
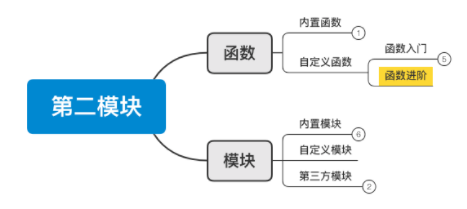
2、函数&模块
第二模块 函数&模块
从今天开始,我们将进入系列课程第二模块的的学习。
第一模块主要是学习python基础知识,从第二模块开始就可以通过程序去解决工作中实际的问题。
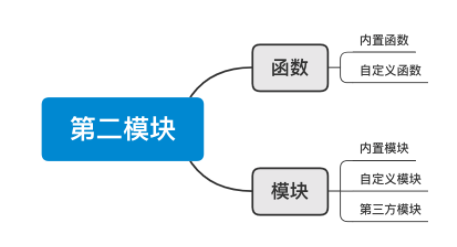
从今天开始,我们将进入第二模块的学习,此模块主要包含两大部分:
-
函数,一个用于专门实现某个功能的代码块(可重用)。
-
内置函数
len、bin、oct、hex 等 -
自定义函数
def send_email(): # 写了10行代码,实现了发送邮件。 pass send_email()# 定义了一个函数,功能代码块 def send_email(): # 写了10行代码,实现了发送邮件。 pass goods = [ {"name": "电脑", "price": 1999}, {"name": "鼠标", "price": 10}, {"name": "游艇", "price": 20}, {"name": "美女", "price": 998} ] for index in range(len(goods)): item = goods[index] print(index + 1, item['name'], item['price']) # 调用并执行函数 send_email() while True: num = input("请输入要选择的商品序号(Q/q):") # "1" if num.upper() == "Q": break if not num.isdecimal(): print("用输入的格式错误") break num = int(num) send_email() if num > 4 or num < 0: print("范围选择错误") break target_index = num - 1 choice_item = goods[target_index] print(choice_item["name"], choice_item['price']) send_email()
-
-
模块,集成了很多功能的函数集合。
-
内置模块,Python内部帮助我们提供好的。
import random num = random.randint(0,19)import decimal v1 = decimal.Decimal("0.1") v2 = decimal.Decimal("0.2") v3 = v1 + v2 print(v3) # 0.3 -
第三方模块,网上下载别人写好的模块(功能集合)。
-
自定义模块
-
day09 文件操作相关
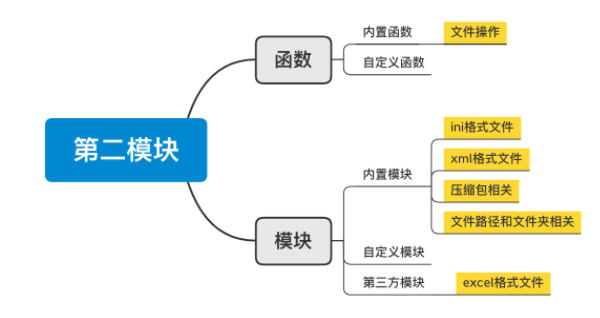
课程目标:掌握基于Python对文件相关操作。
课程概要:
- 文件操作
- 文件夹和路径
- csv格式文件
- ini格式文件
- xml格式文件
- excel文件
- 压缩文件
注意:每种格式包含很多相关操作,大家在学习的过程中只要掌握知识点的用法,参考笔记可以实现相关的练习即可,不必背会(在企业开发过程中也是边搜边实现。
1. 文件操作
在学习文件操作之前,先来回顾一下编码的相关以及先关数据类型的知识。
-
字符串类型(str),在程序中用于表示文字信息,本质上是unicode编码中的二进制。
name = "武沛齐" -
字节类型(bytes)
-
可表示文字信息,本质上是utf-8/gbk等编码的二进制(对unicode进行压缩,方便文件存储和网络传输。)
name = "武沛齐" data = name.encode('utf-8') print(data) # b'\xe6\xad\xa6\xe6\xb2\x9b\xe9\xbd\x90' result = data.decode('utf-8') print(result) # "武沛齐" -
可表示原始二进制(图片、文件等信息)
-
1.1 读文件
-
读文本文件
# 1.打开文件 # - 路径: # 相对路径:'info.txt' # 绝对路径:'/Users/wupeiqi/PycharmProjects/luffyCourse/day09/info.txt' # - 模式 # rb,表示读取文件原始的二进制(r, 读 read;b, 二进制 binary;) # 1.打开文件 file_object = open('info.txt', mode='rb') # 2.读取文件内容,并赋值给data data = file_object.read() # 3.关闭文件 file_object.close() print(data) # b'alex-123\n\xe6\xad\xa6\xe6\xb2\x9b\xe9\xbd\x90-123' text = data.decode("utf-8") print(text)# 1.打开文件 file_object = open('info.txt', mode='rt', encoding='utf-8') # 2.读取文件内容,并赋值给data data = file_object.read() # 3.关闭文件 file_object.close() print(data) -
读图片等非文本内容文件。
file_object = open('a1.png', mode='rb') data = file_object.read() file_object.close() print(data) # \x91\xf6\xf2\x83\x8aQFfv\x8b7\xcc\xed\xc3}\x7fT\x9d{.3.\xf1{\xe8\...
注意事项:
-
路径
- 相对路径,你的程序到底在哪里运行的?
- 相对路径,你的程序到底在哪里运行的?

-
绝对路径
# 1.打开文件 file_object = open('/Users/wupeiqi/PycharmProjects/luffyCourse/day09/info.txt', mode='rt', encoding='utf-8') # 2.读取文件内容,并赋值给data data = file_object.read() # 3.关闭文件 file_object.close()windows系统中写绝对路径容易出问题:
# file_object = open('C:\\new\\info.txt', mode='rt', encoding='utf-8') file_object = open(r'C:\new\info.txt', mode='rt', encoding='utf-8') data = file_object.read() file_object.close() print(data) -
读文件时,文件不存在程序会报错。
Traceback (most recent call last): File "/Users/wupeiqi/PycharmProjects/luffyCourse/day09/2.读文件.py", line 2, in <module> file_object = open('infower.txt', mode='rt', encoding='utf-8') FileNotFoundError: [Errno 2] No such file or directory: 'infower.txt'# 判断路径是否存在? import os file_path = "/Users/wupeiqi/PycharmProjects/luffyCourse/day09/info.txt" exists = os.path.exists(file_path) if exists: # 1.打开文件 file_object = open('infower.txt', mode='rt', encoding='utf-8') # 2.读取文件内容,并赋值给data data = file_object.read() # 3.关闭文件 file_object.close() print(data) else: print("文件不存在")
1.2 写文件
-
写文本文件
# 1.打开文件 # 路径:t1.txt # 模式:wb(要求写入的内容需要是字节类型) file_object = open("t1.txt", mode='wb') # 2.写入内容 file_object.write( "武沛齐".encode("utf-8") ) # 3.文件关闭 file_object.close()file_object = open("t1.txt", mode='wt', encoding='utf-8') file_object.write("武沛齐") file_object.close() -
写图片等文件
f1 = open('a1.png',mode='rb') content = f1.read() f1.close() f2 = open('a2.png',mode='wb') f2.write(content) f2.close()
基础案例:
# 案例1:用户注册
"""
user = input("请输入用户名:")
pwd = input("请输入密码:")
data = "{}-{}".format(user, pwd)
file_object = open("files/info.txt", mode='wt', encoding='utf-8')
file_object.write(data)
file_object.close()
"""
# 案例2:多用户注册
"""
# w写入文件,先清空文件;再在文件中写入内容。
file_object = open("files/info.txt", mode='wt', encoding='utf-8')
while True:
user = input("请输入用户名:")
if user.upper() == "Q":
break
pwd = input("请输入密码:")
data = "{}-{}\n".format(user, pwd)
file_object.write(data)
file_object.close()
"""
小高级案例:(超前)
利用Python想某个网址发送请求并获取结果(利用第三方的模块)
下载第三方模块
pip install requests/Library/Frameworks/Python.framework/Versions/3.9/bin/pip3 install requests
使用第三方模块
import requests res = requests.get(url="网址") print(res)
# 案例1:去网上下载一点文本,文本信息写入文件。
import requests
res = requests.get(
url="https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20",
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
)
# 网络传输的原始二进制信息(bytes)
# res.content
file_object = open('files/log1.txt', mode='wb')
file_object.write(res.content)
file_object.close()
# 案例2:去网上下载一张图片,图片写入本地文件。
import requests
res = requests.get(
url="https://hbimg.huabanimg.com/c7e1461e4b15735fbe625c4dc85bd19904d96daf6de9fb-tosv1r_fw1200",
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
)
# 网络传输的原始二进制信息(bytes)
# res.content
file_object = open('files/美女.png', mode='wb')
file_object.write(res.content)
file_object.close()
注意事项:
- 路径
- 绝对路径
- 相对路径
- 文件不存在时,w模式会新建然后再写入内容;文件存在时,w模式会清空文件再写入内容。
1.3 文件打开模式
上文我们基于文件操作基本实现了读、写的功能,其中涉及的文件操作模式:rt、rb、wt、wb,其实在文件操作中还有其他的很多模式。
========= ===============================================================
Character Meaning
--------- ---------------------------------------------------------------
'r' open for reading (default)
'w' open for writing, truncating the file first
'x' create a new file and open it for writing
'a' open for writing, appending to the end of the file if it exists
'b' binary mode
't' text mode (default)
'+' open a disk file for updating (reading and writing)
The default mode is 'rt' (open for reading text).
关于文件的打开模式常见应用有:
-
只读:
r、rt、rb(用)- 存在,读
- 不存在,报错
-
只写:
w、wt、wb(用)- 存在,清空再写
- 不存在,创建再写
-
只写:
x、xt、xb- 存在,报错
- 不存在,创建再写。
-
只写:
a、at、ab【尾部追加】(用)- 存在,尾部追加。
- 不存在,创建再写。
-
读写
-
r+、rt+、rb+,默认光标位置:起始位置
file_object = open('info.txt', mode='rt+') # 读取内容 data = file_object.read() print(data) # 写入内容 file_object.write("你好呀") file_object.close()file_object = open('info.txt', mode='rt+') # 写入内容 file_object.write("alex") # 读取内容 data = file_object.read() print(data) # -123 file_object.close() -
w+、wt+、wb+,默认光标位置:起始位置(清空文件)
file_object = open('info.txt', mode='wt+') # 读取内容 data = file_object.read() print(data) # 写入内容 file_object.write("你好呀") # 将光标位置重置起始 file_object.seek(0) # 读取内容 data = file_object.read() print(data) file_object.close() -
x+、xt+、xb+,默认光标位置:起始位置(新文件)
-
a+、at+、ab+,默认光标位置:末尾
file_object = open('info.txt', mode='at+') # 写入内容 file_object.write("武沛齐") # 将光标位置重置起始 file_object.seek(0) # 读取内容 data = file_object.read() print(data) file_object.close()
-
多用户注册案例:
while True:
user = input("用户名:")
if user.upper() == "Q":
break
pwd = input("密码:")
data = "{}-{}\n".format(user, pwd)
file_object = open('files/account.txt', mode='a')
file_object.write(data)
file_object.close()
file_object = open('files/account.txt', mode='a')
while True:
user = input("用户名:")
if user.upper() == "Q":
break
pwd = input("密码:")
data = "{}-{}\n".format(user, pwd)
file_object.write(data)
file_object.close()
1.4 常见功能
在上述对文件的操作中,我们只使用了write和read来对文件进行读写,其实在文件操作中还有很多其他的功能来辅助实现更好的读写文件的内容。
-
read,读
-
读所有【常用】
f = open('info.txt', mode='r',encoding='utf-8') data = f.read() f.close()f = open('info.txt', mode='rb') data = f.read() f.close() -
读n个字符(字节)【会用到】
f = open('info.txt', mode='r', encoding='utf-8') # 读1个字符 data = f.read(1) f.close() print(data) # 武f = open('info.txt', mode='r',encoding='utf-8') # 读1个字符 chunk1 = f.read(1) chunk2 = f.read(2) print(chunk1,chunk2) f.close()f = open('info.txt', mode='rb') # 读1个字节 data = f.read(3) f.close() print(data, type(data)) # b'\xe6\xad\xa6' <class 'bytes'>f = open('info.txt', mode='rb') # 读1个字节 chunk1 = f.read(3) chunk2 = f.read(3) chunk3 = f.read(1) print(chunk1,chunk2,chunk3) f.close()
-
-
readline,读一行
f = open('info.txt', mode='r', encoding='utf-8') v1 = f.readline() print(v1) v2 = f.readline() print(v2) f.close()f = open('info.txt', mode='r', encoding='utf-8') v1 = f.readline() print(v1) f.close() f = open('info.txt', mode='r', encoding='utf-8') v2 = f.readline() print(v2) f.close() -
readlines,读所有行,每行作为列表的一个元素
f = open('info.txt', mode='rb') data_list = f.readlines() f.close() print(data_list) -
循环,读大文件(readline加强版)【常见】
f = open('info.txt', mode='r', encoding='utf-8') for line in f: print(line.strip()) f.close() -
write,写
f = open('info.txt', mode='a',encoding='utf-8') f.write("武沛齐") f.close()f = open('info.txt', mode='ab') f.write( "武沛齐".encode("utf-8") ) f.close() -
flush,刷到硬盘
