
第二次作业:卷积神经网络 part2
Part Ⅰ 问题总结
1 如何理解卷积神经网络中的1*1卷积?
在学习MobileNetV2代码中,提到使用11实现降维和升维,有一点迷惑,就去查了查资料,发现11卷积核真是一个神奇的存在。它存在于各种结构中,比如:残差网络的Bootleneck残差模块里、GoogleNet的Inception模块里···
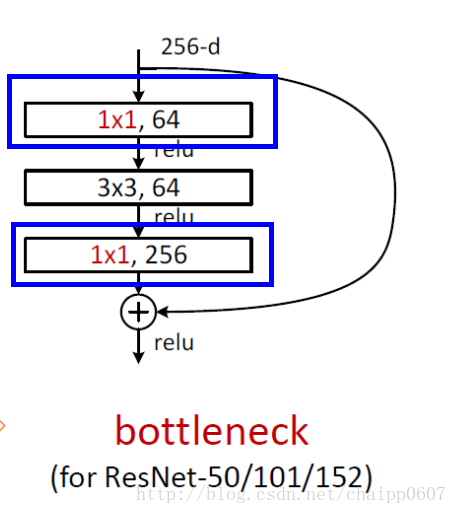
当11卷积出现时,在大多数情况下它作用是升/降特征的维度,这里的维度指的是通道数(厚度),而不改变图片的宽和高。
同时,还会降低参数的数量,增加了网络的深度。
举个例子,hw6的feature map,经过一个11的卷积核,变成了hw。有5个卷积核,输出就变成了hw*5,实现了降维的操作。升维也是一样的道理。
Part Ⅱ 代码练习
1 MobileNetV1
1.1 MobileNetV1概述
MobileNets基于一种流线型结构使用深度可分离卷积来构造轻型权重深度神经网络。MobileNetV1是一个有效的网络结构以及两组用于构建小型、低延迟模型的超参数,能在移动以及嵌入式视觉应用上轻易匹配设计要求。
1.2 MobileNetV1结构
1.2.1 深度可分离卷积
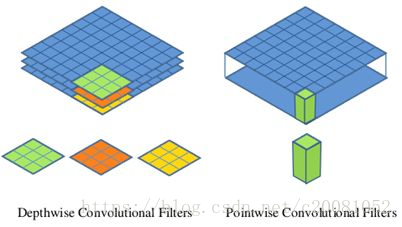
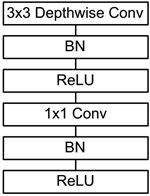
深度级可分离卷积其实是一种可分解卷积操作,其可以分解为两个更小的操作:depthwise convolution和pointwise convolution。
-
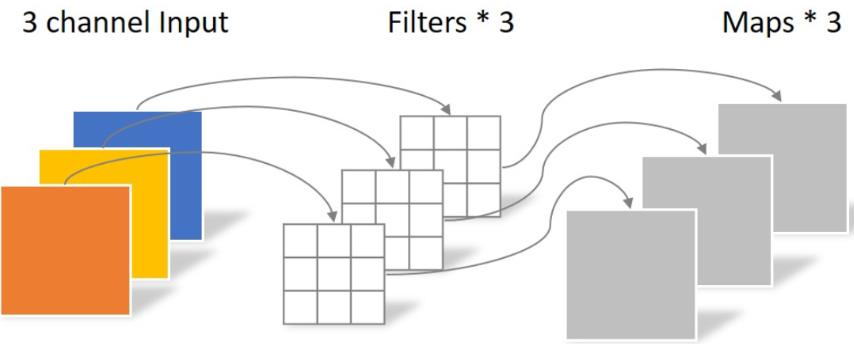
Depthwise convolution和标准卷积不同,对于标准卷积其卷积核是用在所有的输入通道上,而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道。
![]()
-
pointwise convolution其实就是普通的卷积,只不过其采用1x1的卷积核。
![]()
-
对于depthwise separable convolution,其首先是采用depthwise convolution对不同输入通道分别进行卷积,然后采用pointwise convolution将上面的输出再进行结合,这样其实整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。
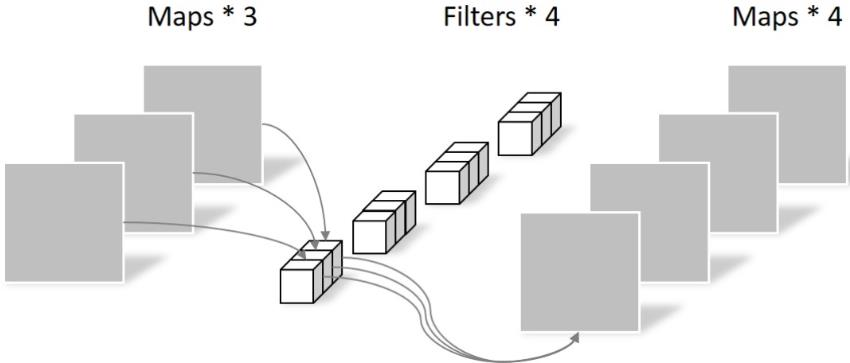
1.2.2 MobileNet网络结构
前面讲述了depthwise separable convolution,这是MobileNet的基本组件,但是在真正应用中会加入batchnorm,并使用ReLU激活函数
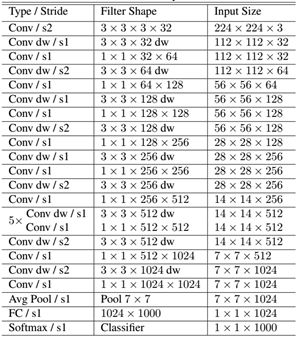
