
回文系列
回文系列。
对于一个静态串,描述其回文性质的重要信息是回文半径,此处不区分奇偶回文,已知奇回文算法求偶回文只需添加分隔符,已知偶回文算法求奇回文只需复制字符。
求回文半径的通用方法是二分 + 哈希,需要求正反哈希,不要傻傻的用一个哈希做,复杂度 \(\Theta(n\log n)\)。
字符串题尽量把开头结尾用陌生字符堵死,可以少费许多心思。
Manacher
是一种 \(\Theta(n)\) 求出回文半径的算法,朴素的 Manacher 是奇回文半径算法(稍加修改可以求偶回文,但细节处理比较麻烦,用到的时候还是二倍扩展吧)。
这是一个离线算法。
注意添加通配符要在首尾隔断,且隔断符不要相同。
注意添加通配符可以用 a[++cnt] 的方式,但不要用 a[++*a],因为 *a 是 char 类型。
此处的回文半径定义为回文中心与回文端点之间的字符个数,即一个点 \(i\) 向外扩展的最长回文串是 \([i-p_i+1,i+p_i-1]\)。
int mr=0,mid=0;
F(i,1,n) {
if(i>=mr) p[i]=1;
else p[i]=min(mr-i,p[mid*2-i]);
while(b[i+p[i]]==b[i-p[i]]) p[i]++;
i+p[i]>mr&&(mr=i+p[i],mid=i);
}
记录之前扩展的右边界最靠右的回文串的右端后一位和半径,每次求新半径可以由之前的这个最靠右回文串贪心地对称过来,但不能超过对称范围,所以要和 mr-i 取 \(\min\),然后暴力扩展,更新。
均摊复杂度基于执行一次 while 则 mr 必定会增加,所以是 \(\Theta(n)\) 的。
PAM
是一种很像 \(\text{ACAM}\) 和 \(\text{SAM}\) 的自动机,也有一个树结构,称为回文树。
准确的说回文树是两棵树,\(0\) 根存偶回文,\(1\) 根存奇回文,类似 \(\text{SAM}\) 的增量构造,回文自动机也是每次添加一个字符来构造。
回文自动机的所有节点包括了所有本质不同的回文子串,每个节点需要记录 \(\text{Fail},\text{len},\text{nxt}_c\),表示其最长非自身回文后缀对应的节点,回文串长度(\(\text{len}_0=0,\text{len}_1=-1,\text{len}_{\text{nxt}_{i,c}}=\text{len}_i+2\),注意最后一个柿子不是 \(\text{len}_i=\text{len}_{\text{Fail}_i}+2\)),添加字符 \(c\) 转移的状态。
每个节点的回文串是从下往上读边再读下来(\(1\) 号点下面的边只读一遍),这和 \(\text{Trie}\) 不一样。
当我们在大串后面添加一个字符的时候,会产生许多新的回文后缀,考虑其中最长的一个,你发现短于该回文串的回文后缀都可以对称过去,所以它们已经在之前出现过了,这也是本质不同回文子串只有 \(\Theta(n)\) 个的原因。
也就是说我们每次只需要把这个最长的回文后缀塞进去即可,塞进去的过程类似 \(\text{ACAM}\),初始尝试塞进 \(i-1\),每次跳它的最长回文后缀,看是否能塞进去。
注意这个 \(\text{Fail}\) 结构是可以在两棵树之间跳来跳去的,例如 \(\text{Fail}_0=1\),而一个串跳 \(\text{Fail}\) 跳到 \(1\) 就一定能形成回文串,因为这代表的是它自己一个字符形成的串。
区别于 \(\text{Fail}\) 树,回文树指的是那两棵树。
有意思的一点是这个 \(\text{Fail}\) 结构保证了每个人的父亲编号小于其编号(\(0\) 除外),这一点其实挺重要的,因为满足这个性质你就可以循环代替简单的 dfs,譬如说子树和,\(\text{ACAM}\) 就不满足这个性质。
P5496 【模板】回文自动机(PAM)
动态往字符串后面添加字符,每次求以当前位置结尾的回文串的个数。
\(n\le5\times 10^5\)。
其实就是 \(\text{Fail}\) 树上的深度,不断求非自身最长回文后缀嘛。