f = open('info.txt', mode='a',encoding='utf-8') while True: # 不是写到了硬盘,而是写在缓冲区,系统会将缓冲区的内容刷到硬盘。 f.write("武沛齐") f.flush() f.close()file_object = open('files/account.txt', mode='a') while True: user = input("用户名:") if user.upper() == "Q": break pwd = input("密码:") data = "{}-{}\n".format(user, pwd) file_object.write(data) file_object.flush() file_object.close() -
移动光标位置(字节)
f = open('info.txt', mode='r+', encoding='utf-8') # 移动到指定字节的位置 f.seek(3) f.write("武沛齐") f.close()注意:在a模式下,调用write在文件中写入内容时,永远只能将内容写入到尾部,不会写到光标的位置。
-
获取当前光标位置
f = open('info.txt', mode='r', encoding='utf-8') p1 = f.tell() print(p1) # 0 f.read(3) # 读3个字符 3*3=9字节 p2 = f.tell() print(p2) # 9 f.close()f = open('info.txt', mode='rb') p1 = f.tell() print(p1) # 0 f.read(3) # 读3个字节 p2 = f.tell() print(p2) # 3 f.close()
1.5 上下文管理
之前对文件进行操作时,每次都要打开和关闭文件,比较繁琐且容易忘记关闭文件。
以后再进行文件操作时,推荐大家使用with上下文管理,它可以自动实现关闭文件。
with open("xxxx.txt", mode='rb') as file_object:
data = file_object.read()
print(data)
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
with open("xxxx.txt", mode='rb') as f1, open("xxxx.txt", mode='rb') as f2:
pass
练习题
-
补充代码:实现下载视频并保存到本地
import requests res = requests.get( url=" https://f.video.weibocdn.com/000pTZJLgx07IQgaH7HW010412066BJV0E030.mp4?label=mp4_720p&template=1280x720.25.0&trans_finger=1f0da16358befad33323e3a1b7f95fc9&media_id=4583105541898354&tp=8x8A3El:YTkl0eM8&us=0&ori=1&bf=2&ot=h&ps=3lckmu&uid=3ZoTIp&ab=3915-g1 ,966-g1,3370-g1,3601-g0,3601-g0,3601-g0,1493-g0,1192-g0,1191-g0,1258-g0&Expires=1608204895&ssig=NdYpDIEXSS&KID=unistore,video", headers={ "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36" } ) # 视频的文件内容 res.content -
日志分析,计算某用户
223.73.89.192访问次数。日志文件如下:access.log49.89.167.91 - - [17/Dec/2020:03:43:50 +0800] "GET /wiki/detail/3/40 HTTP/1.1" 301 0 "-" "Mozilla/5.0(Linux;Android 5.1.1;OPPO A33 Build/LMY47V;wv) AppleWebKit/537.36(KHTML,link Gecko) Version/4.0 Chrome/43.0.2357.121 Mobile Safari/537.36 LieBaoFast/4.51.3" "-" 49.89.167.91 - - [17/Dec/2020:03:44:11 +0800] "GET /wiki/detail/3/40/ HTTP/1.1" 200 8033 "-" "Mozilla/5.0(Linux;Android 5.1.1;OPPO A33 Build/LMY47V;wv) AppleWebKit/537.36(KHTML,link Gecko) Version/4.0 Chrome/43.0.2357.121 Mobile Safari/537.36 LieBaoFast/4.51.3" "-" 203.208.60.66 - - [17/Dec/2020:03:47:58 +0800] "GET /media/uploads/2019/11/17/pic/s1.png HTTP/1.1" 200 710728 "-" "Googlebot-Image/1.0" "-" 223.73.89.192 - - [17/Dec/2020:03:48:26 +0800] "GET /wiki/detail/3/40/ HTTP/1.1" 200 8033 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" 223.73.89.192 - - [17/Dec/2020:03:48:26 +0800] "GET /static/stark/plugins/font-awesome/css/font-awesome.css HTTP/1.1" 200 37414 "https://pythonav.com/wiki/detail/3/40/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" 223.73.89.192 - - [17/Dec/2020:03:48:26 +0800] "GET /static/stark/plugins/bootstrap/css/bootstrap.css HTTP/1.1" 200 146010 "https://pythonav.com/wiki/detail/3/40/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" 223.73.89.192 - - [17/Dec/2020:03:48:26 +0800] "GET /static/web/css/commons.css HTTP/1.1" 200 3674 "https://pythonav.com/wiki/detail/3/40/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" 223.73.89.192 - - [17/Dec/2020:03:48:26 +0800] "GET /static/mdeditor/editormd/css/editormd.preview.css HTTP/1.1" 200 60230 "https://pythonav.com/wiki/detail/3/40/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" 223.73.89.192 - - [17/Dec/2020:03:48:26 +0800] "GET /static/stark/js/jquery-3.3.1.min.js HTTP/1.1" 200 86927 "https://pythonav.com/wiki/detail/3/40/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" 223.73.89.192 - - [17/Dec/2020:03:48:26 +0800] "GET /static/stark/plugins/bootstrap/js/bootstrap.min.js HTTP/1.1" 200 37045 "https://pythonav.com/wiki/detail/3/40/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" 223.73.89.192 - - [17/Dec/2020:03:48:26 +0800] "GET /static/mdeditor/editormd/lib/marked.min.js HTTP/1.1" 200 19608 "https://pythonav.com/wiki/detail/3/40/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" 223.73.89.192 - - [17/Dec/2020:03:48:27 +0800] "GET /static/mdeditor/editormd/lib/prettify.min.js HTTP/1.1" 200 17973 "https://pythonav.com/wiki/detail/3/40/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" 223.73.89.192 - - [17/Dec/2020:03:48:27 +0800] "GET /static/mdeditor/editormd/fonts/fontawesome-webfont.woff2?v=4.3.0 HTTP/1.1" 200 56780 "https://pythonav.com/static/mdeditor/editormd/css/editormd.preview.css" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" 223.73.89.192 - - [17/Dec/2020:03:48:27 +0800] "GET /static/mdeditor/editormd/editormd.js HTTP/1.1" 200 163262 "https://pythonav.com/wiki/detail/3/40/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" 223.73.89.192 - - [17/Dec/2020:03:48:28 +0800] "GET /static/mdeditor/mdeditor-preview-init.js HTTP/1.1" 200 261 "https://pythonav.com/wiki/detail/3/40/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" 223.73.89.192 - - [17/Dec/2020:03:48:29 +0800] "GET /static/stark/plugins/font-awesome/fonts/fontawesome-webfont.woff2?v=4.7.0 HTTP/1.1" 200 77160 "https://pythonav.com/static/stark/plugins/font-awesome/css/font-awesome.css" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" 223.73.89.192 - - [17/Dec/2020:03:48:29 +0800] "GET /media/uploads/2019/02/22/Gobook/_book/ssl2.png HTTP/1.1" 200 203535 "https://pythonav.com/wiki/detail/3/40/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 Edg/87.0.664.60" "-" -
日志分析升级,计算所有用户的访问次数。
-
筛选出股票 当前价大于 20 的所有股票数据。
股票代码,股票名称,当前价,涨跌额,涨跌幅,年初至今,成交量,成交额,换手率,市盈率(TTM),股息率,市值 SH601778,N晶科,6.29,+1.92,+43.94%,+43.94%,259.66万,1625.52万,0.44%,22.32,-,173.95亿 SH688566,吉贝尔,52.66,+6.96,+15.23%,+122.29%,1626.58万,8.09亿,42.29%,89.34,-,98.44亿 SH688268,华特气体,88.80,+11.72,+15.20%,+102.51%,622.60万,5.13亿,22.87%,150.47,-,106.56亿 SH600734,实达集团,2.60,+0.24,+10.17%,-61.71%,1340.27万,3391.14万,2.58%,亏损,0.00%,16.18亿 SH900957,凌云B股,0.36,+0.033,+10.09%,-35.25%,119.15万,42.10万,0.65%,44.65,0.00%,1.26亿 SZ000584,哈工智能,6.01,+0.55,+10.07%,-4.15%,2610.86万,1.53亿,4.36%,199.33,0.26%,36.86亿 SH600599,熊猫金控,6.78,+0.62,+10.06%,-35.55%,599.64万,3900.23万,3.61%,亏损,0.00%,11.25亿 SH600520,文一科技,8.21,+0.75,+10.05%,-24.05%,552.34万,4464.69万,3.49%,亏损,0.00%,13.01亿 SH603682,锦和商业,11.73,+1.07,+10.04%,+48.29%,2746.63万,3.15亿,29.06%,29.62,-,55.42亿 SZ300831,派瑞股份,12.27,+1.12,+10.04%,+208.29%,25.38万,311.41万,0.32%,60.59,-,39.26亿 -
根据要求修改文件的内容,原文件内容如下:
ha.confglobal log 127.0.0.1 local2 daemon maxconn 256 log 127.0.0.1 local2 info defaults log global mode http timeout connect 5000ms timeout client 50000ms timeout server 50000ms option dontlognull listen stats :8888 stats enable stats uri /admin stats auth admin:1234 frontend oldboy.org bind 0.0.0.0:80 option httplog option httpclose option forwardfor log global acl www hdr_reg(host) -i www.luffycity.org use_backend www.luffycity.com if www backend www.luffycity.com server 100.1.7.9 100.1.7.9 weight 20 maxconn 3000 ...请将文件中的
luffycity修改为pythonav。
练习题答案
# 1.下载视频
import requests
res = requests.get(
url=" https://f.video.weibocdn.com/000pTZJLgx07IQgaH7HW010412066BJV0E030.mp4?label=mp4_720p&template=1280x720.25.0&trans_finger=1f0da16358befad33323e3a1b7f95fc9&media_id=4583105541898354&tp=8x8A3El:YTkl0eM8&us=0&ori=1&bf=2&ot=h&ps=3lckmu&uid=3ZoTIp&ab=3915-g1 ,966-g1,3370-g1,3601-g0,3601-g0,3601-g0,1493-g0,1192-g0,1191-g0,1258-g0&Expires=1608204895&ssig=NdYpDIEXSS&KID=unistore,video",
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
)
# 视频的文件内容
with open('nba.mp4',mode='wb') as file_object:
file_object.write(res.content)
# 2.日志计数
total_count = 0
ip = "223.73.89.192"
with open('files/access.log',mode='r',encoding='utf-8') as file_object:
for line in file_object:
if line.startswith(ip):
total_count += 1
print(total_count)
total_count = 0
ip = "223.73.89.192"
with open('files/access.log', mode='r', encoding='utf-8') as file_object:
for line in file_object:
if not line.startswith(ip):
continue
total_count += 1
print(total_count)
# 3.日志计数升级版
user_dict = {}
with open('files/access.log',mode='r',encoding='utf-8') as file_object:
for line in file_object:
user_ip = line.split(" ")[0]
if user_ip in user_dict:
# user_dict[user_ip] = user_dict[user_ip] + 1
user_dict[user_ip] += 1
else:
user_dict[user_ip] = 1
print(user_dict)
# 4.筛选出股票 当前价大于 20 的所有股票数据。
with open('files/stock.txt', mode='r', encoding='utf-8') as file_object:
# 1.跳过第一行
file_object.readline()
# 2.接着往下读
for line in file_object:
text = line.split(',')[2]
price = float(text)
if price > 20:
print(line.strip())
# 5.根据要求修改文件的内容
"""
- 文件读到内存,再通过replace(适用于小文件,不适用大文件),replace会把没有匹配到的内容重新赋值
- 挨个位置读文件的内容,遇到luffycity将其替换成pythonav。(不可取)
- 同时打开两个文件,读+写。(适用于小文件,适用大文件)
"""
with open('files/ha.conf', mode='r', encoding='utf-8') as read_file_object, open('files/new.conf', mode='w',
encoding='utf-8') as write_file_object:
for line in read_file_object:
new_line = line.replace("luffycity", 'pythonav')
write_file_object.write(new_line)
# 重命名
import shutil
shutil.move("files/new.conf", 'files/ha.conf')
2.csv格式文件
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
对于这种格式的数据,我们需要利用open函数来读取文件并根据逗号分隔的特点来进行处理。
股票代码,股票名称,当前价,涨跌额,涨跌幅,年初至今
SH601778,N晶科,6.29,+1.92,-43.94%,+43.94%
SH688566,吉贝尔,52.66,+6.96,+15.23%,+122.29%
...
