数据采集与融合综合作业
写在前面
这么快就到最后一次作业了,我不应该就此放下心爱的 bs4 re selenium 和不心爱的 scrapy,后面我想应该得重拾为了帮好朋友爬网易云做词云而去学 selenium 的学习热情继续加深爬虫技能吧!
学习历程主要就是作业的三大部分:从 bs4 + re ---> scrapy + xpath ---> selenium 系统性地学习了三种工具把原本东拼西凑的爬虫学习技能点满觉得蛮有成就感的欸!
每学一个新的库/框架都会觉得这个真香(刚开始 bs4 + re 天下第一,上一次 selenium 我的最爱),除了scrapy以外hhh
最后一次作业打完突然发现 bs4 稍微忘了一点呢,re 又忘了一点呢,scrapy 又忘了亿点点呢,selenium 倒是没忘。但是把各种工具结合起来用的感觉针不挫,会发现噢原来 bs4 还有这种用法,啊这 re
居然有 split 这个功能,认认真真的再用一次 scrapy 发现又多了一点理解,用起来又更顺手了些,selenium 找不到元素还有这几个原因啊,赶紧总结完进我的 onenote 吃灰吧(误
最后再把学过的都详细地总结一次吧!
作业链接:https://edu.cnblogs.com/campus/fzu/DataCollectionandFusionTechnology2020/homework/11551
第一题
-
代码思路:只使用 bs4 + re 来做这题绰绰有余,虽然心想着 selenium 真的会更快的吧!
用 request 发起请求后我想找 : (我要爬的东西在哪)AND(翻页在哪)
因为我不想每个都去点开然后获得详情,所以在列表面爬数据并把数据做了处理,意味着我的演员数据那部分不是完整数据(!)
知道数据在哪后我想知道我能不能提取到我想要的字段(可能不存在)
我接下来想存数据要用什么办法?
prettytable? no 看起来并没有什么用
数据库? no 不想写连接数据库函数
csv! yes 我可以用 pandas 复习一下我的 dataframe 的操作让我不至于以后拿到数据以后忘记基本的数据预处理的操作 -
结果

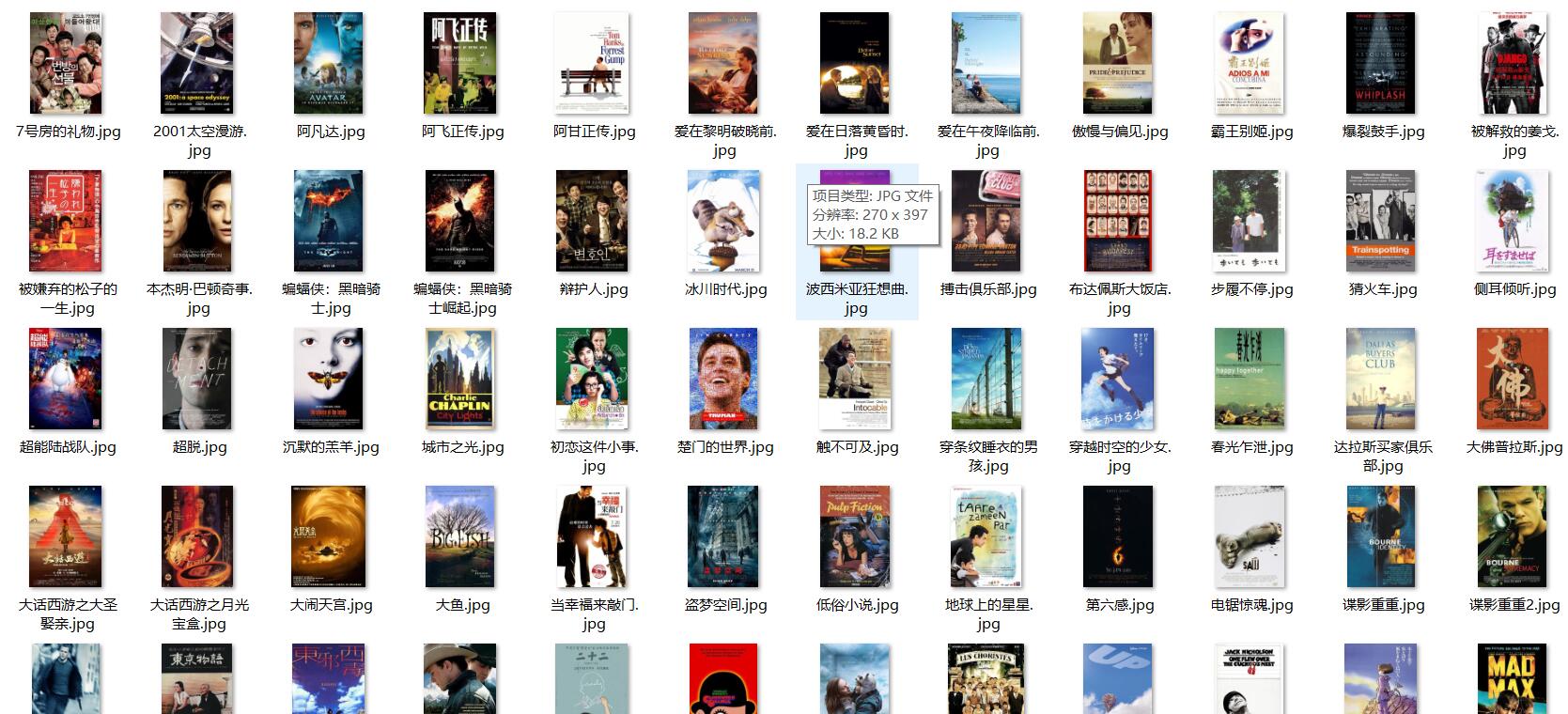
-
代码
import re
import requests
from bs4 import BeautifulSoup
import threading
import pandas as pd
import urllib.request
pd.set_option('display.max_columns',None)
pd.set_option('display.max_rows',None)
class Movie_Crawler():
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36 Edg/87.0.664.41"}
url = "https://movie.douban.com/top250?start=0&filter="
rank = 1
movie_data = pd.DataFrame(columns=["排名", "电影名称", "导演", "主演", "上映时间", "国家", "电影类型", "评分", "评价人数", "引用", "文件路径"])
columns = ["排名", "电影名称", "导演", "主演", "上映时间", "国家", "电影类型", "评分", "评价人数", "引用", "文件路径"] # table head
threads = []
offset = 0 # page offset for pages switch
def get_Movie_Data(self):
# usage : get movie_data in every page
try:
# you need to judge whether the data exists or not
html = requests.get(self.url,headers=self.headers).content
html = html.decode()
movie_bs = BeautifulSoup(html,"html.parser")
ol_tag = movie_bs.find("ol",{"class":"grid_view"})
li_list = ol_tag.find_all("li")
print(self.url)
for li in li_list:
movie_rank = self.rank
movie_name = li.find("span",{"class":"title"}).getText()
movie_details = li.find("div",{"class":"bd"}).find("p").getText().strip().split("\n")
movie_director_and_actors = movie_details[0].replace(u"\xa0",u"%")
movie_director_and_actors = re.split("%+",movie_director_and_actors)
movie_director = movie_director_and_actors[0].split(":")[1]
if (len(movie_director_and_actors) == 2):
if re.search(":",movie_director_and_actors[1]):
movie_actors = movie_director_and_actors[1].split(":")[1]
else:
movie_actors = ""
else:
movie_actors =""
movie_year_country_type = movie_details[1].strip().split("/")
movie_year = movie_year_country_type[0].replace(u"\xa0",u"")
movie_country = movie_year_country_type[1].replace(u"\xa0",u"")
movie_type = movie_year_country_type[2].replace(u"\xa0",u"")
movie_score = li.find("span",{"class":"rating_num"}).getText().strip()
