初识线性回归与逻辑回归

一、线性回归
- 相关系数
两个变量每单位的相关性程度
from collections import OrderedDict
import pandas as pd
# 数据集
examDict={
'学习时间':[0.50,0.75,1.00,1.25,1.50,1.75,1.75,2.00,2.25,
2.50,2.75,3.00,3.25,3.50,4.00,4.25,4.50,4.75,5.00,5.50],
'分数': [10, 22, 13, 43, 20, 22, 33, 50, 62,
48, 55, 75, 62, 73, 81, 76, 64, 82, 90, 93]
}
examOrderDict=OrderedDict(examDict)
examDf=pd.DataFrame(examOrderDict)
#查看数据集前5行
examDf.head()
#提取特征和标签
#特征features
exam_X=examDf.loc[:,'学习时间']
#标签labes
exam_y=examDf.loc[:,'分数']
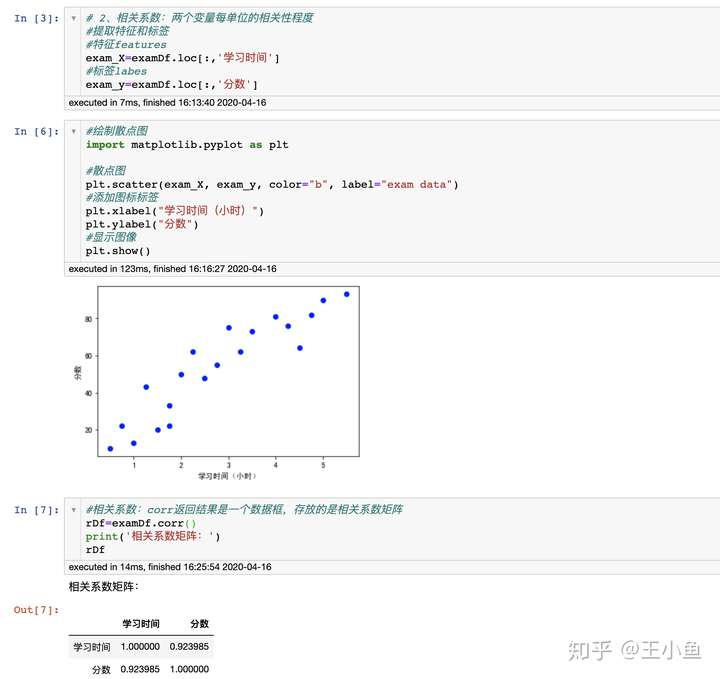
#绘制散点图
import matplotlib.pyplot as plt
#散点图
plt.scatter(exam_X, exam_y, color="b", label="exam data")
#添加图标标签
plt.xlabel("学习时间(小时)")
plt.ylabel("分数")
#显示图像
plt.show()
#相关系数:corr返回结果是一个数据框,存放的是相关系数矩阵
rDf=examDf.corr()
print('相关系数矩阵:')
rDf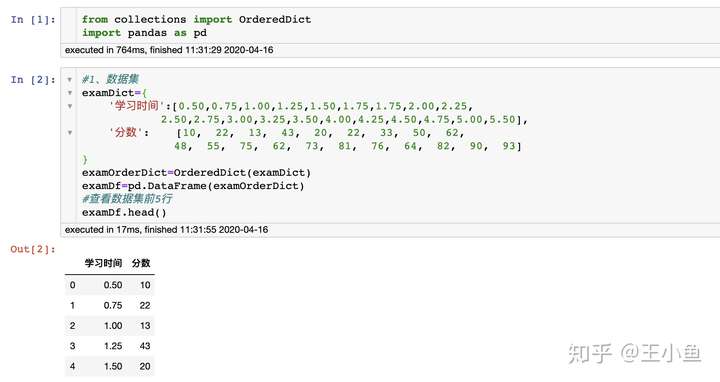
2. 线性回归
2.1 提取特征和标签
#特征features
exam_X=examDf.loc[:,'学习时间']
#标签labes
exam_y=examDf.loc[:,'分数']
2.2 建立训练数据和测试数据
# train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取训练数据(train)和测试数据(test)
# 第一个参数:所要划分的样本特征
# 第2个参数:所要划分的样本标签
# train_size:训练数据占比,如果是整数的话就是样本的数量
from sklearn.model_selection import train_test_split
#建立训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(exam_X,exam_y,train_size = .8)
#输出数据大小