练习题案例:下载文档中的所有图片且以用户名为图片名称存储。
ID,用户名,头像
26044585,Hush,https://hbimg.huabanimg.com/51d46dc32abe7ac7f83b94c67bb88cacc46869954f478-aP4Q3V
19318369,柒十一,https://hbimg.huabanimg.com/703fdb063bdc37b11033ef794f9b3a7adfa01fd21a6d1-wTFbnO
15529690,Law344,https://hbimg.huabanimg.com/b438d8c61ed2abf50ca94e00f257ca7a223e3b364b471-xrzoQd
18311394,Jennah·,https://hbimg.huabanimg.com/4edba1ed6a71797f52355aa1de5af961b85bf824cb71-px1nZz
18009711,可洛爱画画,https://hbimg.huabanimg.com/03331ef39b5c7687f5cc47dbcbafd974403c962ae88ce-Co8AUI
30574436,花姑凉~,https://hbimg.huabanimg.com/2f5b657edb9497ff8c41132e18000edb082d158c2404-8rYHbw
17740339,小巫師,https://hbimg.huabanimg.com/dbc6fd49f1915545cc42c1a1492a418dbaebd2c21bb9-9aDqgl
18741964,桐末tonmo,https://hbimg.huabanimg.com/b60cee303f62aaa592292f45a1ed8d5be9873b2ed5c-gAJehO
30535005,TANGZHIQI,https://hbimg.huabanimg.com/bbd08ee168d54665bf9b07899a5c4a4d6bc1eb8af77a4-8Gz3K1
31078743,你的老杨,https://hbimg.huabanimg.com/c46fbc3c9a01db37b8e786cbd7174bbd475e4cda220f4-F1u7MX
25519376,尺尺寸,https://hbimg.huabanimg.com/ee29ee198efb98f970e3dc2b24c40d89bfb6f911126b6-KGvKes
21113978,C-CLong,https://hbimg.huabanimg.com/7fa6b2a0d570e67246b34840a87d57c16a875dba9100-SXsSeY
24674102,szaa,https://hbimg.huabanimg.com/0716687b0df93e8c3a8e0925b6d2e4135449cd27597c4-gWdv24
30508507,爱起床的小灰灰,https://hbimg.huabanimg.com/4eafdbfa21b2f300a7becd8863f948e5e92ef789b5a5-1ozTKq
12593664,yokozen,https://hbimg.huabanimg.com/cd07bbaf052b752ed5c287602404ea719d7dd8161321b-cJtHss
16899164,一阵疯,https://hbimg.huabanimg.com/0940b557b28892658c3bcaf52f5ba8dc8402100e130b2-G966Uz
847937,卩丬My㊊伴er彎,https://hbimg.huabanimg.com/e2d6bb5bc8498c6f607492a8f96164aa2366b104e7a-kWaH68
31010628,慢慢即漫漫,https://hbimg.huabanimg.com/c4fb6718907a22f202e8dd14d52f0c369685e59cfea7-82FdsK
13438168,海贼玩跑跑,https://hbimg.huabanimg.com/1edae3ce6fe0f6e95b67b4f8b57c4cebf19c501b397e-BXwiW6
28593155,源稚生,https://hbimg.huabanimg.com/626cfd89ca4c10e6f875f3dfe1005331e4c0fd7fd429-9SeJeQ
28201821,合伙哼哼,https://hbimg.huabanimg.com/f59d4780531aa1892b80e0ec94d4ec78dcba08ff18c416-769X6a
28255146,漫步AAA,https://hbimg.huabanimg.com/3c034c520594e38353a039d7e7a5fd5e74fb53eb1086-KnpLaL
30537613,配䦹,https://hbimg.huabanimg.com/efd81d22c1b1a2de77a0e0d8e853282b83b6bbc590fd-y3d4GJ
22665880,日后必火,https://hbimg.huabanimg.com/69f0f959979a4fada9e9e55f565989544be88164d2b-INWbaF
16748980,keer521521,https://hbimg.huabanimg.com/654953460733026a7ef6e101404055627ad51784a95c-B6OFs4
30536510,“西辞”,https://hbimg.huabanimg.com/61cfffca6b2507bf51a507e8319d68a8b8c3a96968f-6IvMSk
30986577,艺成背锅王,https://hbimg.huabanimg.com/c381ecc43d6c69758a86a30ebf72976906ae6c53291f9-9zroHF
26409800,CsysADk7,https://hbimg.huabanimg.com/bf1d22092c2070d68ade012c588f2e410caaab1f58051-ahlgLm
30469116,18啊全阿,https://hbimg.huabanimg.com/654953460733026a7ef6e101404055627ad51784a95c-B6OFs4
15514336,W/小哥,https://hbimg.huabanimg.com/a30f5967fc0acf81421dd49650397de63c105b9ead1c-nVRrNl
17473505,椿の花,https://hbimg.huabanimg.com/0e38d810e5a24f91ebb251fd3aaaed8bb37655b14844c-pgNJBP
19165177,っ思忆゜♪,https://hbimg.huabanimg.com/4815ea0e4905d0f3bb82a654b481811dadbfe5ce2673-vMVr0B
16059616,格林熊丶,https://hbimg.huabanimg.com/8760a2b08d87e6ed4b7a9715b1a668176dbf84fec5b-jx14tZ
30734152,sCWVkJDG,https://hbimg.huabanimg.com/f31a5305d1b8717bbfb897723f267d316e58e7b7dc40-GD3e22
24019677,虚无本心,https://hbimg.huabanimg.com/6fdfa9834abe362e978b517275b06e7f0d5926aa650-N1xCXE
16670283,Y-雨后天空,https://hbimg.huabanimg.com/a3bbb0045b536fc27a6d2effa64a0d43f9f5193c177f-I2vHaI
21512483,汤姆2,https://hbimg.huabanimg.com/98cc50a61a7cc9b49a8af754ffb26bd15764a82f1133-AkiU7D
16441049,笑潇啸逍小鱼,https://hbimg.huabanimg.com/ae8a70cd85aff3a8587ff6578d5cf7620f3691df13e46-lmrIi9
24795603,v,https://hbimg.huabanimg.com/a7183cc3a933aa129d7b3230bf1378fd8f5857846cc5-3tDtx3
29819152,妮玛士珍多,https://hbimg.huabanimg.com/ca4ecb573bf1ff0415c7a873d64470dedc465ea1213c6-RAkArS
19101282,陈勇敢❤,https://hbimg.huabanimg.com/ab6d04ebaff3176e3570139a65155856871241b58bc6-Qklj2E
28337572,爱意随风散,https://hbimg.huabanimg.com/117ad8b6eeda57a562ac6ab2861111a793ca3d1d5543-SjWlk2
17342758,幸运instant,https://hbimg.huabanimg.com/72b5f9042ec297ae57b83431123bc1c066cca90fa23-3MoJNj
18483372,Beau染,https://hbimg.huabanimg.com/077115cb622b1ff3907ec6932e1b575393d5aae720487-d1cdT9
22127102,栽花的小蜻蜓,https://hbimg.huabanimg.com/6c3cbf9f27e17898083186fc51985e43269018cc1e1df-QfOIBG
13802024,LoveHsu,https://hbimg.huabanimg.com/f720a15f8b49b86a7c1ee4951263a8dbecfe3e43d2d-GPEauV
22558931,白驹过隙丶梨花泪う,https://hbimg.huabanimg.com/e49e1341dfe5144da5c71bd15f1052ef07ba7a0e1296b-jfyfDJ
11762339,cojoy,https://hbimg.huabanimg.com/5b27f876d5d391e7c4889bc5e8ba214419eb72b56822-83gYmB
30711623,雪碧学长呀,https://hbimg.huabanimg.com/2c288a1535048b05537ba523b3fc9eacc1e81273212d1-nr8M4t
18906718,西霸王,https://hbimg.huabanimg.com/7b02ad5e01bd8c0a29817e362814666a7800831c154a6-AvBDaG
31037856,邵阳的小哥哥,https://hbimg.huabanimg.com/654953460733026a7ef6e101404055627ad51784a95c-B6OFs4
26830711,稳健谭,https://hbimg.huabanimg.com/51547ade3f0aef134e8d268cfd4ad61110925aefec8a-NKPEYX
import os
import requests
with open('files/mv.csv', mode='r', encoding='utf-8') as file_object:
file_object.readline()
for line in file_object:
user_id, username, url = line.strip().split(',')
print(username, url)
# 1.根据URL下载图片
res = requests.get(
url=url,
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
)
# 检查images目录是否存在?不存在,则创建images目录
if not os.path.exists("images"):
# 创建images目录
os.makedirs("images")
# 2.将图片的内容写入到文件
with open("images/{}.png".format(username), mode='wb') as img_object:
img_object.write(res.content)
3.ini格式文件
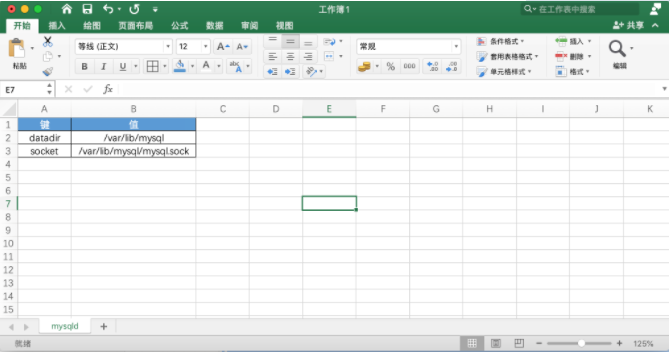
ini文件是Initialization File的缩写,平时用于存储软件的的配置文件。例如:MySQL数据库的配置文件。
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
log-bin=py-mysql-bin
character-set-server=utf8
collation-server=utf8_general_ci
log-error=/var/log/mysqld.log
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
[mysqld_safe]
log-error=/var/log/mariadb/mariadb.log
pid-file=/var/run/mariadb/mariadb.pid
[client]
default-character-set=utf8
这种格式是可以直接使用open来出来,考虑到自己处理比较麻烦,所以Python为我们提供了更为方便的方式。
import configparser
config = configparser.ConfigParser()
config.read('files/my.ini', encoding='utf-8')
# config.read('/Users/wupeiqi/PycharmProjects/luffyCourse/day09/files/my.ini', encoding='utf-8')
# 1.获取所有的节点
"""
result = config.sections()
print(result) # ['mysqld', 'mysqld_safe', 'client']
"""
# 2.获取节点下的键值
"""
result = config.items("mysqld_safe")
print(result) # [('log-error', '/var/log/mariadb/mariadb.log'), ('pid-file', '/var/run/mariadb/mariadb.pid')]
for key, value in config.items("mysqld_safe"):
print(key, value)
"""
# 3.获取某个节点下的键对应的值
"""
result = config.get("mysqld","collation-server")
print(result)
"""
# 4.其他
# 4.1 是否存在节点
# v1 = config.has_section("client")
# print(v1)
# 4.2 添加一个节点
# config.add_section("group")
# config.set('group','name','wupeiqi')
# config.set('client','name','wupeiqi')
# config.write(open('files/new.ini', mode='w', encoding='utf-8'))
# 4.3 删除
# config.remove_section('client')
# config.remove_option("mysqld", "datadir")
# config.write(open('files/new.ini', mode='w', encoding='utf-8'))
-
读取所有节点
import configparser config = configparser.ConfigParser() config.read('/Users/wupeiqi/PycharmProjects/luffyCourse/day09/files/my.conf', encoding='utf-8') # config.read('my.conf', encoding='utf-8') ret = config.sections() print(ret) >>输出 ['mysqld', 'mysqld_safe', 'client'] -
读取节点下的键值
import configparser config = configparser.ConfigParser() config.read('/Users/wupeiqi/PycharmProjects/luffyCourse/day09/files/my.conf', encoding='utf-8') # config.read('my.conf', encoding='utf-8') item_list = config.items("mysqld_safe") print(item_list) >>输出 [('log-error', '/var/log/mariadb/mariadb.log'), ('pid-file', '/var/run/mariadb/mariadb.pid')] -
读取节点下值(根据 节点+键 )
import configparser config = configparser.ConfigParser() config.read('/Users/wupeiqi/PycharmProjects/luffyCourse/day09/files/my.conf', encoding='utf-8') value = config.get('mysqld', 'log-bin') print(value) >>输出 py-mysql-bin -
检查、删除、添加节点
import configparser config = configparser.ConfigParser() config.read('/Users/wupeiqi/PycharmProjects/luffyCourse/day09/files/my.conf', encoding='utf-8') # config.read('my.conf', encoding='utf-8') # 检查 has_sec = config.has_section('mysqld') print(has_sec) # 添加节点 config.add_section("SEC_1") # 节点中设置键值 config.set('SEC_1', 'k10', "123") config.set('SEC_1', 'name', "哈哈哈哈哈") config.add_section("SEC_2") config.set('SEC_2', 'k10', "123") # 修改之后写入原文件 conf.write(open('my.ini','w',encoding='utf-8')) # 内容写入新文件 config.write(open('/Users/wupeiqi/PycharmProjects/luffyCourse/day09/files/xxoo.conf', 'w')) # 删除节点 config.remove_section("SEC_2") # 删除节点中的键值 config.remove_option('SEC_1', 'k10') config.write(open('/Users/wupeiqi/PycharmProjects/luffyCourse/day09/files/new.conf', 'w'))
4.XML格式文件
可扩展标记语言,是一种简单的数据存储语言,XML 被设计用来传输和存储数据。
- 存储,可用来存放配置文件,例如:java的配置文件。
- 传输,网络传输时以这种格式存在,例如:早期ajax传输的数据、soap协议等。
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2026</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
注意:在Python开发中用的相对来比较少,大家作为了解即可(后期课程在讲解微信支付、微信公众号消息处理 时会用到基于xml传输数据)。
例如:https://developers.weixin.qq.com/doc/offiaccount/Message_Management/Receiving_standard_messages.html
4.1 读取文件和内容
from xml.etree import ElementTree as ET
# ET去打开xml文件
tree = ET.parse("files/xo.xml")
# 获取根标签
root = tree.getroot()
print(root) # <Element 'data' at 0x7f94e02763b0>
from xml.etree import ElementTree as ET
content = """
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
"""
root = ET.XML(content)
print(root) # <Element 'data' at 0x7fdaa019cea0>
4.2 读取节点数据
from xml.etree import ElementTree as ET
content = """
<data>
<country name="Liechtenstein" id="999" >
<rank>2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Panama">
<rank>69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
"""
# 获取根标签 data
root = ET.XML(content)
country_object = root.find("country")
print(country_object.tag, country_object.attrib)
gdppc_object = country_object.find("gdppc")
print(gdppc_object.tag,gdppc_object.attrib,gdppc_object.text)
from xml.etree import ElementTree as ET
content = """
<data>
<country name="Liechtenstein">
<rank>2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Panama">
<rank>69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
"""
# 获取根标签 data
root = ET.XML(content)
# 获取data标签的孩子标签
for child in root:
# child.tag = conntry
# child.attrib = {"name":"Liechtenstein"}
print(child.tag, child.attrib)
for node in child:
print(node.tag, node.attrib, node.text)
from xml.etree import ElementTree as ET
content = """
<data>
<country name="Liechtenstein">
<rank>2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Panama">
<rank>69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
"""
root = ET.XML(content)
for child in root.iter('year'):
print(child.tag, child.text)
from xml.etree import ElementTree as ET
content = """
<data>
<country name="Liechtenstein">
<rank>2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Panama">
<rank>69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
"""
root = ET.XML(content)
v1 = root.findall('country')
print(v1)
v2 = root.find('country').find('rank')
print(v2.text)
4.3 修改和删除节点
from xml.etree import ElementTree as ET
content = """
<data>
<country name="Liechtenstein">
<rank>2</rank>
<year>2023</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
</country>
<country name="Panama">
<rank>69</rank>
<year>2026</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
</country>
</data>
"""
root = ET.XML(content)
# 修改节点内容和属性
rank = root.find('country').find('rank')
print(rank.text)
rank.text = "999"
rank.set('update', '2020-11-11')
print(rank.text, rank.attrib)
############ 保存文件 ############
tree = ET.ElementTree(root)
tree.write("new.xml", encoding='utf-8')
# 删除节点
root.remove( root.find('country') )
print(root.findall('country'))
############ 保存文件 ############
tree = ET.ElementTree(root)
tree.write("newnew.xml", encoding='utf-8')
4.4 构建文档
<home>
<son name="儿1">
<grandson name="儿11"></grandson>
<grandson name="儿12"></grandson>
</son>
<son name="儿2"></son>
</home>
from xml.etree import ElementTree as ET
# 创建根标签
root = ET.Element("home")
# 创建节点大儿子
son1 = ET.Element('son', {'name': '儿1'})
