数据采集与融合第二次个人作业
第一题
作业思路:
-
步骤一:看懂网页源码
-
步骤二:用 css 语法把需要的数据提出来
-
步骤三:存入数据库
-
运行结果:

-
相关代码:
from bs4 import BeautifulSoup
import urllib
import requests
import sqlite3
from bs4 import UnicodeDammit
class WeatherDB():
'''
openDB : create a database
closeDB : close database
insert : insert record into database
show : present infomation in database
'''
def openDB(self):
self.connect = sqlite3.connect("weather.db")
self.cursor = self.connect.cursor()
try:
self.connect.execute("create table weathers (wCity VARCHAR(16),wDate VARCHAR(16),wWeather VARCHAR(64),wTemp VARCHAR(32),CONSTRAINT ds_weather PRIMARY KEY (wCity,wDate))")
except:
self.cursor.execute("DELETE FROM weathers")
def closeDB(self):
self.connect.commit()
self.connect.close()
def insert(self,city,date,weather,temp):
try:
self.connect.execute("insert into weathers (wCity,wDate,wWeather,wTemp) VALUES(?,?,?,?)",(city,date,weather,temp))
except Exception as e:
print(e)
def show(self):
self.connect.execute("select * from weathers")
records = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s%"%("city","date","weather","temp"))
for record in records:
print("%-16s%-16s%-32s%-16s%"%(record[0],record[1],record[2],record[3]))
class WeatherForecast():
'''
forecastCity : forecast weekly weather of given cities
process : action
'''
def __init__(self):
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63"}
self.citycode = {"东山":"101230608","厦门":"101230201","福州":"101230101"}
def forcastCity(self,city):
if city not in self.citycode.keys():
print(city + " code is not exist")
return
url = "http://www.weather.com.cn/weather/" + self.citycode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
data = data.decode()
soup = BeautifulSoup(data, "html.parser")
li_list = soup.select("ul[class = 't clearfix'] li")
print("城市 日期 天气 温度")
# select the weather we need
for li in li_list:
try:
date = li.select("h1")[0].text
weather = li.select("p[class = 'wea']")[0].text
