数据采集第四次作业
作业1
股票数据爬取实验
(1)要求:使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
HTML信息:
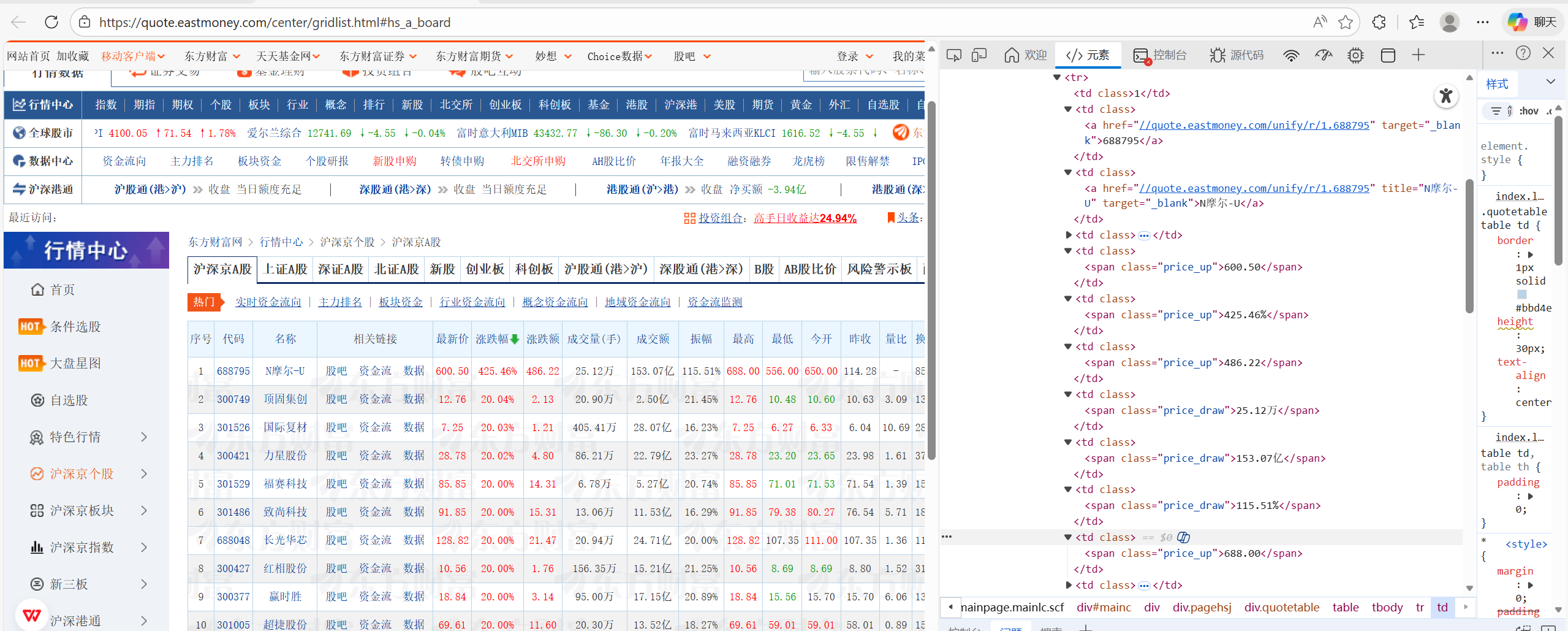
核心代码:
点击查看代码
def crawl_board(self, hash_code, board_name, max_pages):
"""
爬取指定板块的股票数据
:param hash_code: 板块的hash编码
:param board_name: 板块名称
:param max_pages: 最大爬取页数
:return: 爬取的所有数据行
"""
all_data = []
# 构造完整的URL
url = self.base_url + hash_code
print(f"正在访问: {url}")
# 访问目标网页
self.driver.get(url)
# 等待页面加载
time.sleep(5)
# 循环爬取多页数据
for page in range(1, max_pages + 1):
# 如果不是第一页,则需要点击下一页按钮
if page > 1:
# 查找下一页按钮
next_btn = self.driver.find_element(By.XPATH, '//a[@title="下一页"]')
# 检查按钮是否可用
if next_btn.is_enabled():
# 滚动到按钮位置
self.driver.execute_script("arguments[0].scrollIntoView(true);", next_btn)
time.sleep(1)
# 点击下一页按钮
self.driver.execute_script("arguments[0].click();", next_btn)
# 等待新页面加载
time.sleep(5)
else:
print(" 无更多页面,提前结束。")
break
# 等待表格元素加载完成
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "table tbody tr")))
time.sleep(2)
# 获取当前页面所有股票行数据
rows = self.driver.find_elements(By.CSS_SELECTOR, "table tbody tr")
# 遍历每一行数据
for row in rows:
# 获取行内所有单元格
tds = row.find_elements(By.TAG_NAME, "td")
# 如果单元格数量不足14个,则跳过该行
if len(tds) < 14:
continue
# 提取各个字段的数据
data_row = [
tds[0].text.strip(), # 序号
tds[1].text.strip(), # 代码
tds[2].text.strip(), # 名称
tds[4].text.strip(), # 最新价
tds[5].text.strip(), # 涨跌幅
tds[6].text.strip(), # 涨跌额
tds[7].text.strip(), # 成交量(手)
tds[8].text.strip(), # 成交额
tds[9].text.strip(), # 振幅
tds[10].text.strip(), # 最高
tds[11].text.strip(), # 最低
tds[12].text.strip(), # 今开
tds[13].text.strip() # 昨收
]
# 将数据行添加到总数据列表中
all_data.append(data_row)
print(f" 第 {page} 页数据已采集")
return all_data
结果:
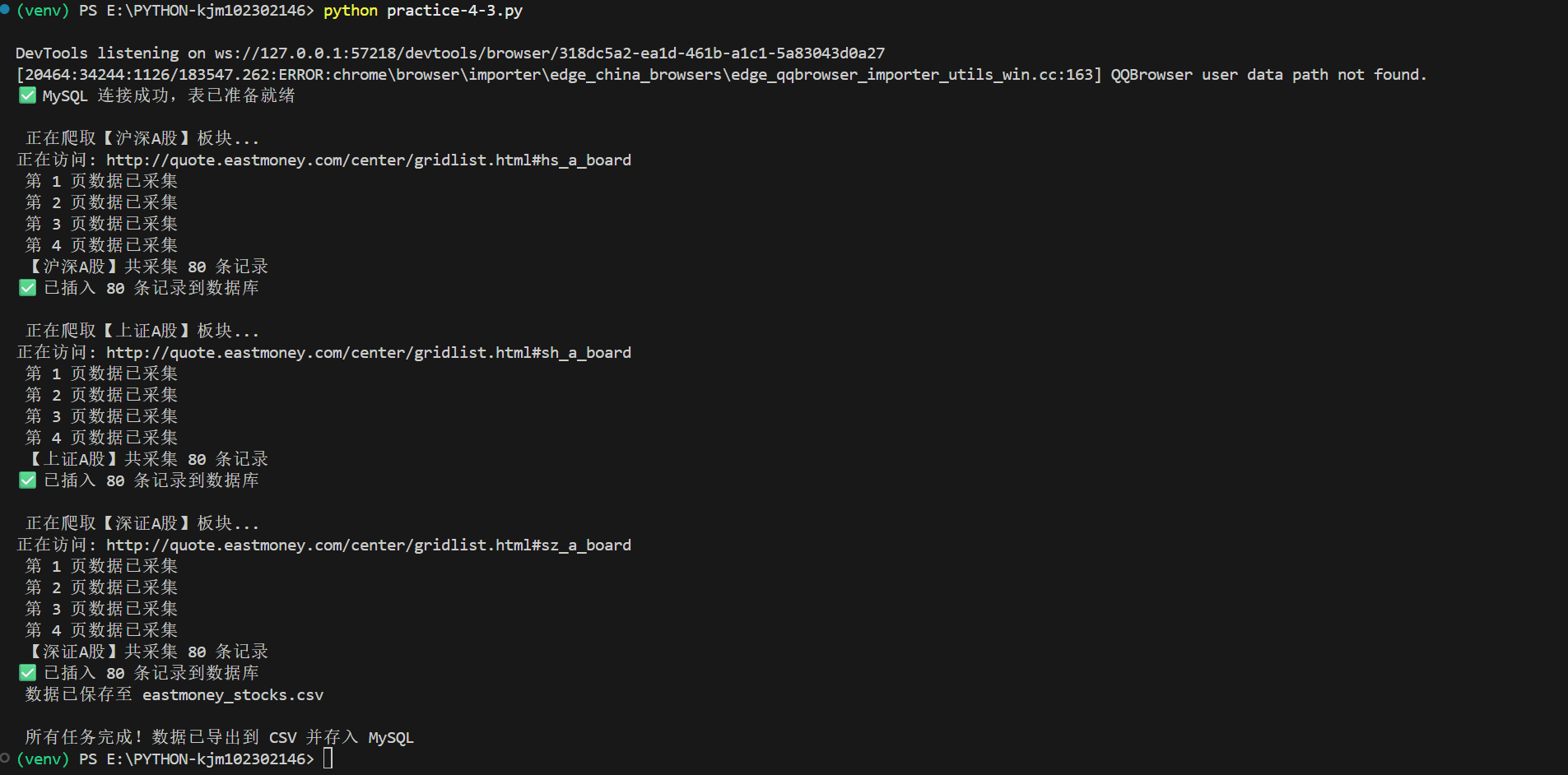
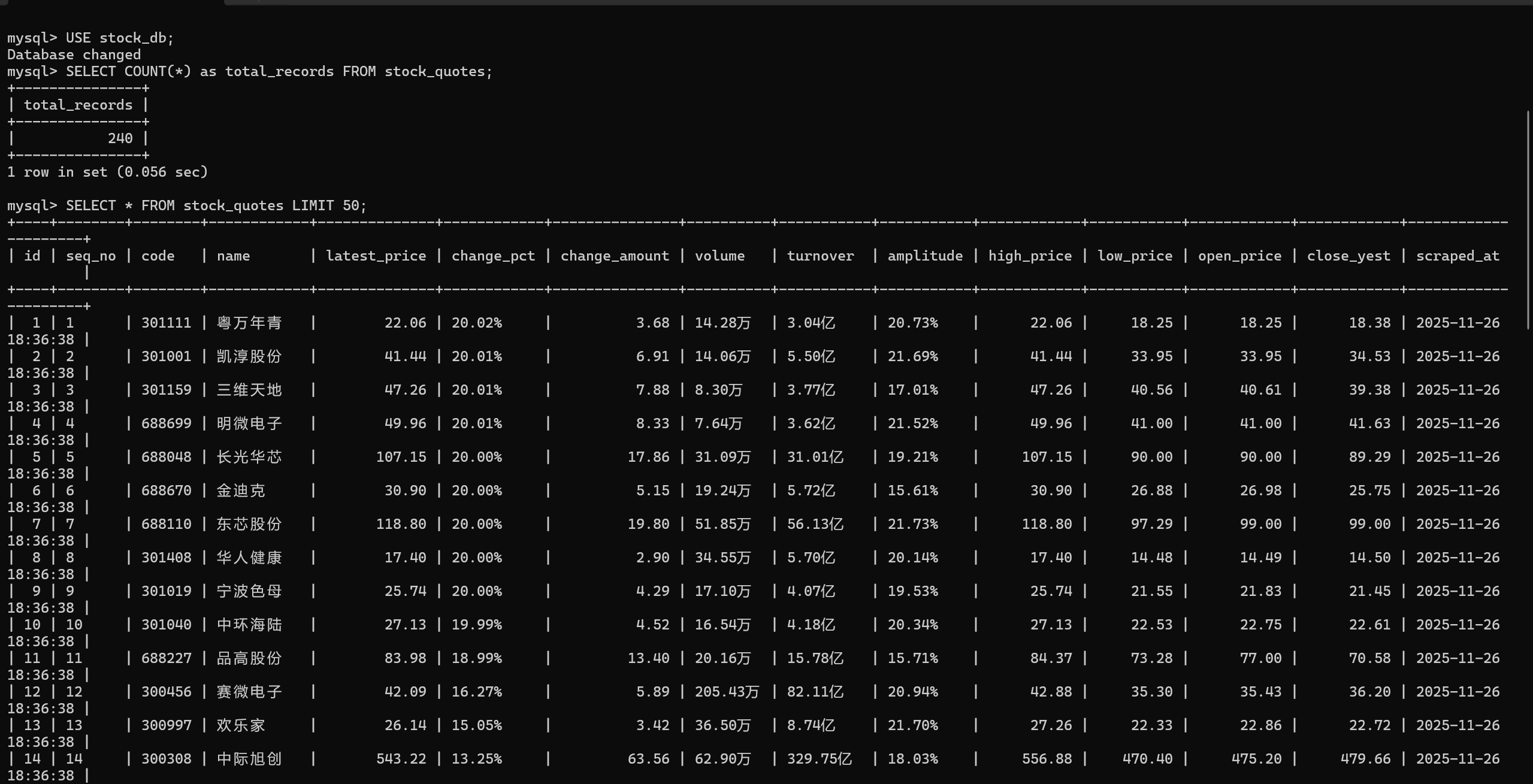
完整代码:
https://gitee.com/kjmfzu/fzu_-kjm/blob/master/实验4/practice-4-2.py
(2)心得体会
新的股票信息新增“相关链接”一列,爬取数据时要略过这一列,并且通过这个实验,我掌握了使用Selenium爬取动态网页数据的技巧,学会了处理金融数据的特殊格式,并实现了数据的自动化采集和存储。这让我对网络爬虫在金融领域的应用有了更深理解。
作业2
慕课课程数据爬取实验
(1)要求:使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
核心代码:
点击查看代码
def get_text(driver, selectors, attr=None, use_innerText=False):
"""
从页面元素中获取文本内容的通用函数
:param driver: WebDriver实例
:param selectors: 选择器元组列表,格式为[(By.XXX, 'selector'), ...]
:param attr: 要获取的属性名(可选)
:param use_innerText: 是否使用innerText获取文本(可选)
:return: 获取到的文本内容或"未知"
"""
# 遍历所有选择器尝试获取元素
for by, val in selectors:
try:
# 根据选择器查找元素
el = driver.find_element(by, val)
# 如果指定了属性名,则返回属性值
if attr:
return el.get_attribute(attr).strip()
# 使用 innerText 获取包含格式的完整文本,解决 .text 获取不全的问题
if use_innerText:
return el.get_attribute("innerText").strip()
# 默认返回元素的text属性
return el.text.strip()
except: continue
# 所有选择器都找不到元素时返回默认值
return "未知"
def crawl_details(driver):
"""提取详情页数据"""
# 创建存储课程信息的字典
d = {}