int Fail(int x,int i) {
while(s[i-len[x]-1]^s[i]) x=fa[x];
return x;
}
s[0]='&';len[1]=-1;fa[0]=1;sz=1;
F(i,1,n) {
s[i]=(s[i]+ans)%26;
int p=Fail(now,i);
if(!nxt[p][s[i]]) {int nw=++sz;
fa[nw]=nxt[Fail(fa[p],i)][s[i]];
nxt[p][s[i]]=nw;
len[nw]=len[p]+2;
dep[nw]=dep[fa[nw]]+1;
} now=nxt[p][s[i]];
printf("%d ",ans=dep[now]);
}
细节:
- 需要将前面封死,以及下标不要从 \(0\) 开始,可以避免许多越界问题。
- 先求新点的 \(\text{Fail}\) 再建立新点,否则有可能使 \(\text{Fail}_x=x\),造成死循环。
- 初始化。
回文自动机并不适合写成动态添加字符的形式,因为其构建过程跟下标强相关。
Fail(x,i) 求的是 \(x\) 在 \(\text{Fail}\) 上的祖先中前后扩展一位即可匹配 \([1,i]\) 这个前缀的后缀的深度最大的节点。
Palindrome Series
是 \(\text{PAM}\) 的扩展思路,这背后是庞大的 \(\text{Border-Period}\) 理论。
不必把所有理论看完,可以先看下面的简单例题再回来学这个。
预先定义几个方便的东西:
- 定义 \(\text{Pre}(s,i)\) 是 \(s\) 的前 \(i\) 个字符,\(\text{Suf}(s,i)\) 是 \(s\) 的后 \(i\) 个字符。
- 定义字符串的相乘就是其拼接,字符串的幂是其自我拼接,特别的,幂可以是有理数,需要满足约分后分母整除 \(|s|\)。
Period
若 \(T\in[1,|s|]\) 满足 \(\forall i\in[1,|s|-T],s_i=s_{i+T}\),则 \(T\) 称为 \(s\) 的一个周期。
等价的理解是 \(s\) 是 \(\text{Pre}(s,T)^{\infty}\) 的前缀,或者 \(s=\text{Pre}(s,T)^{\frac{|s|}{T}}\)。
我们常常研究字符串的最小正周期,称其为 \(\text{Per}(s)\)。
Periodicity Lemma
弱周期引理:若 \(p\) 和 \(q\) 是 \(s\) 的周期且满足 \(p+q\le |s|\),则 \(\gcd(p,q)\) 是 \(s\) 的周期。
周期引理:若 \(p\) 和 \(q\) 是 \(s\) 的周期且满足 \(p+q\le |s|+\gcd(p,q)\),则 \(\gcd(p,q)\) 是 \(s\) 的周期。
证明并不是本文的重点,在此略过(其实是我不会证),感性理解一下吧。
请注意周期引理的使用条件。
Border
若 \(\exists r\in[0,|s|),\text{Pre}(s,r)=\text{Suf}(s,r)\),则 \(\text{Pre}(s,r)\) 称为 \(s\) 的一个 \(\text{Border}\)。
下文称 \(\text{Bor}(s)\) 为 \(s\) 的所有 \(\text{Border}\) 组成的集合。
定理:设 \(p=\text{argmax}\{|t|\mid t\in\text{Bor}(s)\}\),则 \(\text{Bor}(s)=\text{Bor}(p)\cup\{p\}\)。
这告诉我们每个 \(\text{Border}\) 都有唯一的前驱满足以上性质,你可以用森林结构来描述一个串的所有 \(\text{Border}\)。
Border 和 Period 的对偶性
若 \(\text{Pre}(s,r)\in\text{Bor}(s)\),则 \(|s|-r\) 是 \(s\) 的一个周期。
从二者的定义来看就可以互相转化。
在讨论其中一者时,我们一般转化为另一者来得出结论。
数值引理及推论