首先是一个3x3的标准卷积,然后后面就是堆积depthwise separable convolution,并且可以看到其中的部分depthwise convolution会通过strides=2进行down sampling。然后采用average pooling将feature变成1x1,根据预测类别大小加上全连接层,最后是一个softmax层。
1.3 MobileNetV1瘦身
1.3.1 宽度缩放因子(width multiplier)
- 用α表示,该参数用于控制特征图的维数,即通道数
- 计算量变为
![]()
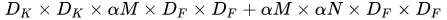
1.3.2 分辨率缩放因子(resolution multiplier)
- 用ρ表示,该参数用于控制特征图的宽/高,即分辨率
- 计算量变为
![]()
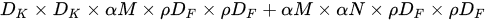
1.4 代码实现
class MobileNetV1(nn.Module):
# (128,2) means conv planes=128, stride=2
cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1),
(1024,2), (1024,1)]
def __init__(self, num_classes=10):
super(MobileNetV1, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(1024, num_classes)
def _make_layers(self, in_planes):
layers = []
for x in self.cfg:
out_planes = x[0]
stride = x[1]
layers.append(Block(in_planes, out_planes, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
2 MobileNetV2
2.1 MobileNet V1 的主要问题
- 结构非常简单,但是没有使用RestNet里的residual learning
- Depthwise Conv确实是大大降低了计算量,但实际中,发现不少训练出来的kernel是空的
2.2 MobileNet V2 的主要改动
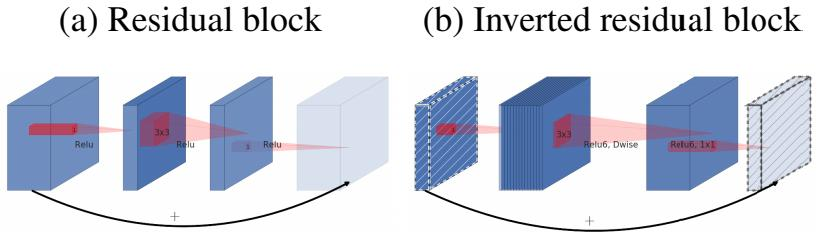
- 设计了Inverted residual block
![]()
ResNet中的bottleneck,先用1x1卷积把通道数由256降到64,然后进行3x3卷积,不然中间3x3卷积计算量太大。
现在我们中间的3x3卷积可以变成Depthwise,计算量很少了,所以通道可以多一些。所以MobileNet V2 先用1x1卷积提升通道数,然后用Depthwise 3x3的卷积,再使用1x1的卷积降维。作者称之为Inverted residual block,中间宽两边窄。 - 去掉输出部分的ReLU6