# 1. 课程名 & 学校
# 获取课程标题
d['cCourse'] = get_text(driver, [(By.CSS_SELECTOR, ".course-title"), (By.CSS_SELECTOR, "h1")])
# 获取学校名称(通过图片的alt属性)
d['cCollege'] = get_text(driver, [(By.CSS_SELECTOR, ".m-teachers img.u-img")], "alt")
# 如果通过图片无法获取学校名称,则尝试其他方式
if d['cCollege'] == "未知":
d['cCollege'] = get_text(driver, [(By.CSS_SELECTOR, ".school-name")])
# 2. 人数 & 进度
# 获取选课人数
raw_cnt = get_text(driver, [(By.CSS_SELECTOR, "span.count"), (By.CLASS_NAME, "course-enroll-count")])
# 使用正则表达式提取数字部分
d['cCount'] = (re.findall(r'\d+', raw_cnt) or ["0"])[0]
try: # SPOC版时间
# 尝试获取SPOC版本的开课时间
d['cProcess'] = driver.find_element(By.XPATH, "//span[contains(text(),'开课时间')]/following-sibling::span").text
except: # 普通版时间
# 获取普通版本的开课时间
d['cProcess'] = get_text(driver, [(By.CLASS_NAME, "course-enroll-time")])
# 替换时间范围符号
d['cProcess'] = d['cProcess'].replace("~", "至")
# 3. 课程简介 (关键修改:放宽限制,使用 innerText)
# 获取课程简介内容
d['cBrief'] = get_text(driver, [
(By.CSS_SELECTOR, ".f-richEditorText"), # SPOC版
(By.CSS_SELECTOR, ".m-course-intro .content"), # 普通版
(By.CSS_SELECTOR, ".u-content")
], use_innerText=True)
# 限制 50 字,便于查看
d['cBrief'] = d['cBrief'][:50]
# 4. 老师 (自动翻页)
# 使用集合存储教师姓名,避免重复
teachers = set()
# (A) 抓普通版静态老师
# 获取普通版本的教师姓名
for t in driver.find_elements(By.CSS_SELECTOR, ".u-teacher-name"): teachers.add(t.text.strip())
# (B) 抓 SPOC 版轮播图老师 (循环翻页)
# 获取SPOC版本的教师信息(可能需要翻页)
for _ in range(5):
try:
# 获取轮播图中的教师姓名
for t in driver.find_elements(By.CSS_SELECTOR, ".m-teachers h3.f-fc3"):
# 强制获取隐藏文本
name = t.get_attribute("textContent").strip() # 强制获取隐藏文本
if name: teachers.add(name)
# 查找并点击下一页按钮
btn = driver.find_element(By.CSS_SELECTOR, ".um-list-slider_next")
if btn.is_displayed():
btn.click()
time.sleep(0.5)
else: break
except: break
# 5. 整理团队数据
# 将教师集合转换为列表
t_list = list(teachers)
if t_list:
# 主讲人 (取第一个)
d['cTeacher'] = t_list[0]
# 团队成员 (包含主讲人 + 其他人)
d['cTeam'] = ",".join(t_list)
else:
# 如果没有找到教师信息,则设置默认值
d['cTeacher'] = "未知"; d['cTeam'] = "无"
return d
点击查看代码
try:
# 访问中国大学MOOC首页
driver.get("https://www.icourse163.org/")
# 尝试点首页登录按钮
try: driver.find_element(By.XPATH, "//div[contains(text(),'登录/注册')]").click()
except: pass
# 唯一的人工操作环节
print("\n" + "="*50)
print(">>> 1. 请在浏览器登录")
print(">>> 2. 请点击同意【隐私政策】")
print(">>> 3. 完成后,请在这里按【回车键】启动全自动爬取...")
print("="*50 + "\n")
input(">>> 等待按回车: ")
# 2. 自动跳转课程列表
print(">>> 正在跳转课程列表...")
try:
# 尝试点击"我的课程"链接
driver.find_element(By.XPATH, "//a[contains(text(),'我的课程')]").click()
except:
# 如果找不到"我的课程"链接,则直接访问课程列表页面
driver.get("https://www.icourse163.org/home.htm#/home/course")
# 等待列表加载完成
time.sleep(5)
点击查看代码
# 3. 循环爬取
# 获取所有课程卡片元素
cards = driver.find_elements(By.CSS_SELECTOR, ".course-card-wrapper, .u-course-card, .u-clist .u-course-card")
print(f">>> 发现 {len(cards)} 门课程,开始处理...")
