
数据采集与融合技术实验课程作业三
数据采集与融合技术实验课程作业三
任务①:
主要代码
## image_spider.py
class ImageSpider(scrapy.Spider):
name = "image_spider"
allowed_domains = ["weather.com.cn"]
start_urls = ["http://www.weather.com.cn"]
def parse(self, response):
# Find all image URLs on the page
img_urls = response.css('img::attr(src)').getall()
img_urls = [response.urljoin(url) for url in img_urls] # Handle relative URLs
# Print image URLs in console
for img_url in img_urls:
self.log(f"Image URL: {img_url}")
# Yield image requests
for img_url in img_urls:
yield scrapy.Request(img_url, callback=self.save_image)
def save_image(self, response):
# Save each image in 'images' folder
path = 'images'
os.makedirs(path, exist_ok=True)
filename = os.path.join(path, response.url.split('/')[-1])
with open(filename, 'wb') as f:
f.write(response.body)
self.log(f"Saved file {filename}")
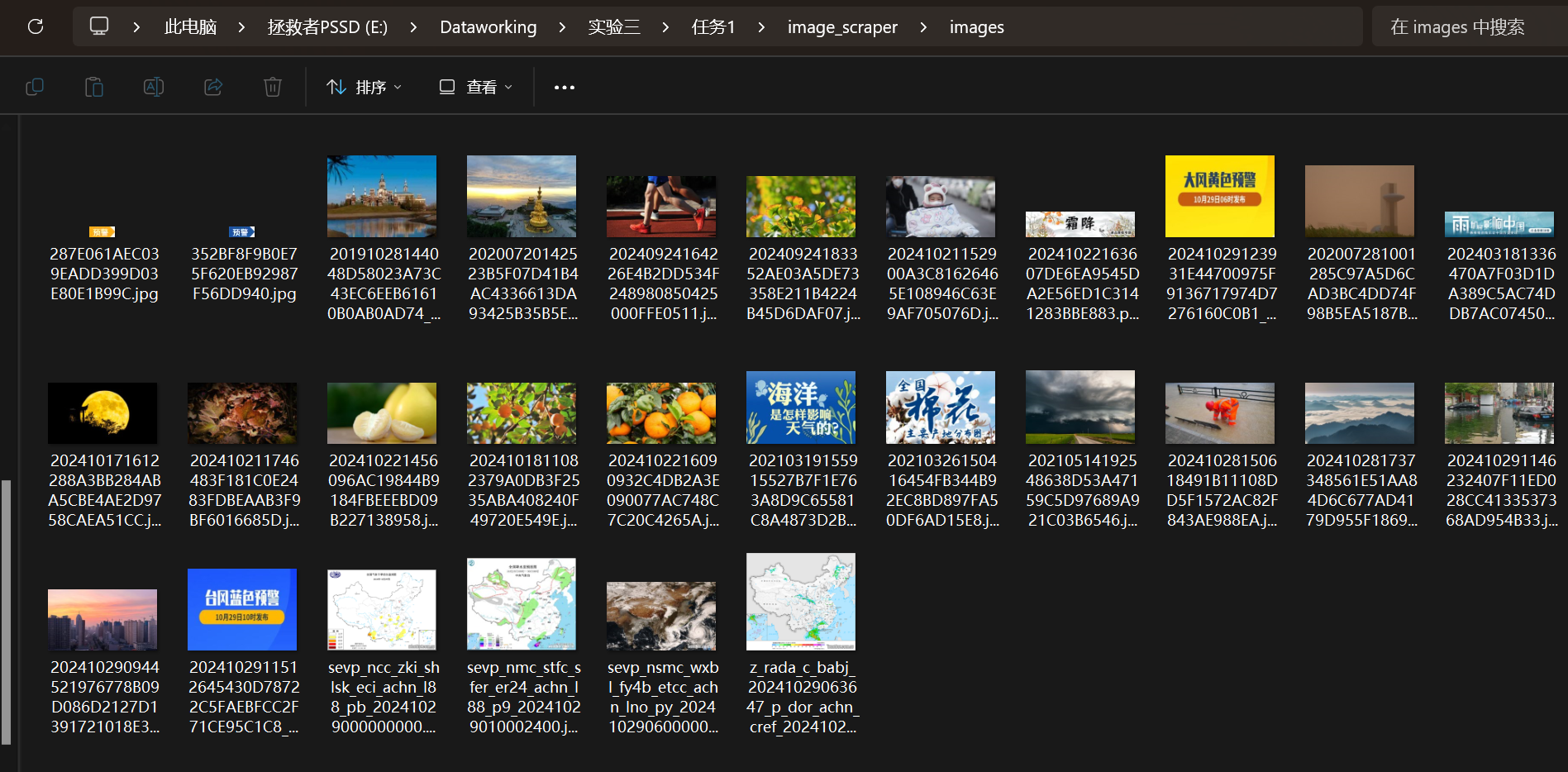
运行后查看抓取的图片
作业心得
-
- Scrapy 框架的强大功能
Scrapy 是一个功能强大的网页抓取框架,它提供了许多方便的工具和方法来处理网页抓取任务。在这个项目中,我使用 Scrapy 来抓取天气网站上的所有图片,并将它们保存到本地。Scrapy 的 Spider 类和 Request 对象使得抓取和处理网页内容变得非常简单和直观。
- Scrapy 框架的强大功能
-
- 使用 CSS 选择器提取数据
在 parse 方法中,我使用了 CSS 选择器来提取页面上的所有图片 URL。CSS 选择器是一种非常强大的工具,它允许我们轻松地选择和提取网页中的特定元素。在这个项目中,我使用 response.css('img::attr(src)').getall() 来获取所有图片的 URL。
- 使用 CSS 选择器提取数据
-
- 处理相对 URL
