代码中的软件工程
代码中的软件工程
这两节课孟宁老师主要结合了一个menu小程序,通过不断的迭代调试,为我们展示了代码是如何生长起来的,同时也让我对模块化设计、可重用接口、线程安全等有了初步的认识和理解。这里我以这篇博客来记录相应的内容和自己的体会。
1.编译和调试环境配置
1.1在VSCode中下载C/C++插件
直接在应用商店搜索C/C++,点击安装即可。
1.2安装配置C/C++编译器:Mingw-w64/GCC
下载并运行Mingw-w64-install.exe,安装过程中几个选项选择如下:
- Version制定版本号,从4.9.1-8.x.0,按需选择,没有特殊要求就用最新版;
- Architecture跟操作系统有关,64位系统选择x86_64,32位系统选择i686;
- Threads设置线程标准可选posix或win32;
- Exception设置异常处理系统,x86_64可选为seh和sjlj,i686为dwarf和sjlj;
- Build revision构建版本号,选择最大即可。
安装完成后添加环境变量:打开mingw-w64文件夹,一步步找到bin文件夹,复制路径。
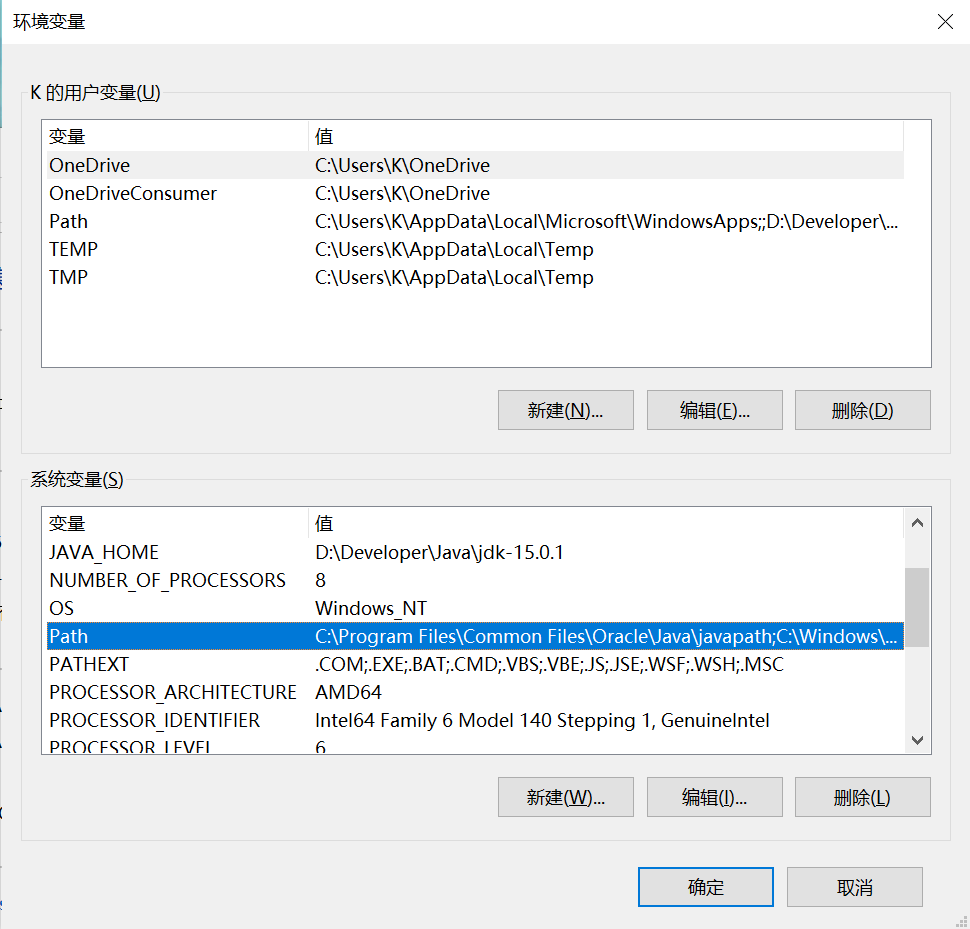
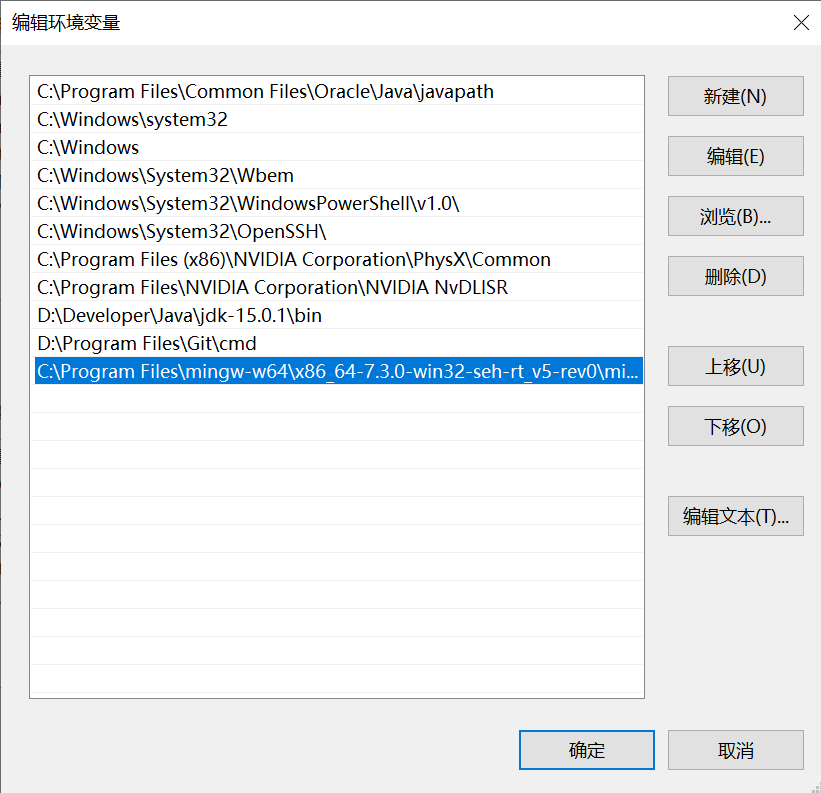
复制完成后,打开系统高级设置,选择环境变量,在弹出的对话框里选择系统变量的path变量,将刚刚复制的路径粘贴进去,流程如下:
安装完成后,可使用快捷键win+R,输入cmd,打开命令行窗口执行gcc -v查看是否安装成功;或者直接在开始菜单中找到mingw-w64,打开运行终端,进行后续操作。
1.3 配置VSCode项目结构
在你需要的地方建立一个新文件夹menu,在该目录下使用命令行输入“code .” 就会在VSCode中打开这个文件夹。

在目录下新建test文件,输入一段简单的helloword小程序,然后点击运行->启动调试,环境选择C++(GDB/LLDB),配置选择g++.exe :


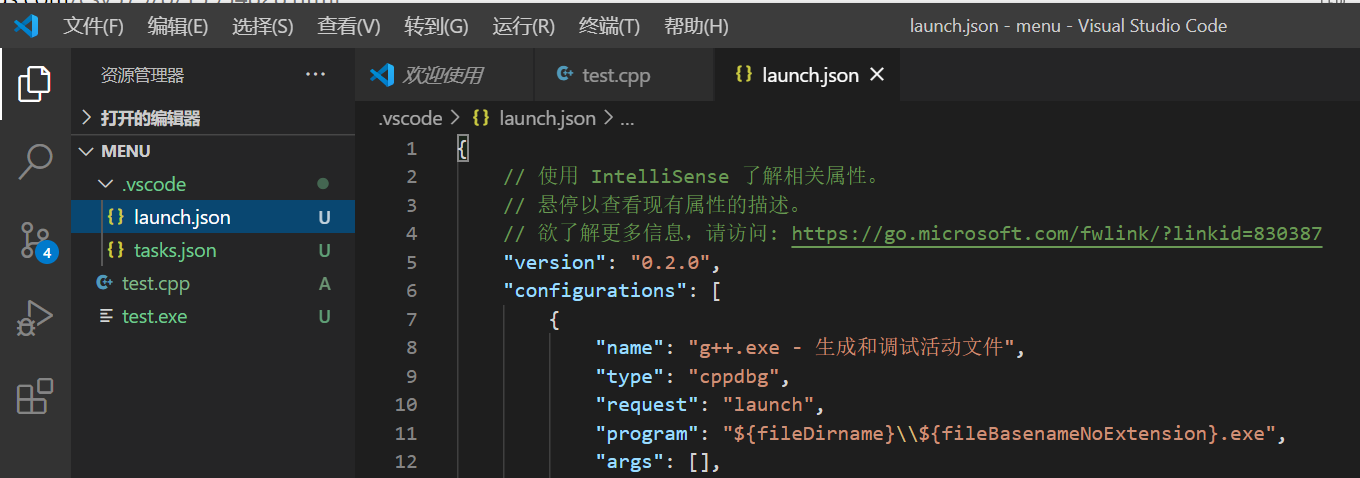
然后会生成一个包含launch.json和task.json的.vscode文件夹,如下:
2. 代码中的软件工程分析
2.1 模块化软件设计
模块化(Modularity)是在软件系统设计时保持系统内各部分相对独立,以便每一个部分可以被独立地进行设计和开发。这个做法背后的基本原理是关注点的分离 (SoC, Separation of Concerns), 关注点的分离在软件工程领域是最重要的原则,我们习惯上称为模块化。模块化软件设计的方法如果应用的比较好,最终每个软件模块都只有一个单一的功能目标,并相对独立于其他软件模块。整个软件系统也更容易定位软件缺陷bug,系统的维护和变更也更容易。
我们使用耦合度(Coupling)和内聚度(Cohesion)来衡量软件模块化的程度。