# 遍历所有课程卡片
for i in range(len(cards)):
try:
# 重新定位防失效(防止页面元素变化导致的错误)
current_cards = driver.find_elements(By.CSS_SELECTOR, ".course-card-wrapper, .u-course-card, .u-clist .u-course-card")
if i >= len(current_cards): break
card = current_cards[i]
# 进入详情页
try:
# 尝试通过更多按钮进入课程详情
ActionChains(driver).move_to_element(card.find_element(By.CSS_SELECTOR, ".u-icon-dots-more")).perform()
time.sleep(0.5)
driver.find_element(By.LINK_TEXT, "查看课程介绍").click()
except:
# 备选方案:直接点击卡片
card.click()
# 等待页面加载
time.sleep(2)
# 切换到新打开的标签页
driver.switch_to.window(driver.window_handles[-1])
# 抓取并存库
# 爬取课程详情信息
data = crawl_details(driver)
# 将数据保存到数据库
save_to_mysql(data)
# 关闭当前标签页并切换回主页面
driver.close()
driver.switch_to.window(driver.window_handles[0])
except Exception as e:
# 处理异常情况
print(f" [跳过] 课程 {i+1} 异常: {e}")
# 如果打开了多个标签页但出现异常,则关闭当前标签页并切换回主页面
if len(driver.window_handles) > 1:
driver.close(); driver.switch_to.window(driver.window_handles[0])
完整代码:
https://gitee.com/kjmfzu/fzu_-kjm/blob/master/实验4/practice-4-2.py
结果:
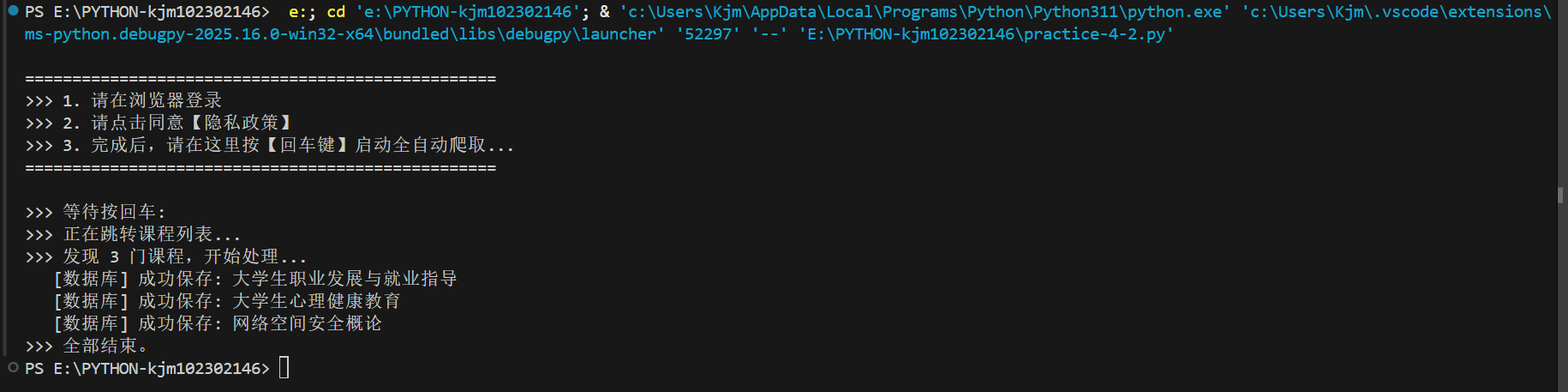

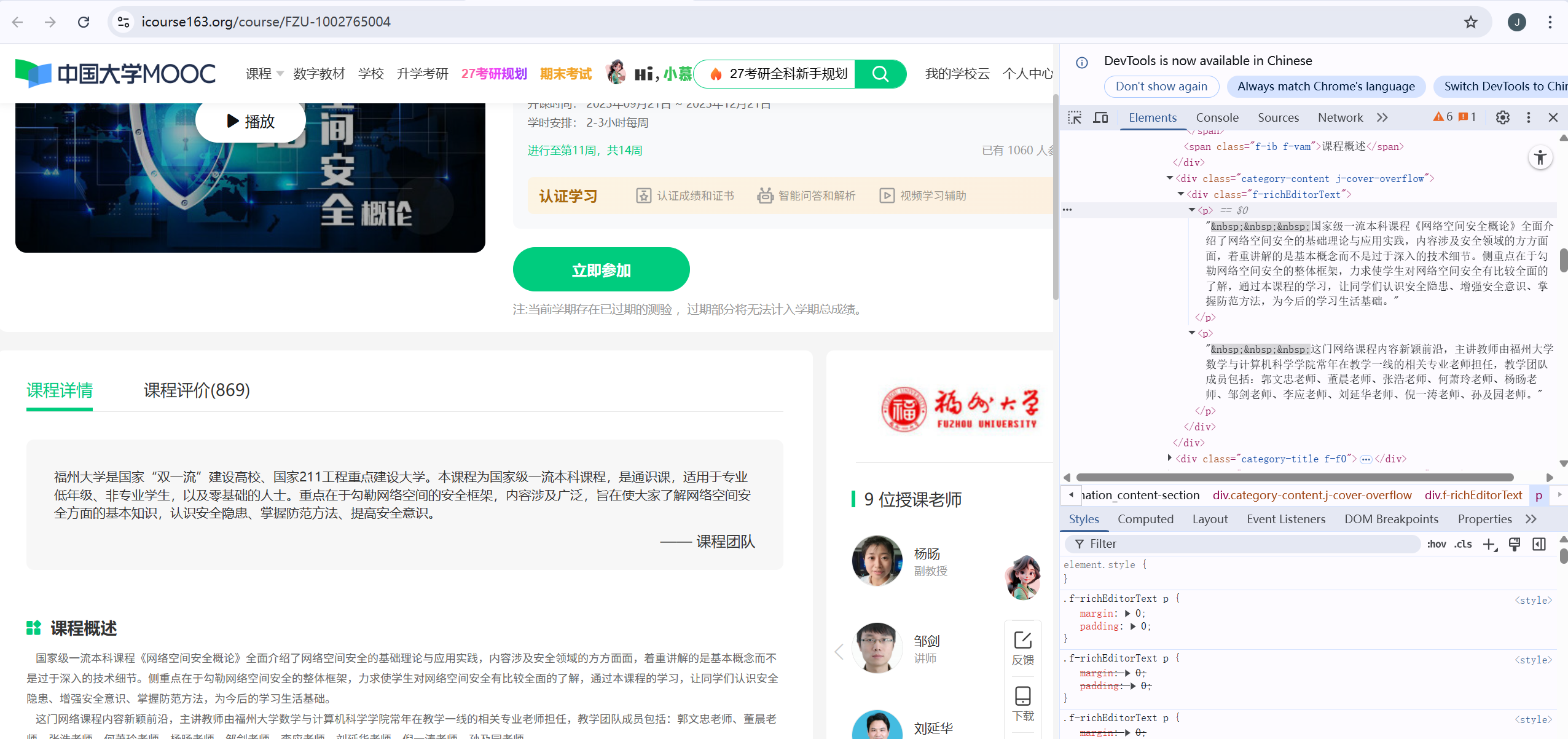
我的思路是选择手动登录+点掉隐私政策来方便获取课程详细HTML信息,其他操作让程序全自动进行。并且我还设置了课程简绍限制字数为50来方便MYSQL界面查看,以下是我个人账号的课程部分HTML信息
其中值得注意是个人课程的查看课程介绍和老师界面的翻页按钮
查看课程简绍
老师界面翻页按钮
登录键
我的课程
课程名
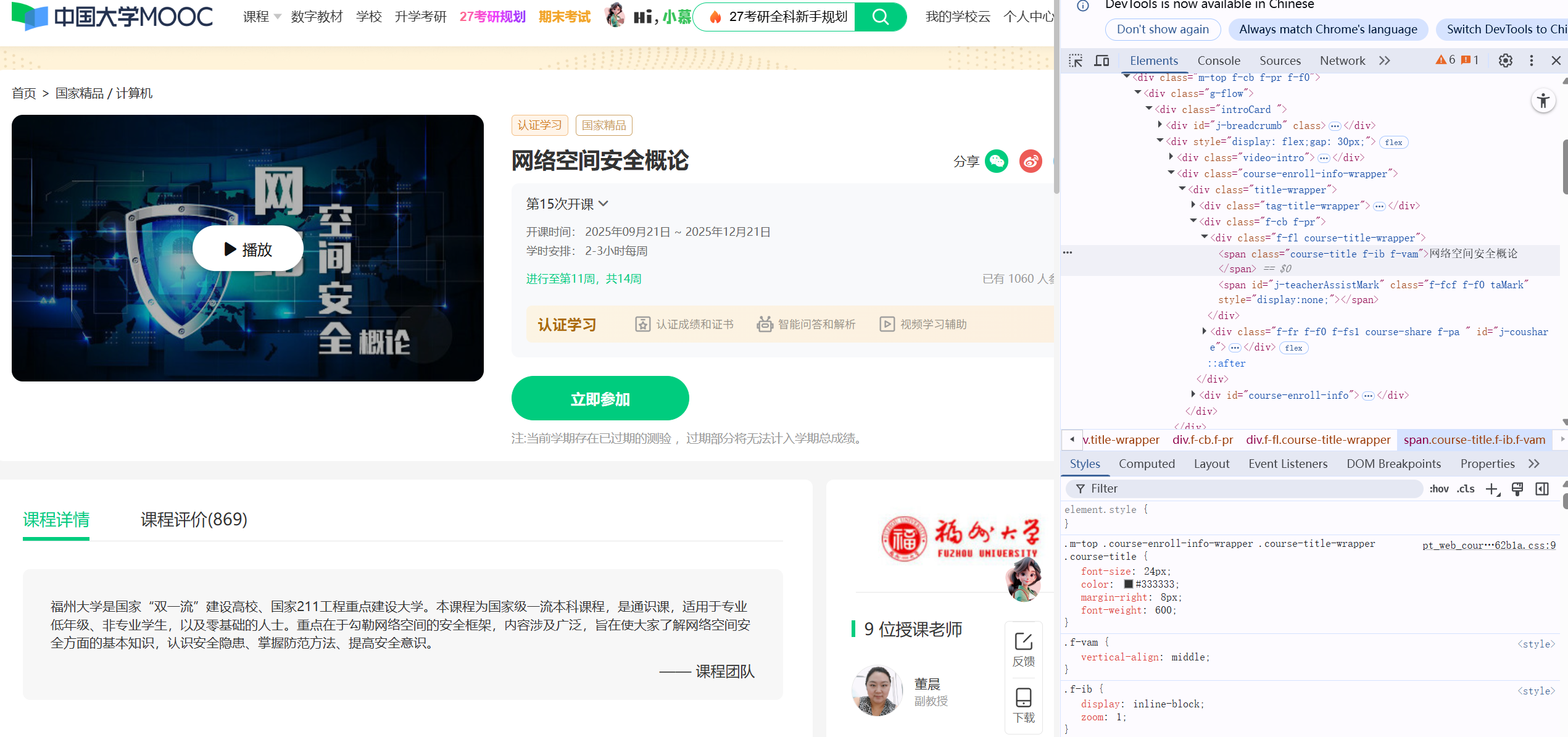
开课时间
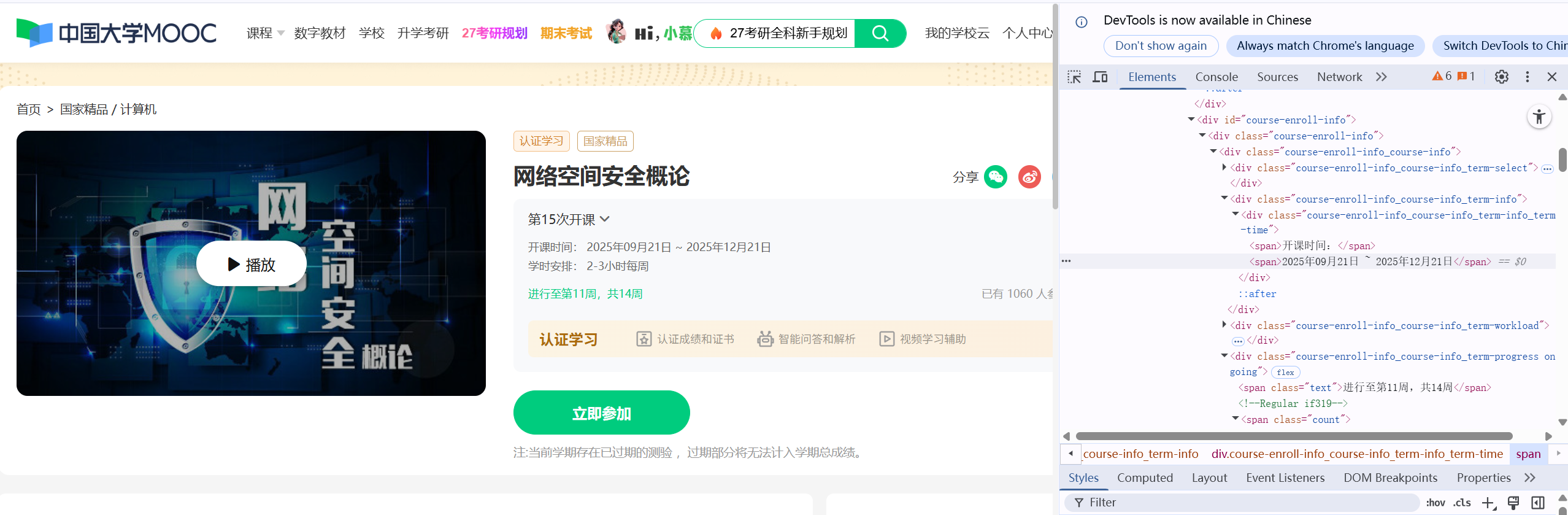