- 引理 \(1\):\(s\) 的所有 \(\ge\frac {|s|}2\) 的 \(\text{Border}\) 的长度可以构成一个等差数列,公差是 \(\text{Per}(s)\)。
此处可以将 \(s\) 也视为自身的一个 \(\text{Border}\)。
证明需要转化为周期:
设 \(p=\text{Per}(s)\),再任取 \(q<\frac{|s|} 2\),则根据弱周期引理 \(p=\gcd(p,q)\),也就是 \(p\mid q\)。
所以 \(p,2p,3p,\cdots,q\) 都是 \(s\) 的周期,且相邻两者之间没有周期,否则与 \(p=\text{Per}(s)\) 矛盾。
在前面填上一个 \(0\),再转化为 \(\text{Border}\),我们就得到了上述引理。
- 引理 \(2\):若 \(|u|=|v|=n\),则定义 \(\text{PS}(u,v)=\{k\mid\text{Pre}(u,k)=\text{Suf}(v,k)\}\),则 \(\text{LPS}(u,v)=\{k\in\text{PS}(u,v)\mid k\ge\frac n 2\}\) 中的元素构成一个等差数列。
这其实是对引理 \(1\) 的扩展,引理 \(1\) 讨论的是 \(\text{LPS}(s,s)\)。
\(\text{PS}\) 和 \(\text{Border}\) 有很多相似之处。
\(\text{Proof}\):
取 \(p=\max \text{PS}(u,v),t=\text{Pre}(u,p)\)。
此时 \(\{\text{Pre}(u,x)\mid x\in\text{LPS}(u,v)\setminus p\}=\text{Bor}(t)\),理解这个结论类似于理解 \(\text{Border}\) 的 \(\text{Border}\) 还是 \(\text{Border}\),证明略过。
则 \(\text{LPS}(u,v)=\{|t|\}\cup\{|o|\mid o\in \text{Bor}(t)\}\),由于 \(\frac p 2\le \frac n 2\),则我们利用引理 \(1\) 即可证明结论。
- 最终推论:\(\text{Bor}(s)\) 的长度集合可以划分为相邻的 \(\Theta(\log|s|)\) 个等差数列。
前面的结论都为了引出这个结论呢。
两种证明方式:
- 递归构造,先取出 \(\text{LPS}(s,s)\),构造完一个等差数列之后递归构造 \(\text{LPS}(\text{Pre}(s,\lfloor\frac {|s|} 2\rfloor),\text{Suf}(s,\lfloor\frac {|s|} 2\rfloor))\),每次长度减半。
- 按照长度划分,类似于值域分块将 \(|s|\) 划分为 \([1,2),[2,4),\cdots,[2^k,2^{k+1}),|s|\in[2^k,2^{k+1})\),那么每段要划分的就是 \(\text{LPS}(\text{Pre}(s,2^j-1),\text{Suf}(s,2^j-1))\),由于 \(\frac{2^j-1}2\le 2^{j-1}\),所以每段都可以划分成 \(1\) 个等差数列。
与回文自动机的联系
硬着头皮学完了上面的读者现在肯定疑惑这玩意有什么用。
我们发现,对于回文串 \(s\),它的所有 \(\text{Border}\) 刚好就是所有的回文后缀,换句话说,\(s\) 在 \(\text{Fail}\) 上的祖先可以划分为 \(\Theta(\log |s|)\) 个等差数列。
对于求值问题,如果我们能对每段等差数列分别维护答案,则我们就完成了 \(\Theta(n)\to\Theta(\log n)\)。
对于数据结构问题,该结构也可以替代庞大的倍增数组,获得更小的常数来实现对串长的倍增,你甚至可以对 \(\text{slink}\) 建立倍增数组,获得 \(\Theta(\log \log n)\) 的复杂度,不过随机数据下似乎没有暴力跳 \(\text{slink}\) 优秀?