- 耦合度是指软件模块之间的依赖程度,一般可以分为紧密耦合、松散耦合和无耦合(一般在软件设计中我们追求松散耦合)。
- 内聚度是指一个软件模块内部各种元素之间互相依赖的紧密程度。理想的内聚是功能内聚(一个软件模块只做一件事,只完成一个主要功能点或一个软件特性)
接下来我们将结合menu小程序来理解其中的模块化思想。
首先,lab3.1中使用到了宏
#define CMD_MAX_LEN 128 #define DESC_LEN 1024 #define CMD_NUM 10
这样做的好处是,可以避免出现"magic number",如果把一些有含义的数字直接放入代码,又不添加注释,时间长了,便很难理解数字代表的含义。将这些数字定义为宏,方便以后重构的时候修改。
lab3.1到lab3.2,将一些对数据的操作独立了出来,如FindCmd和ShallAllCmd,但此时所有代码还在同一个源文件内,对于修改和维护不太方便。
tDataNode* FindCmd(tDataNode * head, char * cmd)。 { if(head == NULL || cmd == NULL) { return NULL; } tDataNode *p = head; while(p != NULL) { if(!strcmp(p->cmd, cmd)) { return p; } p = p->next; } return NULL; } int ShowAllCmd(tDataNode * head) { printf("Menu List:\n"); tDataNode *p = head; while(p != NULL) { printf("%s - %s\n", p->cmd, p->desc); p = p->next; } return 0; }
lab3.2到lab3.3,其中改进主要在于从menu菜单程序内部实现模块化,业务逻辑层与数据存储层的分离。把数据结构和操作独立到一个文件(linklist)里面,设计链表接口,让链表成为提供程序结构的接口,以下是linklist.h中的代码。
typedef struct DataNode { char* cmd; char* desc; int (*handler)(); struct DataNode *next; } tDataNode; /* find a cmd in the linklist and return the datanode pointer */ tDataNode* FindCmd(tDataNode * head, char * cmd); /* show all cmd in listlist */ int ShowAllCmd(tDataNode * head);
2.2 可重用软件设计
2.2.1 接口的概念