进度,人数
学校名
课程概述
(2)心得体会:
这个项目让我学会了如何爬取教育平台数据,处理复杂的页面交互和教师信息展示。特别是解决了iframe和动态加载内容的抓取难题,提升了我对复杂网页结构的分析能力。
作业3
华为云平台实验
(1)要求:掌握大数据相关服务,熟悉 Xshell 的使用
环境搭建:
任务一:开通 MapReduce 服务
1.申请弹性公网IP
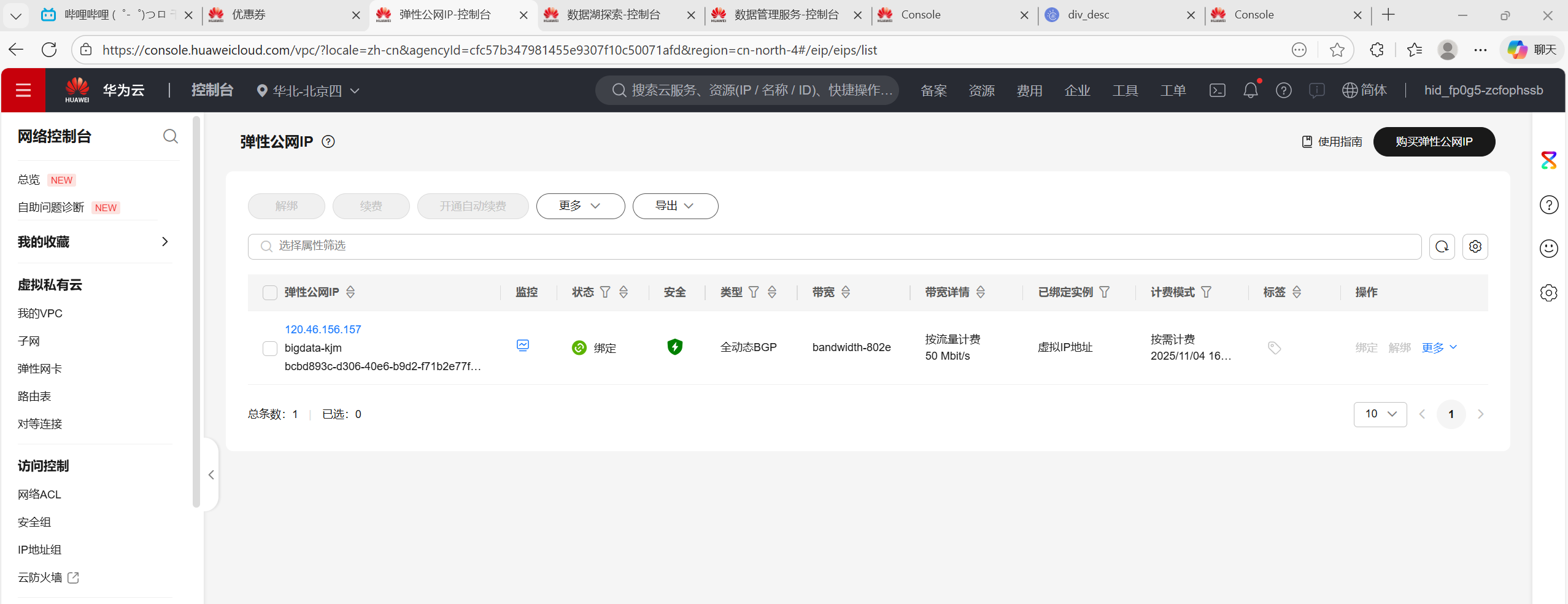
2.开通MapReduce服务
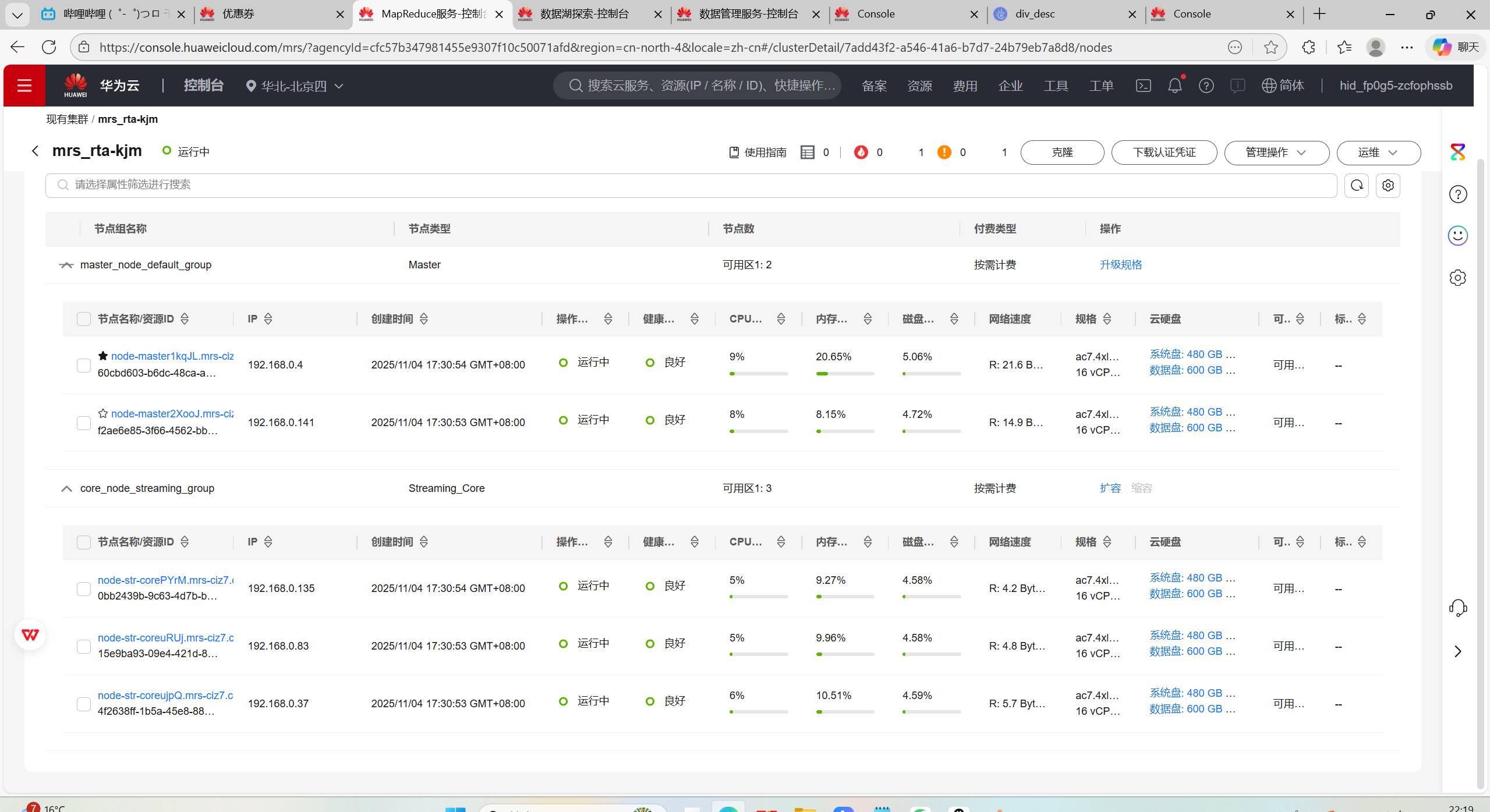
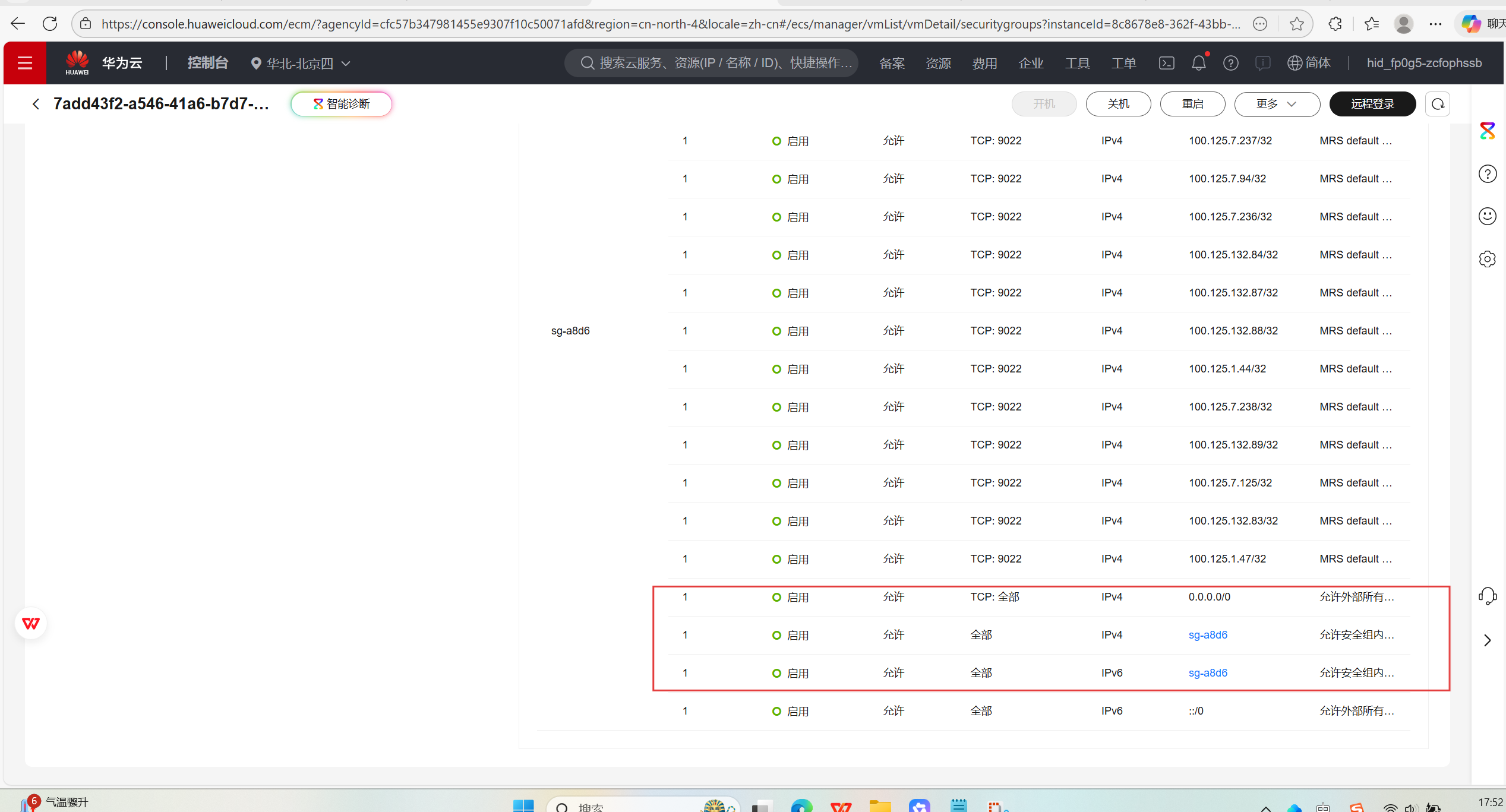
安全组
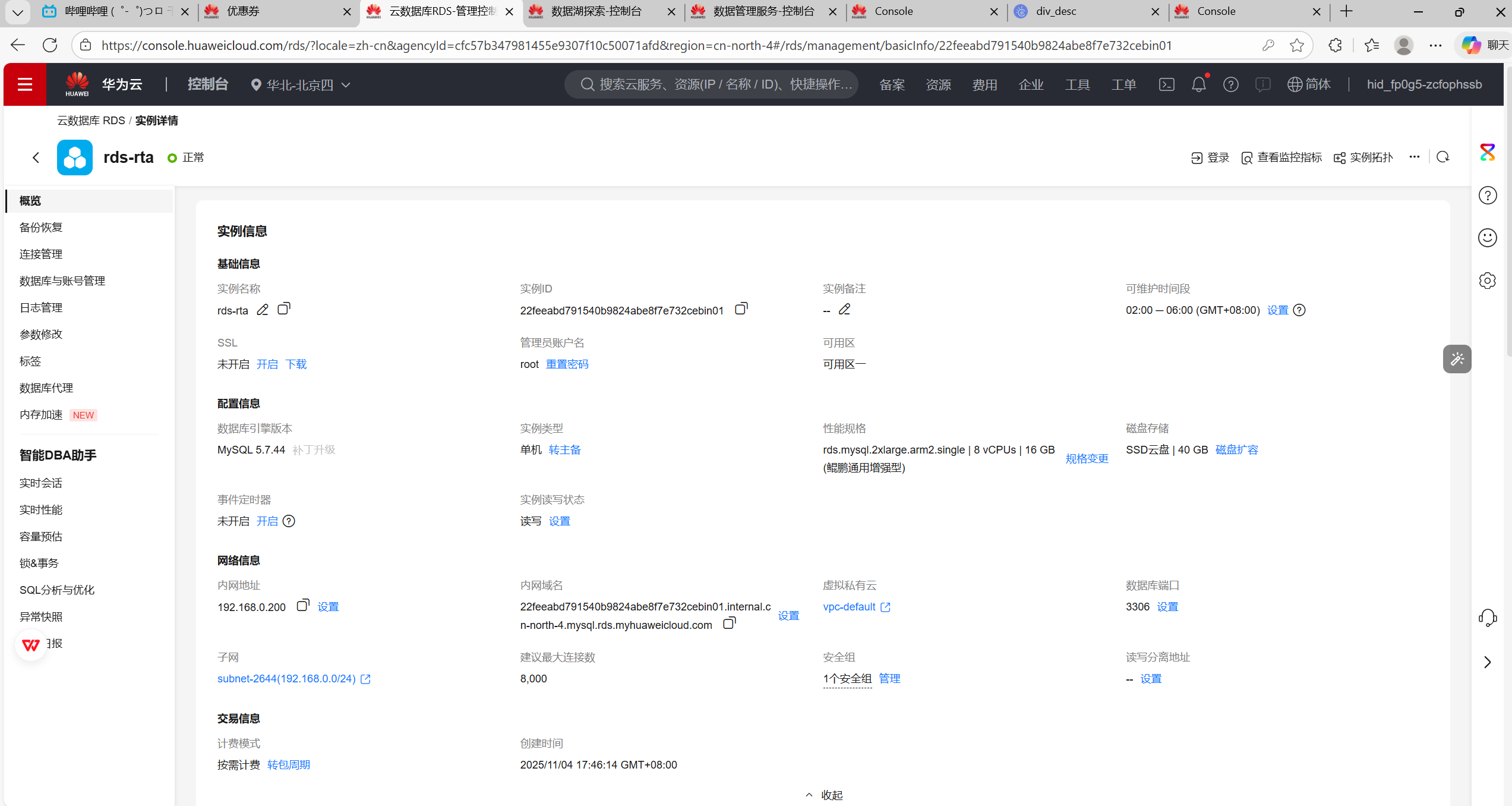
3.开通云数据库服务RDS
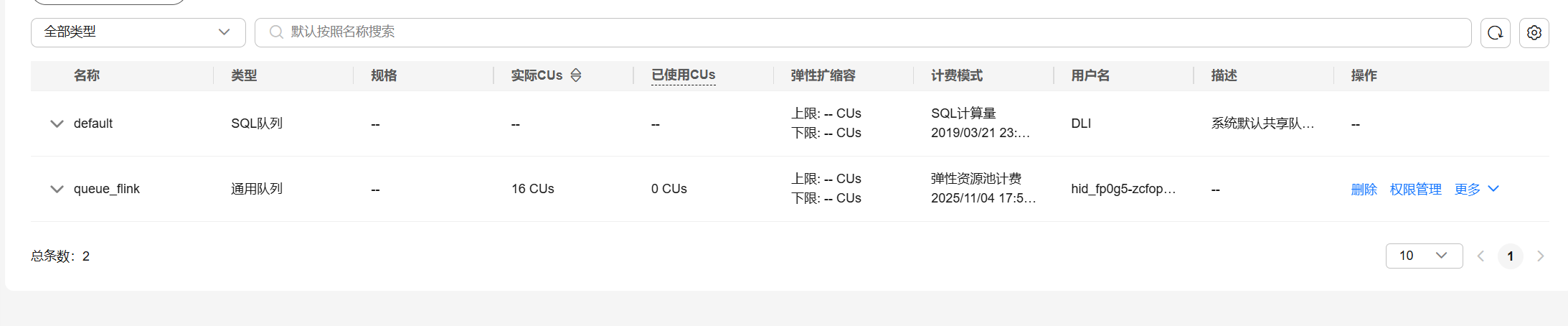