在 MobileNet V1 里面使用 ReLU6,ReLU6 就是普通的ReLU但是限制最大输出值为 6,这是为了在移动端设备 float16/int8 的低精度的时候,也能有很好的数值分辨率。Depthwise输出比较浅,应用ReLU会带来信息损失,所以在最后把ReLU去掉了(注意下图中标红的部分没有ReLU)。
![]()

2.3 网络结构
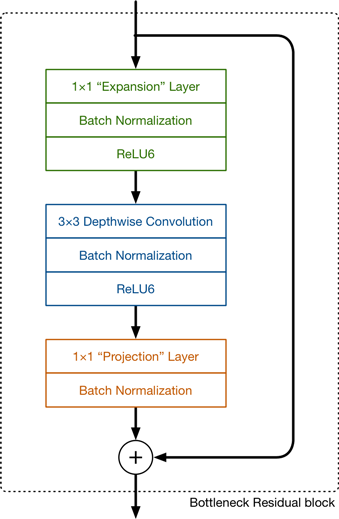
- Expansion layer:使用1*1的网络结构,目的是将低维空间映射到高维空间。这里Expansion有一个超参数是维度扩展几倍。可以根据实际情况来做调整的,默认值是6,也就是扩展6倍。
- 深度可分离卷积:与V1结构相同
- Projection layer:使用1*1的网络结构,把高维特征映射到低维空间去。
![]()
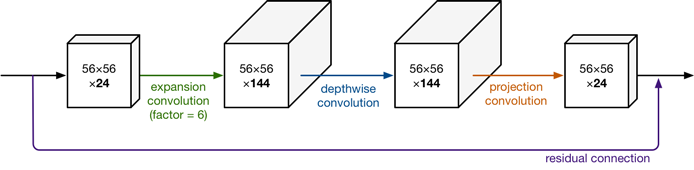
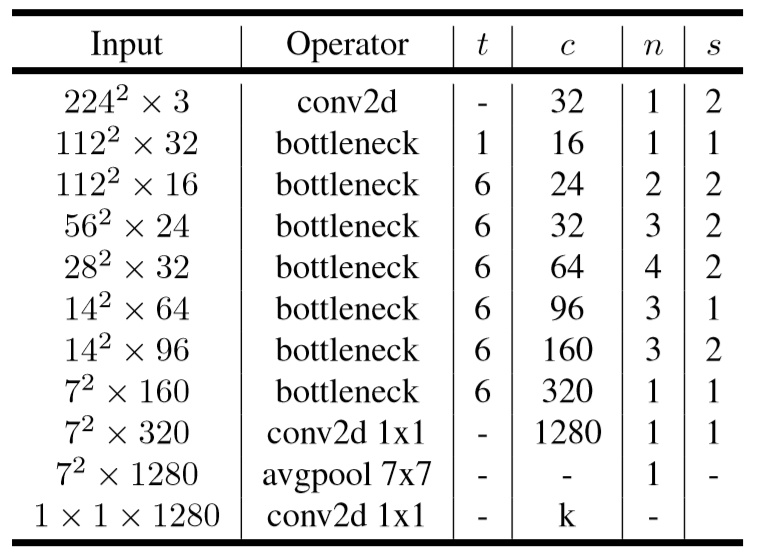
2.4 代码实现
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, in_planes, out_planes, expansion, stride):
super(Block, self).__init__()
self.stride = stride
# 通过 expansion 增大 feature map 的数量
planes = expansion * in_planes
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, groups=planes, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_planes)
# 步长为 1 时,如果 in 和 out 的 feature map 通道不同,用一个卷积改变通道数
if stride == 1 and in_planes != out_planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_planes))
# 步长为 1 时,如果 in 和 out 的 feature map 通道相同,直接返回输入
if stride == 1 and in_planes == out_planes:
self.shortcut = nn.Sequential()
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
# 步长为1,加 shortcut 操作
if self.stride == 1:
return out + self.shortcut(x)
# 步长为2,直接输出
else:
return out
# (expansion, out_planes, num_blocks, stride)
cfg = [(1, 16, 1, 1),
(6, 24, 2, 1),
(6, 32, 3, 2),
(6, 64, 4, 2),
(6, 96, 3, 1),
(6, 160, 3, 2),
(6, 320, 1, 1)]
def __init__(self, num_classes=10):
