


【深度学习】|01复旦大学邱锡鹏《神经网络与深度学习》学习小笔记(三)前馈+卷积+循环
前馈网络/全连接/多层感知机/有向无环图;
常见激活函数;
并行;
前馈神经网络;
计算梯度的方法;
静态/动态计算图;
卷积网络;
不同卷积核提取不同特征;
经典卷积结构;
循环网络;
RNN入门;
经典结构;
一、前馈网络
(1)常见激活函数【前面是表达式,后面是评论】

【非0中心化,并且是指数形式】
非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(bias shift),并进一步使得梯度下降的收敛速度变慢(作为乘积传入的)。
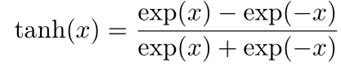
中心化在0,但是有负数

计算上更加高效,单侧抑制、宽兴奋边界,在一定程度上缓解梯度消失问题,有些神经元可能永远不会被激活

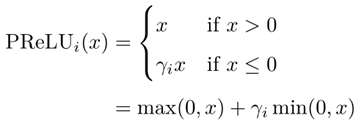


![]()
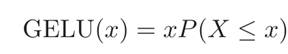
其中P(X ≤ x)是高斯分布N(µ,σ 2 )的累积分布函数,其中µ,σ为超参数,一般设µ = 0,σ = 1即可

(2)并行计算的含义
从基本的并行化原理上来讲,分布式深度学习分为数据并行(Data Parallelism)以及模型并行(Model Parallelism)。
数据并行:指每个设备有神经网络模型的完整拷贝并独立处理其输入数据流、每次迭代后将更新归并到参数服务器(Parameter Server)上;
模型并行:指每个设备有模型的一部分参数、多个设备共同来处理一条输入数据流并更新各自部分的模型参数。
(3)前馈神经网络
1.计算方式:

2.前馈计算:
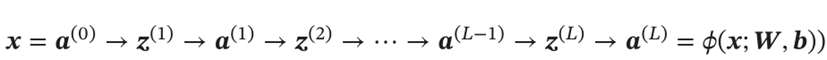
只要其隐藏层神经元的数量足够,它可以以任意的精度来近似任何从一个定义在实数空间中的有界闭集函数。【通用近似定理】可以逼近一个复杂的条件分布;
(4)计算梯度的方法
a.视为复合函数运用链式法则
b.反向传播算法
c.自动微分
利用链式法则来自动计算一个复合函数的梯度,有前向模式和反向模式;反向模式和反向传播相同;
前向传播就是新建h1,h2,...,hn来存储h的梯度的累积值
反向传播可以分为以下三步
前向计算每一层的状态和激活值,直到最后一层
反向计算每一层的参数的偏导数
更新参数
(5)静态计算图和动态计算图
tensorflow这样提前定义好图,不定义完不能跑的——静态计算图
pytorch这样跑一步看一步的——动态计算图
静态计算图在构建时可以进行优化,并行能力强,但灵活性比较差低。
动态计算图则不容易优化,当不同输入的网络结构不一致时,难以并行计算,但是灵活性比较高。
二、卷积神经网络——提取局部不变特性
局部连接,权值共享,时间或空间上的次采样
(1)不同卷积核提取不同类型特征
(a)提取的是低频信息,因为没有新波段的时候variance很低;
(b)提取的是高频信息,因为对旧波段也会产生更大的variance

窄卷积:步长 𝑇 = 1 ,两端不补零 𝑃 = 0 ,卷积后输出长度为 𝑀 − 𝐾 + 1
宽卷积:步长 𝑇 = 1 ,两端补零 𝑃 = 𝐾 − 1 ,卷积后输出长度 𝑀 + 𝐾 − 1
等宽卷积:步长 𝑇 = 1 ,两端补零 𝑃 =(𝐾 − 1)/2 ,卷积后输出长度 𝑀
卷积层虽然可以显著减少连接的个数,但是每一个特征映射的神经元个数并没有显著减少。
(2)经典卷积
(a)LeNet: 三套卷积+relu+池化,再来三个全连接;
(b)AlexNet:分到两块去计算