我们一般在回文树上多维护两个数组,\(\text{d}_x=\text{len}_x-\text{len}_{\text{Fail}_x},\text{slink}_x\) 表示最深的 \(\text{d}_v\ne \text d_x\) 的节点 \(v\),即 \(x\) 所在等差数列的第一个元素,以及上一个等差数列的最后一个元素。
DP部分:Palindrome Series
上述理论可以用来优化一类问题。
若有转移式 \(f_i\xleftarrow[{s[j+1,i]\text{ 是回文串}}]{\oplus} f_j\) 或者收集式 \(f_i\xleftarrow[{s[j+1,i]\text{ 是回文串}}]{\oplus} h_j\),其中 \(\oplus\) 表示 \(\text{dp}\) 值的合并方式,例如 \(\min\),前者朴素的方法只能做到 \(\Theta(n^2)\),后者可离线的话可以 \(\text{manacher}\) 变成静态区间询问,但很麻烦。
考虑直接把每段等差数列的(自上而下的)前缀 \(\bigoplus f\) 记录下来(该段等差数列最上方的分界点属于上一个等差数列),称回文树上 \(x\) 节点记录的信息是 \(g_x\),则我们的 \(g_x\) 能从 \(g_{\text{Fail}_x}\) 转移而来,更具体的是:
那为什么是 \(f_{i-\text{d}_x-\text{len}_{\text{slink}_x}}\) 呢,来看下面这张典图:
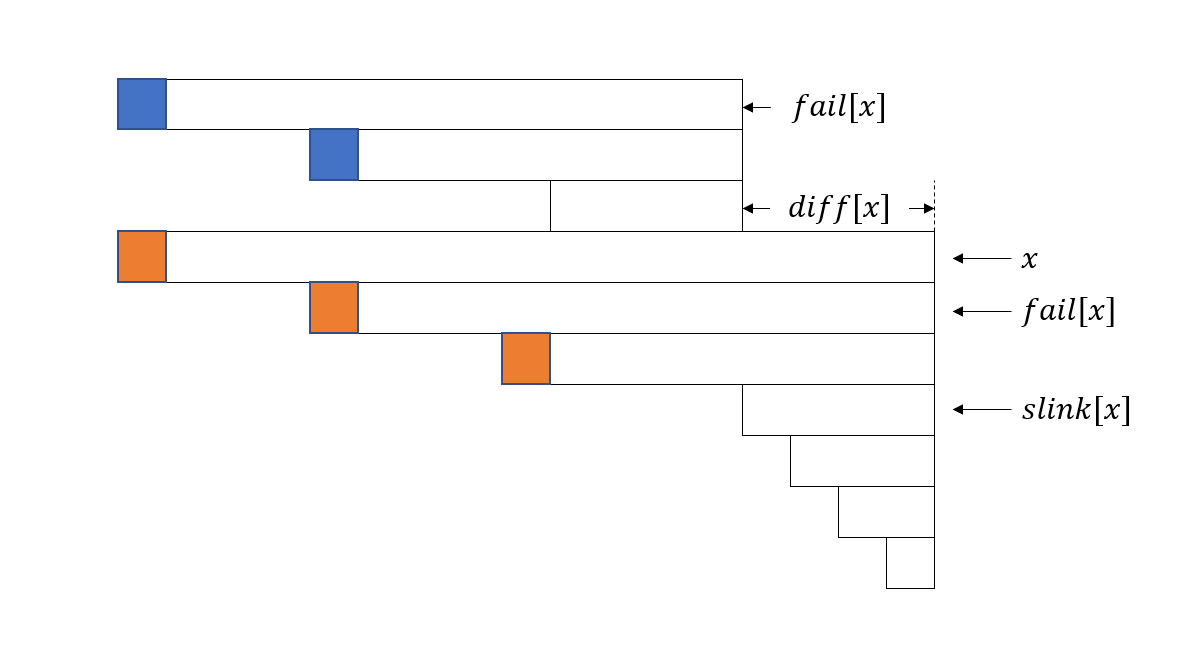
我们的 \(g_{\text{Fail}_x}\) 记录了两个蓝色的部分,应当记录的是黄色的部分,故我们需要额外加入 \(f_{i-\text{d}_x-\text{len}_{\text{slink}_x}}\)。
至于为什么两个蓝色的部分刚好重合于前两个黄色的部分,这是因为这维护了一段等差数列。
稍后会见到这个算法的应用。
(这甚至是个在线算法,优雅。)
例题
接下来是回文例题时间。
你会发现正常难度的大多数的非强制在线回文题都可以用回文半径解决,只有极少数需要用到 \(\text{PAM}\)。
口胡题#1 NFLS2023.9.25 D1A
给定一个串,\(q\) 次询问区间最长回文子串长度。
\(n,q\le3\times 10^5\)。
好像做法非常多,不过首先肯定要求回文半径。
来一个我考场上的纱布做法:
离线扫描线,右端点右移时,考虑所有中点在右端点前的线段。
发现与右端点无交的线段的贡献形如一个斜率固定的一次函数,可以使用简化的李超线段树解决。
与右端点有交的线段发现可以贪心,全部将中点插进
std::set里,选最靠近询问区间中点的即可。
最简单的解法是二分答案,二分完答案之后就能确定中点位置了,直接区间 \(\max\) 即可。
P3649 [APIO2014] 回文串
给定一个串,求所有回文子串中出现次数与长度乘积的最大值。
\(n\le 3\times 10^5\)。
前者是 \(\text{Fail}\) 上子树和,后者是 \(\text{len}\)。
口胡题#2 NFLS2023.11.07 D1C
一个字符串 \(T\) 是好的,当且仅当这个字符串能通过若干次“行走”使得每个点都被走过至少一次。