super(MobileNetV2, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.conv2 = nn.Conv2d(320, 1280, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(1280)
self.linear = nn.Linear(1280, num_classes)
def _make_layers(self, in_planes):
layers = []
for expansion, out_planes, num_blocks, stride in self.cfg:
strides = [stride] + [1]*(num_blocks-1)
for stride in strides:
layers.append(Block(in_planes, out_planes, expansion, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.relu(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
Part Ⅲ 论文阅读心得
1 《Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising》
1.1 摘要
提出了一个前馈去噪卷积神经网络(DnCNN)用于图像的去噪(首次将深度学习加入到了图像去噪之中),使用了更深的结构、残差学习算法、正则化和批量归一化等方法提高去噪性能。优势是可以处理未知噪声水平的高斯去噪。
- 非常深的结构提高利用图像特征的容量和灵活方面是非常有效的
- 训练CNN的正则化和学习方面取得了相当大的进展,ReLU、批量归一化、残差学习,提高去噪性能
- 适合GPU的并行运算。提高运行时的性能
1.2 DnCNN模型
1.2.1 网络结构
DnCNN的输入是一个噪音观察y=x+v,采用残差学习公式来训练残差映射 ,然后我们得到x = y - R(y)。
,然后我们得到x = y - R(y)。

- 深度架构:给定深度为D的DnCNN,由三种类型的层,展示在图1中有三种不同的颜色。(i) Conv+ReLU:对于第一层,使用64个大小为33c的滤波器被用于生成64个特征图。然后将整流的线性单元
![]() 用于非线性。(ii) Conv+BN+ReLU:对应于层
用于非线性。(ii) Conv+BN+ReLU:对应于层![]() ,使用64个大小3364的过滤器,并且将批量归一化加在卷积和ReLU之间。(iii) Conv:对应于最后一层,c个大小为3364的滤波器用于重建输出。
,使用64个大小3364的过滤器,并且将批量归一化加在卷积和ReLU之间。(iii) Conv:对应于最后一层,c个大小为3364的滤波器用于重建输出。
- 采用残差学习公式来学习R(y),并结合批量归一化来加速训练以及提高去噪性能。
- 通过将卷积和ReLU结合,DnCNN可以通过隐藏层逐渐将图像结构与在噪声观察分开。