# 创建小儿子
son2 = ET.Element('son', {"name": '儿2'})
# 在大儿子中创建两个孙子
grandson1 = ET.Element('grandson', {'name': '儿11'})
grandson2 = ET.Element('grandson', {'name': '儿12'})
son1.append(grandson1)
son1.append(grandson2)
# 把儿子添加到根节点中
root.append(son1)
root.append(son2)
tree = ET.ElementTree(root)
tree.write('oooo.xml', encoding='utf-8', short_empty_elements=False)
<famliy>
<son name="儿1">
<grandson name="儿11"></grandson>
<grandson name="儿12"></grandson>
</son>
<son name="儿2"></son>
</famliy>
from xml.etree import ElementTree as ET
# 创建根节点
root = ET.Element("famliy")
# 创建大儿子
son1 = root.makeelement('son', {'name': '儿1'})
# 创建小儿子
son2 = root.makeelement('son', {"name": '儿2'})
# 在大儿子中创建两个孙子
grandson1 = son1.makeelement('grandson', {'name': '儿11'})
grandson2 = son1.makeelement('grandson', {'name': '儿12'})
son1.append(grandson1)
son1.append(grandson2)
# 把儿子添加到根节点中
root.append(son1)
root.append(son2)
tree = ET.ElementTree(root)
tree.write('oooo.xml',encoding='utf-8')
<famliy>
<son name="儿1">
<age name="儿11">孙子</age>
</son>
<son name="儿2"></son>
</famliy>
from xml.etree import ElementTree as ET
# 创建根节点
root = ET.Element("famliy")
# 创建节点大儿子
son1 = ET.SubElement(root, "son", attrib={'name': '儿1'})
# 创建小儿子
son2 = ET.SubElement(root, "son", attrib={"name": "儿2"})
# 在大儿子中创建一个孙子
grandson1 = ET.SubElement(son1, "age", attrib={'name': '儿11'})
grandson1.text = '孙子'
et = ET.ElementTree(root) #生成文档对象
et.write("test.xml", encoding="utf-8")
<user><![CDATA[你好呀]]</user>
from xml.etree import ElementTree as ET
# 创建根节点
root = ET.Element("user")
root.text = "<![CDATA[你好呀]]"
et = ET.ElementTree(root) # 生成文档对象
et.write("test.xml", encoding="utf-8")
案例:
content = """<xml>
<ToUserName><![CDATA[gh_7f083739789a]]></ToUserName>
<FromUserName><![CDATA[oia2TjuEGTNoeX76QEjQNrcURxG8]]></FromUserName>
<CreateTime>1395658920</CreateTime>
<MsgType><![CDATA[event]]></MsgType>
<Event><![CDATA[TEMPLATESENDJOBFINISH]]></Event>
<MsgID>200163836</MsgID>
<Status><![CDATA[success]]></Status>
</xml>"""
from xml.etree import ElementTree as ET
info = {}
root = ET.XML(content)
for node in root:
# print(node.tag,node.text)
info[node.tag] = node.text
print(info)
5.Excel格式文件
Python内部未提供处理Excel文件的功能,想要在Python中操作Excel需要按照第三方的模块。
pip install openpyxl
此模块中集成了Python操作Excel的相关功能,接下来我们就需要去学习该模块提供的相关功能即可。

5.1 读Excel
-
读sheet
from openpyxl import load_workbook wb = load_workbook("files/p1.xlsx") # sheet相关操作 # 1.获取excel文件中的所有sheet名称 """ print(wb.sheetnames) # ['数据导出', '用户列表', 'Sheet1', 'Sheet2'] """ # 2.选择sheet,基于sheet名称 """ sheet = wb["数据导出"] cell = sheet.cell(1, 2) print(cell.value) """ # 3.选择sheet,基于索引位置 """ sheet = wb.worksheets[0] cell = sheet.cell(1,2) print(cell.value) """ # 4.循环所有的sheet """ for name in wb.sheetnames: sheet = wb[name] cell = sheet.cell(1, 1) print(cell.value) """ """ for sheet in wb.worksheets: cell = sheet.cell(1, 1) print(cell.value) """ """ for sheet in wb: cell = sheet.cell(1, 1) print(cell.value) """ -
读sheet中单元格的数据
from openpyxl import load_workbook wb = load_workbook("files/p1.xlsx") sheet = wb.worksheets[0] # 1.获取第N行第N列的单元格(位置是从1开始) """ cell = sheet.cell(1, 1) print(cell.value) print(cell.style) print(cell.font) print(cell.alignment) """ # 2.获取某个单元格 """ c1 = sheet["A2"] print(c1.value) c2 = sheet['D4'] print(c2.value) """ # 3.第N行所有的单元格 """ for cell in sheet[1]: print(cell.value) """ # 4.所有行的数据(获取某一列数据) """ for row in sheet.rows: print(row[0].value, row[1].value) """ # 5.获取所有列的数据 """ for col in sheet.columns: print(col[1].value) """ -
读合并的单元格

from openpyxl import load_workbook
wb = load_workbook("files/p1.xlsx")
sheet = wb.worksheets[2]
# 获取第N行第N列的单元格(位置是从1开始)
c1 = sheet.cell(1, 1)
print(c1) # <Cell 'Sheet1'.A1>
print(c1.value) # 用户信息
c2 = sheet.cell(1, 2)
print(c2) # <MergedCell 'Sheet1'.B1>
print(c2.value) # None
from openpyxl import load_workbook
wb = load_workbook('files/p1.xlsx')
sheet = wb.worksheets[2]
for row in sheet.rows:
print(row)
>>> 输出结果
(<Cell 'Sheet1'.A1>, <MergedCell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>)
(<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>)
(<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.C3>)
(<MergedCell 'Sheet1'.A4>, <Cell 'Sheet1'.B4>, <Cell 'Sheet1'.C4>)
(<Cell 'Sheet1'.A5>, <Cell 'Sheet1'.B5>, <Cell 'Sheet1'.C5>)
5.1 写Excel
在Excel中想要写文件,大致要分为在:
-
原Excel文件基础上写内容。
from openpyxl import load_workbook wb = load_workbook('files/p1.xlsx') sheet = wb.worksheets[0] # 找到单元格,并修改单元格的内容 cell = sheet.cell(1, 1) cell.value = "新的开始" # 将excel文件保存到p2.xlsx文件中 wb.save("files/p2.xlsx") -
新创建Excel文件写内容。
from openpyxl import workbook # 创建excel且默认会创建一个sheet(名称为Sheet) wb = workbook.Workbook() sheet = wb.worksheets[0] # 或 sheet = wb["Sheet"] # 找到单元格,并修改单元格的内容 cell = sheet.cell(1, 1) cell.value = "新的开始" # 将excel文件保存到p2.xlsx文件中 wb.save("files/p2.xlsx")
在了解了如何读取Excel和创建Excel之后,后续对于Excel中的sheet和cell操作基本上都相同。
from openpyxl import workbook
wb = workbook.Workbook() # Sheet
# 1. 修改sheet名称
"""
sheet = wb.worksheets[0]
sheet.title = "数据集"
wb.save("p2.xlsx")
"""
# 2. 创建sheet并设置sheet颜色
"""
sheet = wb.create_sheet("工作计划", 0)
sheet.sheet_properties.tabColor = "1072BA"
wb.save("p2.xlsx")
"""
# 3. 默认打开的sheet
"""
wb.active = 0
wb.save("p2.xlsx")
"""
# 4. 拷贝sheet
"""
sheet = wb.create_sheet("工作计划")
sheet.sheet_properties.tabColor = "1072BA"
new_sheet = wb.copy_worksheet(wb["Sheet"])
new_sheet.title = "新的计划"
wb.save("p2.xlsx")
"""
# 5.删除sheet
"""
del wb["用户列表"]
wb.save('files/p2.xlsx')
"""
from openpyxl import load_workbook
from openpyxl.styles import Alignment, Border, Side, Font, PatternFill, GradientFill
wb = load_workbook('files/p1.xlsx')
sheet = wb.worksheets[1]
# 1. 获取某个单元格,修改值
"""
cell = sheet.cell(1, 1)
cell.value = "开始"
wb.save("p2.xlsx")
"""
# 2. 获取某个单元格,修改值
"""
sheet["B3"] = "Alex"
wb.save("p2.xlsx")
"""
# 3. 获取某些单元格,修改值
"""
cell_list = sheet["B2":"C3"]
for row in cell_list:
for cell in row:
cell.value = "新的值"
wb.save("p2.xlsx")
"""
# 4. 对齐方式
"""
cell = sheet.cell(1, 1)
# horizontal,水平方向对齐方式:"general", "left", "center", "right", "fill", "justify", "centerContinuous", "distributed"
# vertical,垂直方向对齐方式:"top", "center", "bottom", "justify", "distributed"
# text_rotation,旋转角度。
# wrap_text,是否自动换行。
cell.alignment = Alignment(horizontal='center', vertical='distributed', text_rotation=45, wrap_text=True)
wb.save("p2.xlsx")
"""
# 5. 边框
# side的style有如下:dashDot','dashDotDot', 'dashed','dotted','double','hair', 'medium', 'mediumDashDot', 'mediumDashDotDot','mediumDashed', 'slantDashDot', 'thick', 'thin'
"""
cell = sheet.cell(9, 2)
cell.border = Border(
top=Side(style="thin", color="FFB6C1"),
bottom=Side(style="dashed", color="FFB6C1"),
left=Side(style="dashed", color="FFB6C1"),
right=Side(style="dashed", color="9932CC"),
diagonal=Side(style="thin", color="483D8B"), # 对角线
diagonalUp=True, # 左下 ~ 右上
diagonalDown=True # 左上 ~ 右下
)
wb.save("p2.xlsx")
"""
# 6.字体
"""
cell = sheet.cell(5, 1)
cell.font = Font(name="微软雅黑", size=45, color="ff0000", underline="single")
wb.save("p2.xlsx")
"""
# 7.背景色
"""
cell = sheet.cell(5, 3)
cell.fill = PatternFill("solid", fgColor="99ccff")
wb.save("p2.xlsx")
"""
# 8.渐变背景色
"""
cell = sheet.cell(5, 5)
cell.fill = GradientFill("linear", stop=("FFFFFF", "99ccff", "000000"))
wb.save("p2.xlsx")
"""
# 9.宽高(索引从1开始)
"""
sheet.row_dimensions[1].height = 50
sheet.column_dimensions["E"].width = 100
wb.save("p2.xlsx")
"""
# 10.合并单元格
"""
sheet.merge_cells("B2:D8")
sheet.merge_cells(start_row=15, start_column=3, end_row=18, end_column=8)
wb.save("p2.xlsx")
"""
"""
sheet.unmerge_cells("B2:D8")
wb.save("p2.xlsx")
"""
# 11.写入公式
"""
sheet = wb.worksheets[3]
sheet["D1"] = "合计"
sheet["D2"] = "=B2*C2"
wb.save("p2.xlsx")
"""
"""
sheet = wb.worksheets[3]
sheet["D3"] = "=SUM(B3,C3)"
wb.save("p2.xlsx")
"""
# 12.删除
"""
# idx,要删除的索引位置
# amount,从索引位置开始要删除的个数(默认为1)
sheet.delete_rows(idx=1, amount=20)
sheet.delete_cols(idx=1, amount=3)
wb.save("p2.xlsx")
"""
# 13.插入
"""
sheet.insert_rows(idx=5, amount=10)
sheet.insert_cols(idx=3, amount=2)
wb.save("p2.xlsx")
"""
# 14.循环写内容
"""
sheet = wb["Sheet"]
cell_range = sheet['A1:C2']
for row in cell_range:
for cell in row:
cell.value = "xx"
for row in sheet.iter_rows(min_row=5, min_col=1, max_col=7, max_row=10):
for cell in row:
cell.value = "oo"
wb.save("p2.xlsx")
"""
# 15.移动
"""
# 将H2:J10范围的数据,向右移动15个位置、向上移动1个位置
sheet.move_range("H2:J10",rows=1, cols=15)
wb.save("p2.xlsx")
"""
"""
sheet = wb.worksheets[3]
sheet["D1"] = "合计"
sheet["D2"] = "=B2*C2"
sheet["D3"] = "=SUM(B3,C3)"
sheet.move_range("B1:D3",cols=10, translate=True) # 自动翻译公式
wb.save("p2.xlsx")
"""
# 16.打印区域
"""
sheet.print_area = "A1:D200"
wb.save("p2.xlsx")
"""
# 17.打印时,每个页面的固定表头
"""
sheet.print_title_cols = "A:D"
sheet.print_title_rows = "1:3"
wb.save("p2.xlsx")
"""
6.压缩文件
基于Python内置的shutil模块可以实现对压缩文件的操作。
import shutil
# 1. 压缩文件
"""
# base_name,压缩后的压缩包文件
# format,压缩的格式,例如:"zip", "tar", "gztar", "bztar", or "xztar".
# root_dir,要压缩的文件夹路径
"""
# shutil.make_archive(base_name=r'datafile',format='zip',root_dir=r'files')
# 2. 解压文件
"""
# filename,要解压的压缩包文件
# extract_dir,解压的路径
# format,压缩文件格式
"""
# shutil.unpack_archive(filename=r'datafile.zip', extract_dir=r'xxxxxx/xo', format='zip')
7.路径相关
7.1 转义
windows路径使用的是\,linux路径使用的是/。
特别的,在windows系统中如果有这样的一个路径 D:\nxxx\txxx\x1,程序会报错。因为在路径中存在特殊符 \n(换行符)和\t(制表符),Python解释器无法自动区分。
所以,在windows中编写路径时,一般有两种方式:
- 加转义符,例如:
"D:\\nxxx\\txxx\\x1" - 路径前加r,例如:
r"D:\\nxxx\\txxx\\x1"
7.2 程序当前路径
项目中如果使用了相对路径,那么一定要注意当前所在的位置。
例如:在/Users/wupeiqi/PycharmProjects/CodeRepository/路径下编写 demo.py文件
with open("a1.txt", mode='w', encoding='utf-8') as f:
f.write("你好呀")
用以下两种方式去运行:
-
方式1,文件会创建在
/Users/wupeiqi/PycharmProjects/CodeRepository/目录下。cd /Users/wupeiqi/PycharmProjects/CodeRepository/ python demo.py -
方式2,文件会创建在
/Users/wupeiqi目录下。cd /Users/wupeiqi python /Users/wupeiqi/PycharmProjects/CodeRepository/demo.py
import os
"""
# 1.获取当前运行的py脚本所在路径
abs = os.path.abspath(__file__)
print(abs) # /Users/wupeiqi/PycharmProjects/luffyCourse/day09/20.路径相关.py
path = os.path.dirname(abs)
print(path) # /Users/wupeiqi/PycharmProjects/luffyCourse/day09
"""
base_dir = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(base_dir, 'files', 'info.txt')
print(file_path)
if os.path.exists(file_path):
file_object = open(file_path, mode='r', encoding='utf-8')
data = file_object.read()
file_object.close()
print(data)
else:
print('文件路径不存在')
7.3 文件和路径相关
import shutil
import os
# 1. 获取当前脚本绝对路径
"""
abs_path = os.path.abspath(__file__)
print(abs_path)
"""
# 2. 获取当前文件的上级目录
"""
base_path = os.path.dirname( os.path.dirname(路径) )
print(base_path)
"""
# 3. 路径拼接
"""
p1 = os.path.join(base_path, 'xx')
print(p1)
p2 = os.path.join(base_path, 'xx', 'oo', 'a1.png')
print(p2)
"""
# 4. 判断路径是否存在
"""
exists = os.path.exists(p1)
print(exists)
"""
# 5. 创建文件夹
"""
os.makedirs(路径)
"""
"""
path = os.path.join(base_path, 'xx', 'oo', 'uuuu')
if not os.path.exists(path):
os.makedirs(path)
"""
# 6. 是否是文件夹
"""
file_path = os.path.join(base_path, 'xx', 'oo', 'uuuu.png')
is_dir = os.path.isdir(file_path)
print(is_dir) # False
folder_path = os.path.join(base_path, 'xx', 'oo', 'uuuu')
is_dir = os.path.isdir(folder_path)
print(is_dir) # True
"""
# 7. 删除文件或文件夹
"""
os.remove("文件路径")
"""
"""
path = os.path.join(base_path, 'xx')
shutil.rmtree(path)
"""
# 8. 拷贝文件夹
"""
shutil.copytree("/Users/wupeiqi/Desktop/图/csdn/","/Users/wupeiqi/PycharmProjects/CodeRepository/files")
"""
# 9.拷贝文件
"""
shutil.copy("/Users/wupeiqi/Desktop/图/csdn/WX20201123-112406@2x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/")
shutil.copy("/Users/wupeiqi/Desktop/图/csdn/WX20201123-112406@2x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/x.png")
"""
# 10.文件或文件夹重命名
"""
shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/xxxx.png")
shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/files","/Users/wupeiqi/PycharmProjects/CodeRepository/images")
"""
总结
今天我们主要围绕着文件 相关的操作来展开进行讲解,让大家能够基于Python处理不同格式的文件。由于涉及的知识点比较多,所以今日的内容学起来会比较耗时,但都比较简单,只需要理解并编写好相关笔记以便后期开发时翻阅。
-
文件相对路径,在使用相对路径时可能会执行程序的目录不同,导致路径出问题。所以,如若使用相对路径请务必清楚当前运行程序所在目录。
-
文件绝对路径(推荐),不要将文件路径写死,而是基于 os 模块中的相关功能自动化获取绝对路径,以方便项目移动到其他文件或电脑上。
import os base_dir = os.path.dirname(os.path.abspath(__file__)) file_path = os.path.join(base_dir, 'files', 'info.txt') -
路径转义
- 手动写路径,需要自己在路径中添加 r 或 加入 \ 来进行处理。
- 基于os.path.join拼接,内部自动处理,不需要手动处理。
-
内置函数、内置模块、第三方模块的区别?