print('原始数据特征:',exam_X.shape ,
',训练数据特征:', X_train.shape ,
',测试数据特征:',X_test.shape )
print('原始数据标签:',exam_y.shape ,
'训练数据标签:', y_train.shape ,
'测试数据标签:' ,y_test.shape)
#绘制散点图
import matplotlib.pyplot as plt
#散点图
plt.scatter(X_train, y_train, color="blue", label="训练数据")
plt.scatter(X_test, y_test, color="red", label="测试数据")
#添加图标标签
plt.legend(loc=2)
plt.xlabel("Hours")
plt.ylabel("Score")
#显示图像
plt.show()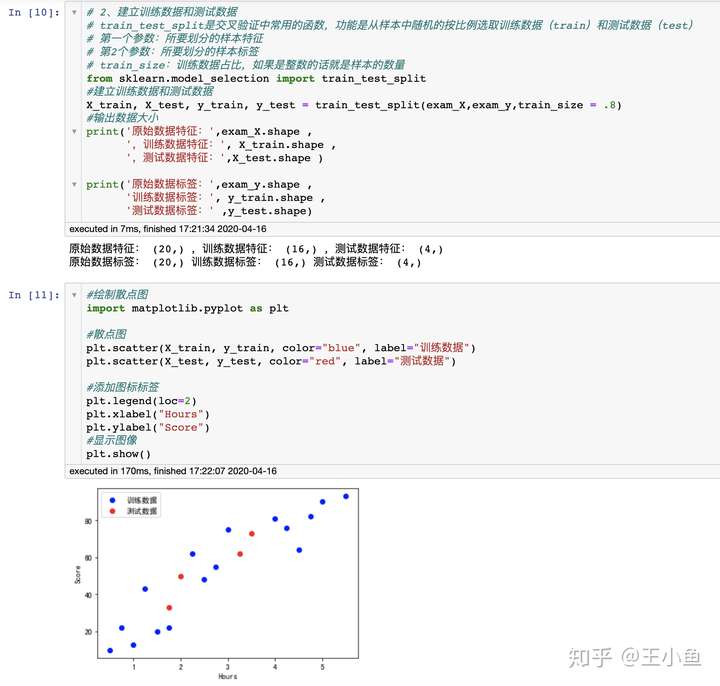
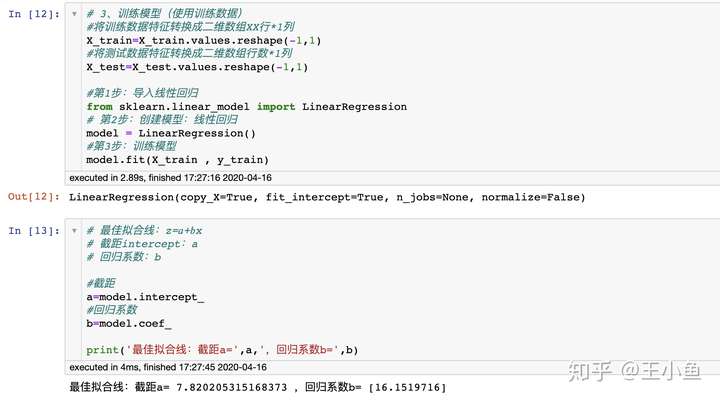
2.3 训练模型(使用训练数据)
#将训练数据特征转换成二维数组XX行*1列
X_train=X_train.values.reshape(-1,1)
#将测试数据特征转换成二维数组行数*1列
X_test=X_test.values.reshape(-1,1)
#第1步:导入线性回归
from sklearn.linear_model import LinearRegression
# 第2步:创建模型:线性回归
model = LinearRegression()
#第3步:训练模型
model.fit(X_train , y_train)
# 最佳拟合线:z= + x
# 截距intercept:a
# 回归系数:b
#截距
a=model.intercept_
#回归系数
b=model.coef_
print('最佳拟合线:截距a=',a,',回归系数b=',b)
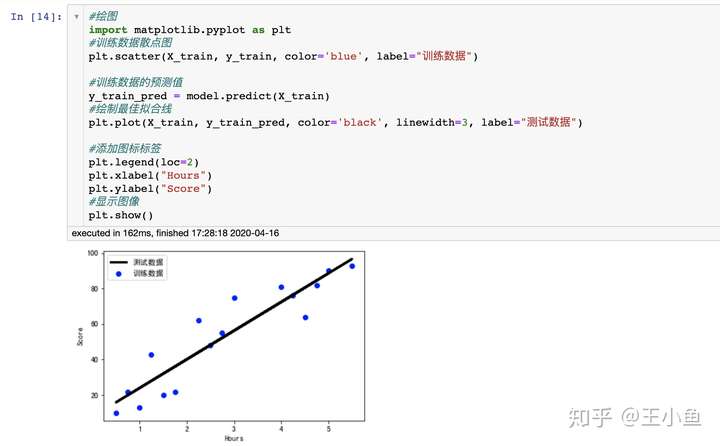
#绘图
import matplotlib.pyplot as plt
#训练数据散点图
plt.scatter(X_train, y_train, color='blue', label="训练数据")
#训练数据的预测值
y_train_pred = model.predict(X_train)
#绘制最佳拟合线
plt.plot(X_train, y_train_pred, color='black', linewidth=3, label="测试数据")
#添加图标标签
plt.legend(loc=2)
plt.xlabel("Hours")
plt.ylabel("Score")
#显示图像
plt.show()
2.4 模型评估(使用测试数据)