一次行走定义为:选择一个正整数序列 \(t_1,t_2,\dots,t_m\),满足 \(\forall i\in[2,m],|t_i-t_{i-1}|=1,t_1\ne t_m,T_{t_1},T_{t_2},\dots T_{t_m}\) 是一个回文串。
\(q\) 次询问一个子串是否是好的。
\(n,q\le 10^6\)。
给两组样例帮助理解:
in:
7
danaand
3
2 6
4 5
1 3
out:
110
in:
8
bcdbacab
10
5 6
2 7
1 5
1 5
2 7
4 8
4 6
2 4
1 5
3 3
out:
0100110000
通过观察样例可以发现,我们首先能构造出两种“好”的条件:偶回文覆盖或有形如 aba 这种形式的串。
第一个不用多说,事实上也可以理解为回文覆盖,只不过第二种情况把 \(\ge3\) 的奇回文排除了,而单字符显然不合法。
第二个,我们可以 \(\text a_0\to \text b\to\text a_0\to(left)\to \text a_0\to \text b\to \text a_1\) 来完成覆盖左边,右边同理。
你发现你找不到新的条件了,于是你猜这是充要的,事实上这真的是充要的。
判断第二个条件非常容易,于是我们就要解决一个区间能否被偶回文覆盖。
先说回文半径做法。
我们首先求回文半径 \(len_i:(i,i+1)\),然后每个点能被覆盖的条件是(\(p_i\) 为 \(i\) 左边最近的能覆盖它的偶回文中心,\(q_i\) 为 \(i\) 右边的):
(可以自己画图理解)
求 \(p_i,q_i\) 可以用并查集。
然后我们倒着枚举 \(L\),把每个点挂在 \(2p_i-i+1\) 上,枚举到这个点就说明这个点的 \(2p_i-i+1\ge L\) 了,就不需要管 \(q_i\) 了。
然后判断就是做一个区间 \(\max\) 看是否 \(\le R\),复杂度 \(\Theta(n\log n)\)。
来一个回文自动机做法。
考虑将所有询问分治,每个询问 \([L,R]\) 在第一次遇到 \(m=\frac{l+r}2\in[L,R]\) 的时候处理。
考虑 \([L,R]\) 的回文覆盖一定至少有一个回文串跨过 \(m\),由此将覆盖分成两部分,从 \(L\) 一直覆盖到超过 \(R_0\ge m\),从 \(R\) 一直覆盖到 \(L_0\le m\),若 \(R_0\le R\wedge L_0\ge L\),则覆盖合法。
换句话说,我们只需要对每个 \(L\) 找到最小的合法 \(R_0\),记为 \(f_L\),对每个 \(R\) 找到最大的合法的 \(L_0\),这部分是对称的,所以我们考虑解决前一个问题。
我们可以列出转移柿子,用 \([[l,r]]\) 表示 \(s[l,r]\) 是一个回文串:
也就是我们要找到最小的 \(j\ge m\) 使得 \([[i,j]]\),还有最大的 \(j<m\) 使得 \([[i,j]]\),这可以回文树上倍增得到答案,第二个转移要用到前缀 \(\min\),可以树状数组维护,复杂度 \(\Theta(n\log^2 n)\)。
我们发现后者是一个询问左边界不断左移,右边界在不断摇摆的区间 \(\min\),但有一个重要性质是转移并不改变原始信息,所以我们可以每次在单调栈尽可能弹掉不优的值,毕竟这些不优的值真的再也不会用到了,因为那个优秀的值转移到 \(i\) 之后就会单调优于那些值了。
所以这部分可以使用单调栈来优化。