尽管已经做了初步的模块化设计,但是分离出来的数据结构和它的操作还有很多菜单业务上的痕迹,我们要求这一个软件模块只做一件事,也就是功能内聚,那就要让它做好链表数据结构和对链表的操作,不涉及菜单业务功能上的东西;同样我们希望这一个软件模块与其他软件模块之间松散耦合,就需要定义简洁、清晰、明确的接口。 这时进一步优化这个初步的模块化代码就需要设计合适的接口。
接口就是互相联系的双方共同遵守的一种协议规范,在我们软件系统内部一般的接口方式是通过定义一组API函数来约定软件模块之间的沟通方式。换句话说,接口具体定义了软件模块对系统的其他部分提供了怎样的服务,以及系统的其他部分如何访问所提供的服务。 在面向过程的编程中,接口一般定义了数据结构及操作这些数据结构的函数;而在面向对象的编程中,接口是对象对外开放(public)的一组属性和方法的集合。函数或方法具体包括名称、参数和返回值等。
2.2.2 软件模块接口举例
在2.1中提到的接口虽然初步将数据结构和操作分离了出来,但还不够通用,本节要介绍的是如何将其写成可重用的接口,使其不仅能够用于menu小程序,还能应用于其他需要使用该接口的模块,也即不要"重复造轮子",以下代码是通用linktable模块的接口。
#ifndef _LINK_TABLE_H_ #define _LINK_TABLE_H_ #include <pthread.h> #define SUCCESS 0 #define FAILURE (-1) /* * LinkTable Node Type */ typedef struct LinkTableNode { struct LinkTableNode * pNext; }tLinkTableNode; /* * LinkTable Type */ typedef struct LinkTable { tLinkTableNode *pHead; tLinkTableNode *pTail; int SumOfNode; pthread_mutex_t mutex; }tLinkTable; /* * Create a LinkTable */ tLinkTable * CreateLinkTable(); /* * Delete a LinkTable */ int DeleteLinkTable(tLinkTable *pLinkTable); /* * Add a LinkTableNode to LinkTable */ int AddLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode); /* * Delete a LinkTableNode from LinkTable */ int DelLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode); /* * get LinkTableHead */ tLinkTableNode * GetLinkTableHead(tLinkTable *pLinkTable); /* * get next LinkTableNode */ tLinkTableNode * GetNextLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode); #endif /* _LINK_TABLE_H_ */
