第一次个人编程作业
https://github.com/TungChintao/061900224
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 20 | 10 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 380 | 400 |
| · Design Spec | · 生成设计文档 | 20 | 10 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 10 |
| · Design | · 具体设计 | 300 | 330 |
| · Coding | · 具体编码 | 280 | 300 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 120 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| · 合计 | 1250 | 1310 |
二、计算模块接口
(3.1)计算模块接口的设计与实现过程。
3.1.1.算法与结构概述
使用DFA+回溯算法(借鉴kmp的next指针),以树为基础数据结构构建敏感词树进行状态转移查询
难点在于敏感词树的构建与部分重合匹配状态时的回溯
3.1.2.实现细节
1.对于敏感词树的构建
采用双状态,主状态和辅助状态(主状态与辅助状态无并集)
以下以“你好”和“hello"作为敏感词构建敏感词树
(1)主状态构建:
step1 汉字,通过递归算法对敏感词进行组合,如下:
# 组合函数,构建新敏感词组合
def get_comb(word, py_word, sx_word, cur_list, new_keyword, lev):
if lev == len(word):
new_keyword.append(cur_list)
# print(new_keyword)
return
for i in range(3):
if i == 0:
get_comb(word, py_word, sx_word, cur_list + [word[lev]], new_keyword, lev + 1)
elif i == 1:
get_comb(word, py_word, sx_word, cur_list + [py_word[lev]], new_keyword, lev + 1)
elif i == 2:
get_comb(word, py_word, sx_word, cur_list + [sx_word[lev]], new_keyword, lev + 1)
return
结果如下:
['你', '好']
['你', 'hao']
['你', 'h']
['ni', '好']
['ni', 'hao']
['ni', 'h']
['n', '好']
['n', 'hao']
['n', 'h']
step2 英文,小写处理即可:
step3 汉字转偏旁直接存入辅助状态
状态构建函数(具体代码略,详细可看github)
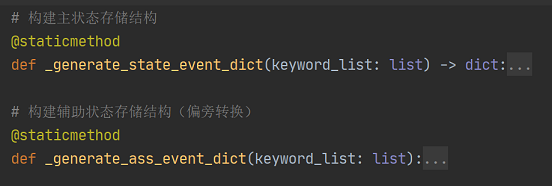
状态转移构建完成的结果:
主状态:

辅助状态:

(上述图片展示的是python字典形式实现的状态树,不理解的可以看下面的手绘状态树)
手绘状态树如下(手绘图省略了每个‘is_end'子节点,
即每个状态都有一个’is_end':False的子节点,为最终状态时‘is_end'为敏感词):
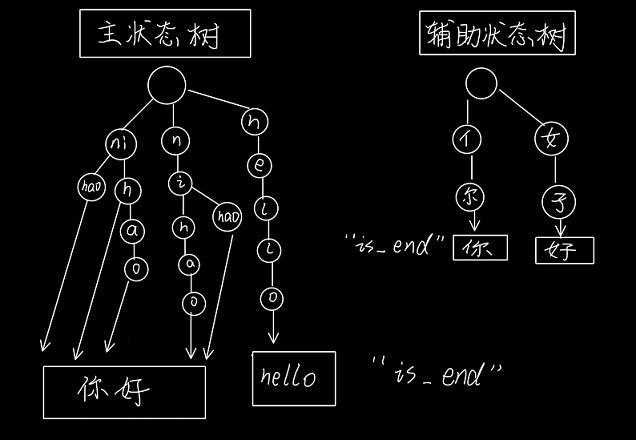
2.对于查找
文本的字符统一小写化处理再拼音化;
因为拼音化了,所以繁体字也可以得到有效识别,无需特意构建带有繁体字的状态树
查找时:
先检测原字符是否位于辅助状态,若处于辅助状态并能到达终点,则能转换为处于主状态中的状态
若原字符不位于辅助状态,则用处理后的字符在主状态中查找。
对于特殊字符,若之前已经匹配了处于状态树中的字符,则继续读入,但在状态树中的状态不发生转移,
若之前没有匹配到处于状态树中的字符,则忽略即可。
此外,还需注意的是局部答案的回溯,例如falung和***,在***中很容易识别成falung
这里需要给falung的最后一个g字加个回溯条件,在条件范围下按最长匹配原则进行匹配
3.类的构建
-
(1)dfa类,其中有四个函数:
-
(1)__init__: 接受敏感词列表
-
(2)_generate_state_event_dict: 用于构建主状态树
-
(3)_generate_ass_state_event: 用于构建辅助状态树
-
(3)match: 实现敏感词过滤功能
(2) Pianpan类:将汉字拆分为偏旁(data.pkl为自制查询表)
import pickle
import os
# import pkg_resources
class Pianpan(object):
def __init__(self):
# self.path = os.getcwd() + '/data.pkl'
# self.path = pkg_resources.resource_filename(__name__, "data.pkl")
self.path = os.path.dirname(__file__) + '/data.pkl'
with open(self.path, 'rb') as f:
self.data = pickle.load(f)
def toPianpan(self, input_char):
if input_char in self.data:
result = ''
results = self.data.get(input_char)
for i in results[0]:
result += i
else:
result = input_char
return result
(3.2)计算模块接口部分的性能改进。
(1)使用cProfile进行性能测试并按总时间排序,得到如下结果(调用函数过多,仅展示主要部分):
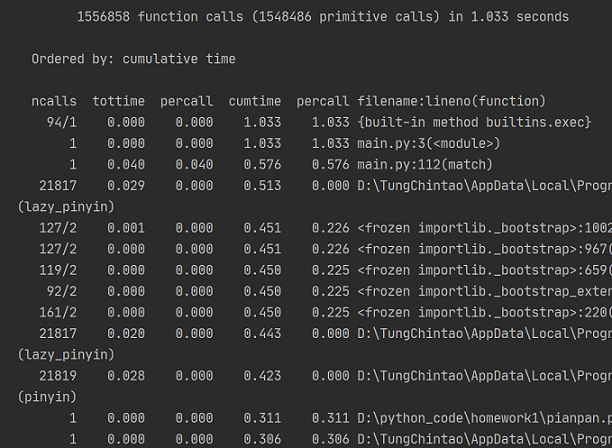
可以看到,耗时较大的主要是第三方的pypinyin库,改进方法是自己建一个拼音转换的map,但比较麻烦,所以没有对此进行改进(都用python了还自己造轮子?都用python了对性能要求也没那么在意了吧?要运行效率用C写去)
(2)继续分析发现,自建的pianpan模块中的import的pkg_resources很是显眼:



- 对于pianpan中的Pianpan类,获取偏旁文件路径的方法如下:
def __init__(self):
self.path = pkg_resources.resource_filename(__name__, "data.pkl")
with open(self.path, 'rb') as f:
self.data = pickle.load(f)
- 对此进行优化,改进如下:
def __init__(self):
self.path = os.path.dirname(__file__) + '/data.pkl'
with open(self.path, 'rb') as f:
self.data = pickle.load(f)
- 由pkg_resources模块改成了用os模块,os模块依赖较少,且为python内置模块,故运行效率较高
优化后测试如下:
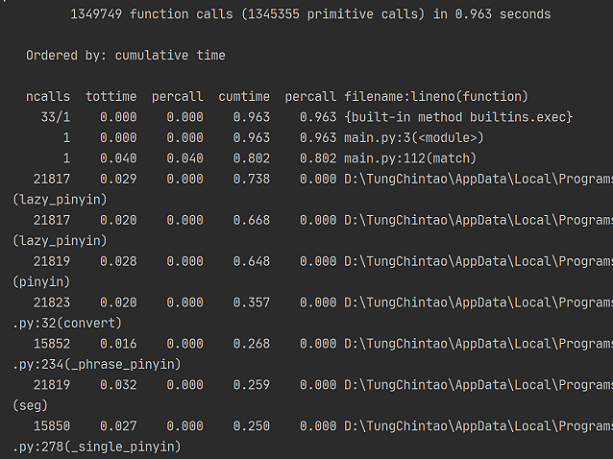
可以看到,总的函数调用从1556858减少到了1349749,减少了20多万个调用?有点被吓到了....
总的运行时间也减少了
(3.3)计算模块部分单元测试展示。
(1)部分单元测试函数展示:
- test_get_comb:主要验证是否能正确得到敏感词的不同组合以用于构造状态树:
def test_get_comb(self):
data1 = ['1', '2']
data2 = ['3', '4']
data3 = ['5', '6']
ans1 = [['1', '2'], ['1', '4'], ['1', '6'], ['3', '2'], ['3', '4'],
['3', '6'], ['5', '2'], ['5', '4'], ['5', '6']]
result1 = []
get_comb(data1, data2, data3, [], result1, 0)
self.assertEqual(result1, ans1)
- test_generate_ass_event_dict:主要验证能否构造正确的辅助状态树:
def test_generate_ass_event_dict(self):
dfa = main.DFA(['你好', 'hello'])
ans = {'亻': {'is_end': False, '尔': {'is_end': 'ni'}}, '女': {'is_end': False, '子': {'is_end': 'hao'}}}
result = dfa.ass_even_dict
self.assertEqual(result, ans)
- test_generate_state_event_dict:主要验证能否构造正确的主状态树:
def test_generate_state_event_dict(self):
dfa = main.DFA(['你好', 'hello'])
ans = {'ni': {'is_end': False, 'hao': {'is_end': '你好'}, 'h': {'is_end': '你好', 'a': {'is_end': False, 'o': {'is_end': '你好'}}}}, 'n': {'is_end': False, 'i': {'is_end': False, 'hao': {'is_end': '你好'}, 'h': {'is_end': '你好', 'a': {'is_end': False, 'o': {'is_end': '你好'}}}}, 'hao': {'is_end': '你好'}, 'h': {'is_end': '你好', 'a': {'is_end': False, 'o': {'is_end': '你好'}}}}, 'h': {'is_end': False, 'e': {'is_end': False, 'l': {'is_end': False, 'l': {'is_end': False, 'o': {'is_end': 'hello'}}}}}}
result = dfa.state_event_dict
self.assertEqual(result, ans)
- test_pianpan_toPianpan: 主要验证能否正确将左右结构的汉字拆分为偏旁
def test_pianpan_toPianpan1(self):
pp = Pianpan()
result = pp.toPianpan('你')
ans = '亻尔'
self.assertEqual(result, ans)
def test_pianpan_toPianpan2(self):
pp = Pianpan()
result = pp.toPianpan('开')
ans = '开'
self.assertEqual(result,ans)
- test_dfa_match 1~n:主要验证能否正确匹配敏感词(该函数过多,不在此展示)
(2)单元测试覆盖率
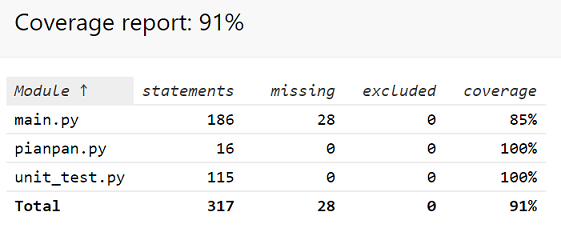
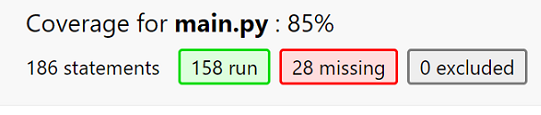

(3)ans的对比
左边是我的答案,右边是测试组给出的答案,多了几个也是挺离谱的.....

(3.4)计算模块部分异常处理说明。
- 命令行参数异常
if len(sys.argv) != 4:
print('Wrong number of parameters!\nPlease re-enter!')
exit(0)
- 文件读取错误异常
def try_file_path(file_path):
try:
f = open(file_path, encoding='utf-8')
except Exception as msg:
print(msg)
exit(0)
else:
f.close()
三、心得
(4.1)在完成本次作业过程的心得体会
1.发现自己在算法和数据结构方面还存在许多不足,有点真正理解了为什么都在强调算法与数据结构的重要性;
2.对于git以及的使用更加熟练;
3.对于知识的搜集能力、第三方库的查阅和使用能力有所提升;
4.前期真的不用急着写代码,设计和规划真的非常非常重要,在做这个作业时,我就是前期的规划没有做好,饶了很多弯路;
5.最重要的放最后,要注意代码的整体架构!!!不要只经过简单的思考就直接去写代码!!!我在做这次作业时,是一个阶段一个阶段完成的,先完成基础功能,再拓展出谐音,拼音,部首,缩写,但由于整体的架构没做好,每次有了简单的思路就直接写了,导致后期debug弄了很久,直接就是code一小时,debug一整天。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号