movie_comments = re.search("\d+",li.find("div",{"class":"star"}).find_all("span")[3].getText().strip()).group()
if (li.find("span",{"class":"inq"})):
movie_quote = li.find("span",{"class":"inq"}).getText().strip()
else:
movie_quote = ""
movie_img = li.find("img",{"width":100})["src"]
movie_img_with_realname = movie_name + movie_img[len(movie_img)-4:]
# multiprocessing
T = threading.Thread(target=self.download_Image,args=(movie_img,movie_name))
T.setDaemon(False)
T.start()
self.threads.append(T)
# print(movie_rank,movie_name,movie_director,movie_actors,movie_year,movie_country,movie_type,movie_score,movie_comments,movie_quote,movie_img)
one_row = pd.DataFrame([[movie_rank,movie_name,movie_director,movie_actors,movie_year,movie_country,movie_type,movie_score,movie_comments,movie_quote,movie_img_with_realname]],columns=self.columns)
self.movie_data = self.movie_data.append(one_row)
self.rank += 1
except Exception as e:
print(e)
def download_Image(self,img_url,img_name):
# usage : download the img and write into filefolder
try:
if img_url[len(img_url)-4] == ".":
ext = img_url[len(img_url)-4:]
else:
ext = ""
req = urllib.request.Request(img_url,headers=self.headers)
data = urllib.request.urlopen(req,timeout=100).read()
fobj = open("./Image/" + img_name + ext,"wb")
fobj.write(data)
fobj.close()
except Exception as e:
print(e)
def start_Crawler(self):
# main
for idx in range(10):
self.get_Movie_Data()
for t in self.threads:
t.join()
self.offset += 25
self.url = "https://movie.douban.com/top250?start={:d}&filter=".format(self.offset)
self.movie_data.to_csv("movie_data.csv",index=0,encoding="utf_8_sig")
mc = Movie_Crawler()
mc.start_Crawler()
- 总结:
这题复习了一下 bs4 + re 的基本用法并加上了多线程以及 dataframe 的构建和导出生成 csv 文件,除了老套路以外收获了 re 的 split 用法。我觉得做的不够好的是提取字段那一块,应该在提取字段的同时判断字段是否存在,加上异常处理。
第二题
- 代码思路:这题我放在最后一题做了,因为 scrapy 忘得不少,所以先转战了第三题(上次就做的差不多hhh)
观察要爬取的页面后发现需要点进详情页才能爬到需要的信息
嗯我现在用的是 scrapy
所以我应该在 start_request 把需要的 URL 都先收集下来,这样才能一个个 callback parse (哇我居然理清楚了)
在 item 里把需要的字段写好
在 pipeline 里面把数据库连接好然后写好插入函数
在 parse 里面做需要字段的提取或者其他操作
在 setting 把需要的字段补上
突然喜欢上了 scrapy 好有条理噢
有个问题:为什么存入数据库以后不是按顺序,就算我查询语句用了 orderby 他还是无动于衷或者仍然无序?难道跟字段类型有关?我用的 varchar 没用 int 存,对该字段不能排序?
- 结果



由于有些学校并没有 info 这个字段所以数据库中会显示 None
- 代码
- 主函数
import scrapy
from bs4 import UnicodeDammit
from bs4 import BeautifulSoup
import requests
import urllib.request
import sys,os
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
from items import UniversityrankItem
class MySpider(scrapy.Spider):
name = "xrfspider"
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
front = "https://www.shanghairanking.cn"
hyperlinks = []
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36 Edg/87.0.664.41"}
cnt = 1
def start_requests(self):
# use bs4 to extract the main page of school
html = requests.get(self.url, headers=self.headers).content
html = html.decode()
school_soup = BeautifulSoup(html, "html.parser")