在抓取网页内容时,经常会遇到相对 URL。为了确保我们能够正确地访问这些资源,我使用了 response.urljoin(url) 方法将相对 URL 转换为绝对 URL。这是一个非常重要的步骤,因为它确保了我们能够正确地下载和保存所有图片。
- 处理相对 URL
任务②:
主要代码
# stock_spider.py
def parse(self, response):
# 提取 JSON 数据
data = json.loads(response.text[response.text.find('(') + 1 : response.text.rfind(')')]) # 去除 JSONP 包裹
for stock in data['data']['diff']:
item = StockScraperItem()
item['id'] = stock['f12']
item['code'] = stock['f12']
item['name'] = stock['f14']
item['latest_price'] = stock['f2']
item['price_change_percentage'] = stock['f3']
item['price_change'] = stock['f4']
item['volume'] = stock['f5']
item['turnover'] = stock['f6']
item['amplitude'] = stock['f7']
item['high'] = stock['f15']
item['low'] = stock['f16']
item['today_open'] = stock['f17']
item['yesterday_close'] = stock['f18']
yield item
# pipelines.py
def process_item(self, item, spider):
# 插入数据
self.cursor.execute("""
INSERT INTO stock_data (id, code, name, latest_price, price_change_percentage, price_change, volume, turnover, amplitude, high, low, today_open, yesterday_close)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
latest_price=VALUES(latest_price),
price_change_percentage=VALUES(price_change_percentage),
price_change=VALUES(price_change),
volume=VALUES(volume),
turnover=VALUES(turnover),
amplitude=VALUES(amplitude),
high=VALUES(high),
low=VALUES(low),
today_open=VALUES(today_open),
