

数据结构中的参见排序算法的实现,以及时间复杂度和稳定性的分析(1)
数据结构测参见算法分类如下(图片来源https://www.cnblogs.com/hokky/p/8529042.html)
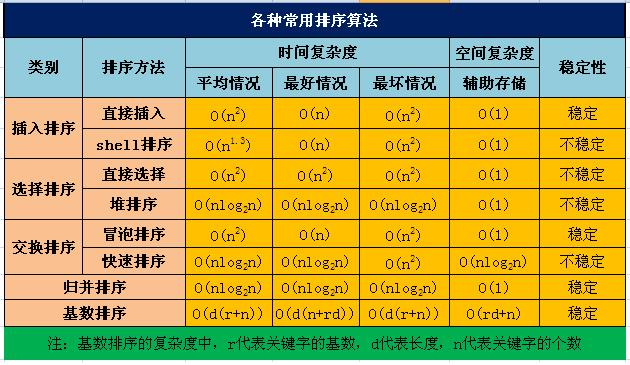
1.直接插入排序:直接插入排序是每次将要插入的数据与已排序的序列从后向前进行比较,如果已排序元素小于需要插入的数据,那么交换两者的位置,一直到达已排序序列头部为止。
代码如下:
#include <iostream> using namespace std; int main() { int s[]={10,9,8,7,6,5,4,3,2,1}; for(int i=0;i<10;i++) { int j=i+1; while(s[j]<s[j-1]&&j>=1&&j<10) { int temp=s[j]; s[j]=s[j-1]; s[j-1]=temp; j--; } } for(int i=0;i<10;i++) { cout<<s[i]<<" "; } cout<<endl; return 0; }
最好情况下,序列是有序的,每次都只和有序序列的最后一个元素比较一次,此时的时间复杂度为O(n)。
最坏情况下,序列是逆序的,此时第一个元素要比较0次,第二个元素要比较1次并交换,类推下去,第n个元素要比较n-1次,并交换,此时等差数列求和,时间复杂度为O(n*2)。
稳定性分析:两个相同元素,在直接插入排序后,相对位置任然不变,算法是稳定的。
Shell排序:Shell排序可以理解为是分组的直接插入排序,需要设置一个步长step(初始值为n/2),按照步长将序列分组,每组内部进行直接插入排序。
希尔排序的时间性能优于直接插入排序的原因:
①当文件初态基本有序时直接插入排序所需的比较和移动次数均较少。
②当n值较小时,n和n^2的差别也较小,即直接插入排序的最好时间复杂度O(n)和最坏时间复杂度0(n^2)差别不大。
③在希尔排序开始时增量较大,分组较多,每组的记录数目少,故各组内直接插入较快,后来增量di逐渐缩小,分组数逐渐减少,而各组的记录数目逐渐增多,但由于已经按di-1作为距离排过序,使文件较接近于有序状态,所以新的一趟排序过程也较快。
因此,希尔排序在效率上较直接插入排序有较大的改进。
①当文件初态基本有序时直接插入排序所需的比较和移动次数均较少。
②当n值较小时,n和n^2的差别也较小,即直接插入排序的最好时间复杂度O(n)和最坏时间复杂度0(n^2)差别不大。
③在希尔排序开始时增量较大,分组较多,每组的记录数目少,故各组内直接插入较快,后来增量di逐渐缩小,分组数逐渐减少,而各组的记录数目逐渐增多,但由于已经按di-1作为距离排过序,使文件较接近于有序状态,所以新的一趟排序过程也较快。
因此,希尔排序在效率上较直接插入排序有较大的改进。
代码如下:
#include <iostream> using namespace std; int main() { int s[]={10,9,8,7,6,5,4,3,2,1}; int gap=10/2; while(gap>=1) { for(int i=0;i<10;i++) { int j=i+gap; while(j>=gap && j<10 && s[j]<s[j-gap]) { int temp=s[j]; s[j]=s[j-gap]; s[j-gap]=temp; j=j-gap; } } gap=gap/2; } for(int i=0;i<10;i++) { cout<<s[i]<<" "; } cout<<endl; return 0; }
最坏情况下,和直接插入排序一样,初始序列是逆序的,此时时间复杂度为O(n*2),最好情况时,初始序列有序,此时时间复杂度为O(n)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号