若一个回文串的最长回文后缀 \(\ge \frac{|s|}2\),则该回文串能被这个小串平铺,也就不可能有用了,所以我们可以处理出每个点向上跳到的第一个有用的回文串,每个点向上有用的回文串至多只有 \(\Theta(\log n)\) 个。
而随着分治的进行,我们需要的回文串长度在逐步变小,所以可以把回文树上倍增换成指针暴力跳,这部分均摊到 \(\Theta(n\log n)\)。
当然也可以无脑跳 \(\text{slink}\),没人卡的掉。
总复杂度喜提 \(\Theta(n\log n)\)。
P9482 [NOI2023] 字符串
给定一个字符串,\(q\) 次询问,每次给出 \(i,r\),求有多少 \(l\in[1,r]\) 满足 \(s_{[i,i+l-1]}<\text{rev}(s_{[i+l,i+2l-1]})\),其中 \(\text{rev}(s)\) 表示 \(s\) 左右翻转。
\(n,q\le 10^5\)。
首先把 \(s_{[i,i+l-1]}<\text{rev}(s_{[i+l,i+2l-1]})\) 变成 \(\text{Suf}_i<\text{Pre}_{i+2l-1}\),当然这样会有一些副作用,等会再说,先来解决这个新问题。
比较字典序我们自然想到后缀数组的 \(\text{rk}\),于是我们把这个串翻转之后接到自己身上,但不能直接接,为了避免各种麻烦,中间要加上隔断,形如 \(s-c_1-\text{rev}(s)-c_2\),其中 \(c_1,c_2\) 不能在字符集内,且二者不能相等,为了避免 \(\text{rev}(s)\) 错误参与到 \(s\) 的比较中。
然后我们就可以愉快列式子,下标从 \(1\) 开始的话则 \(\text{Suf}_i<\text{Pre}_{i+2l-1}\) 应该写成 \(\text{rk}_i<\text{rk}_{2n+3-i-2l}\),发现这就是一个二维数点,将询问按照 \(\text{rk}_i\) 从大到小排序,用两棵树状数组分奇偶性询问即可。
然后就是看这个副作用,答案无疑会多统计一些部分,这些部分的 \(s_{[i,i+l-1]}=\text{rev}(s_{[i+l,i+2l-1]})\) 但 \(\text{Suf}_i<\text{Pre}_{i+2l-1}\),我们瞪大眼仔细看发现这描述了一个回文中心在 \([i+l-1,i+l]\) 的回文串,于是我们用 \(\text{manacher}\) 求个回文半径先。
你发现求完回文半径之后,回文串两边的两个不相等的字符唯一决定了 \(\text{Suf}_i\) 和 \(\text{Pre}_{i+2l-1}\) 的大小关系,所以只需要回文串右边的字符比左边的小那么整个回文串都是被多统计的,应当减掉。
小细节:如果回文串顶到边界了怎么办?
根据我们上面的后缀数组构建规则,我们钦定整个字符串的最后有一个 \(c_1\),最前面有一个 \(c_2\),使用这个来比较即可。
这个数点问题需要寻找一个锚定物,直接从条件推到结果是很麻烦的,这里的锚定物找的就是左半边字符串是否合法。
设回文串是 \([i-l_i,i+l_i+1]\)(\(l_i\) 是回文半径),则我们把 \(\forall x\in[i-l_i,i],[x,i]\) 都应当被统计到,建立关于 \(l,r\) 的平面直角坐标系,你发现这是一条横线。
我们看原来的询问的左半边字符串,\(\forall l\in[1,r],[i,i+l-1]\) 是询问范围,这在平面直角坐标系里是一条竖线,扫描线完事!