-
如何去下载安装第三方模块?
pip install 模块名称- requests模块,可以用来发送网络请求。
- openpyxl模块,处理Excel格式的文件。
-
基本文件的读写、打开模式、上下文管理。
-
其他格式:csv、ini、xml、excel格式的处理(无序记忆,做好笔记即可)。
作业
-
基于csv格式实现 用户的注册 & 登录认证。详细需求如下:
- 用户注册时,新注册用户要写入文件csv文件中,输入Q或q则退出。
- 用户登录时,逐行读取csv文件中的用户信息并进行校验。
- 提示:文件路径须使用os模块构造的绝对路径的方式。
-
补充代码:实现去网上获取指定地区的天气信息,并写入到Excel中。
import requests while True: city = input("请输入城市(Q/q退出):") if city.upper() == "Q": break url = "http://ws.webxml.com.cn//WebServices/WeatherWebService.asmx/getWeatherbyCityName?theCityName={}".format(city) res = requests.get(url=url) print(res.text) # 1.提取XML格式中的数据 # 2.为每个城市创建一个sheet,并将获取的xml格式中的数据写入到excel中。 -
读取ini文件内容,按照规则写入到Excel中。
-
ini文件内容如下:
[mysqld] datadir=/var/lib/mysql socket=/var/lib/mysql/mysql.sock log-bin=py-mysql-bin character-set-server=utf8 collation-server=utf8_general_ci log-error=/var/log/mysqld.log # Disabling symbolic-links is recommended to prevent assorted security risks symbolic-links=0 [mysqld_safe] log-error=/var/log/mariadb/mariadb.log pid-file=/var/run/mariadb/mariadb.pid [client] default-character-set=utf8 -
读取ini格式的文件,并创建一个excel文件,且为每个节点创建一个sheet,然后将节点下的键值写入到excel中,按照如下格式。
- 首行,字体白色 & 单元格背景色蓝色。
- 内容均居中。
- 边框。
-
-
补充代码,实现如下功能。
import requests # 1.下载文件 file_url = 'https://files.cnblogs.com/files/wupeiqi/HtmlStore.zip' res = requests.get(url=file_url) print(res.content) # 2.将下载的文件保存到当前执行脚本同级目录下 /files/package/ 目录下(且文件名为HtmlStore.zip) # 3.在将下载下来的文件解压到 /files/html/ 目录下
作业答案
"""
day09 作业题讲解
"""
# 1.for循环
data_list = [11,22,33,44,55]
for item in data_list:
print(item)
break
else:
print("else中的内容") # for循环中的内容全部执行了一遍,且未遇到break
# 2.enumerate
data_list = [11, 22, 33, 44, 55]
for index in range(len(data_list)):
print(index+1, data_list[index])
data_list = [11, 22, 33, 44, 55]
for i, item in enumerate(data_list, 1):
print(i, item)
# ############### 1. 基于csv的用户注册和认证 #############
import os
# 文件路径处理
base_dir = os.path.dirname(os.path.abspath(__file__))
db_file_path = os.path.join(base_dir, 'db.csv')
# 用户注册
while True:
choice = input("是否进行用户注册(Y/N)?")
choice = choice.upper()
if choice not in {'Y', 'N'}:
print('输入格式错误,请重新输入。')
continue
if choice == "N":
break
with open(db_file_path, mode='a', encoding='utf-8') as file_object:
while True:
user = input("请输入用户名(Q/q退出):")
if user.upper() == 'Q':
break
pwd = input("请输入密码:")
file_object.write("{},{}\n".format(user, pwd))
file_object.flush()
break
# 用户登录
print("欢迎使用xx系统,请登录!")
username = input("请输入用户名:")
password = input("请输入密码:")
if not os.path.exists(db_file_path):
print("用户文件不存在")
else:
with open(db_file_path, mode='r', encoding='utf-8') as file_object:
for line in file_object:
user, pwd = line.strip().split(',')
if username == user and pwd == password:
print('登录成功')
break
else:
print("用户名或密码错误")
# ############### 2. 实现去网上获取指定地区的天气信息,并写入到Excel中。 #############
import os
import requests
from xml.etree import ElementTree as ET
from openpyxl import workbook
# 处理文件路径
base_dir = os.path.dirname(os.path.abspath(__file__))
target_excel_file_path = os.path.join(base_dir, 'weather.xlsx')
# 创建excel且默认会创建一个sheet(名称为Sheet)
wb = workbook.Workbook()
del wb['Sheet']
while True:
# 用户输入城市,并获取该城市的天气信息
city = input("请输入城市(Q/q退出):")
if city.upper() == "Q":
break
url = "http://ws.webxml.com.cn//WebServices/WeatherWebService.asmx/getWeatherbyCityName?theCityName={}".format(city)
res = requests.get(url=url)
# 1.提取XML格式中的数据
root = ET.XML(res.text)
# 2.为每个城市创建一个sheet,并将获取的xml格式中的数据写入到excel中。
sheet = wb.create_sheet(city)
for row_index, node in enumerate(root, 1):
text = node.text
cell = sheet.cell(row_index, 1)
cell.value = text
wb.save(target_excel_file_path)
# ############### 3. 读取ini文件,并写入到Excel #############
import os
import configparser
from openpyxl import workbook
from openpyxl.styles import Alignment, Border, Side, Font, PatternFill
# 文件路径处理
base_dir = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(base_dir, 'files', 'my.ini')
target_excel_file_path = os.path.join(base_dir, 'my.xlsx')
# 创建excel且默认会创建一个sheet(名称为Sheet)
wb = workbook.Workbook()
del wb['Sheet']
# 解析ini格式文件
config = configparser.ConfigParser()
config.read(file_path, encoding='utf-8')
# 循环获取每个节点,并为每个节点创建一个sheet
for section in config.sections():
# 在excel中创建一个sheet,名称为ini文件的节点名称
sheet = wb.create_sheet(section)
# 边框和居中(表头和内容都需要)
side = Side(style="thin", color="000000")
border = Border(top=side, bottom=side, left=side, right=side)
align = Alignment(horizontal='center', vertical='center')
# 为此在sheet设置表头
title_dict = {"A1": "键", "B1": "值"}
for position, text in title_dict.items():
cell = sheet[position]
# 设置值
cell.value = text
# 设置居中
cell.alignment = align
# 设置背景色
cell.fill = PatternFill("solid", fgColor="6495ED")
# 设置字体颜色
cell.font = Font(name="微软雅黑", color="FFFFFF")
# 设置边框
cell.border = border
# 读取此节点下的所有键值,并将键值写入到当前sheet中
# row_index = 2
# for key, val in config.items(section):
# c1 = sheet.cell(row_index, 1)
# c1.value = key
# c1.alignment = align
# c1.border = border
#
# c2 = sheet.cell(row_index, 2)
# c2.value = val
# c2.alignment = align
# c2.border = border
# row_index += 1
row_index = 2
for group in config.items(section):
# group = ("datadir","/var/lib/mysql")
for col, text in enumerate(group, 1):
cell = sheet.cell(row_index, col)
cell.alignment = align
cell.border = border
cell.value = text
row_index += 1
wb.save(target_excel_file_path)
# ############### 4. 下载zip文件,并解压到指定路径 #############
import os
import shutil
import requests
# 文件路径处理
base_dir = os.path.dirname(os.path.abspath(__file__))
download_folder = os.path.join(base_dir, 'files', 'package')
if not os.path.exists(download_folder):
os.makedirs(download_folder)
# 1.下载文件
file_url = 'https://files.cnblogs.com/files/wupeiqi/HtmlStore.zip'
res = requests.get(url=file_url)
# 2.将下载的文件保存到当前执行脚本同级目录下 /files/package/ 目录下(且文件名为 HtmlStore.zip )
file_name = file_url.split('/')[-1]
zip_file_path = os.path.join(download_folder, file_name) # .../files/package/HtmlStore.zip
with open(zip_file_path, mode='wb') as file_object:
file_object.write(res.content)
# 3.在将下载下来的文件解压到 /files/html/ 目录下
unpack_folder = os.path.join(base_dir, 'files', 'html')
shutil.unpack_archive(filename=zip_file_path, extract_dir=unpack_folder, format='zip')
day10 函数入门
目标:掌握函数的编写方式以及函数的基本使用。
今日概要:
- 初识函数
- 函数的参数
- 函数的返回值
提示:由于昨天的内容比较多,为了减轻大家的学习压力,今天设计的课程内容会比较少。
1. 初识函数
函数到底是个什么东西?
函数,可以当做是一大堆功能代码的集合。
def 函数名():
函数内编写代码
...
...
函数名()
例如:
# 定义名字叫info的函数
def info():
print("第一行")
print("第二行")
print("第n行...")
info()
什么时候会用到函数?
什么时候会用到函数呢?一般在项目开发中有会有两种应用场景:
-
有重复代码,用函数增加代码的重用性。
def send_email(): # 10行代码 print("欢迎使用计算机监控系统") if CPU占用率 > 90%: send_email() if 硬盘使用率 > 99%: send_email() if 内存使用率 > 98%: send_email() ... -
代码太长,用函数增强代码的可读性。
def calculate_same_num_rule(): """判断是否是豹子""" pass def calculate_same_color_rule(): """判断是否是同花""" pass def calculate_straight_rule(): """判断是否顺子""" pass def calculate_double_card_rule(poke_list): """判断是否对子""" pass def calculate_single_card_rule(): """判断是否单牌""" pass # 1. 生成一副扑克牌 card_color_list = ["红桃", "黑桃", "方片", "梅花"] card_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] # A all_card_list = [[color, num] for color in card_color_list for num in card_nums] # 2.洗牌 random.shuffle(all_card_list) # 3.给玩家发牌 ... # 4.判断牌是:豹子?同花顺?顺子?对子?单点? calculate_same_num_rule() calculate_same_color_rule() calculate_straight_rule() ...
