数据采集与融合第五次个人作业
写在前面
这次的作业是比较有挑战性而且比较实用的,mooc 的那次作业很考验对 selenium 一些操作的熟悉程度,有很多坑要自己走过才会知道。但是打完这些项目之后会发现 selenium 这种自动化测试工具是永远的神。一个月前:bs4 + re 不香吗,xpath 什么玩意... 现在:selenium 天下第一!
第一题
第一题,京东的反爬很 low 所以领会一下题意,输入关键字直接开始爬就行,照着课件打,练练手。
-
结果
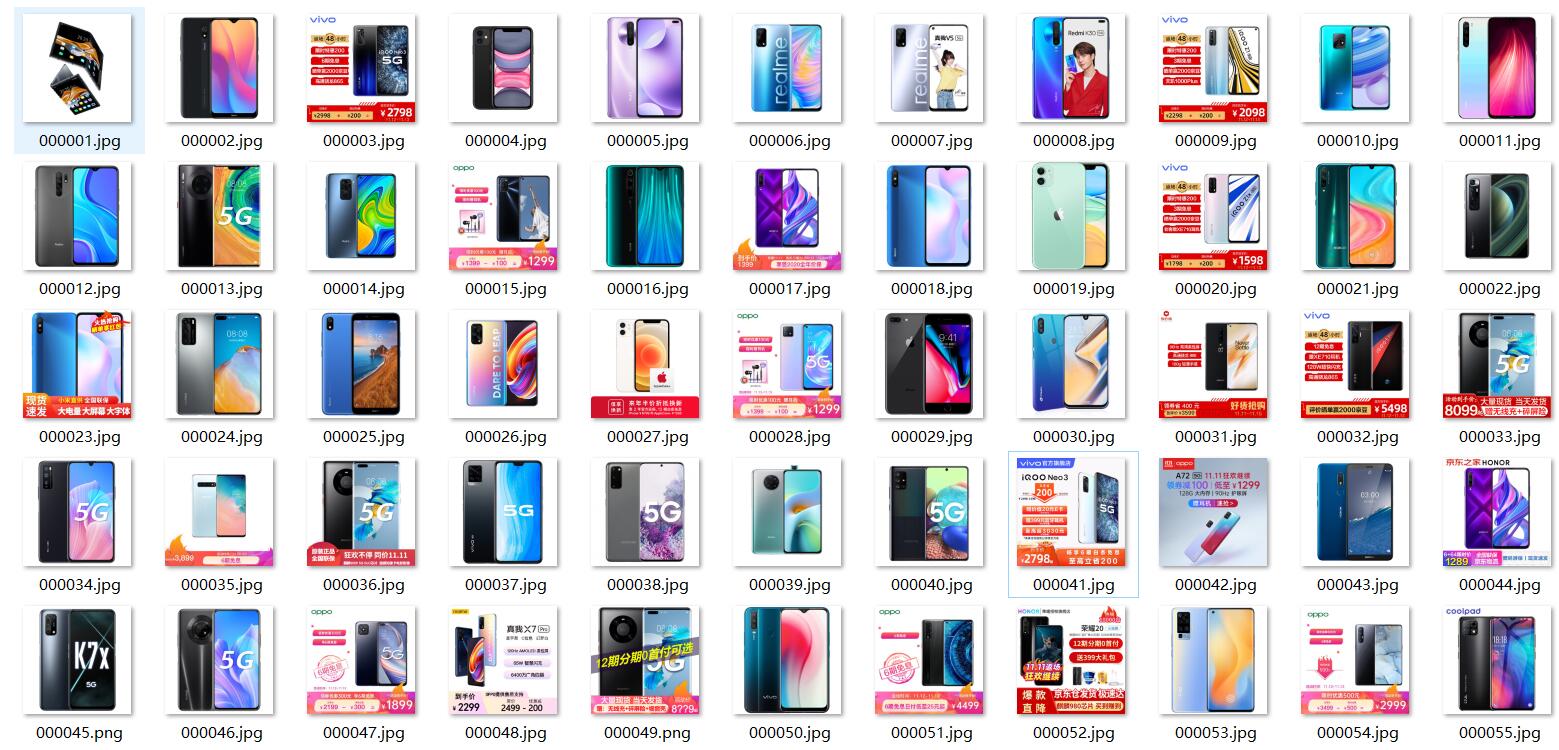
-
代码
import datetime
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import urllib.request
import threading
import sqlite3
import os
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
imagePath = "download"
def startUp(self, url, key):
self.driver = webdriver.Edge("C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver.exe")
self.threads = []
self.No = 0
self.imgNo = 0
try:
self.con = sqlite3.connect("phones.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table phones")
except:
pass
try:
sql = "create table phones (mNo varchar(32) primary key, mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as e1:
print(e1)
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as e2:
print(e2)
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print("err2")
def insertDB(self, mNo, mMark, mPrice, mNote, mFile):
try:
sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (?,?,?,?,?)"