#线性回归的scroe方法得到的是决定系数R平方
#评估模型:决定系数R平方
# score内部会对第一个参数X_test用拟合曲线自动计算出y预测值,内容是决定系数R平方的计算过程。
model.score(X_test , y_test)
import matplotlib.pyplot as plt
# 第1步:绘制训练数据散点图
plt.scatter(X_train, y_train, color='blue', label="训练数据")
# 第2步:用训练数据绘制最佳线
#最佳拟合线训练数据的预测值
y_train_pred = model.predict(X_train)
#绘制最佳拟合线:标签用的是训练数据的预测值y_train_pred
plt.plot(X_train, y_train_pred, color='black', linewidth=3, label="最佳拟合线")
# 第3步:绘制测试数据的散点图
plt.scatter(X_test, y_test, color='red', label="测试数据")
#添加图标标签
plt.legend(loc=2)
plt.xlabel("Hours")
plt.ylabel("Score")
#显示图像
plt.show()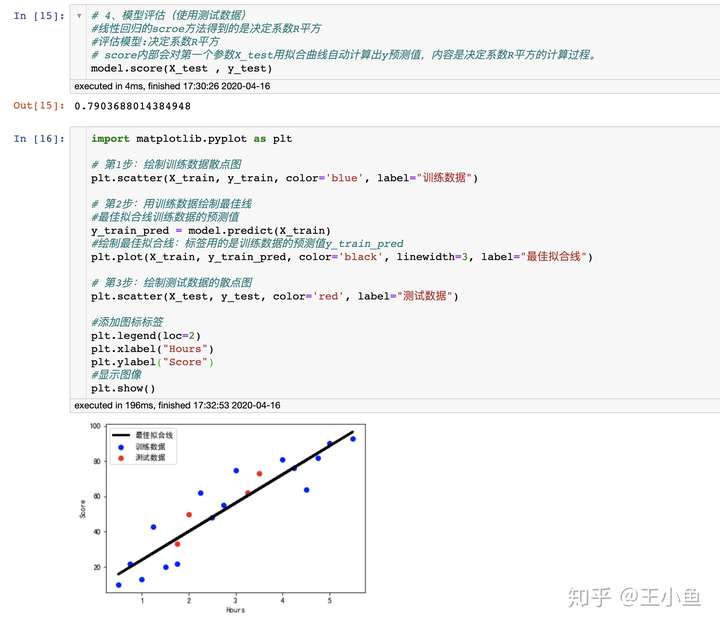
二、逻辑回归
- 建立数据集
from collections import OrderedDict
import pandas as pd
examDict={
'学习时间':[0.50,0.75,1.00,1.25,1.50,1.75,1.75,2.00,2.25,2.50,
2.75,3.00,3.25,3.50,4.00,4.25,4.50,4.75,5.00,5.50],
'通过考试':[0,0,0,0,0,0,1,0,1,0,1,0,1,0,1,1,1,1,1,1]
}
examOrderDict=OrderedDict(examDict)
examDf=pd.DataFrame(examOrderDict)
examDf.head()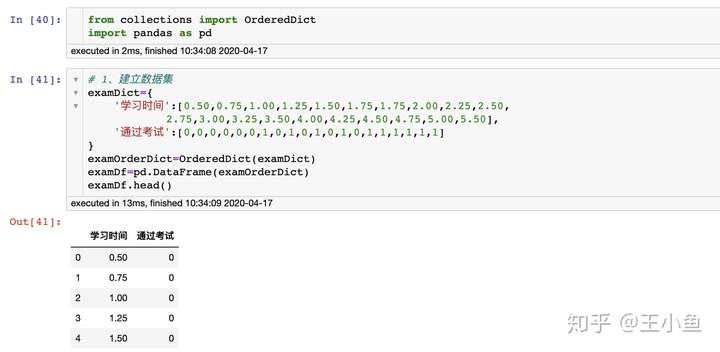
2. 提取特征和标签
#特征features
exam_X=examDf.loc[:,'学习时间']
#标签labes
exam_y=examDf.loc[:,'通过考试']
3. 绘制散点图
# 通过散点图看看两个变量的分布情况。
import matplotlib.pyplot as plt
#散点图
plt.scatter(exam_X, exam_y, color="b", label="exam data")
#添加图标标签
plt.xlabel("学习时间(小时)")
plt.ylabel("通过考试")
#显示图像