以前我们变成是按照业务逻辑从上到下逐步完成,称为:面向过程编程;现在学了函数之后,利用函数编程称为:函数式编程。
2. 函数的参数
之前说了很好多次发送邮件的案例,下面就来教大家用python发邮件,然后再由此引出函数的参数。
- 注册邮箱
- 基础配置
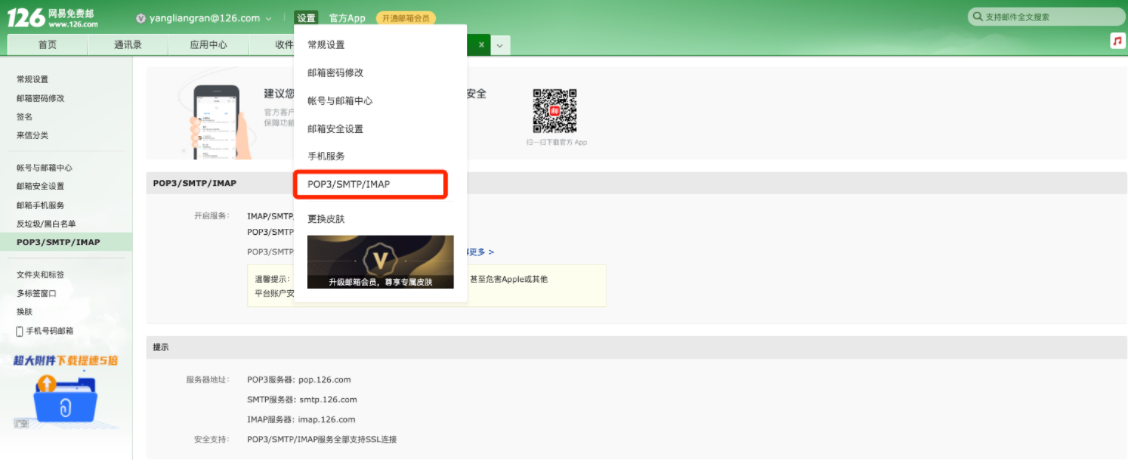
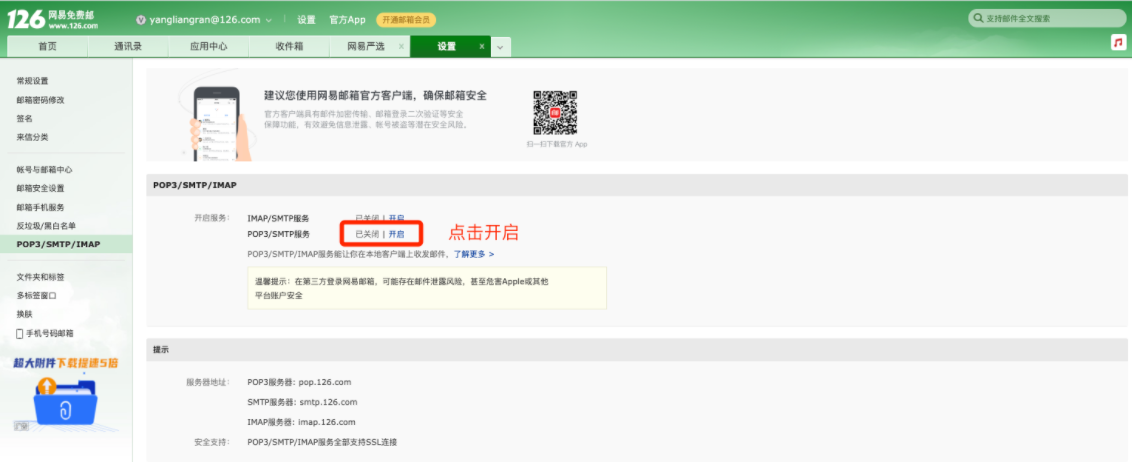
- 授权码
- SMTP服务器: smtp.126.com
- 代码发送邮件
以下是我为大家提供的发邮件的一个函数。
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
# ### 1.邮件内容配置 ###
msg = MIMEText("约吗", 'html', 'utf-8')
msg['From'] = formataddr(["武沛齐", "yangliangran@126.com"])
msg['Subject'] = "180一晚"
# ### 2.发送邮件 ###
server = smtplib.SMTP_SSL("smtp.126.com")
server.login("yangliangran@126.com", "LAYEVIAPWQAVVDEP")
server.sendmail("yangliangran@126.com", "424662508@qq.com", msg.as_string())
server.quit()
那么需求来了,请求大家提一个需求:根据上述代码实现给3个用户发邮件。
v1 = "424662508@qq.com"
v2 = "424662509@qq.com"
v3 = "wupeiqi@live.com"
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
def send_email(xx):
# ### 1.邮件内容配置 ###
msg = MIMEText("约吗", 'html', 'utf-8')
msg['From'] = formataddr(["武沛齐", "yangliangran@126.com"])
msg['Subject'] = "180一晚"
# ### 2.发送邮件 ###
server = smtplib.SMTP_SSL("smtp.126.com")
server.login("yangliangran@126.com", "LAYEVIAPWQAVVDEP")
server.sendmail("yangliangran@126.com", xx, msg.as_string())
server.quit()
send_email("424662508@qq.com")
send_email("424662509@qq.com")
send_email("wupeiqi@live.com")
-
思路1
def send_email1(): # ### 1.邮件内容配置 ### # 邮件文本 msg = MIMEText("约吗", 'html', 'utf-8') # 邮件上显示的发件人 msg['From'] = formataddr(["武沛齐", "wptawy@126.com"]) # 邮件上显示的主题 msg['Subject'] = "邮件主题" # ### 2.发送邮件 ### server = smtplib.SMTP_SSL("smtp.126.com") server.login("wptawy@126.com", "WIYSAILOVUKPQGHY") server.sendmail("wptawy@126.com", "424662508@qq.com", msg.as_string()) server.quit() def send_email2(): # ### 1.邮件内容配置 ### # 邮件文本 msg = MIMEText("约吗", 'html', 'utf-8') # 邮件上显示的发件人 msg['From'] = formataddr(["武沛齐", "wptawy@126.com"]) # 邮件上显示的主题 msg['Subject'] = "邮件主题" # ### 2.发送邮件 ### server = smtplib.SMTP_SSL("smtp.126.com") server.login("wptawy@126.com", "WIYSAILOVUKPQGHY") server.sendmail("wptawy@126.com", "424662509@qq.com", msg.as_string()) server.quit() def send_email3(): # ### 1.邮件内容配置 ### # 邮件文本 msg = MIMEText("约吗", 'html', 'utf-8') # 邮件上显示的发件人 msg['From'] = formataddr(["武沛齐", "wptawy@126.com"]) # 邮件上显示的主题 msg['Subject'] = "邮件主题" # ### 2.发送邮件 ### server = smtplib.SMTP_SSL("smtp.126.com") server.login("wptawy@126.com", "WIYSAILOVUKPQGHY") server.sendmail("wptawy@126.com", "wupeiqi@live.com", msg.as_string()) server.quit() send_email1() send_email2() send_email3() -
思路2,基于函数的参数(将代码中动态部分提取到参数位置,让函数可以充分被重用)
def send_email(email): # ### 1.邮件内容配置 ### # 邮件文本 msg = MIMEText("约吗", 'html', 'utf-8') # 邮件上显示的发件人 msg['From'] = formataddr(["武沛齐", "wptawy@126.com"]) # 邮件上显示的主题 msg['Subject'] = "邮件主题" # ### 2.发送邮件 ### server = smtplib.SMTP_SSL("smtp.126.com") server.login("wptawy@126.com", "WIYSAILOVUKPQGHY") server.sendmail("wptawy@126.com", email, msg.as_string()) server.quit() v1 = "424662508@qq.com" send_email(v1) v2 = "424662509@qq.com" send_email(v2) v3 = "wupeiqi@live.com" send_email(v3)
2.1 参数
在定义函数时,如果在括号中添加变量,我们称它为函数的形式参数:
# ###### 定义有三个参数的函数(a1/a2/a3一般称为形式参数-形参) #####
def func(a1,a2,a3):
print(a1+a2+a3)
# 执行函数并传入参数(执行函数传值时一般称为实际参数-实参)
func(11,22,33)
# 执行函数并传入参数
func(9,2,103)
-
位置传参
def add(n1,n2): print(n1+n2) add(1,22) -
关键字传参
def add(n1,n2): print(n1+n2) add(n1=1,n2=22)
"""
1. 形参
2. 实参
3. 位置传参
4. 关键字传参
"""
# ###### 定义有三个参数的函数(a1/a2/a3一般称为形式参数-形参) #####
def func(a1, a2, a3):
print(a1 + a2 + a3)
# 执行函数并传入参数(执行函数传值时一般称为实际参数-实参)
func(11, 22, 33)
# 执行函数并传入参数
func(9, 2, 103)
# 执行函数
func(a1=99, a2=88, a3=1)
func(a1=99, a3=1, a2=88)
2.2 默认参数
def func(a1, a2, a3=10):
print(a1 + a2 + a3)
# 位置传参
func(8, 19)
func(1, 2, 99)
# 关键字传参(位置和关键混合时,关键字传参要在后面)
func(12, 9, a3=90)
func(12, a2=9, a3=90)
func(a1=12, a2=9, a3=90)
file_object = open("xxx.txt")
2.3 动态参数
-
def func(*args): print(args) # 元组类型 (22,) (22,33,99,) () # 只能按照位置传参 func(22) func(22,33) func(22,33,99) func() -
**
def func(**kwargs): print(kwargs) # 字典类型 {"n1":"武沛齐"} {"n1":"武沛齐","age":"18","email":"xxxx"} {} # 只能按关键字传参 func(n1="武沛齐") func(n1="武沛齐",age=18) func(n1="武沛齐",age=18,email="xx@live.com") -
,*
def func(*args,**kwargs): print(args,kwargs) # (22,33,99) {} func(22,33,99) func(n1="武沛齐",age=18) func(22,33,99,n1="武沛齐",age=18) func()提示:是否还记得字符串格式化时的format功能。
v1 = "我叫{},今年{},性别{}".format("武沛齐",18,"男") v2 = "我叫{name},今年{age},性别{gender}".format(name="武沛齐",age=18,gender="男")
注意事项(不重要,听过一遍即可)
# 1. ** 必须放在 * 的后面
def func1(*args, **kwargs):
print(args, **kwargs)
# 2. 参数和动态参数混合时,动态参数只能放在最后。
def func2(a1, a2, a3, *args, **kwargs):
print(a1, a2, a3, args, **kwargs)
# 3. 默认值参数和动态参数同时存在
def func3(a1, a2, a3, a4=10, *args, a5=20, **kwargs):
print(a1, a2, a3, a4, a5, args, kwargs)
func3(11, 22, 33, 44, 55, 66, 77, a5=10, a10=123)
3. 函数返回值
在开发过程中,我们希望函数可以帮助我们实现某个功能,但让函数实现某功能之后有时也需要有一些结果需要反馈给我们,例如:
import requests
from xml.etree import ElementTree as ET
def xml_to_list(city):
data_list = []
url = "http://ws.webxml.com.cn//WebServices/WeatherWebService.asmx/getWeatherbyCityName?theCityName={}".format(city)
res = requests.get(url=url)
root = ET.XML(res.text)
for node in root:
data_list.append(node.text)
return data_list
result = xml_to_list("北京")
print(result)
def func():
return 666
res = func()
print(res) # 666
def magic(num):
result = num + 1000
return result
data = magic(9)
print(data) # 1009
在了解了返回值的基本使用之后,接下来在学3个关键知识:
-
返回值可以是任意类型,如果函数中没写return,则默认返回None
def func(): return [1,True,(11,22,33)] result = func() print(result)def func(): value = 1 + 1 ret = func() print(ret) # None当在函数中
未写返回值或return或return None,执行函数获取的返回值都是None。def func(): value = 1 + 1 return # 或 return None ret = func() print(ret) # None -
return后面的值如果有逗号,则默认会将返回值转换成元组再返回。
def func(): return 1,2,3 value = func() print(value) # (1,2,3) -
函数一旦遇到return就会立即退出函数(终止函数中的所有代码)
def func(): print(1) return "结束吧" print(2) ret = func() print(ret)def func(): print(1) for i in range(10): print(i) return 999 print(2) result = func() print(result) # 输出 1 0 999def func(): print(1) for i in range(10): print(i) for j in range(100): print(j) return print(2) result = func() print(result) # 输出 1 0 0 None
小结:
-
完成某个结果并希望的到结果。
def send_email(): ... return True v1 = send_email()def encrypt(old): ... return "密文..." data = encrypt("武沛齐") print(data) -
基于return控制让函数终止执行
def func(name): with open("xxx.txt",mode='r',encoding="utf-8") as file_object: for line in file_object: if name in line: return True data = func("武沛齐") if data: print("存在") else: print("不存在")def foo(): while True: num = input("请输入数字(Q):") if num.upper() == "Q": return num = int(num) if num == 99: print("猜对了") else: print("猜错了,请继续!") print("....") foo()
总结
-
如何定义一个函数?
-
函数名的规范。(同变量名规范)
-
规范
-
建议
def change_num(): pass
-
-
函数的注释,说明函数的作用。
def encrypt(origin): """ 用于数据加密和xxx """ pass -
定义函数时,参数一般有以下情况(形式参数)
-
情景1
def func(a1,a2): pass -
情景2:
def func(a1,a2=123): pass -
情景2:
def func(*args,**kwargs): pass
-
-
函数的返回值,一般用于将函数执行的返回给调用者。
- 默认返回None
- 遇到return则函数执行完毕
作业
-
请定义一个函数,用于计算一个字符串中字符
a出现的次数并通过return返回。- 参数,字符串。
- 返回值,字符串中 a 出现的次数。
-
写函数,判断用户传入的一个值(字符串或列表或元组任意)长度是否大于5,并返回真假。
-
写函数,接收两个数字参数,返回比较大的那个数字(等于时返回两个中的任意一个都可以)。
-
写函数,函数接收四个参数分别是:姓名,性别,年龄,学历,然后将这四个值通过"*"拼接起来并追加到一个student_msg.txt文件中。
-
补充代码,实现如下功能:
- 【位置1】读取文件中的每一行数据,将包含特定关键的数据筛选出来,并以列表的形式返回。
- 【位置1】文件不存在,则返回None
- 【位置2】文件不存在,输出 "文件不存在",否则循环输出匹配成功的每一行数据。
def select_content(file_path,key): # 补充代码【位置1】 result = select_content("files/xxx.txt","股票") # 补充代码【位置2】 -
补充代码,实现敏感词替换的功能。
def change_string(origin): # 补充代码,将字符串origin中中的敏感词替换为 **,最后将替换好的值返回。 data_list = ["苍老师","波多老师","大桥"] text = input("请输入内容:") result = change_string(text) print(result) -
基于函数实现用户认证,要求:
-
写函数,读取的用户信息并构造为字典(用户信息存放在
files/user.xlsx文件中)
# 构造的字典格式如下 user_dict = { "用户名":"密码" ... } -
用户输入用户名和密码,进行校验。(且密码都是密文,所以,需要将用户输入的密码进行加密,然后再与Excel中的密文密码进行比较)
import hashlib def encrypt(origin): origin_bytes = origin.encode('utf-8') md5_object = hashlib.md5() md5_object.update(origin_bytes) return md5_object.hexdigest() p1 = encrypt('admin') print(p1) # "21232f297a57a5a743894a0e4a801fc3" p2 = encrypt('123123') print(p2) # "4297f44b13955235245b2497399d7a93" p3 = encrypt('123456') print(p3) # "e10adc3949ba59abbe56e057f20f883e"
-
扩展:密码都不是明文。
- 注册京东,京东存储:用户名和密码(密文)
- 登录京东:用户名& 密码。
作业答案
# 第一题
def char_count(text):
count = 0
for char in text:
if char == 'a':
count += 1
return count
result = char_count("89alskdjf;auqkaaafasdfiojqln")
# 第二题
def judge_length(data):
if len(data) > 5:
return True
return False
result = judge_length("武沛齐武沛齐")
print(result)
# 第三题
def get_bigger(num1, num2):
if num1 > num2:
return num1
return num2
result = get_bigger(11, 22)
# 第四题
def write_file(name, gender, age, degree):
data_list = [name, gender, age, degree]
data = "*".join(data_list)
with open('student_msg.txt', mode='a', encoding='utf-8') as file_object:
file_object.write(data)
write_file("武沛齐", "男", "18", "博士")
# 第五题
import os
def select_content(file_path, key):
# 补充代码【位置1】
if not os.path.exists(file_path):
return
data_list = []
with open(file_path, mode='r', encoding='utf-8') as file_object:
for line in file_object:
if key in line:
data_list.append(line)
return data_list
result = select_content("files/xxx.txt", "股票")
if result == None:
print("文件不存在")
else:
print(result)
# 第六题
def change_string(origin):
# 补充代码,将字符串origin中中的敏感词替换为 **,最后将替换好的值返回。
data_list = ["苍老师", "波多老师", "大桥"]
for item in data_list:
origin = origin.replace(item, "**")
return origin
text = input("请输入内容:")
result = change_string(text)
print(result)
# 第七题
import hashlib
from openpyxl import load_workbook
def get_user_dict():
user_dict = {}
wb = load_workbook("files/user.xlsx")
sheet = wb.worksheets[0]
for row in sheet.rows:
user_dict[row[1].value] = row[2].value
return user_dict
def encrypt(origin):
origin_bytes = origin.encode('utf-8')
md5_object = hashlib.md5()
md5_object.update(origin_bytes)
return md5_object.hexdigest()
user = input("请输入用户名:")
pwd = input("请输入密码:")
encrypt_password = encrypt(pwd)
user_dict = get_user_dict()
db_password = user_dict.get(user)
if encrypt_password == db_password:
print("登录成功")
else:
print("登录失败")
day11 函数进阶
目标:掌握函数相关易错点 & 项目开发必备技能。
今日概要:
- 参数的补充
- 函数名,函数名到底是什么?