因此这里linktable模块是可重用的,只对外暴露其接口。linktable模块只做与数据处理有关的操作,不涉及对menu业务的操作(进一步实现了内聚,降低了耦合度),所以linktable中增加了适合其他程序使用的方法。
为进一步改进接口设计,使其更简洁和通用,我们给Linktable增加Callback方式
给Linktable增加Callback方式的接口,需要两个函数接口,一个是call-in方式函数,如SearchLinkTableNode函数,其中有一个函数作为参数,这个作为参数的函数就是callback函数,如代码中Conditon函数。
/* * Search a LinkTableNode from LinkTable * int Conditon(tLinkTableNode * pNode); */ tLinkTableNode * SearchLinkTableNode(tLinkTable , int Conditon(tLinkTableNode * pNode));
2.3 线程安全
2.3.1 可重入函数
一个可重入的函数简单来说,就是可以被中断的函数。我们可以在这个函数执行的的任何时候中断他的运行在任务调度下去执行另一段代码而不会出现什么错误。而不可重入函数因为使用了一些系统资源,比如全局变量区,中断向量表等等,这类函数如果被中断的话可能会出现问题,所以是不能运行在多任务环境下的。把一个不可重入函数变成可重入的唯一方法是用可重入规则来重写他,主要有以下几点:
- 不为连续的调用持有静态数据;
- 不返回指向静态数据的指针; 所有数据都由函数的调用者提供;
- 使用局部变量,或者通过制作全局数据的局部变量拷贝来保护全局数据;
- 使用静态数据或全局变量时做周密的并行时序分析,通过临界区互斥避免临界区冲突;
- 绝不调用任何不可重入函数。
2.3.2 线程安全
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。 线程安全问题都是由全局变量及静态变量引起的。若每个线程中对全局变量、静态变量只有读操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行读写操作,一般都需要考虑线程同步,否则就可能影响线程安全。
不可重入函数一定不是线程安全的;可重入函数在多个线程中并发使用时是线程安全的,但不同的可重入函数(共享全局变量和静态变量)在多线程并发使用时会有线程安全问题。
2.3.3 Linktable软件模块的线程安全分析
怎么样进行一个软件模块的线程安全分析呢?