yesterday_close=VALUES(yesterday_close)
""", (
item['id'],
item['code'],
item['name'],
item['latest_price'],
item['price_change_percentage'],
item['price_change'],
item['volume'],
item['turnover'],
item['amplitude'],
item['high'],
item['low'],
item['today_open'],
item['yesterday_close']
))
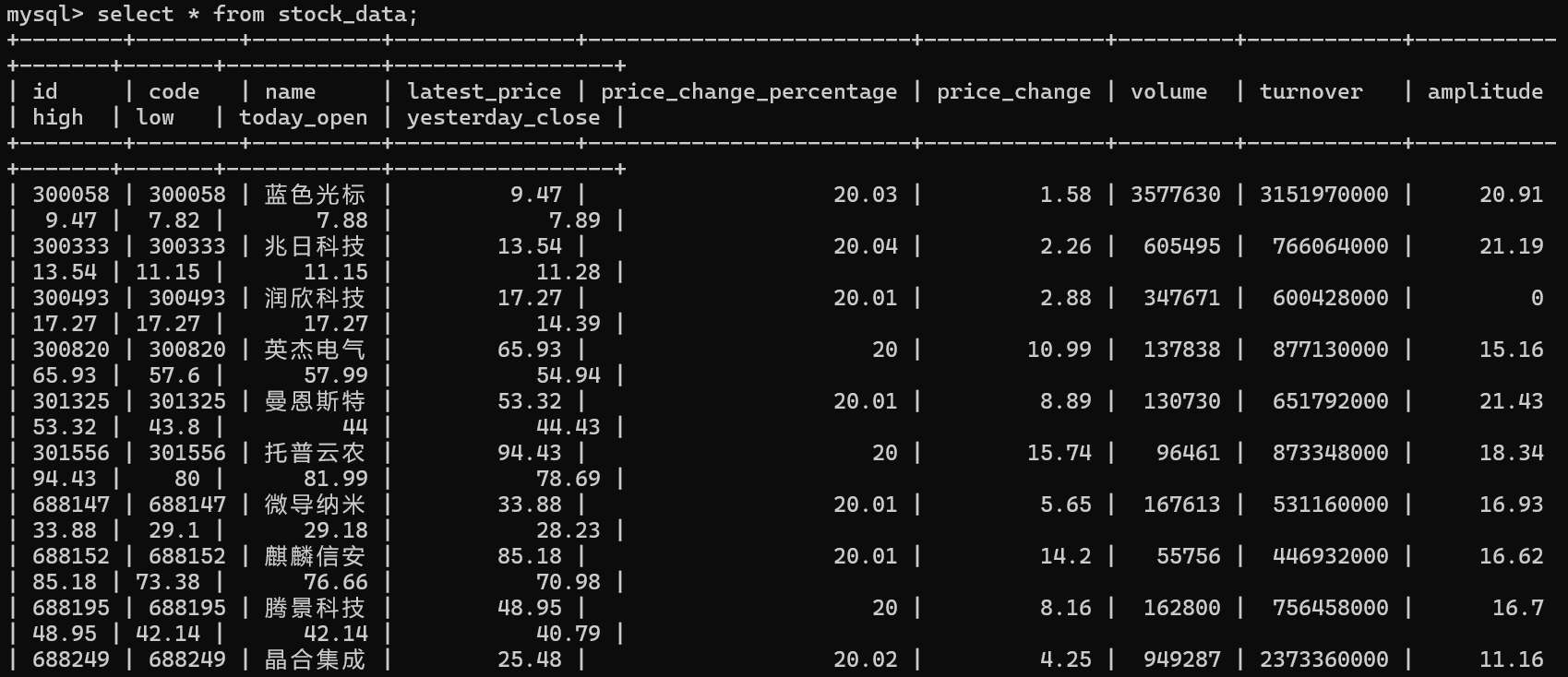
运行查看MySQL中查看股票数据
作业心得
-
- 处理 JSON 数据
在 StockSpider 爬虫中,我需要从 API 响应中提取 JSON 数据。通过使用 Python 的 json 模块,我能够轻松地解析 JSON 数据,并提取所需的字段。在这个项目中,我使用 json.loads 方法解析 JSON 数据,并使用字典访问提取到的数据。
- 处理 JSON 数据
-
- 使用 Scrapy Item
为了更好地组织和管理抓取到的数据,我使用了 Scrapy 的 Item 类。在 StockScraperItem 中定义了各个字段,并在爬虫中将提取到的数据赋值给这些字段。这种方法不仅使代码更加清晰,还能确保数据的一致性和完整性。
- 使用 Scrapy Item
-
- 数据存储到 MySQL
在 StockScraperPipeline 中,我使用了 mysql.connector 模块将抓取到的数据存储到 MySQL 数据库中。通过在 open_spider 方法中建立数据库连接,并在 close_spider 方法中关闭连接,我确保了数据库连接的正确管理。在 process_item 方法中,我使用 SQL 语句将数据插入到数据库中,并使用 ON DUPLICATE KEY UPDATE 语句处理重复数据。
- 数据存储到 MySQL
任务③:
主要代码
# work3.py
def parse(self, response):
data = response.body.decode()
selector=scrapy.Selector(text=data)
data_lists = selector.xpath('//table[@align="left"]/tr')
for data_list in data_lists:
datas = data_list.xpath('.//td')
if datas != []:
item = work3_Item()
keys = ['name','price1','price2','price3','price4','price5','date']
str_lists = datas.extract()
for i in range(len(str_lists)-1):