- 减少边界伪影:在卷积之前直接填充0,以确保中间层的每个特征图具有与输入图像相同的大小。我们发现简单的零填充策略不会导致任何边界伪影。这个好的特性可能归因于DnCNN的强大能力。
 用于非线性。(ii) Conv+BN+ReLU:对应于层
用于非线性。(ii) Conv+BN+ReLU:对应于层 ,使用64个大小3364的过滤器,并且将批量归一化加在卷积和ReLU之间。(iii) Conv:对应于最后一层,c个大小为3364的滤波器用于重建输出。
,使用64个大小3364的过滤器,并且将批量归一化加在卷积和ReLU之间。(iii) Conv:对应于最后一层,c个大小为3364的滤波器用于重建输出。
1.2.2 残差学习和批量归一化对图像去噪的整合
- 残差学习从批量归一化中受益。因为批量归一化为CNN提供了一些优点,例如减轻内部协变量偏移问题。
- 批量归一化有益于残差学习。通过残差学习,可以利用批量归一化来加速训练并提高性能。
2《Squeeze-and-Excitation Networks》
2.1 Background
- CNN是基于卷积操作的,卷积就是通过融合局部感受野的空间和通道信息来提取信息特征。
- 为了增强CNN的提取信息特征的表征力
- 其他方法:加强空间编码
- 本文:关注通道间关系,并提出一种全新的结构单元,我们称之为“压缩并激活”(Squeeze-and-Excitation,SE)块,其能够 通过对通道间的相关性进行显式建模,以自适应地重新标定通道维度上的特征响应。(本质上就是对各个特征图赋予权重,不再是简单的相加,而是加权求和)
- 注意力机制
2.2 Squeeze-and-Excitation,SE
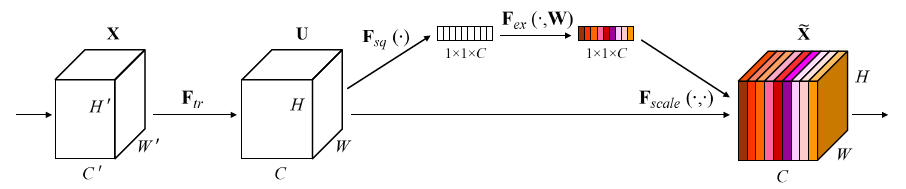
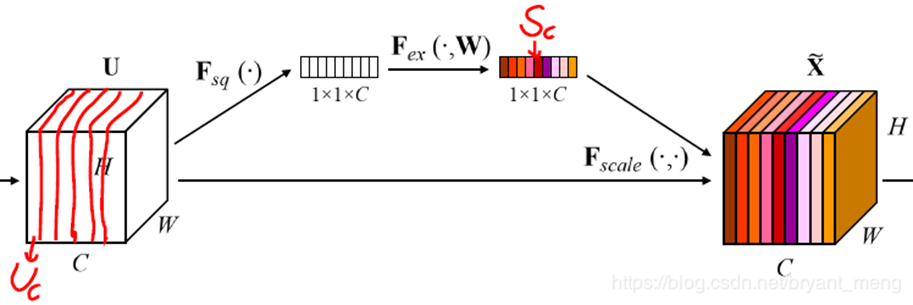
2.2.1 Squeeze压缩:嵌入全局信息
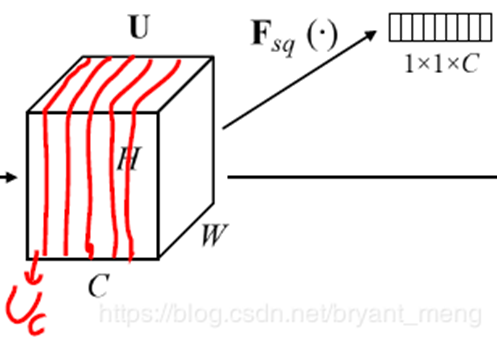
- Uc为U的c通道
- Zc 为一个标量,是最后生成一小格
- 这个公式是对该通道进行 global average pooling
![]()
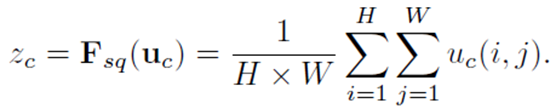
2.2.2 Excitation激发:自适应重标定
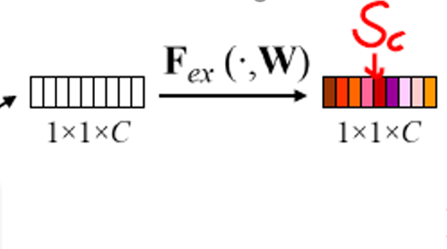
- 两个全连接层(FC)组成瓶颈(bottleneck)结构来参数化门限机制
- 第一个 fc 降低维度,激活函数为 relu,第二个还原为原来的维度,激活函数为 sigmoid
![]()
- 之所以用到两个全连接层,是降低参数的数量
![]()
- 对feature map进行加权计算
![]()

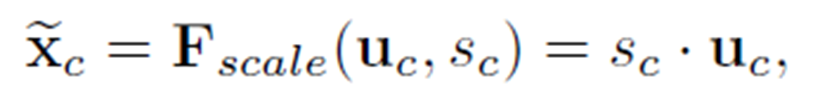
2.3 conclusion
经过了SE块,我们会加强利用对我们有用的feature map,弱化对我们没有用的feature map

 浙公网安备 33010602011771号
浙公网安备 33010602011771号