中文医学知识图谱爬取(二)
使用上一次的爬取结果对更加详细的信息进行爬取,最终目的是获取类似下图的数据
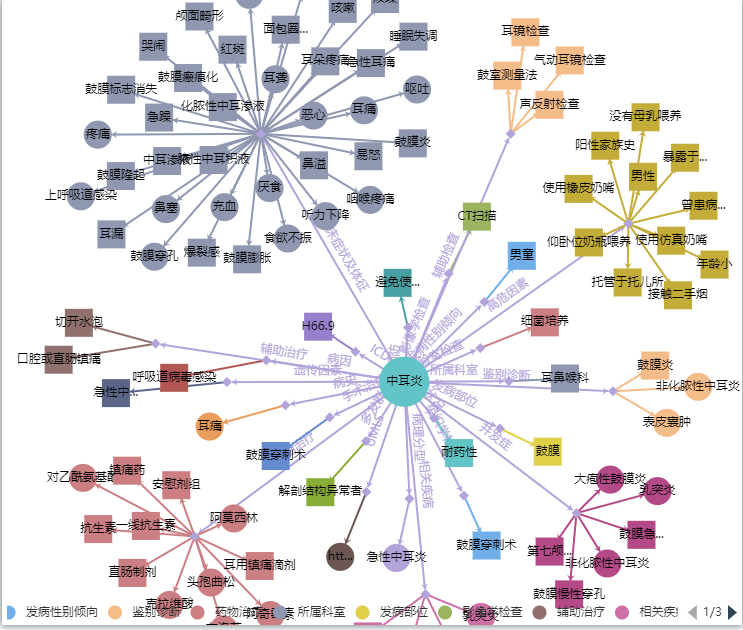
使用上次得到的疾病名称、药物、症状、诊疗等更加详细的信息
import scrapy
import json
from dieasekg.items import DieasekgItem
class DkgSpider(scrapy.Spider):
name = 'dkg'
allowed_domains = ['http://cmekg.pcl.ac.cn/']
def start_requests(self):
with open('F:\\Users\\Kun\\PycharmProjects\\cmekg\\cme\\disease_list.json', 'r', encoding='utf-8') as fp:
json_data = json.load(fp)
for i in range(119, len(json_data)):
# print(json_data[i]['name'])
u = 'https://zstp.pcl.ac.cn:8002/knowledge?name={0}'.format(json_data[i]['name'])
# print(u)
yield scrapy.Request(url=u)
def parse(self, response):
item = DieasekgItem()
data = json.loads(response.text)
# print(data['categories'])
# data['name'] 疾病名称
item['name'] = data['name']
# data['categories'] 类别
item['categories'] = data['categories']
# data['link'] 连线
item['link'] = data['link']
# data['node'] 点
item['node'] = data['node']
yield item
最终的数据:

其中重要的是link和node信息,后期用来构建其间的关系(十分重要)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号