主要步骤如下:
- 判断所有的函数是否都是可重入函数
- 分析不同的可重入函数有没有可能同时进入临界区(写互斥、读写互斥)
首先要逐一分析所有的函数是不是都是可重入函数,以下述函数为例:
tLinkTable * CreateLinkTable() { tLinkTable * pLinkTable = (tLinkTable *)malloc(sizeof(tLinkTable)); if(pLinkTable == NULL) { return NULL; } pLinkTable->pHead = NULL; pLinkTable->pTail = NULL; pLinkTable->SumOfNode = 0; pthread_mutex_init(&(pLinkTable->mutex), NULL); return pLinkTable; }
要判断其是否是可重入函数,可以模拟多个线程同时访问代码,观察其是否出错。通过模拟我们发现,如果有两个线程同时访问代码,这两个线程各自创建了一块存储区,没有同时访问同一资源的情况,因此该函数是可重入的。
再看下述函数:
int DeleteLinkTable(tLinkTable *pLinkTable) { if(pLinkTable == NULL) { return FAILURE; } while(pLinkTable->pHead != NULL) { tLinkTableNode * p = pLinkTable->pHead; pthread_mutex_lock(&(pLinkTable->mutex)); pLinkTable->pHead = pLinkTable->pHead->pNext; pLinkTable->SumOfNode -= 1 ; pthread_mutex_unlock(&(pLinkTable->mutex)); free(p); } pLinkTable->pHead = NULL; pLinkTable->pTail = NULL; pLinkTable->SumOfNode = 0; pthread_mutex_destroy(&(pLinkTable->mutex)); free(pLinkTable); return SUCCESS; }
假如同时有多个线程访问代码,由于传入了链表指针,两个线程会执行删除同一个链表的操作,删除结点时加上了mutex_lock,可使线程互斥访问,因而不会出现错误。(但在执行free(pLinkTable)时,线程可能会释放已经被别的线程释放过的结点内存,因此可能会出现异常。)
下面是向链表中添加结点的函数代码:
int AddLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode) { if(pLinkTable == NULL || pNode == NULL) { return FAILURE; } pNode->pNext = NULL; pthread_mutex_lock(&(pLinkTable->mutex)); if(pLinkTable->pHead == NULL) { pLinkTable->pHead = pNode; } if(pLinkTable->pTail == NULL) { pLinkTable->pTail = pNode; } else { pLinkTable->pTail->pNext = pNode; pLinkTable->pTail = pNode; } pLinkTable->SumOfNode += 1 ; pthread_mutex_unlock(&(pLinkTable->mutex)); return SUCCESS; }
如果有两个线程同时访问以上代码,即同时给链表添加结点,代码中在对链表操作之前先加锁,将结点插入链表里面之后再解锁。这样就避免了多个线程同时添加结点,而产生结点覆盖的情况。所以这个函数很显然也是可重入的。
对源文件里的所有函数一一分析可知,linktable.c中对所有的写操作都加了锁(对读操作未加锁),因而函数都是可重入的。但其并不是完全线程安全的。如果想将它改成绝对线程安全的代码,一种解决办法是对所有的读线程也加互斥锁,但这样做读的效率会大幅降低。另一种解决办法是加读写锁:多个线程同时进行读操作时,锁不起作用,但如果一个线程要执行写操作,它需要等待所有的线程读完,才能进行写操作。而只要有一个线程在进行写操作所有的读线程都会等待。
3. 可重用接口设计
menu作为一个子系统会用在不同项目中,如何给menu子系统设计可重用的接口呢?
学习了Linktable链表的通用接口定义的方法之后,我们往往会参照执行,这是经常犯的典型错误——“手里有把锤子,看哪里都是钉子”,menu子系统不像Linktable链表,Linktable链表是一个非常基础的软件模块,重用的机会非常多,应用的场景也非常多,而menu子系统的重用机会和应用场景都比较有限,我们没有必要花非常多的心思把接口定义的太通用,通用往往意味着接口的使用不够直接明了。所以在menu子系统的接口设计我们的原则是“够用就好——不要太具体,也不要太通用”。
如下代码是我们在menu.h中定义的两个接口,一个是通过给出命令的名称、描述和命令的实现函数定义一个命令;另一个是启动menu引擎。
/* add cmd to menu */ int MenuConfig(char * cmd, char * desc, int (*handler)()); /* Menu Engine Execute */ int ExecuteMenu()
4. 心得
孟宁老师的课程为我们展示了从无设计代码、模块化设计的代码到可复用的代码和回调函数等接口设计,通过menu命令行菜单程序这么一个小项目,让我体会到了许多工程化的编程思想和方法,也明白了严格按照代码风格规范编写代码的优势,受益匪浅。在此对孟宁老师表示感谢!
源代码:https://github.com/mengning/menu

 浙公网安备 33010602011771号
浙公网安备 33010602011771号