plt.show()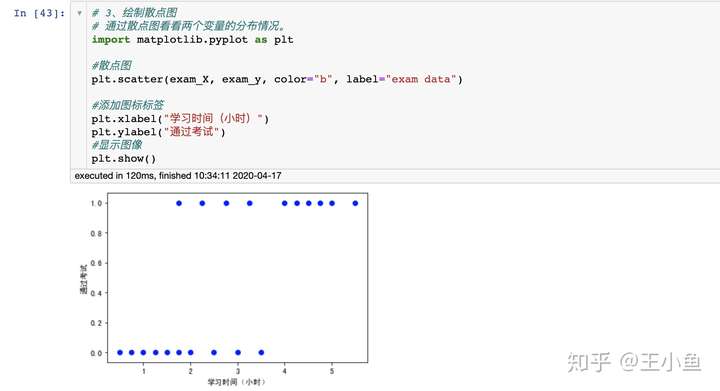
4. 建立训练数据集和测试数据集
# train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取训练数据(train)和测试数据(test)
# 第一个参数:所要划分的样本特征
# 第2个参数:所要划分的样本标签
# train_size:训练数据占比,如果是整数的话就是样本的数量
from sklearn.model_selection import train_test_split
#建立训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(exam_X,exam_y,train_size = .8)
#输出数据大小
print('原始数据特征:',exam_X.shape ,
',训练数据特征:', X_train.shape ,
',测试数据特征:',X_test.shape )
print('原始数据标签:',exam_y.shape ,
'训练数据标签:', y_train.shape ,
'测试数据标签:' ,y_test.shape)
#绘制散点图
import matplotlib.pyplot as plt
#散点图
plt.scatter(X_train, y_train, color="blue", label="训练数据")
plt.scatter(X_test, y_test, color="red", label="测试数据")
#添加图标标签
plt.legend(loc=2)
plt.xlabel("学习时间(小时")
plt.ylabel("通过考试")
#显示图像
plt.show()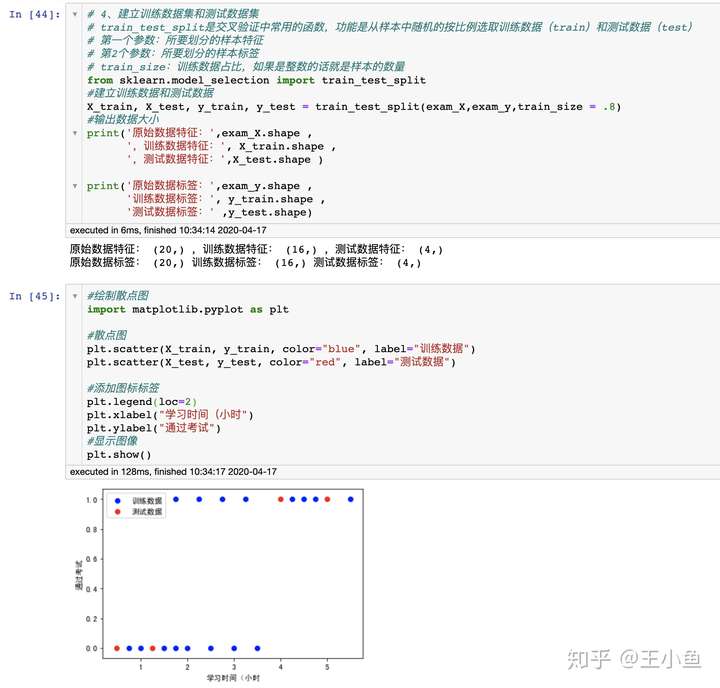
5. 训练模型(使用训练数据)
#将训练数据特征转换成二维数组XX行*1列
X_train=X_train.values.reshape(-1,1)
#将测试数据特征转换成二维数组行数*1列
X_test=X_test.values.reshape(-1,1)
#第1步:导入线性回归
from sklearn.linear_model import LinearRegression
# 第2步:创建模型:线性回归
model = LinearRegression()
#第3步:训练模型
model.fit(X_train , y_train)
model.fit(X_train , y_train)
6. 模型评估(使用测试数据)
#评估模型:准确率
model.score(X_test , y_test)
#预测数据:使用模型的predict方法可以进行预测。
#这里我们输入学生的特征学习时间3小时,模型返回结果标签是1,表示预测该学生通过考试。