temp = li.select("p[class = 'tem'] span")[0].text + "/" + li.select("p[class = 'tem'] i")[0].text
print(city + " " + date + " " + weather + " " + temp)
self.db.insert(city,date,weather,temp)
except Exception as ee:
print(ee)
except Exception as e:
print(e)
def process(self,cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forcastCity(city)
self.db.closeDB()
ws = WeatherForecast()
ws.process(["东山","厦门","福州"])
- 作业心得
本次作业主要的收获是用 css 语法从网页中挑出我们需要的数据之后存入数据库,至少了解了框架是这样子写的~
第二题
- 作业思路:
拿到题目第一反应先用 bs 把想要的数据爬下来,但是会发现其实数据都是用 JS 动态加载的,所以赶紧打开 network 模块,找到需要的信息对应下的 JS 文件发现了这个大兄弟就存储了我们想要的数据。
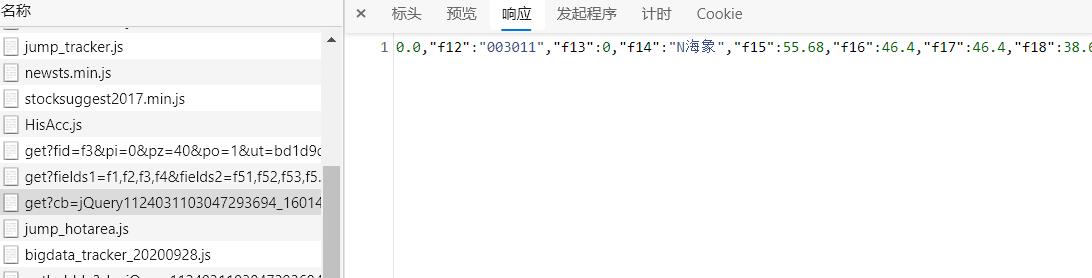
(爬虫做多了会发现一般jQuery里面会放着我们想要的数据xixixi~)
好的现在我们已经知道了这个 JS 那就赶紧用 request 让他给爷爬过来,解码之后得到 JS 里面 Json 的内容,但是得到的是字符串,那就构成字典之后可以方便的提取相关的字段啦~
然后翻页也是非常简单的,只要点击下一页的按钮并且在 network 模块中找一下从前一页都后一页的 request url 发生了什么变化。可以发现仅仅只是 request url 中的 pn 发生了变化,所以只要对 pn 进行修改就可以实现翻页了。
既然爬取了辣么多的数据,在不用数据库存储的情况下我就比较喜欢用,也是比较通用的就是把数据存成 csv 文件格式,打开查看一目了然,接下来附上代码结果(爬了四页一共80条,就不全部展示了)~
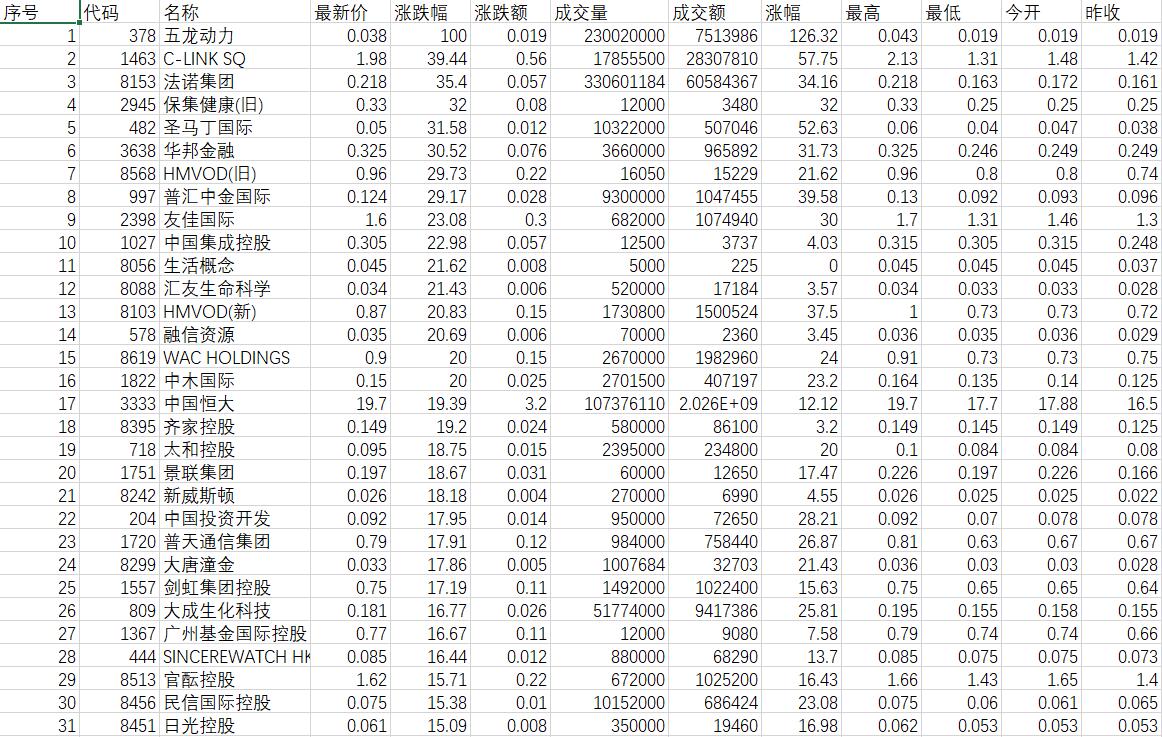
- 附上代码:
import requests
import re
import pandas as pd
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63"}
def get_Info_And_Save(url,offset):
all_data = pd.DataFrame(columns=["序号", "代码", "名称", "最新价", "涨跌幅", "涨跌额", "成交量","成交额", "涨幅"])
try:
html = requests.get(url,headers = headers).content.decode(encoding="utf-8")
res = re.findall(re.compile("\[(.+)\]"),html)[0]
res = res.split("},") # split by } , but need to fix
# print("序号 代码 名称 最新价 涨跌幅 涨跌额 成交量(股) 成交额(港元) 涨幅 ")
for idx,info in enumerate(res):
if idx != 19:# reach 19 dont add }
info = info + "}" # make a complete dict
info = eval(info) # construct a dict
id = idx + 1 + offset
code = info["f12"]
name = info["f14"]
newest_price = info["f2"]
up_down_extent = info["f3"]
up_down_value = info["f4"]
deal_volume = info["f5"]
deal_value = info["f6"]
freq = info["f7"]
# print(str(id) + " " + str(code) + " " + str(name) + " " + str(newest_price) + " " + str(up_down_extent) + " " + str(up_down_value) + " " + str(deal_volume)\
# + " " + str(deal_value) + " " + str(freq))
data = pd.DataFrame([id,code,name,newest_price,up_down_extent,up_down_value,deal_volume,deal_value,freq])