这个题 Alex_Wei 选了整个串作为锚定物,于是他之后进行了一系列的坐标变换把斜线变成直线,所以说选好锚定物很重要。
口胡题#3 最小回文划分
给定字符串 \(s\),求最小的 \(k\),使得存在 \(s_1,s_2,\cdots ,s_k\),其拼接起来为 \(s\)。
\(n\le 3\times 10^5\)。
弱化版是 UVA11584,\(n\le 2000\)。
首先先说一个朴素思路,使用分段 \(\text{dp}\),\(f_i\xleftarrow [{s[j+1,i]\text{ 是回文串}}]{\min} f_j+1\)。
直接朴素做就是 \(\Theta(n^2)\),无需使用字符串算法。
下面开始神秘优化。
首先我们跑个 \(\text{PAM}\) 出来,每次不断跳 \(\text{Fail}\) 转移,看起来优化了很多。
实际上只需要请出 aaaaaa...aaa,我们就喜提 \(\Theta(n^2)\),还是大常数呢。
我们运用上面提到的 \(\text{Palindrome Series}\),其中 \(\oplus=\min\),\(\Theta(n\log n)\)。
\(\text{d,slink}\) 无需初始化,在 \(f_0\) 放幺元,\(f_{\text{others}},g_{\text{all}}\) 放零元。
注意每次到的 \(\Theta(\log |s|)\) 个节点都不能保留之前的值,要翻新重来。
代码。
CF932G Palindrome Partition
给定一个串,要求把它分为偶数段,将每段视为一个新字符,求这个新串是回文串的方案数。
\(n\le 10^6\)。
很妙的一点:构造一个新串 \(t=s_1s_ns_2s_{n-1}s_3s_{n-2}\cdots s_{n/2}s_{n/2+1}\),问题等价于求新串的偶回文划分数。
构造的理由很简单:我们并不知道原串每个字符对应哪个字符,但我们知道对应的两段位置是对称的,于是我们用这个方式将两端揉在一起,条件就找到了。
回文划分数就是 \(\text{Palindrome Series}\) 的 \(\oplus=+\),偶回文划分直接钦定奇数位置不转移即可。
代码。
CF17E Palisection
给定一个串,问有多少种方案选出两个回文串且有交。
\(n\le 2\times 10^6,2\text{ seconds}\)。
Ex:强制在线对于每个前缀求出答案。
正难则反,考虑求出无交的方案。
设 \(f_i\) 为 \(\subseteq [1,i]\) 的回文串个数,显然可以用 manacher + 差分区间加 \(\Theta(n)\) 求出。
注意这里首先标记回文串位置需要差分区间加,然后前缀和还原,然后前缀和求 \(f\),然后再前缀和求 \(f\) 的前缀和,共三次前缀和。
然后枚举回文中心,每次对 \(f\) 求一个区间和,复杂度 \(\Theta(n)\)。
代码。
How Ex?
这一看就要上 \(\text{PAM}\) 了,考虑来一个 \(\text{Palindrome Series}\),这样就不用求 \(f\) 的前缀和了,直接 \(h_i\xleftarrow [{s[j+1,i]\text{ 是回文串}}]{+} f_j,\text{ans}_i\gets \text{ans}_{i-1}+h_i\),\(f_i\) 也好求了,就等于 \(f_{i-1}+\text{dep}_{x}\),后者是 \(\text{PAM}\) 模板求的东西。
这个题卡空间就不写 Ex 代码了。
HDU 6320 Cut The String
给定一个串,\(q\) 次询问 \(s[l,r]\) 有多少个间隔能一刀切出两个回文串。
\(n,q\le 10^5\)。
\(\text{dp}\) 做多了也该做做数据结构,限制相当于存在 \(l\) 开头的回文串 \(s\) 和 \(r\) 开头的回文串 \(t\) 满足 \(|s|+|t|=r-l+1\)。
我们求出正反串 \(\text{PAM}\),就能得到每个位置开头/结尾的回文串的等差数列,我们用正串 \(\text{PAM}\) 上 \(r\) 的等差数列和反串 \(\text{PAM}\) 上 \(l\) 的等差数列双指针即可求出答案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号