temp_record = school_soup.find("tbody").find_all("tr")
for record in temp_record:
school_link = record.find("a").attrs["href"]
self.hyperlinks.append(self.front + school_link)
for link in self.hyperlinks:
yield scrapy.Request(url=link,callback=self.parse)
def parse(self, response, **kwargs):
item = UniversityrankItem()
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
school_rank = self.cnt
item["sNO"] = school_rank
school_page = selector.xpath("//div[@class='univ-website']//a/@href").extract_first()
item["officialUrl"] = school_page
school_name = selector.xpath("//div[@class='univ-name']/text()").extract_first()
item["schoolName"] = school_name
school_region = selector.xpath("//div[@class='science-rank-text']/text()").extract()[1][:-2]
item["city"] = school_region
school_info = selector.xpath("//div[@class='univ-introduce']/p/text()").extract_first()
item["info"] = school_info
school_logo_link = selector.xpath("//td[@class='univ-logo']/img/@src").extract_first()
school_logo = str(self.cnt) + school_logo_link[-4:]
item["mFile"] = school_logo
yield item
self.download_Image(school_logo_link)
self.cnt += 1
print(school_rank,school_page,school_name,school_region,school_info,school_logo_link)
def download_Image(self,img_url):
try:
if img_url[len(img_url) - 4] == ".":
ext = img_url[len(img_url) - 4:]
else:
ext = ""
req = urllib.request.Request(img_url, headers=self.headers)
data = urllib.request.urlopen(req, timeout=100).read()
fobj = open("./Image/" + str(self.cnt) + ext, "wb")
fobj.write(data)
fobj.close()
except Exception as e:
print(e)
- item
import scrapy
class UniversityrankItem(scrapy.Item):
# define the fields for your item here like:
sNO = scrapy.Field()
schoolName = scrapy.Field()
city = scrapy.Field()
officialUrl = scrapy.Field()
info = scrapy.Field()
mFile = scrapy.Field()
pass
- pipeline
import pymssql
class UniversityrankPipeline:
def open_spider(self, spider):
try:
# connect my SQL SERVER but need to open TCP/IP interface (with cmd)
self.conn = pymssql.connect(host="localhost", user="sa", password="xrf5623641", database="xrfdb")
self.cursor = self.conn.cursor()
self.cursor.execute("delete from universities")
self.opened = True
self.count = 0
except Exception as e:
print(e)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.conn.commit()
self.conn.close()
self.opened = False
print("db close")
print("crawl data : " + str(self.count))
def process_item(self, item, spider):
if self.opened:
self.cursor.execute(
"insert into universities (sno,schoolname,city,officialurl,schoolinfo,mfile) VALUES (%s,%s,%s,%s,%s,%s)",(item["sNO"], item["schoolName"], item["city"], item["officialUrl"], item["info"],item["mFile"]))
self.count += 1
return item
settings需要把 robots 协议改成 false,并且启用pipeline
在主函数目录下使用: scrapy runspider xxx.py -s LOG_FILE=all.logs 查看运行结果这样可以把一大堆消息消掉,或者用 scrapy 的 cmdline 嵌入
scrapy 框架每部分要干嘛相信我不会忘记的,就不注释了!