(3)Inception v1: 1 1-3 1-5 3-1
其中的1*1 卷积:
对于single channel而言就相当于对原特征的scala操作;
multi-channel可以根据自己的需要定义卷积核的个数,从而进行降(升)维。
如果将它看作cross channel的pooling 操作,还能得到在同一位置不同通道之间进行特征的aggregation。
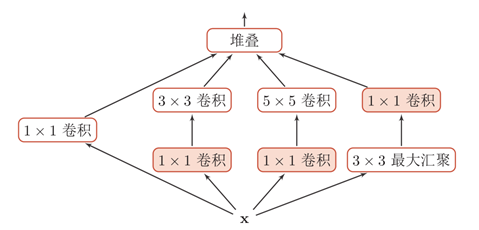
(4)Inception v3:
两个3*3替代一个5*5,减少参数量;同理用n*1和1*n来替代n*n
2*3*3=18
5*5=25

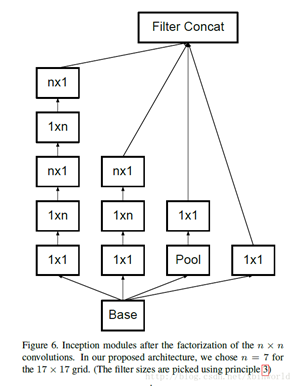
(5)残差网络:
残差网络中卷积部分拟合的是残差h(x)-x,模型向前运算只会更好不会更坏


三、循环网络---处理变长序列
(1)RNN入门
给网络增加记忆能力——时间序列模型
一个RNN:
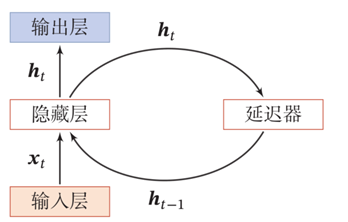
展开如下,需要看的是一个方块被哪些箭头指着,代表了这个方块的输入是什么,方块上的值就是输出;
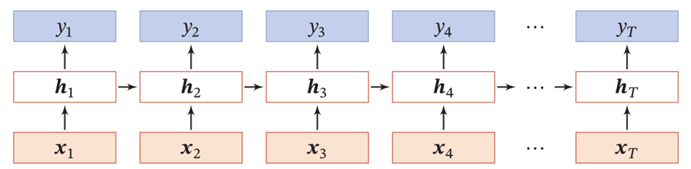
公式:
![]()
由于梯度爆炸或消失问题,实际上只能学习到短周期的依赖关系。这就是所谓的长程依赖问题。【跟梯度的表达式有关】
【梯度爆炸】权重衰减,梯度截断
【梯度消失】改进模型
改成线性依赖:(不用像上面那样经过f非线性)
增加非线性 ![]()
![]()
(2)经典的循环神经网络(衍生递归神经网络等)
a. LSTM: 这里的f,i,o都有“w”权重的意味,所以被称为门控。有变体让f+i==1


b. GRU :


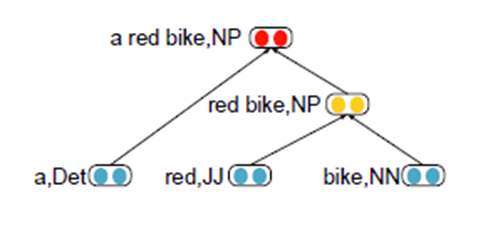
c. 递归神经网络
递归神经网络是在一个有向图无循环图上共享一个组合函数
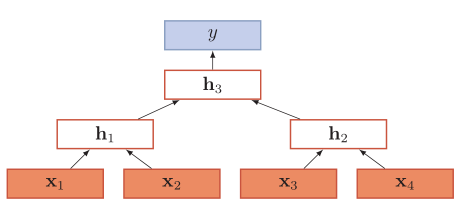
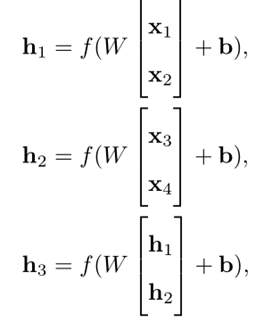
退化成循环神经网络:
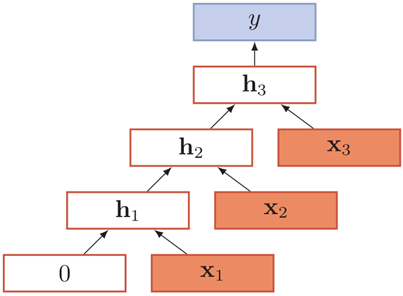
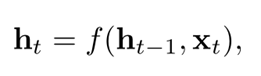
给定一个语法树,
p2 → ap1,
p1 → bc.
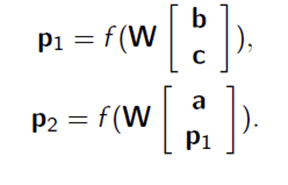

 浙公网安备 33010602011771号
浙公网安备 33010602011771号