new_data = pd.DataFrame(data.values.T,columns=None)
new_data.columns = ["序号", "代码", "名称", "最新价", "涨跌幅", "涨跌额", "成交量","成交额", "涨幅"]
all_data = all_data.append(new_data)
return all_data
except Exception as e:
print(e)
def go_To_NextPage():
stock_data = pd.DataFrame(columns=["序号", "代码", "名称", "最新价", "涨跌幅", "涨跌额", "成交量", "成交额", "涨幅"])
for idx in range(1,5):
# compare different pages,find parameter "fn" will change autonomously
url = "http://31.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240033772650735816256_1601427948453&pn={:,d}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:128+t:3,m:128+t:4,m:128+t:1,m:128+t:2&\
fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f19,f20,f21,f23,f24,f25,f26,f22,f33,f11,f62,f128,f136,f115,f152&_=1601427948454".format(idx)
info = get_Info_And_Save(url,20*(idx-1))
stock_data = stock_data.append(info)
stock_data.to_csv("stock_info.csv",index=False,encoding="utf-8-sig")
go_To_NextPage()
- 作业心得
第二题和第三题都是一样的,当网页的数据通过 JS 来动态加载的时候必须要去解析相应的 JS 来获取数据。
第三题
-
作业思路:
既然有了第一题的思路,那么第二题也就势如破竹了,同样需要找出特定信息所在的 JS。但是又必须多加一步,就是以学号后三位结尾并且加上任意的前三位,那么可以在搜索页那里先找出所有的以学号后三位结尾的股票代码,然后后面再来调用之前的做法删删补补就 OK 了。 -
在搜索页中找到需要的 json ,提取对应的股票代码
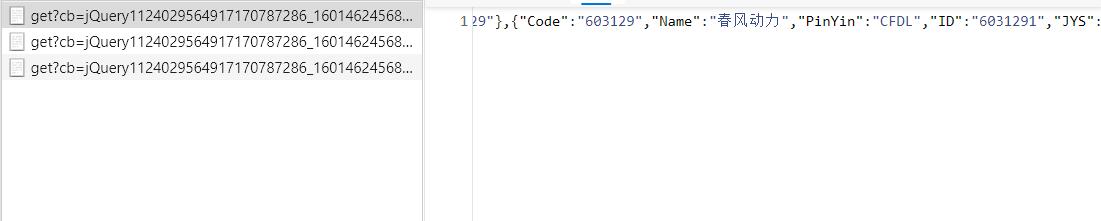
-
找到相应的 JS 再传入已获得的股票代码然后爬爬爬
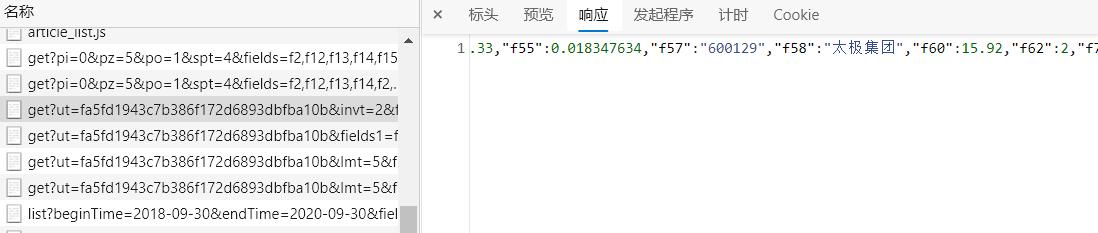
-
运行结果
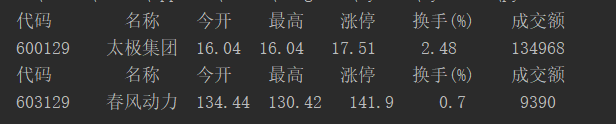
-
附上代码
import re
import requests
# search_url = "http://so.eastmoney.com/web/s?keyword=129"
url = "http://push2.eastmoney.com/api/qt/ulist.np/get?pn=1&pz=50&po=1&np=1&ut=fa5fd1943c7b386f172d6893dbfba10b&fltt=2&invt=2&fid=f62\
&secids=1.600129,1.603129,0.002129&fields=f12,f4,f5,f13,f186,f148,f187,f217,f14,f2,f3,f62,f184,f66,f69,f72,f75,f78,f81,f84,f87,f204,f205,f124&rt=52534396&cb=jQuery1124043095589175823057_1601447227478&_=1601447227499"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63"}