- 返回值和print,傻傻分不清楚。
- 函数的作用域
1.参数的补充
在函数基础部分,我们掌握函数和参数基础知识,掌握这些其实完全就可以进行项目的开发。
今天的补充的内容属于进阶知识,包含:内存地址相关、面试题相关等,在特定情况下也可以让代码更加简洁,提升开发效率。
1.1 参数内存地址相关【面试题】
在开始开始讲参数内存地址相关之前,我们先来学习一个技能:
如果想要查看下某个值的在内存中的地址?
v1 = "武沛齐"
addr = id(v1)
print(addr) # 140691049514160
v1 = [11,22,33]
v2 = [11,22,33]
print( id(v1) )
print( id(v2) )
v1 = [11,22,33]
v2 = v1
print( id(v1) )
print( id(v2) )
记住一句话:函数执行传参时,传递的是内存地址。
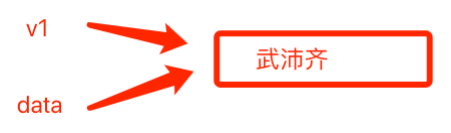
def func(data):
print(data, id(data)) # 武沛齐 140247057684592
v1 = "武沛齐"
print(id(v1)) # 140247057684592
func(v1)
面试题:请问Python的参数默认传递的是什么?
Python参数的这一特性有两个好处:
-
节省内存:每次执行函数的时候就不用重新创建地址了
-
对于可变类型且函数中修改元素的内容,所有的地方都会修改。可变类型:列表、字典、集合。
# 可变类型 & 修改内部修改 def func(data): data.append(999) v1 = [11,22,33] func(v1) print(v1) # [11,22,33,666]# 特殊情况:可变类型 & 重新赋值 def func(data): data = ["武沛齐","alex"] v1 = [11,22,33] func(v1) print(v1) # [11,22,33]# 特殊情况:不可变类型,无法修改内部元素,只能重新赋值。 def func(data): data = "alex" v1 = "武沛齐" func(v1)
其他很多编程语言执行函数时,默认传参时会将数据重新拷贝一份,会浪费内存。
提示注意:其他语言也可以通过 ref 等关键字来实现传递内存地址。
当然,如果你不想让外部的变量和函数内部参数的变量一致,也可以选择将外部值拷贝一份,再传给函数。
import copy
# 可变类型 & 修改内部修改
def func(data):
data.append(999)
v1 = [11, 22, 33]
new_v1 = copy.deepcopy(v1) # 拷贝一份数据
func(new_v1)
print(v1) # [11,22,33]
1.2 函数的返回值是内存地址
def func():
data = [11, 22, 33]
return data
v1 = func()
print(v1) # [11,22,33]
上述代码的执行过程:
- 执行func函数
data = [11, 22, 33]创建一块内存区域,内部存储[11,22,33],data变量指向这块内存地址。return data返回data指向的内存地址- v1接收返回值,所以 v1 和 data 都指向
[11,22,33]的内存地址(两个变量指向此内存,引用计数器为2) - 由函数执行完毕之后,函数内部的变量都会被释放。(即:删除data变量,内存地址的引用计数器-1)
所以,最终v1指向的函数内部创建的那块内存地址。
def func():
data = [11, 22, 33]
return data
v1 = func()
print(v1) # [11,22,33]
v2 = func()
print(v2) # [11,22,33]
上述代码的执行过程:
- 执行func函数
data = [11, 22, 33]创建一块内存区域,内部存储[11,22,33],data变量指向这块内存地址 1000001110。return data返回data指向的内存地址- v1接收返回值,所以 v1 和 data 都指向
[11,22,33]的内存地址(两个变量指向此内存,引用计数器为2) - 由函数执行完毕之后,函数内部的变量都会被释放。(即:删除data变量,内存地址的引用计数器-1)
所以,最终v1指向的函数内部创建的那块内存地址。(v1指向的1000001110内存地址)
- 执行func函数
data = [11, 22, 33]创建一块内存区域,内部存储[11,22,33],data变量指向这块内存地址 11111001110。return data返回data指向的内存地址- v2接收返回值,所以 v1 和 data 都指向
[11,22,33]的内存地址(两个变量指向此内存,引用计数器为2) - 由函数执行完毕之后,函数内部的变量都会被释放。(即:删除data变量,内存地址的引用计数器-1)
所以,最终v1指向的函数内部创建的那块内存地址。(v1指向的11111001110内存地址)
def func():
data = [11, 22, 33]
print(id(data))
return data
v1 = func()
print(v1, id(v1)) # [11,22,33]
v2 = func()
print(v2, id(v1)) # [11,22,33]
1.3 参数的默认值【面试题】
这个知识点在面试题中出现的概率比较高,但真正实际开发中用的比较少。
def func(a1,a2=18):
print(a1,a2)
原理:Python在创建函数(未执行)时,如果发现函数的参数中有默认值,则在函数内部会创建一块区域并维护这个默认值。
- 执行函数未传值时,则让a2指向 函数维护的那个值的地址。
func("root")
- 执行函数传值时,则让a2指向新传入的值的地址。
func("admin",20)
在特定情况【默认参数的值是可变类型 list/dict/set】 & 【函数内部会修改这个值】下,参数的默认值 有坑 。
-
坑
# 在函数内存中会维护一块区域存储 [1,2,666,666,666] 100010001 def func(a1,a2=[1,2]): a2.append(666) print(a1,a2) # a1=100 # a2 -> 100010001 func(100) # 100 [1,2,666] # a1=200 # a2 -> 100010001 func(200) # 200 [1,2,666,666] # a1=99 # a2 -> 1111111101 func(99,[77,88]) # 66 [177,88,666] # a1=300 # a2 -> 100010001 func(300) # 300 [1,2,666,666,666] -
大坑
# 在内部会维护一块区域存储 [1, 2, 10, 20,40 ] ,内存地址 1010101010 def func(a1, a2=[1, 2]): a2.append(a1) return a2 # a1=10 # a2 -> 1010101010 # v1 -> 1010101010 v1 = func(10) print(v1) # [1, 2, 10] # a1=20 # a2 -> 1010101010 # v2 -> 1010101010 v2 = func(20) print(v2) # [1, 2, 10, 20 ] # a1=30 # a2 -> 11111111111 [11, 22,30] # v3 -> 11111111111 v3 = func(30, [11, 22]) print(v3) # [11, 22,30] # a1=40 # a2 -> 1010101010 # v4 -> 1010101010 v4 = func(40) print(v4) # [1, 2, 10, 20,40 ] -
深坑
# 内存中创建空间存储 [1, 2, 10, 20, 40] 地址:1010101010 def func(a1, a2=[1, 2]): a2.append(a1) return a2 # a1=10 # a2 -> 1010101010 # v1 -> 1010101010 v1 = func(10) # a1=20 # a2 -> 1010101010 # v2 -> 1010101010 v2 = func(20) # a1=30 # a2 -> 11111111111 [11,22,30] # v3 -> 11111111111 v3 = func(30, [11, 22]) # a1=40 # a2 -> 1010101010 # v4 -> 1010101010 v4 = func(40) print(v1) # [1, 2, 10, 20, 40] print(v2) # [1, 2, 10, 20, 40] print(v3) # [11,22,30] print(v4) # [1, 2, 10, 20, 40]
1.4 动态参数
动态参数,定义函数时在形参位置用 *或** 可以接任意个参数。
def func(*args,**kwargs):
print(args,kwargs)
func("宝强","杰伦",n1="alex",n2="eric")
在定义函数时可以用 *和**,其实在执行函数时,也可以用。
-
形参固定,实参用
*和**def func(a1,a2): print(a1,a2) func( 11, 22 ) func( a1=1, a2=2 ) func( *[11,22] ) func( **{"a1":11,"a2":22} ) -
形参用
*和**,实参也用*和**def func(*args,**kwargs): print(args,kwargs) func( 11, 22 ) func( 11, 22, name="武沛齐", age=18 ) # 小坑,([11,22,33], {"k1":1,"k2":2}), {} func( [11,22,33], {"k1":1,"k2":2} ) # args=(11,22,33),kwargs={"k1":1,"k2":2} func( *[11,22,33], **{"k1":1,"k2":2} ) # 值得注意:按照这个方式将数据传递给args和kwargs时,数据是会重新拷贝一份的(可理解为内部循环每个元素并设置到args和kwargs中)。
所以,在使用format字符串格式化时,可以可以这样:
v1 = "我是{},年龄:{}。".format("武沛齐",18)
v2 = "我是{name},年龄:{age}。".format(name="武沛齐",age=18)
v3 = "我是{},年龄:{}。".format(*["武沛齐",18])
v4 = "我是{name},年龄:{age}。".format(**{"name":"武沛齐","age":18})
练习题
-
看代码写结果
def func(*args,**kwargs): print(args,kwargs) params = {"k1":"v2","k2":"v2"} func(params) # ({"k1":"v2","k2":"v2"}, ) {} func(**params) # (), {"k1":"v2","k2":"v2"} -
读取文件中的 URL 和 标题,根据URL下载视频到本地(以标题作为文件名)。
模仿,https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog&ratio=720p&line=0 卡特,https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g&ratio=720p&line=0 罗斯,https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg&ratio=720p&line=0# 下载视频示例 import requests res = requests.get( url="https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg&ratio=720p&line=0", headers={ "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS" } ) with open('rose.mp4', mode='wb') as f: f.write(res.content)
习题答案
import requests
def download(title, url):
""" 下载并保存视频 """
res = requests.get(
url=url,
headers={
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS"
}
)
with open('{}.mp4'.format(title), mode='wb') as f:
f.write(res.content)
# 读取文件
with open('db.csv', mode='r', encoding='utf-8') as file_object:
for line in file_object:
line = line.strip()
row_list = line.split(',')
# download(row_list[0], row_list[1])
download(*row_list)
2. 函数和函数名
函数名其实就是一个变量,这个变量只不过代指的函数而已。
name = "武沛齐"
def add(n1,n2):
return n1 + n2
注意:函数必须先定义才能被调用执行(解释型语言)。
# 正确
def add(n1,n2):
return n1 + n2
ret = add(1,2)
print(ret)
# 错误
ret = add(1,2)
print(ret)
def add(n1,n2):
return n1 + n2
2.1 函数做元素
既然函数就相当于是一个变量,那么在列表等元素中是否可以把行数当做元素呢?