item[keys[i]] = str_lists[i].strip('<td class="pjrq"></td>').strip()
yield item
# pipelines.py
class work3_Pipeline:
def open_spider(self,spider):
try:
self.db = pymysql.connect(host='127.0.0.1', user='root', passwd='wq1233', port=3306,charset='utf8',database='forex')
self.cursor = self.db.cursor()
self.cursor.execute('DROP TABLE IF EXISTS bank')
sql = """CREATE TABLE bank(Currency varchar(32),p1 varchar(17),p2 varchar(17),p3 varchar(17),p4 varchar(17),p5 varchar(17),Time varchar(32))"""
self.cursor.execute(sql)
except Exception as e:
print(e)
def process_item(self, item, spider):
if isinstance(item,work3_Item):
sql = 'INSERT INTO bank VALUES ("%s","%s","%s","%s","%s","%s","%s")' % (item['name'],item['price1'],item['price2'],
item['price3'],item['price4'],item['price5'],item['date'])
self.cursor.execute(sql)
self.db.commit()
return item
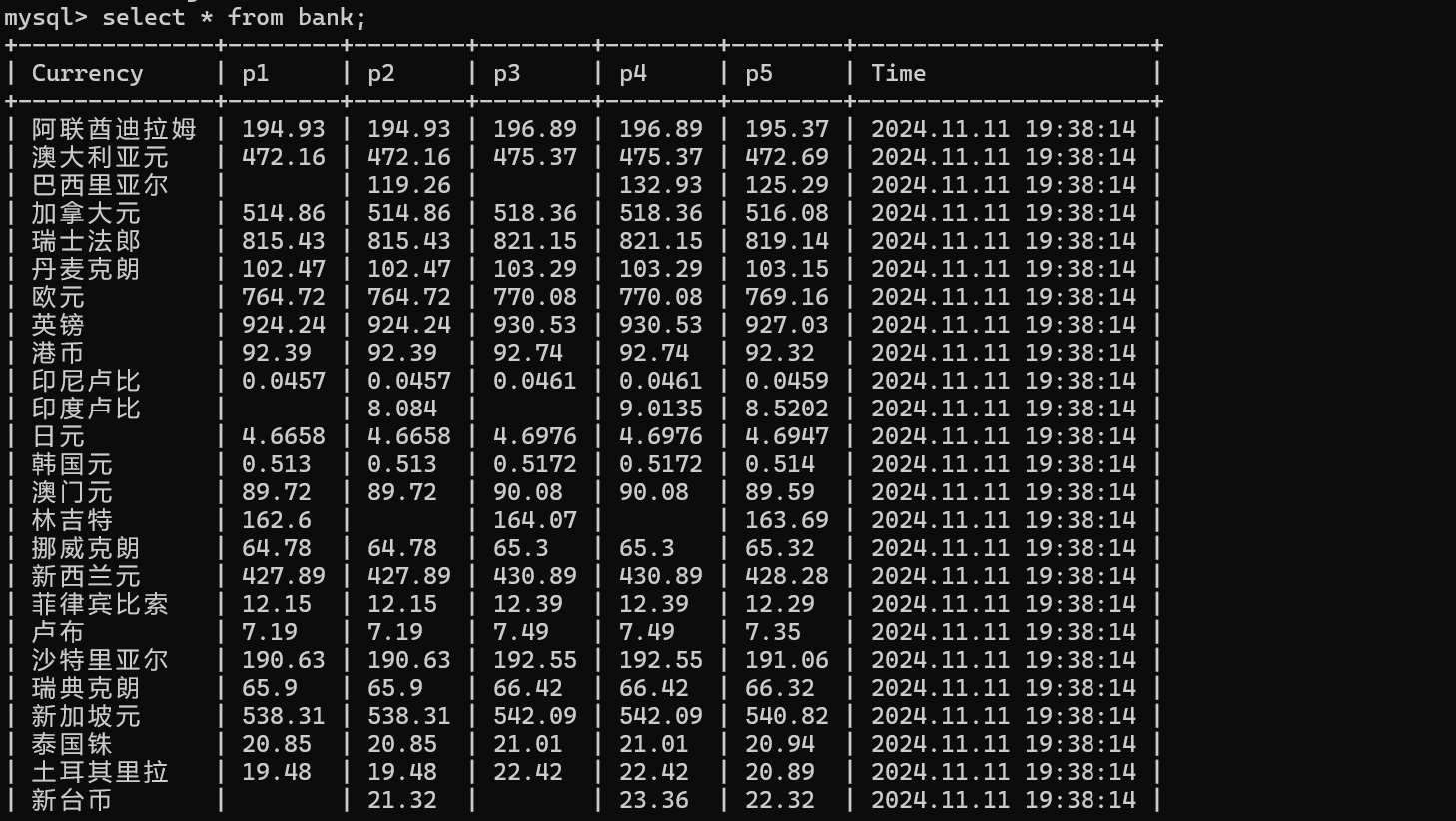
运行查看MySQL查看外汇数据
作业心得
-
- 使用 XPath 提取数据
在 Work3Spider 爬虫中,我使用了 XPath 表达式来提取网页中的数据。XPath 是一种非常强大的工具,它允许我们轻松地选择和提取网页中的特定元素。在这个项目中,我使用 selector.xpath('//table[@align="left"]/tr') 来获取所有数据行,并进一步提取每行中的各个数据单元格。
- 使用 XPath 提取数据
-
- 使用 Scrapy Item
为了更好地组织和管理抓取到的数据,我使用了 Scrapy 的 Item 类。在 work3_Item 中定义了各个字段,并在爬虫中将提取到的数据赋值给这些字段。这种方法不仅使代码更加清晰,还能确保数据的一致性和完整性。
- 使用 Scrapy Item

 浙公网安备 33010602011771号
浙公网安备 33010602011771号