4.开通数据湖探索服务(DLI)
实时分析开发实战:
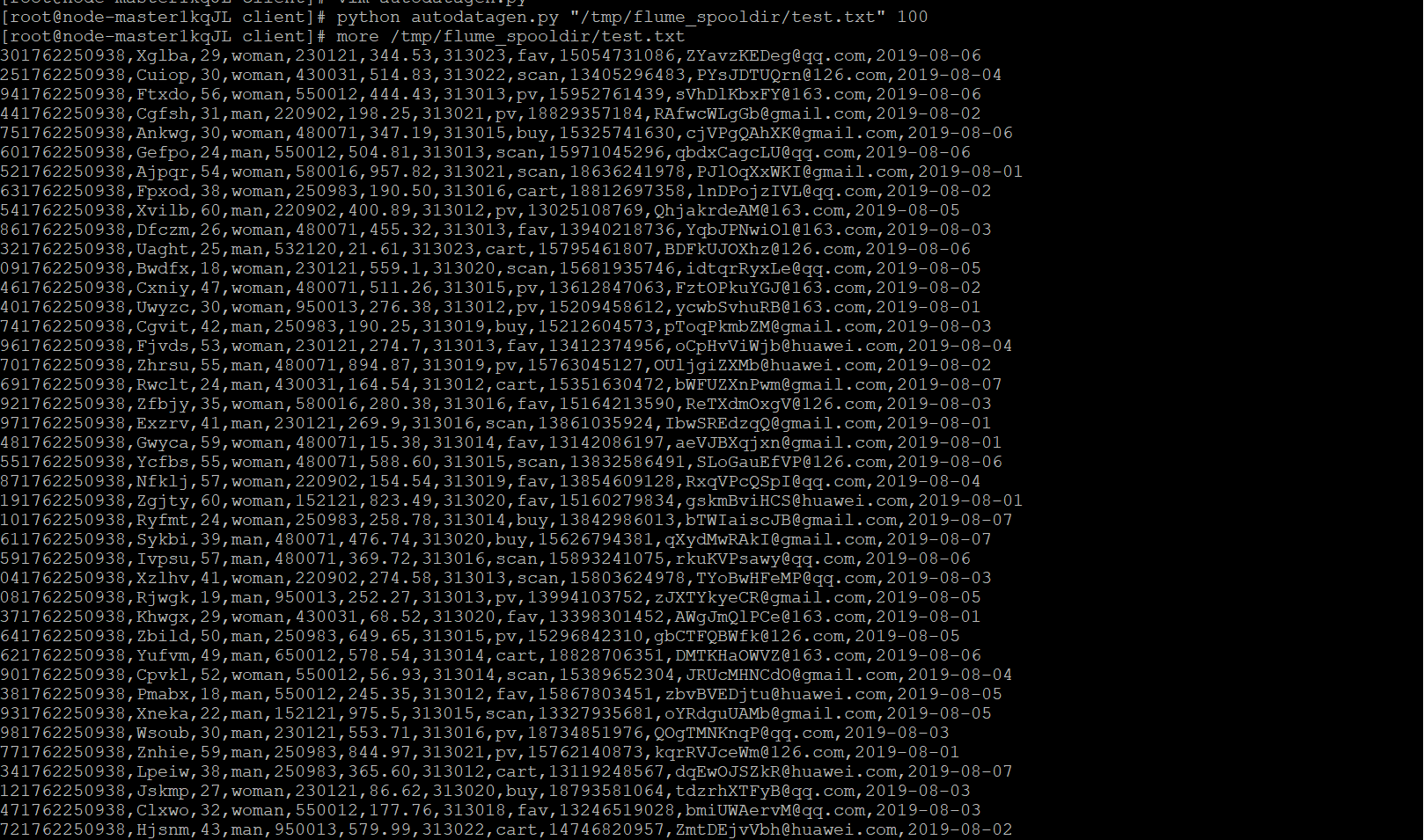
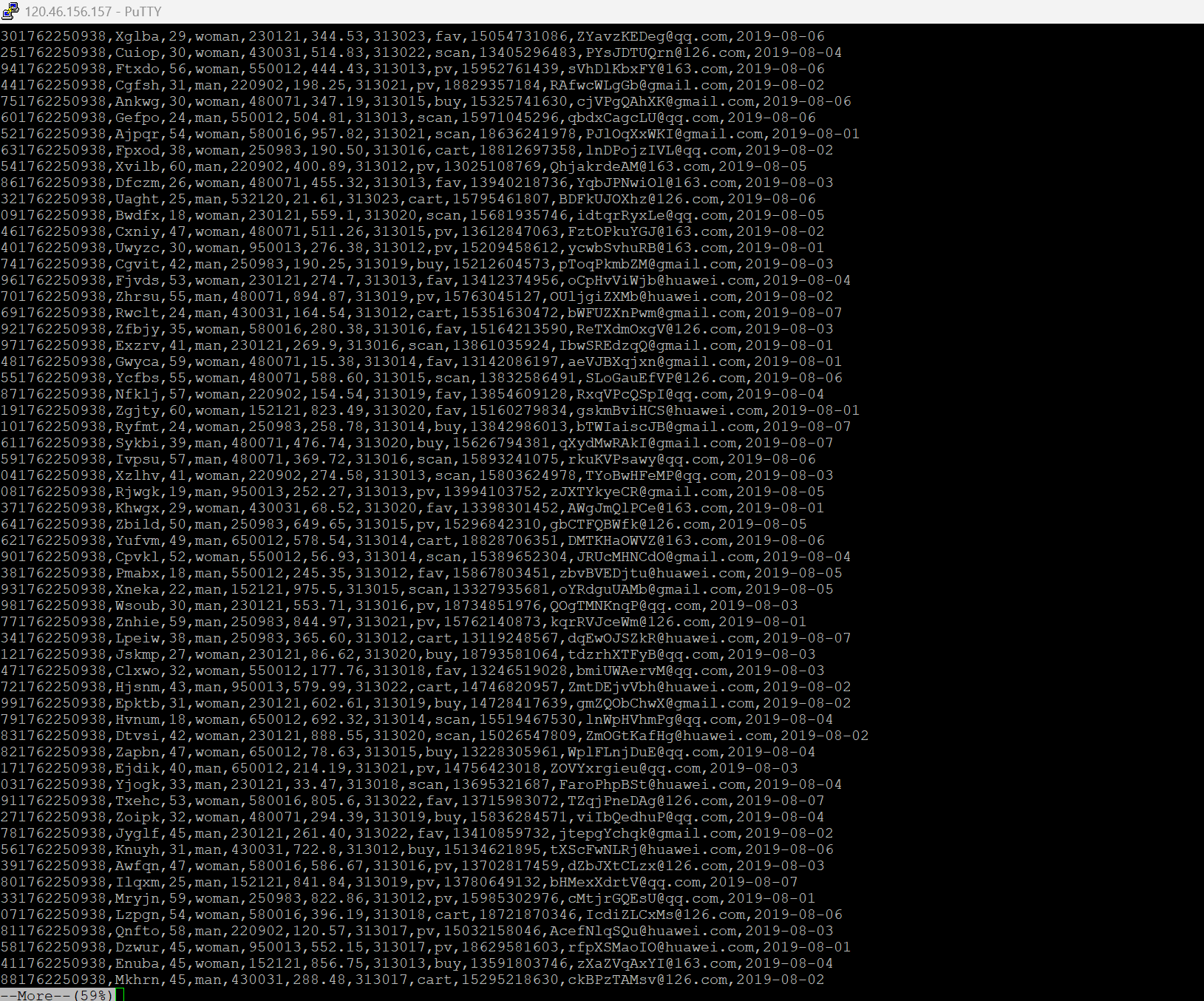
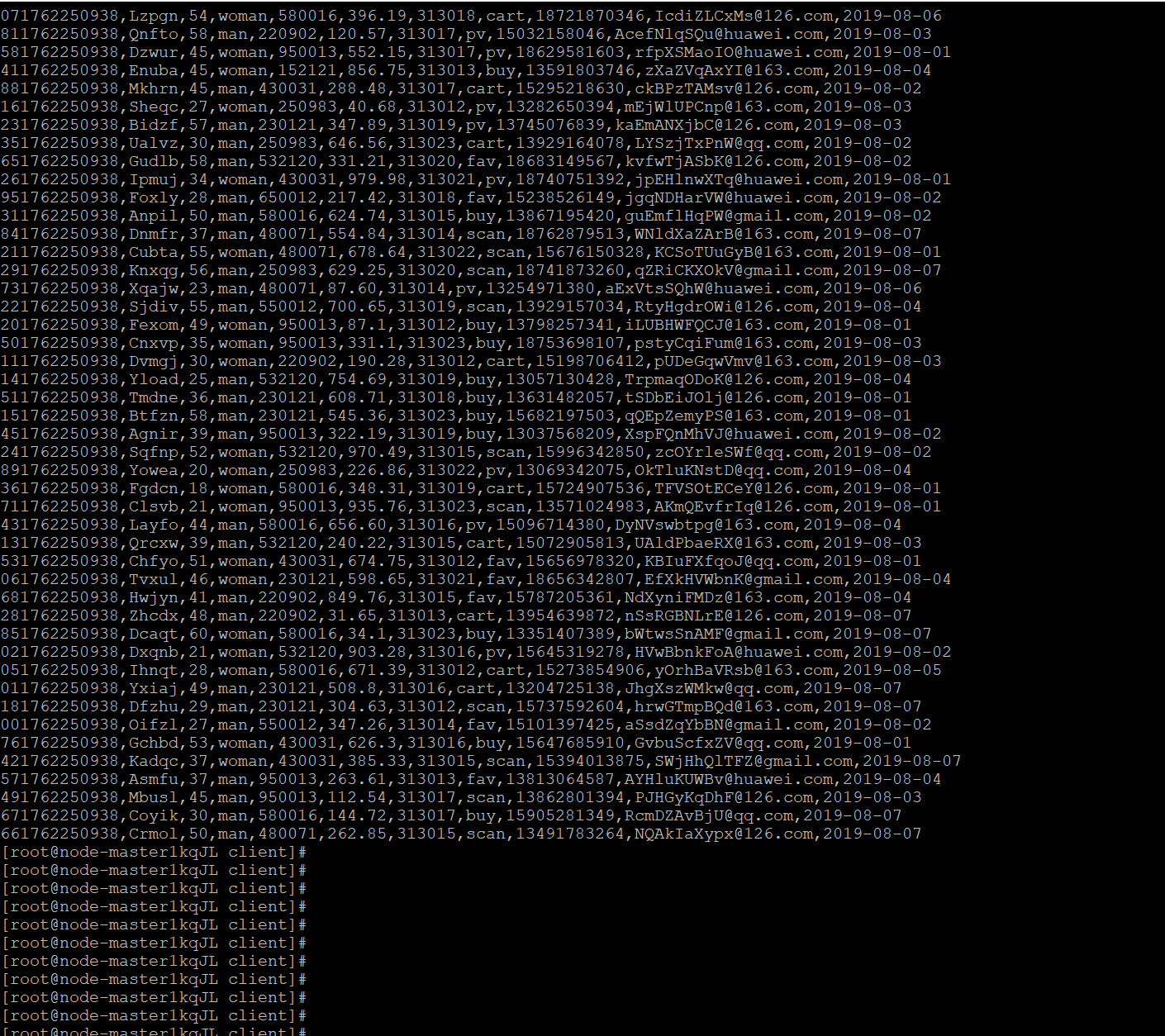
任务一:Python脚本生成测试数据
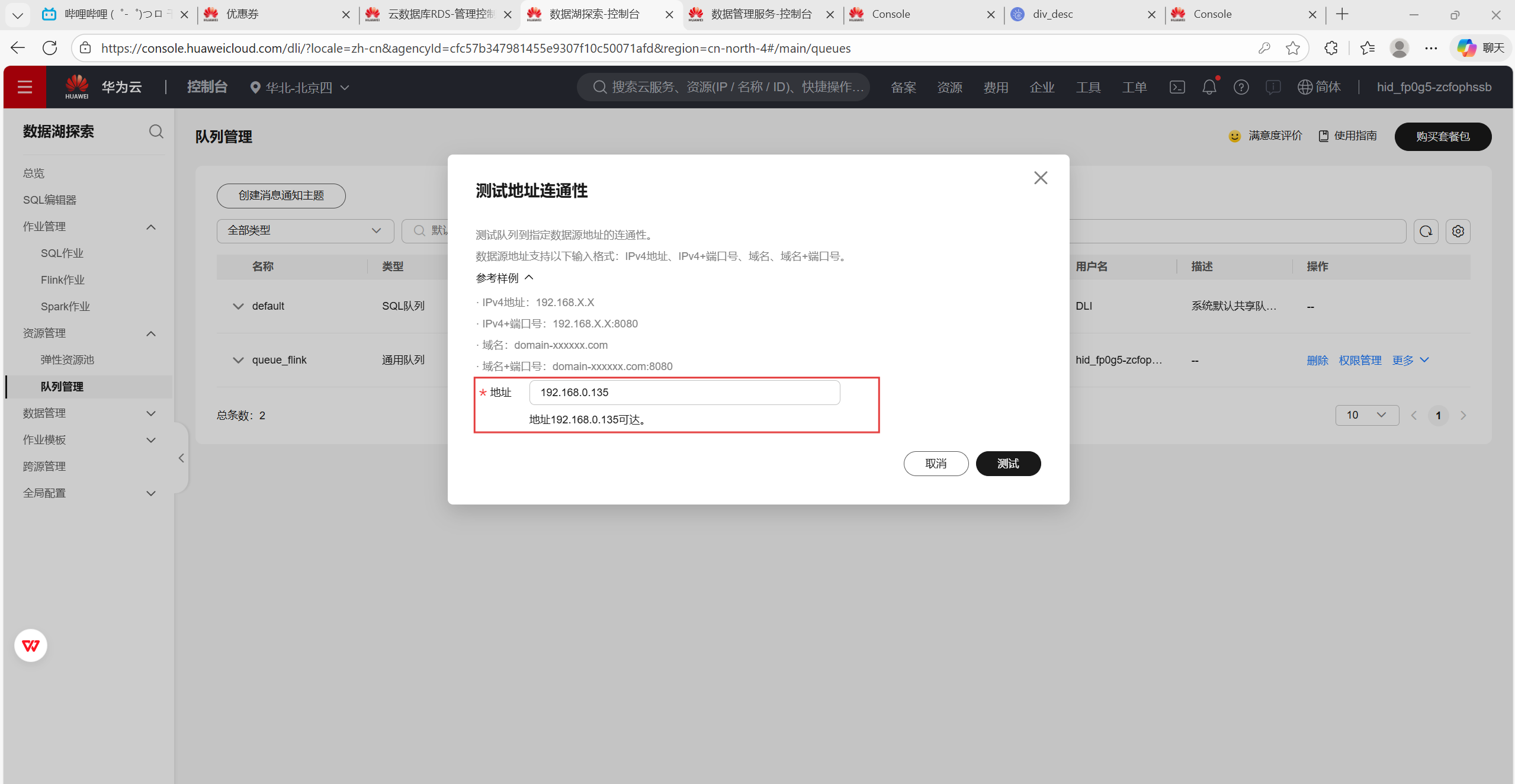
任务二:配置Kafka
kafka-topics.sh --create --topic fludesc --partitions 1 --replication-factor 1 --bootstrap-server 192.168.0.135 9092

任务三:安装Flume客户端

任务四:配置Flume采集数据
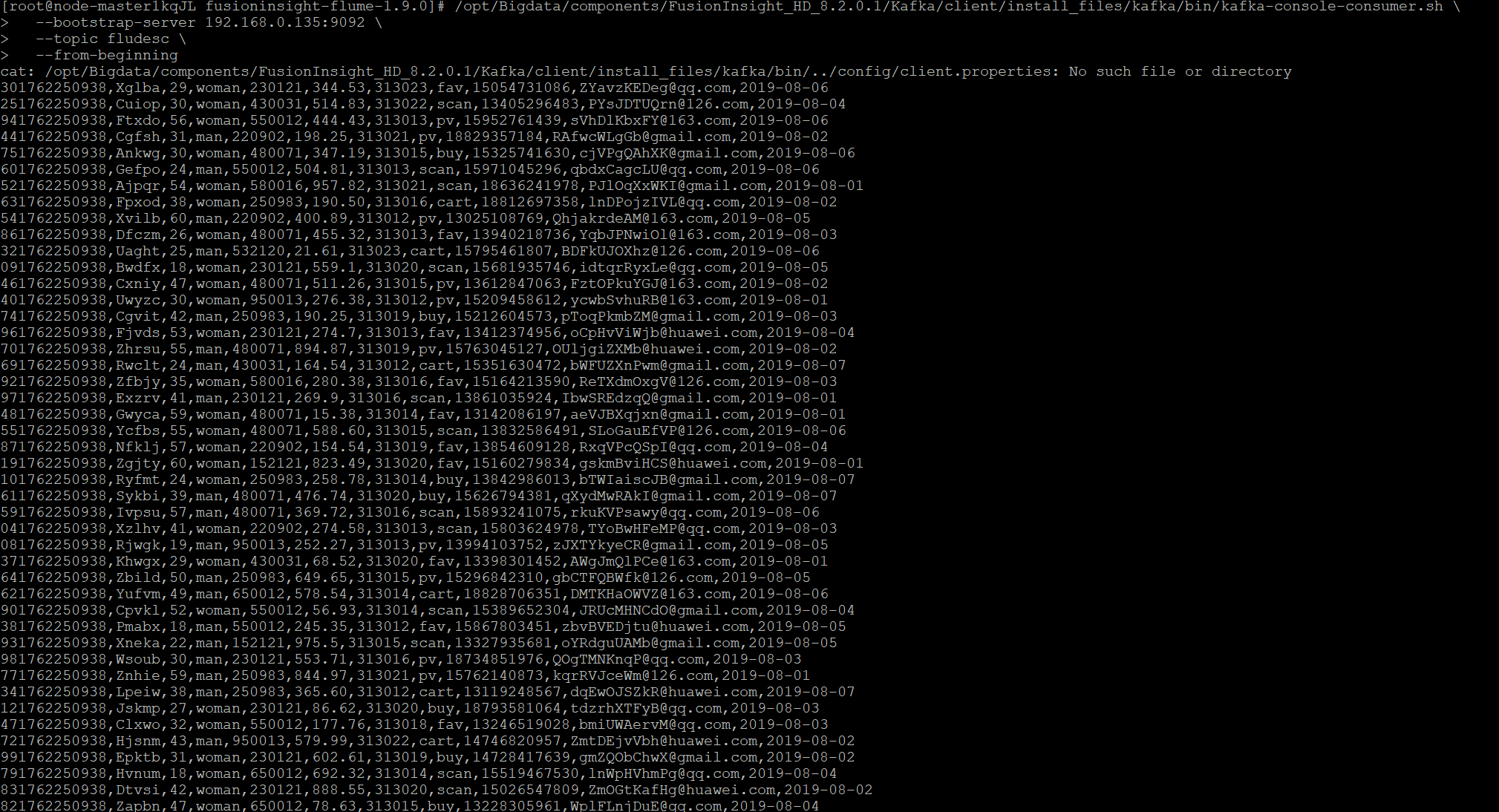
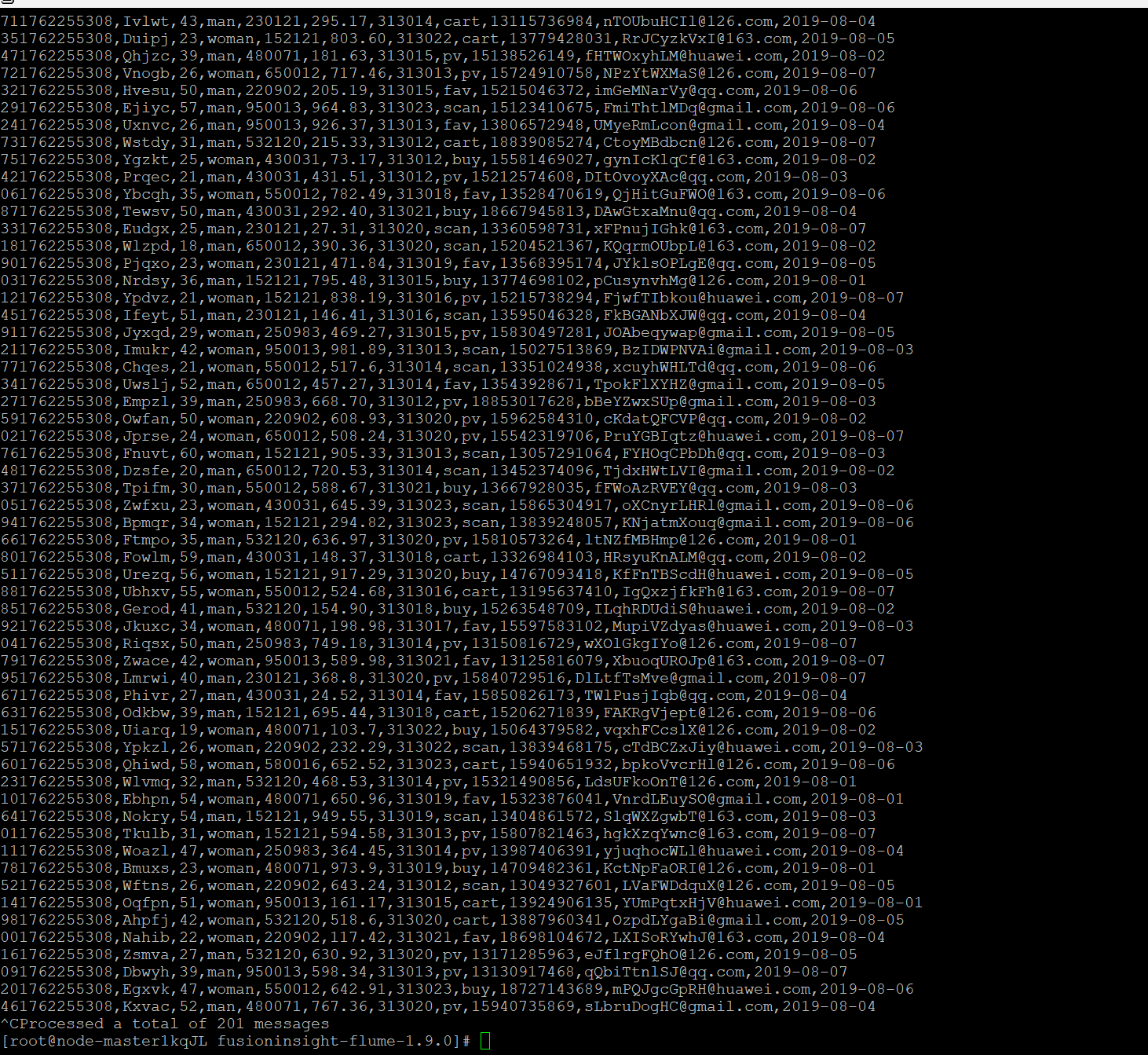