pred=model.predict([[3]])
print(pred)
'''
理解逻辑回归函数
斜率slope
截距intercept
'''
import numpy as np
#第1步:得到回归方程的z值
#回归方程:z= + x
#截距
a=model.intercept_
#回归系数
b=model.coef_
x=3
z=a+b*x
#第2步:将z值带入逻辑回归函数中,得到概率值
y_pred=1/(1+np.exp(-z))
print('预测的概率值:',y_pred)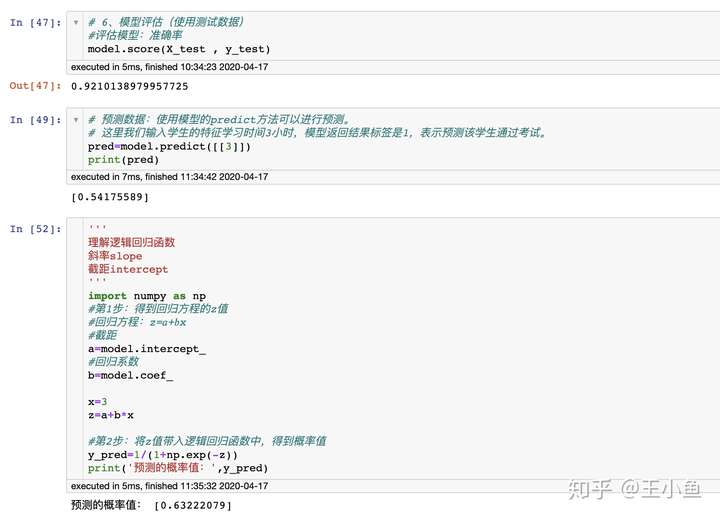
三、小总结:
3.1 线性回归
3.1.1 优点:
善于获取数据集中的线性关系;
适用于在已有了一些预先定义好的变量并且需要一个简单的预测模型的情况下使用;
训练速度和预测速度较快;
在小数据集上表现很好;
结果可解释,并且易于说明;
当新增数据时,易于更新模型;
不需要进行参数调整(下面的正则化线性模型需要调整正则化参数);
不需要特征缩放(下面的正则化线性模型需要特征缩放);
如果数据集具有冗余的特征,那么线性回归可能是不稳定的;
3.1.2 缺点:
不适用于非线性数据;
预测精确度较低;
可能会出现过度拟合(下面的正则化模型可以抵消这个影响);
分离信号和噪声的效果不理想,在使用前需要去掉不相关的特征;
不了解数据集中的特征交互;
3.2 逻辑回归:
3.2.1 优点:
- (模型)模型清晰,背后的概率推导经得住推敲。
- (输出)输出值自然地落在0到1之间,并且有概率意义(逻辑回归的输出是概率么?https://www.jianshu.com/p/a8d6b40da0cf)。
- (参数)参数代表每个特征对输出的影响,可解释性强。
- (简单高效)实施简单,非常高效(计算量小、存储占用低),可以在大数据场景中使用。
- (可扩展)可以使用online learning的方式更新轻松更新参数,不需要重新训练整个模型。
- (过拟合)解决过拟合的方法很多,如L1、L2正则化。
- (多重共线性)L2正则化就可以解决多重共线性问题。
3.2.2 缺点:
- (特征相关情况)因为它本质上是一个线性的分类器,所以处理不好特征之间相关的情况。
- (特征空间)特征空间很大时,性能不好。
- (精度)容易欠拟合,精度不高。
3.2.3 适用场景
应用:
- 用于分类:适合做很多分类算法的基础组件。
- 用于预测:预测事件发生的概率(输出)。
- 用于分析:单一因素对某一个事件发生的影响因素分析(特征参数值)。
适用:
- 基本假设:输出类别服从伯努利二项分布。
- 样本线性可分。
- 特征空间不是很大的情况。
- 不必在意特征间相关性的情景。
- 后续会有大量新数据的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号