- 总结
看到这题要用 scrapy 来做我有点不情愿,因为起初不是很喜欢这个框架,要写的东西太多了,为了总结一次妥协吧。如果一块块来设计其实并没有那么抗拒,我觉得他是一种很逻辑化的工具,当你知道每一步要干什么那你就可以找到那个位置并且写出来hhh(突然喜欢
第三题
-
代码思路
上一次作业的老题目了,对于上一次就实现的登录并不是很想赘述,在 window_handle 中的跳转也是常规技巧,只要把 xpath 运用熟练 selenium 就是最实用的工具
我先想我必须登录才能查看我学过的课程(就算点过也是学过因为我点过好多课程555) ---> 定位到要爬取的页面 ---> 页面跳转 ---> 写到数据库
最强大的工具往往能说的就越少,因为熟能生巧 -
结果

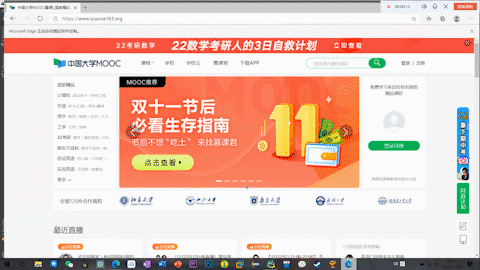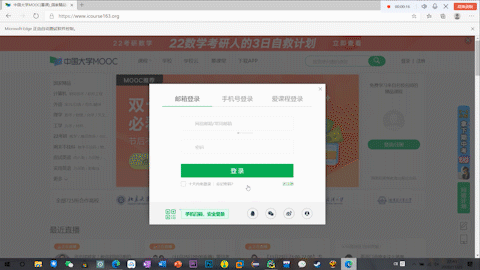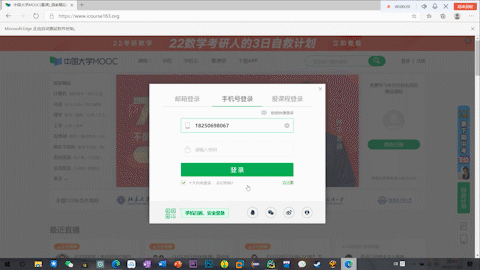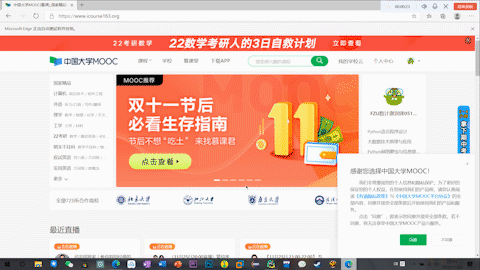
PR真是好东西hhhh,无压力转GIF,但是上传上来只能全损画质555
- 代码
import selenium
from selenium import webdriver
import pymssql
import time
class MyConsumingSpider():
driver = webdriver.Edge("C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver.exe")
url = "https://www.icourse163.org/"
cnt = 0
def login_and_go(self):
# usage : open the source page and login into your account then straight forward personal center
self.driver.get(self.url)
time.sleep(3)
self.driver.maximize_window()
self.driver.find_element_by_xpath("//a[@class='f-f0 navLoginBtn']").click() # choose login
time.sleep(2)
self.driver.find_element_by_xpath("//div[@class='ux-login-set-scan-code_ft']//span[@class='ux-login-set-scan-code_ft_back']").click() # choose other way
time.sleep(2)
self.driver.find_elements_by_xpath("//div[@class='ux-tabs-underline']//ul[@class='ux-tabs-underline_hd']//li")[1].click() # choose login with tel
time.sleep(2)
# when page have many iframes you need to use selenium with switch_to_iframe to go to the iframe what you want
temp_iframe_id = self.driver.find_elements_by_tag_name('iframe')[1].get_attribute('id') # choose iframe what you want
self.driver.switch_to_frame(temp_iframe_id)
# set username and password to login
self.driver.find_element_by_xpath("//input[@id='phoneipt']").send_keys("******")
time.sleep(1)
self.driver.find_element_by_xpath("//input[@class='j-inputtext dlemail']").send_keys("******")
time.sleep(0.5)
self.driver.find_element_by_xpath("//div[@class='f-cb loginbox']//a[@class='u-loginbtn btncolor tabfocus ']").click()
time.sleep(5)
self.driver.find_element_by_xpath("//div[@class='u-navLogin-myCourse-t']").click()
time.sleep(3)
def insert_data_into_DB(self):
# usage : select the course you learned and read the information you need
course_list = self.driver.find_elements_by_xpath("//div[@class='course-card-wrapper']")
for course in course_list:
course.click()
windows = self.driver.window_handles
self.driver.switch_to_window(windows[-1])