self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile))
except Exception as e3:
print(e3)
def showDB(self):
try:
con = sqlite3.connect("phones.db")
cursor = con.cursor()
print("%-8s%-16s%-8s%-16s%s" % ("No", "Mark", "Price", "Image", "Note"))
cursor.execute("select mNo,mMark,mPrice,mFile,mNote from phones order by mNo")
rows = cursor.fetchall()
for row in rows:
print("%-8s %-16s %-8s %-16s %s" % (row[0], row[1], row[2], row[3], row[4]))
con.close()
except Exception as err:
print(err)
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
lis = self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
self.insertDB(no, mark, price, note, mFile)
try:
self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
except:
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(10)
nextPage.click()
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url, key)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
for t in self.threads:
t.join()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "http://www.jd.com"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url, "手机")
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break
第二题
第二题还是比较简单的,其实在上次作业就已经用 selenium 实现过了,算是对第三题开始前的一个练手。
-
先贴一下数据库里的结果

-
代码如下
import selenium
from selenium import webdriver
import pymssql
import time
class stock_pack():
def initialize(self):
self.conn = pymssql.connect(host="localhost", user="sa", password="xrf5623641", database="xrfdb")
self.cursor = self.conn.cursor()
self.cursor.execute("delete from stocks")
driver = webdriver.Edge("C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver.exe")
self.get_data(driver,self.cursor)
self.conn.commit()
self.conn.close()
def insertdata(self,code, name, newest_price, up_down_extent, up_down_value, deal_volume, deal_value, freq, highest, lowest,
opening, over):
try:
self.cursor.execute(
"insert into stocks (stockcode,stockname,stocknp,stockude,stockudv,stockdv1,stockdv2,stockfreq,stockhighest,stocklowest,stockopening,stockover) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(code, name, newest_price, up_down_extent, up_down_value, deal_volume, deal_value, freq, highest, lowest,
opening, over))
except Exception as e:
print(e)
def get_data(self,driver,cursor):
driver.get("http://quote.eastmoney.com/center/gridlist.html#hs_a_board")
try:
for cnt in range(5):
tr_list = driver.find_elements_by_xpath("//div[@class='listview full']/table[@class='table_wrapper-table']/tbody/tr")
for tr in tr_list:
tr_val = tr.text.split(" ")
code = tr_val[1]
name = tr_val[2]
newest_price = tr_val[6]
up_down_extent = tr_val[7]
up_down_value = tr_val[8]
deal_volume = tr_val[9]
deal_value = tr_val[10]
freq = tr_val[11]
highest = tr_val[12]
lowest = tr_val[13]
opening = tr_val[14]
over = tr_val[15]
self.insertdata(code,name,newest_price,up_down_extent,up_down_value,deal_volume,deal_value,freq,highest,lowest,opening,over)
# go to next page
driver.find_elements_by_xpath("//a[@class='next paginate_button']")[-1].click()
time.sleep(5)
except Exception as e:
print(e)
instance = stock_pack().initialize()
- 代码思路
