可以使用索引,c无法使用到索引
- 当where条件为a < 10 and b = 2时,a可以使用索引,b无法使用
匹配原因解释
联合索引也是由B+树构成, 联合索引树节点存储的是多个字段值,由于一颗B+树只能根据一个值来构建索引关系,因此根据最左字段来构建。
如创建一个(a,b)的联合索引:
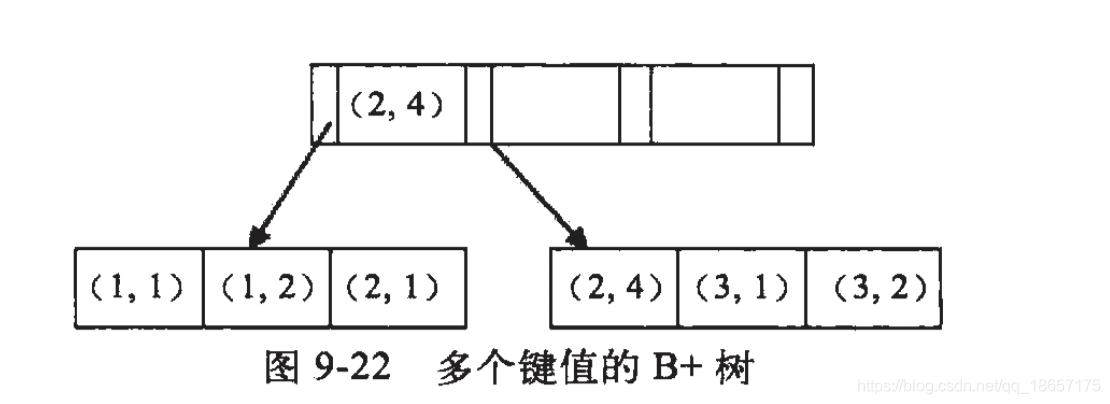
- 其中a的值是有序的 1, 1, 2, 3, 3,b的值是无序的1, 2, 1, 4, 1, 2,所以where中条件为b=2这种条件无法使用到索引
- 在a等值的情况下,b的值又是按顺序排列的,这是一种相对a的有序,当a的取值时一个范围时,范围内的b是无序的,所以匹配时遇到范围查询就会停止,后续字段无法使用到索引
例如a = 1 and b = 2 a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1 and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。
mysql创建复合索引的规则是首先对复合索引最左边的字段的数据进行排序,在此基础上,再对后面的字段进行排序,这样第一个字段是绝对有序的,后面的字段就是无序的了,一般情况下第二个字段进行条件判断是用不到索引的,可能出现type是index类型的,这就是mysql最左前缀的原因。
索引内字段顺序
- 频率使用高的字段放在前面
- 更长的字段放在前面,避免查询条件变化需新构建索引时,新索引占用更多空间
- 区分度高的字段放前面,可能有较少符合条件的数据,减少后续扫描成本,提高性能
索引下推
在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
索引的使用
使用不到索引的情况
- where条件中使用了or分割字段,并且被分割字段中含非索引字段
想用索引就需要为or连接的所有字段加独立索引 - where条件不满足最左匹配原则(非联合索引的最左 N 个字段,或非字符串索引的最左 M 个字符)
- where条件中索引字段存在数据类型隐式转换
- where条件中对索引字段进行数学运算
- where条件中对索引字段使用函数
- where条件内in操作的字段太多
最好是在代码里分批查,每次in较少字段 - where条件内使用了不等于!=或<>
- mysql认为使用全表扫描要比使用索引快
如数据量较小时
不推荐使用索引的情况
- 数据区分度低(一个字段的取值只有几种时)的字段不要使用索引
- 频繁更新的字段不要使用索引
参考资料
MySQL实战45讲
InnoDB中的页合并与分裂
深入浅出最左匹配原则
面试中常被提到的最左前缀匹配原则
mysql联合索引的B+树到底张什么样子‘

 浙公网安备 33010602011771号
浙公网安备 33010602011771号