def get_Stock_Code(url):
# get stock code endswith 129
code_list = []
html = requests.get(url,headers = headers).content.decode(encoding="utf-8")
res = re.findall(re.compile('"diff":\[(.+)\]'),html)[0].split("},")
for idx,info in enumerate(res):
if idx != len(res)-1:
info = info + "}"
info = eval(info)
code = info["f12"]
code_list.append(code)
return code_list
def get_Info(code):
print("代码 名称 今开 最高 涨停 换手(%) 成交额 ")
url = "http://push2.eastmoney.com/api/qt/stock/get?ut=fa5fd1943c7b386f172d6893dbfba10b&invt=2&fltt=2&fields=f43,f57,f58,f169,f170,f46,f44,f51,f168,f47,f164,f163,f116,f60,f45,f52,f50,f48,f167,f117,f71,f161,f49,f530,f135,f136,f137,f138,f139,f141,f142,f144,f145,f147,f148,f140,f143,f146,f149,f55,f62,f162,f92,f173,f104,f105,f84,f85,f183,f184,f185,f186,f187,f188,f189,f190,f191,f192,f107,f111,f86,f177,f78,f110,f262,f263,f264,f267,f268,f250,f251,f252,f253,f254,f255,f256,f257,f258,f266,f269,f270,f271,f273,f274,f275,f127,f199,f128,f193,f196,f194,f195,f197,f80,f280,f281,f282,f284,f285,f286,f287,f292&secid=1." + str(code) +"&cb=jQuery11240959380450062036_1601458369843&_=1601458369844"
html = requests.get(url, headers=headers).content.decode(encoding="utf-8")
# print(re.findall(re.compile('"data":\{(.*?)\}\}\)'), html))
res = re.findall(re.compile('"data":\{(.*?)\}\}\)'), html)[0]
res = "{" + res + "}" # constuct a complete dict
res = eval(res)
code = res["f57"]
name = res["f58"]
opening = res["f44"]
highest = res["f46"]
up_to_stop = res["f51"]
change = res["f168"]
volumn = res["f47"]
print(str(code) + " " + str(name) + " " + str(opening) + " " + str(highest) + " " + str(up_to_stop) + " " + str(change) + " " + str(volumn))
if __name__ == "__main__":
code_list = get_Stock_Code(url)[:2]
for code in code_list:
get_Info(code)
作业总结
这次作业难度不大,主要是考察从网页爬取数据然后存入数据库中以及当 bs4 无法从 HTML 源代码中爬取数据(也就是说网页数据是以 JS 动态加载的话),从 JS 中找出所需要的数据转化为 JSON 格式然后再提取相关的字段。然后问题是不知道这样子的代码是否稳定,当网页改版之后代码很可能失效。特别是第三题,换成其他的股票代码很可能会无法运行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号