所有的题目代码思路都很简单:就是找到想要的数据到底在哪,然后一步步接近就可以了,很明显这个题目我们需要的数据在一个表格中,只要看懂表格的 HTML 源码那么这些数据就是手到擒来的。这次的作业就是在上次我提交的作业的基础上用类进行了封装,其他功能基本一致。
第三题
第三题很考验对 selenium 的掌握,不仅仅是考察 xpath ,还考察 selenium 中对 driver 的页面跳转的理解。
-
代码思路
根据题目要求需要先进行登录,然后输入关键词进行搜索,在从课程列表中爬取出想要的信息。所以代码的编写也是分为这三步,第一步登录比较简单,其实就是对 xpath 的简单考察,找到相应的元素来写 xpath 即可。但是呢这个地方有个坑,就是 selenium 不能在不同的 frame 里跳转,需要手动来找到需要爬取的信息在哪个 frame 然后跳转;第二步就是找到搜索栏输入关键字也是对 xpath 的考察;第三步爬取相应信息除了对 xpath 的考察外还需要使 driver 在不同的标签页进行跳转,需要自己踩坑。 -
代码运行流程
本代码的运行流程是打开 mooc 的网站然后先关闭弹窗(弹窗可能已经消失,只需要把login函数中关闭弹窗的语句注释掉即可),寻找登录框,点击用手机号登录,自动输入手机和密码,自动在搜索框输入关键词,搜索之后点击列表里每个项爬取信息,翻页,重复爬取,之后存入数据库,啊哈一气呵成~
-
先上运行结果,把爬到的信息先输出了

-
再贴一下数据库中的结果
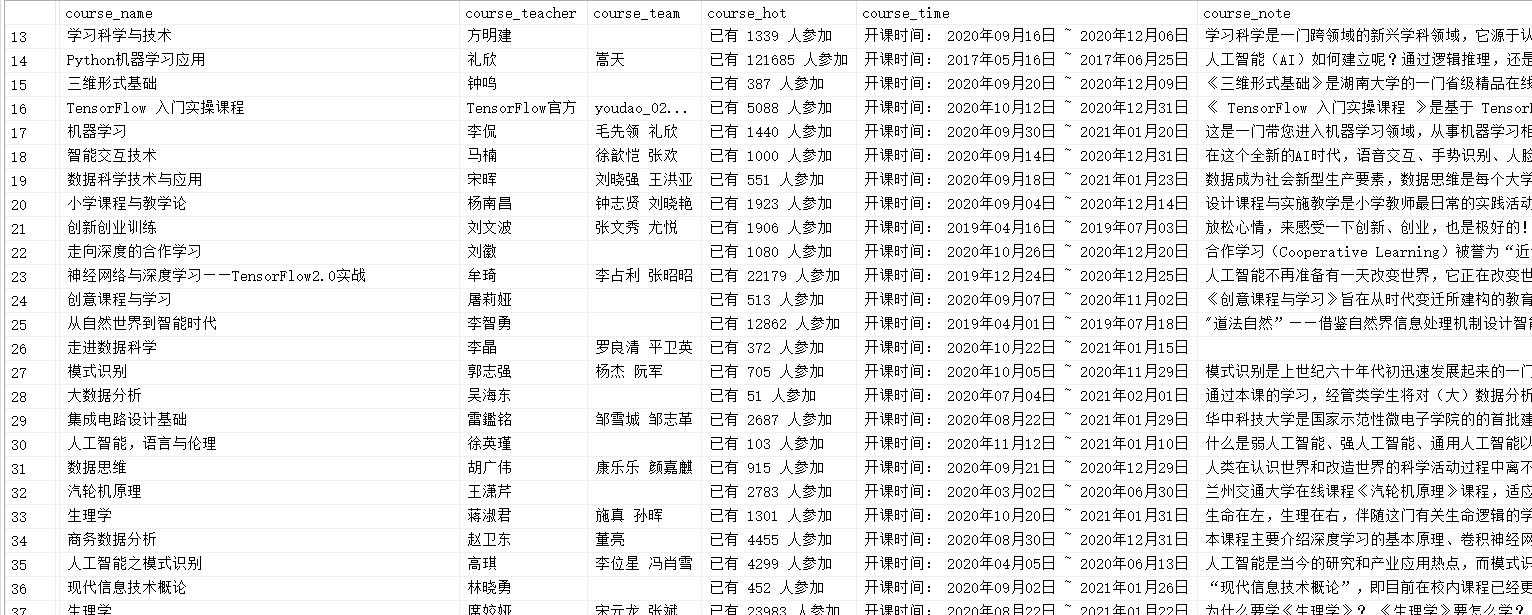
-
源代码:
import selenium
from selenium import webdriver
import pymssql
import time
class MyConsumingSpider():
driver = webdriver.Edge("C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver.exe")
url = "https://www.icourse163.org/"
# you can change your keyword,it should work normally
keyword = "深度学习"
cnt = 0
def login_and_go(self):
# usage : open the source page and login into your account then search with keyword
self.driver.get(self.url)
self.driver.maximize_window()
time.sleep(2)
# close the evil popup,but it may not show up
self.driver.find_element_by_xpath("//i[@class='ux-icon ux-icon-close']").click()
self.driver.find_element_by_xpath("//a[@class='f-f0 navLoginBtn']").click() # choose login
time.sleep(2)
self.driver.find_element_by_xpath("//div[@class='ux-login-set-scan-code_ft']//span[@class='ux-login-set-scan-code_ft_back']").click() # choose other way
time.sleep(2)
self.driver.find_elements_by_xpath("//div[@class='ux-tabs-underline']//ul[@class='ux-tabs-underline_hd']//li")[1].click() # choose login with tel
time.sleep(2)
# when page have many iframes you need to use selenium with switch_to_iframe to go to the iframe what you want
temp_iframe_id = self.driver.find_elements_by_tag_name('iframe')[1].get_attribute('id') # choose iframe what you want
self.driver.switch_to_frame(temp_iframe_id)
# set username and password to login
self.driver.find_element_by_xpath("//input[@id='phoneipt']").send_keys("******")
time.sleep(1)
self.driver.find_element_by_xpath("//input[@class='j-inputtext dlemail']").send_keys("******")
time.sleep(0.5)
self.driver.find_element_by_xpath("//div[@class='f-cb loginbox']//a[@class='u-loginbtn btncolor tabfocus ']").click()
time.sleep(5)
# search with keyword
self.driver.find_element_by_xpath("//div[@class='u-baseinputui']//input[@name='search']").send_keys(self.keyword)
time.sleep(1)
self.driver.find_element_by_xpath("//span[@class='u-icon-search2 j-searchBtn']").click()
time.sleep(3)
def insert_data_into_DB(self):
# usage : find the element we need and insert into your DB
res = self.driver.find_elements_by_xpath("//div[@id='j-courseCardListBox']//div[@class='m-course-list']//div//div[@class='u-clist f-bgw f-cb f-pr j-href ga-click']")
# when you click other page,dont forget to use window_switch to change your new page,otherwise you will turn around in your primitive page! f**king bug again!