time.sleep(3)
self.driver.find_element_by_xpath("//div[@class='m-learnhead']//div[@class='f-fl info']//a[@hidefocus='true']").click()
time.sleep(3)
windows = self.driver.window_handles
self.driver.switch_to_window(windows[-1])
self.cnt += 1
name = self.driver.find_element_by_xpath("//span[@class='course-title f-ib f-vam']").text.strip()
person = self.driver.find_elements_by_xpath("//div[@class='um-list-slider_con_item']")
first_teacher = person[0].find_element_by_xpath("//div[@class='cnt f-fl']//h3[@class='f-fc3']").text.strip()
team_member = ""
for j in range(1, len(person)):
team_member += person[j].text.strip().split("\n")[0]
team_member += " "
hot = self.driver.find_element_by_xpath("//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text.strip()
note = self.driver.find_element_by_xpath("//div[@class='course-heading-intro_intro']").text.strip()
ntime = self.driver.find_element_by_xpath("//div[@class='course-enroll-info_course-info_term-info_term-time']").text.strip()
self.cursor.execute("insert into mooc (course_idx,course_name,course_teacher,course_team,course_hot,course_time,course_note) VALUES (%s,%s,%s,%s,%s,%s,%s)",(self.cnt, name, first_teacher, team_member, hot, ntime, note))
print(self.cnt, name, first_teacher, team_member, hot, note, ntime)
self.driver.close()
windows = self.driver.window_handles
self.driver.switch_to_window(windows[0])
time.sleep(1)
windows = self.driver.window_handles
for i in range(1,len(windows)):
self.driver.switch_to_window(windows[i])
time.sleep(0.5)
self.driver.close()
windows = self.driver.window_handles
self.driver.switch_to_window(windows[0])
def connect_to_SQLSERVER(self):
# usage : connect to DB
self.conn = pymssql.connect(host="localhost", user="sa", password="xrf5623641", database="xrfdb")
self.cursor = self.conn.cursor()
self.cursor.execute("delete from mooc")
def close_DB(self):
# usage : close your DB
self.conn.commit()
self.conn.close()
def start_my_spider(self):
# main
self.connect_to_SQLSERVER()
self.login_and_go()
for i in range(2):
self.insert_data_into_DB()
# turn to next page
self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']//a[@class='th-bk-main-gh']").click()
time.sleep(5)
self.close_DB()
ms = MyConsumingSpider().start_my_spider()
-
总结
selenium 最根本的是 xpath 的写法,加以页面跳转和元素等待的辅助,熟能生巧。如果说收获,想要获取元素就得把 xpath 写的完整具体才是最大的收获。 -
总结完了,学习这三部分的时候解决了无数的 bug,也许就是熟能生巧的必经之路吧 hhh,希望这篇博客能帮到以后的自己,和任何人~ whatever it takes

 浙公网安备 33010602011771号
浙公网安备 33010602011771号