华为云平台相关结果:
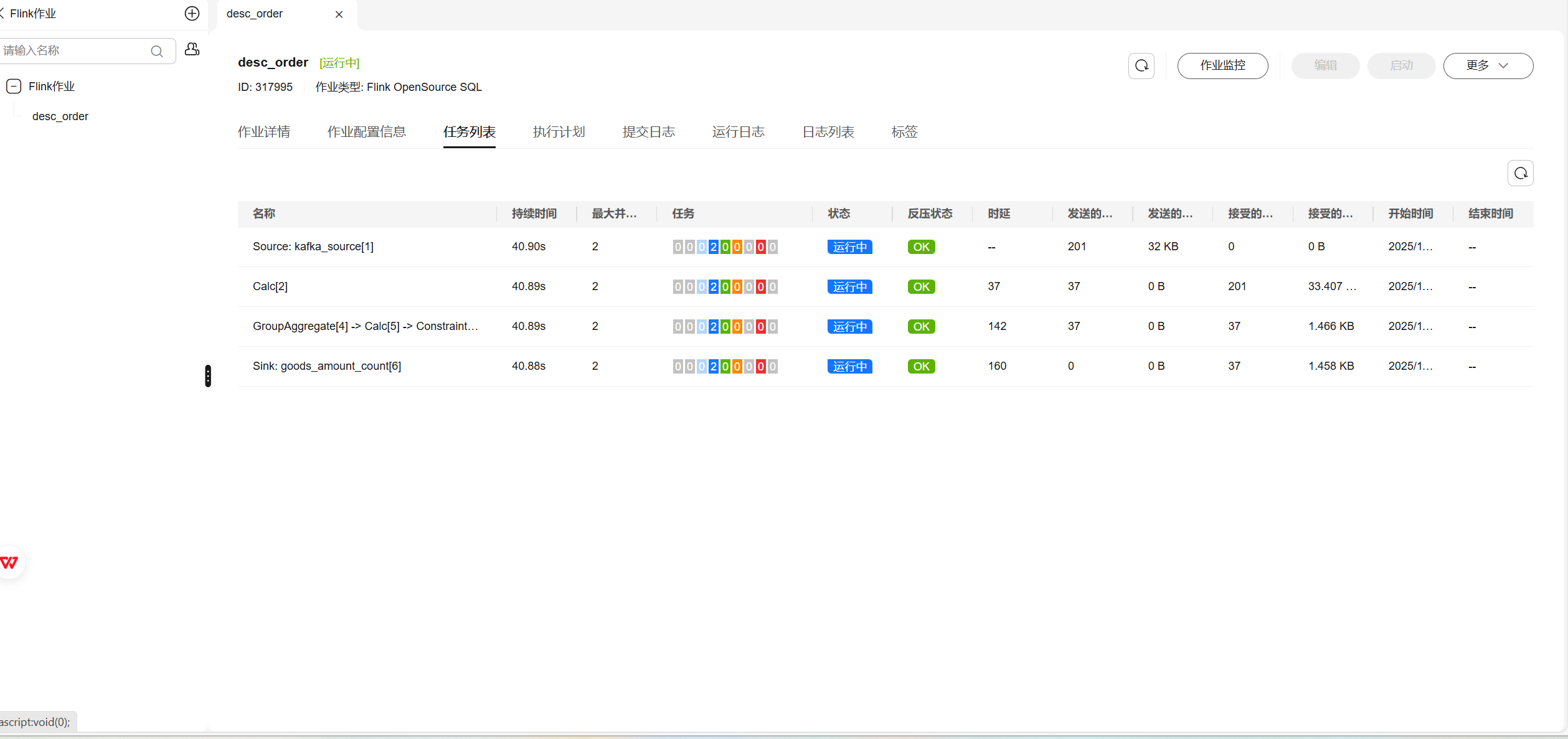
使用DLI中的Flink作业进行数据分析:
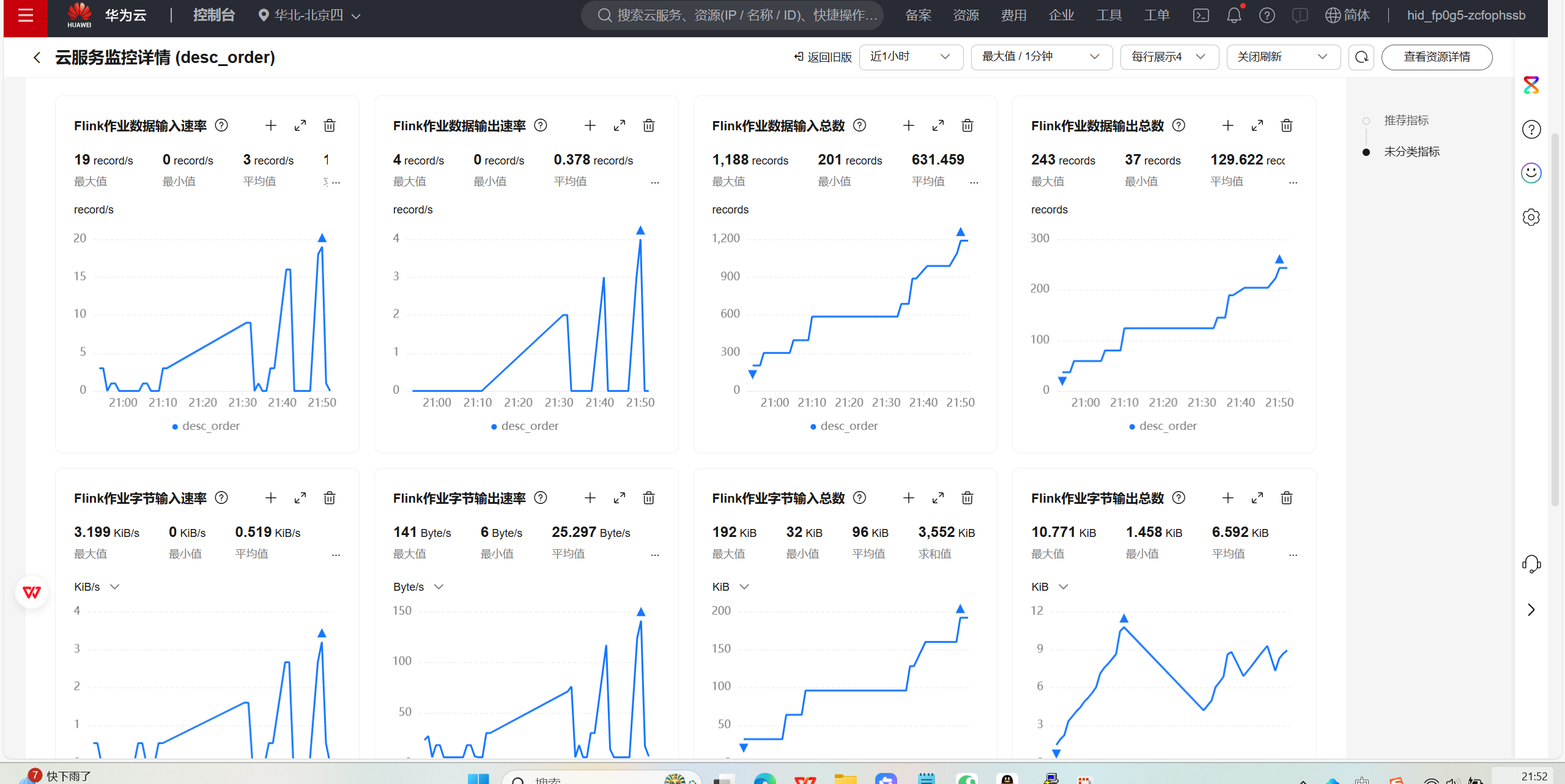
数据库结果:
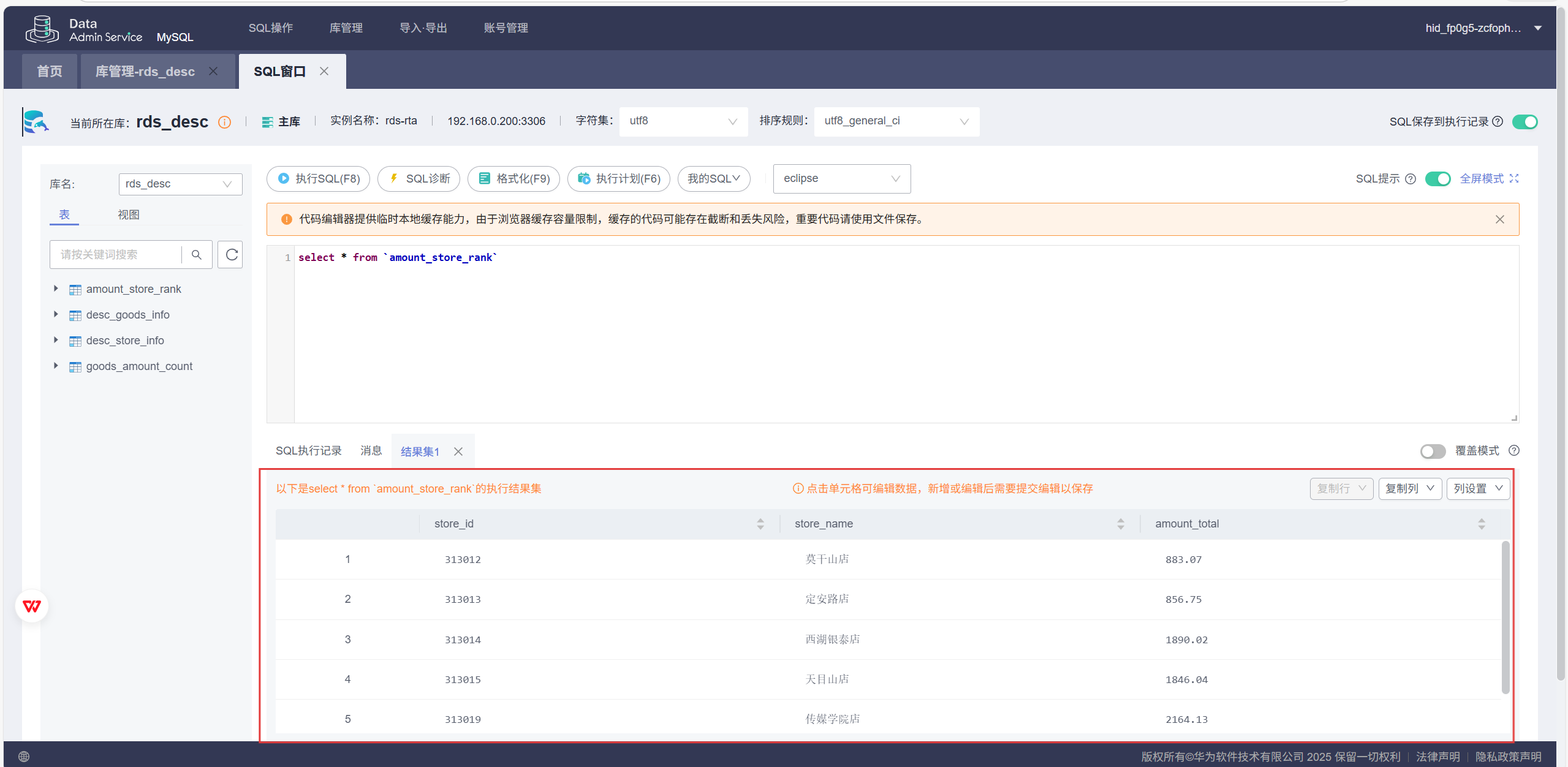
(2)心得体会:
本实验让我首次完整体验了“数据生成 → 实时采集 → 流式处理”的实时数仓链路。通过编写Python脚本模拟日志数据,利用Kafka作为消息队列缓冲,再通过Flume将数据采集至MRS集群,最后借助DLI中的Flink作业进行实时计算,整个流程环环相扣。我在配置Kafka时因路径问题和Flume版本不匹配遇到了小挫折,但通过查阅文档及时修正(如使用1.9.0版本Flume、指定绝对路径),提升了排错能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号