for r in res:
# open the pages we need in advance
r.click()
time.sleep(1)
window = self.driver.window_handles
for i in range(len(window)):
if (i != len(window) - 1): # should not be our main_page
# extract parameter
self.cnt += 1
self.driver.switch_to_window(window[len(window) - i - 1])
time.sleep(3)
name = self.driver.find_element_by_xpath("//span[@class='course-title f-ib f-vam']").text.strip()
person = self.driver.find_elements_by_xpath("//div[@class='um-list-slider_con_item']")
first_teacher = person[0].find_element_by_xpath("//div[@class='cnt f-fl']//h3[@class='f-fc3']").text.strip()
team_member = ""
for j in range(1, len(person)):
team_member += person[j].text.strip().split("\n")[0]
team_member += " "
hot = self.driver.find_element_by_xpath("//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text.strip()
note = self.driver.find_element_by_xpath("//div[@class='course-heading-intro_intro']").text.strip()
ntime = self.driver.find_element_by_xpath("//div[@class='course-enroll-info_course-info_term-info_term-time']").text.strip()
self.cursor.execute("insert into mooc (course_idx,course_name,course_teacher,course_team,course_hot,course_time,course_note) VALUES (%s,%s,%s,%s,%s,%s,%s)",(self.cnt,name,first_teacher,team_member,hot,ntime,note))
print(self.cnt,name, first_teacher, team_member, hot, ntime, note)
# switch among your pages
for i in range(1,len(window)):
self.driver.switch_to_window(window[i])
time.sleep(0.5)
self.driver.close()
# back to main_page and prepare to turn to next page
window = self.driver.window_handles
self.driver.switch_to_window(window[-1])
def connect_to_SQLSERVER(self):
# usage : connect to DB
self.conn = pymssql.connect(host="localhost", user="sa", password="******", database="xrfdb")
self.cursor = self.conn.cursor()
self.cursor.execute("delete from mooc")
def close_DB(self):
# usage : close your DB
self.conn.commit()
self.conn.close()
def start_my_spider(self):
# main
self.connect_to_SQLSERVER()
self.login_and_go()
for i in range(3):
self.insert_data_into_DB()
# turn to next page
self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']//a[@class='th-bk-main-gh']").click()
time.sleep(5)
self.close_DB()
ms = MyConsumingSpider().start_my_spider()
-
总结
这个 mooc 项目的代码量其实不大,但是自己做的有点久,是因为之前不想在列表中点击每个课程去获取它的详情信息,直接在课程列表页面做然后在那个页面翻页(说白了就是懒/(ㄒoㄒ)/~~),但是做着做着发现最后一个需要的字段找不到,还得点进去课程详情找信息,就又重写了一遍主干部分,增加了许多奇奇怪怪的知识,所以对于 selenium 这种自动化测试工具确实有必要花时间来试试毒(ง •_•)ง。
所以这个项目的第一个收获是深入了解了 xpath 的写法,以及 selenium 内置的一些自动化测试的函数以及工作原理,并且加深了对数据库存取和读写操作的认识,知道了要完整的从一个页面来爬取信息需要经历的步骤。
第二个收获是从这个项目中解决了一个之前未解决的问题,之前做过用 selenium 来爬取网抑云评论制作词云,由于网易云的翻页是在单页面加载的,难度其实比这个作业要小,当时卡在了翻页,从这次作业中完美解决,算是一箭双雕吧~ -
关于代码
一个完整的代码需要经过多次的测试和修改,比如我昨晚刚写完今天来跑突然跑不动了,找了下原因发现是因为今天 mooc 网站在首页给爷加了个弹窗,导致无法自动点击登录按钮,所以就得不断补充代码来维护原有代码(但是过一两天弹窗又会消失)。其次我的代码还有一个较大的缺陷就是没有使用 try-except 来捕捉异常,这是不可取的,有时间再继续添加叭~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号