4 种策略让 MySQL 和 Redis 数据保持一致
缓存更新的几种设计
-
先删除缓存,再更新数据库(这种方法在并发下最容易出现长时间的脏数据,不可取)
-
先更新数据库,删除缓存(Cache Aside Pattern)
-
只更新缓存,由缓存自己同步更新数据库(Read/Write Through Pattern)
-
只更新缓存,由缓存自己异步更新数据库(Write Behind Cache Pattern)
(1)先删除缓存,再更新数据库
这种方法在并发读写的情况下容易出现缓存不一致的问题

其可能的执行流程顺序为:
-
客户端1 触发更新数据A的逻辑
-
客户端2 触发查询数据A的逻辑
-
客户端1 删除缓存中数据A
-
客户端2 查询缓存中数据A,未命中
-
客户端2 从数据库查询数据A,并更新到缓存中
-
客户端1 更新数据库中数据A
最后缓存中的数据 A 跟数据库中的数据 A 是不一致的,缓存中的数据A是旧的脏数据。
(2)先更新数据库,再让缓存失效
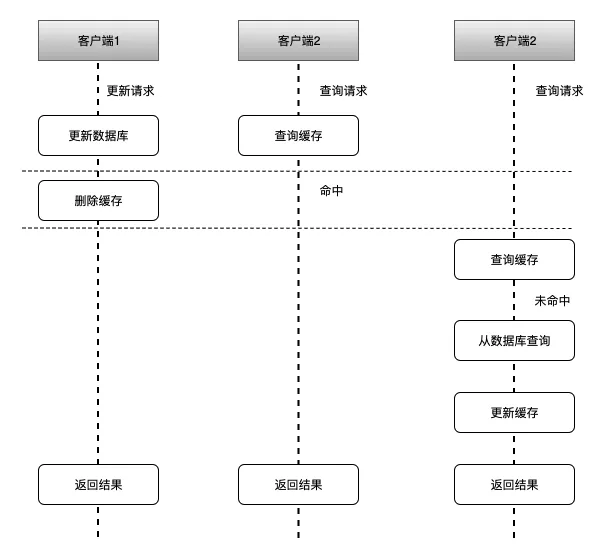
执行的流程顺序为:
-
客户端1 触发更新数据A的逻辑
-
客户端2 触发查询数据A的逻辑
-
客户端3 触发查询数据A的逻辑
-
客户端1 更新数据库中数据A
-
客户端2 查询缓存中数据A,命中返回(旧数据)
-
客户端1 让缓存中数据A失效
-
客户端3 查询缓存中数据A,未命中
-
客户端3 查询数据库中数据A,并更新到缓存中
最后缓存中的数据A和数据库中的数据 A 是一致的,理论上可能会出现一小段时间数据不一致,不过这种概率也比较低
(3)只更新缓存,由缓存自己同步更新数据库(Read/Write Through Pattern)
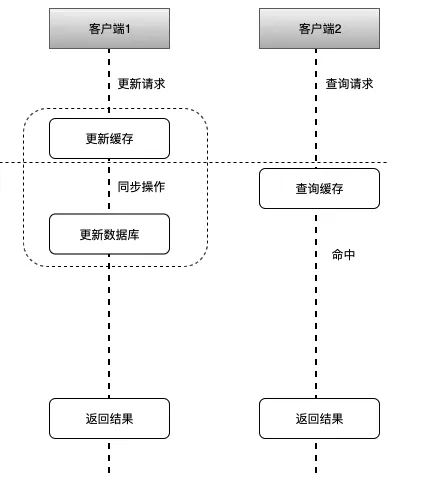
执行的流程顺序为:
-
客户端1 触发更新数据 A 的逻辑
-
客户端2 触发查询数据 A 的逻辑
-
客户端1 更新缓存中数据 A,缓存同步更新数据库中数据 A,再返回结果
-
客户端2 查询缓存中数据 A,命中返回
Read Through 和 WriteThrough 的流程类似,只是在客户端查询数据A时,如果缓存中数据A失效了(过期或被驱逐淘汰),则缓存会同步去数据库中查询数据A,并缓存起来,再返回给客户端。这种方式缓存不一致的概率极低。
(4)只更新缓存,由缓存自己异步更新数据库(Write Behind Cache Pattern)

执行流程顺序为:
-
客户端1 触发更新数据 A 的逻辑
-
客户端2 触发查询数据 A 的逻辑
-
客户端1 更新缓存中的数据 A,返回
-
客户端2 查询缓存中的数据 A,命中返回
-
缓存异步更新数据 A 到数据库中
这种方式的优势是读写的性能都非常好,基本上只要操作完内存后就返回给客户端了,但是其是非强一致性,存在丢失数据的情况。如果在缓存异步将数据更新到数据库中时,缓存服务挂了,此时未更新到数据库中的数据就丢失了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号