def func():
return 123
data_list = ["武沛齐", "func", func , func() ]
print( data_list[0] ) # 字符串"武沛齐"
print( data_list[1] ) # 字符串 "func"
print( data_list[2] ) # 函数 func
print( data_list[3] ) # 整数 123
res = data_list[2]()
print( res ) # 执行函数 func,并获取返回值;print再输出返回值。
print( data_list[2]() ) # 123
注意:函数同时也可被哈希,所以函数名通知也可以当做 集合的元素、字典的键。
掌握这个知识之后,对后续的项目开发有很大的帮助,例如,在项目中遇到根据选择做不同操作时:
-
情景1,例如:要开发一个类似于微信的功能。
def send_message(): """发送消息""" pass def send_image(): """发送图片""" pass def send_emoji(): """发送表情""" pass def send_file(): """发送文件""" pass print("欢迎使用xx系统") print("请选择:1.发送消息;2.发送图片;3.发送表情;4.发送文件") choice = input("输入选择的序号") if choice == "1": send_message() elif choice == "2": send_image() elif choice == "3": send_emoji() elif choice == "4": send_file() else: print("输入错误")def send_message(): """发送消息""" pass def send_image(): """发送图片""" pass def send_emoji(): """发送表情""" pass def send_file(): """发送文件""" pass def xxx(): """收藏""" pass function_dict = { "1": send_message, "2": send_image, "3": send_emoji, "4": send_file, "5": xxx } print("欢迎使用xx系统") print("请选择:1.发送消息;2.发送图片;3.发送表情;4.发送文件") choice = input("输入选择的序号") # "1" func = function_dict.get(choice) if not func: print("输入错误") else: # 执行函数 func() -
情景2,例如:某个特定情况,要实现发送短信、微信、邮件。
def send_msg(): """发送短信""" pass def send_email(): """发送图片""" pass def send_wechat(): """发送微信""" # 执行函数 send_msg() send_email() send_wechat()def send_msg(): """发送短信""" pass def send_email(): """发送图片""" pass def send_wechat(): """发送微信""" pass func_list = [ send_msg, send_email, send_wechat ] for item in func_list: item()
上述两种情景,在参数相同时才可用,如果参数不一致,会出错。所以,在项目设计时就要让程序满足这一点,如果无法满足,也可以通过其他手段时间,例如:
情景1:
def send_message(phone,content):
"""发送消息"""
pass
def send_image(img_path, content):
"""发送图片"""
pass
def send_emoji(emoji):
"""发送表情"""
pass
def send_file(path):
"""发送文件"""
pass
function_dict = {
"1": [ send_message, ['15131255089', '你好呀']],
"2": [ send_image, ['xxx/xxx/xx.png', '消息内容']],
"3": [ send_emoji, ["😁"]],
"4": [ send_file, ['xx.zip'] ]
}
print("欢迎使用xx系统")
print("请选择:1.发送消息;2.发送图片;3.发送表情;4.发送文件")
choice = input("输入选择的序号") # 1
item = function_dict.get(choice) # [ send_message, ['15131255089', '你好呀']],
if not item:
print("输入错误")
else:
# 执行函数
func = item[0] # send_message
param_list = item[1] # ['15131255089', '你好呀']
func(*param_list) # send_message(*['15131255089', '你好呀'])
情景2:
def send_msg(mobile, content):
"""发送短信"""
pass
def send_email(to_email, subject, content):
"""发送图片"""
pass
def send_wechat(user_id, content):
"""发送微信"""
pass
func_list = [
{"name": send_msg, "params": {'mobile': "15131255089", "content": "你有新短消息"}},
{"name": send_email, "params": {'to_email': "wupeiqi@live.com", "subject": "报警消息", "content": "硬盘容量不够用了"}},
{"name": send_wechat, "params": {'user_id': 1, 'content': "约吗"}},
]
# {"name": send_msg, "params": {'mobile': "15131255089", "content": "你有新短消息"}},
for item in func_list:
func = item['name'] # send_msg
param_dict = item['params'] # {'mobile': "15131255089", "content": "你有新短消息"}
func(**param_dict) # send_msg(**{'mobile': "15131255089", "content": "你有新短消息"})
2.2 函数名赋值
-
将函数名赋值给其他变量,函数名其实就个变量,代指某函数;如果将函数名赋值给另外一个变量,则此变量也会代指该函数,例如:
def func(a1,a2): print(a1,a2) xxxxx = func # 此时,xxxxx和func都代指上面的那个函数,所以都可以被执行。 func(1,1) xxxxx(2,2)def func(a1,a2): print(a1,a2) func_list = [func,func,func] func(11,22) func_list[0](11,22) func_list[1](33,44) func_list[2](55,66) -
对函数名重新赋值,如果将函数名修改为其他值,函数名便不再代指函数,例如:
def func(a1,a2): print(a1,a2) # 执行func函数 func(11,22) # func重新赋值成一个字符串 func = "武沛齐" print(func)def func(a1,a2): print(a1+a2) func(1,2) def func(): print(666) func()注意:由于函数名被重新定义之后,就会变量新被定义的值,所以大家在自定义函数时,不要与python内置的函数同名,否则会覆盖内置函数的功能,例如:
id,bin,hex,oct,len...# len内置函数用于计算值得长度 v1 = len("武沛齐") print(v1) # 3 # len重新定义成另外一个函数 def len(a1,a2): return a1 + a2 # 以后执行len函数,只能按照重新定义的来使用 v3 = len(1,2) print(v3)
2.3 函数名做参数和返回值
函数名其实就一个变量,代指某个函数,所以,他和其他的数据类型一样,也可以当做函数的参数和返回值。
-
参数
def plus(num): return num + 100 def handler(func): res = func(10) # 110 msg = "执行func,并获取到的结果为:{}".format(res) print(msg) # 执行func,并获取到的结果为:110 # 执行handler函数,将plus作为参数传递给handler的形式参数func handler(plus) -
返回值
def plus(num): return num + 100 def handler(): print("执行handler函数") return plus result = handler() data = result(20) # 120 print(data)
3.返回值和print
对于初学者的同学,很多人都对print和返回值分不清楚,例如:
def add(n1,n2):
print(n1 + n2)
v1 = add(1,3)
print(v1)
# 输出
4
None
def plus(a1,a2):
return a1 + a2
v2 = plus(1,2)
print(v2)
# 输出
3
这两个函数是完全不同的
- 在函数中使用print,只是用于在某个位置输出内容而已。
- 在函数中使用return,是为了将函数的执行结果返回给调用者,以便于后续其他操作。
在调用并执行函数时,要学会分析函数的执行步骤。
def f1():
print(123)
def f2(arg):
ret = arg()
return ret
v1 = f2(f1)
print(v1)
# 输出
123
None
def f1():
print(123)
def f2(arg):
ret = arg()
return f1
v1 = f2(f1)
v2 = v1()
print(v2)
# 输出
123
123
None
4. 作用域
作用域,可以理解为一块空间,这块空间的数据是可以共享的。通俗点来说,作用域就类似于一个房子,房子中的东西归里面的所有人共享,其他房子的人无法获取。
4.1 函数为作用域
Python以函数为作用域,所以在函数内创建的所有数据,可以此函数中被使用,无法在其他函数中被使用。
def func():
name = "武沛齐"
data_list = [11,22,33,44]
print(name,data_list)
age = 20
print(age)
def handler():
age = 18
print(age)
func()
handler()
学会分析代码,了解变量到底属于哪个作用域且是否可以被调用:
def func():
name = "武沛齐"
age = 29
print(age)
data_list = [11,22,33,44]
print(name,data_list)
for num in range(10):
print(num)
print(num)
if 1 == 1:
value = "admin"
print(value)
print(value)
if 1 > 2:
max_num = 10
print(max_num)
print(max_num)
def handler():
age = 18
print(age)
handler()
func()
4.2 全局和局部
Python中以函数为作用域,函数的作用域其实是一个局部作用域。

goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998}
]
for index in range(len(goods)):
item = goods[index]
print(index + 1, item['name'], item['price'])
while True:
num = input("请输入要选择的商品序号(Q/q):") # "1"
if num.upper() == "Q":
break
if not num.isdecimal():
print("用输入的格式错误")
break
num = int(num)
send_email()
if num > 4 or num < 0:
print("范围选择错误")
break
target_index = num - 1
choice_item = goods[target_index]
print(choice_item["name"], choice_item['price'])
send_email()
# 全局变量(变量名大写)
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
# 局部变量
url = "http://www.xxx.com"
...
def upload():
file_name = "rose.zip"
...
COUNTRY和CITY_LIST是在全局作用域中,全局作用域中创建的变量称之为【全局变量】,可以在全局作用域中被使用,也可以在其局部作用域中被使用。
download和upload函数内部维护的就是一个局部作用域,在各自函数内部创建变量称之为【局部变量】,且局部变量只能在此作用域中被使用。局部作用域中想使用某个变量时,寻找的顺序为:优先在局部作用域中寻找,如果没有则去上级作用域中寻找。
注意:全局变量一般都是大写。
示例1:在局部作用域中读取全局作用域的变量。
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
url = "http://www.xxx.com"
print(url)
print(COUNTRY)
print(CITY_LIST)
def upload():
file_name = "rose.zip"
print(file_name)
print(COUNTRY)
print(CITY_LIST)
print(COUNTRY)
print(CITY_LIST)
downlowd()
upload()
print(file_name) # 报错
print(url) # 报错
示例2:局部作用域和全局作用域变量同名,这算啥?
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
url = "http://www.xxx.com"
CITY_LIST = ["河北","河南","山西"]
print(url)
print(COUNTRY)
print(CITY_LIST)
def upload():
file_name = "rose.zip"
print(COUNTRY)
print(CITY_LIST)
print(COUNTRY)
print(CITY_LIST)
download()
upload()
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
url = "http://www.xxx.com"
CITY_LIST = ["河北","河南","山西"]
print(url)
print(COUNTRY)
print(CITY_LIST)
def upload():
file_name = "rose.zip"
print(COUNTRY)
print(CITY_LIST)
print(COUNTRY)
print(CITY_LIST)
download()
upload()
COUNTRY = "中华人民共和共国"
CITY_LIST = [11,22,33]
download()
upload()
# 输出
中国
["北京","上海","深圳"]
http://www.xxx.com
中国
["河北","河南","山西"]
中国
["北京","上海","深圳"]
http://www.xxx.com
中华人民共和共国
["河北","河南","山西"]
中华人民共和共国
[11,22,33]
4.3 global关键字
默认情况下,在局部作用域对全局变量只能进行:读取和修改内部元素(可变类型),无法对全局变量进行重新赋值。
-
读取
COUNTRY = "中国" CITY_LIST = ["北京","上海","深圳"] def download(): url = "http://www.xxx.com" print(COUNTRY) print(CITY_LIST) download() -
修改内部元素(可变类型)
COUNTRY = "中国" CITY_LIST = ["北京","上海","深圳"] def download(): url = "http://www.xxx.com" print(CITY_LIST) CITY_LIST.append("广州") CITY_LIST[0] = "南京" print(CITY_LIST) download() -
无法对全局变量重新赋值
COUNTRY = "中国" CITY_LIST = ["北京","上海","深圳"] def download(): url = "http://www.xxx.com" # 不是对全部变量赋值,而是在局部作用域中又创建了一个局部变量 CITY_LIST 。 CITY_LIST = ["河北","河南","山西"] print(CITY_LIST) def upload(): file_name = "rose.zip" print(COUNTRY) print(CITY_LIST) download() upload()
如果想要在局部作用域中对全局变量重新赋值,则可以基于 global关键字实现,例如:
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
url = "http://www.xxx.com"
global CITY_LIST
CITY_LIST = ["河北","河南","山西"]
print(CITY_LIST)
global COUNTRY
COUNTRY = "中华人民共和国"
print(COUNTRY)
def upload():
file_name = "rose.zip"
print(COUNTRY)
print(CITY_LIST)
download()
upload()
总结
-
函数参数传递的是内存地址。
-
想重新创建一份数据再传递给参数,可以手动拷贝一份。
-
特殊:参数是动态参数时,通过*或**传参时,会将数据循环添加到参数中(类似于拷贝一份)
def fun(*args, **kwargs): print(args, kwargs) fun(*[11, 22, 33], **{"k1": 1, "k2": 2})
-
-
函数的返回值也是内存地址。(函数执行完毕后,其内部的所有变量都会被销毁,引用计数器为0时,数据也销毁)
def func(): name = [11,22,33] data = name func()def func(): name = [11,22,33] return name data = func() while True: print(data) -
当函数的参数有默认值 & 默认值是可变类型 & 函数内部会修改内部元素(有坑)
# 内部会维护一个列表 [],只要b不传值则始终使用都是这个列表。 def func(a,b=[]): b.append(a) -
定义函数写形式参数时可以使用
*和**,执行函数时也可以使用。 -
函数名其实也是个变量,他也可以做列表、字典、集合等元素(可哈希)
-
函数名可以被重新赋值,也可以做另外一个函数的参数和返回值。
-
掌握 print 和 return的区别,学会分析代码的执行流程。
-
python是以函数为作用域。
-
在局部作用域中寻找某数据时,优先用自己的,自己没有就在上级作用域中寻找。
-
基于 global关键字可以在局部作用域中实现对全局作用域中的变量(全局变量)重新赋值。
作业
-
如何查看一个值得内存地址?
-
函数的参数传递的是引用(内存地址)还是值(拷贝一份)?
-
看代码写结果
v1 = {} v2 = v1 v1["k1"] = 123 print(v1,v2) -
看代码写结果
def func(k,v,info={}): info[k] = v return info v1 = func(1,2) print(v1) v2 = func(4,5,{}) print(v2) v3 = func(5,6) print(v3) -
看代码写结果
def func(k,v,info={}): info[k] = v return info v1 = func(1,2) v2 = func(4,5,{}) v3 = func(5,6) print(v1,v2,v3) -
简述第5题、第6题的结果为何结果不同。
-
看代码写结果
def func(*args, **kwargs): print(args, kwargs) return "完毕" v1 = func(11, 22, 33) print(v1) v2 = func([11, 22, 33]) print(v2) v3 = func(*[11, 22, 33]) print(v3) v4 = func(k1=123, k2=456) print(v4) v5 = func({"k1": 123, "k2": 456}) print(v5) v6 = func(**{"k1": 123, "k2": 456}) print(v6) v7 = func([11, 22, 33], **{"k1": 123, "k2": 456}) print(v7) v8 = func(*[11, 22, 33], **{"k1": 123, "k2": 456}) print(v8) -
看代码写结果
def func(*args,**kwargs): prev = "-".join(args) data_list = [] for k,v in kwargs.items(): item = "{}-{}".format(k,v) data_list.append(item) content = "*".join(data_list) return prev,content v1 = func("北京","上海",city="深圳",count=99) print(v1) v2 = func(*["北京","上海"],**{"city":"深圳","count":99}) print(v2) -
补充代码,实现获取天气信息并按照指定格式写入到文件中。
# 获取天气信息示例 import requests res = requests.get(url="http://www.weather.com.cn/data/ks/101010100.html") res.encoding = "utf-8" weather_dict = res.json() # 获取的天气信息是个字典类型,内容如下: print(weather_dict) """ { 'weatherinfo': { 'city': '北京', 'cityid': '101010100', 'temp': '18', 'WD': '东南风', 'WS': '1级', 'SD': '17%', 'WSE': '1', 'time': '17:05', 'isRadar': '1', 'Radar': 'JC_RADAR_AZ9010_JB', 'njd': '暂无实况', 'qy': '1011', 'rain': '0' } } """import requests def write_file(**kwargs): """将天气信息拼接起来,并写入到文件 格式要求: 1. 每个城市的天气占一行 2. 每行的格式为:city-北京,cityid-101010100,temp-18... """ # 补充代码 def get_weather(code): """ 获取天气信息 """ url = "http://www.weather.com.cn/data/ks/{}.html".format(code) res = requests.get(url=url) res.encoding = "utf-8" weather_dict = res.json() return weather_dict city_list = [ {'code': "101020100", 'title': "上海"}, {'code': "101010100", 'title': "北京"}, ] # 补充代码 -
看代码写结果
def func(): return 1,2,3 val = func() print( type(val) == tuple ) print( type(val) == list ) -
看代码写结果
def func(users,name): users.append(name) print(users) result = func(['武沛齐','李杰'],'alex') print(result) -
看代码写结果
def func(v1): return v1 * 2 def bar(arg): return "%s 是什么玩意?" %(arg,) val = func('你') data = bar(val) print(data) -
看代码写结果
def func(v1): return v1* 2 def bar(arg): msg = "%s 是什么玩意?" %(arg,) print(msg) val = func('你') data = bar(val) print(data) -
看代码写结果
def func(): data = 2 * 2 return data data_list = [func,func,func] for item in data_list: v = item() print(v) -
分析代码,写结果:
def func(handler,**kwargs): extra = { "code":123, "name":"武沛齐" } kwargs.update(extra) return handler(**kwargs) def something(**kwargs): return len(kwargs) def killer(**kwargs): key_list = [] for key in kwargs.keys(): key_list.append(key) return key_list v1 = func(something,k1=123,k2=456) print(v1) v2 = func(killer,**{"name":"武沛齐","age":18}) print(v2) -
两个结果输出的分别是什么?并简述其原因。
def func(): return 123 v1 = [func,func,func,func,] print(v1) v2 = [func(),func(),func(),func()] print(v2) -
看代码结果
v1 = '武沛齐' def func(): print(v1) func() func() -
看代码结果
v1 = '武沛齐' def func(): print(v1) func() v1 = '老男人' func() -
看代码写结果
NUM_LIST = [] SIZE = 18 def f1(): NUM_LIST.append(8) SIZE = 19 def f2(): print(NUM_LIST) print(SIZE) f2() f1() f2() -
看代码写结果
NUM_LIST = [] SIZE = 18 def f1(): global NUM_LIST global SIZE NUM_LIST.append(8) SIZE = 19 def f2(): print(NUM_LIST) print(SIZE) f2() f1() f2() -
根据要求实现资源下载器。
-
启动后,让用户选择专区,每个专区用单独的函数实现,提供的专区如下:
- 下载 花瓣网图片专区
- 下载 抖音短视频专区
- 下载 NBA锦集 专区
-
在用户选择了某个功能之后,表示进入某下载专区,在里面循环提示用户可以下载的内容选项(已下载过的则不再提示下载)
提醒:可基于全部变量保存已下载过得资源。 -
在某个专区中,如果用户输入(Q/q)表示 退出上一级,即:选择专区。
-
在选择专区如果输入Q/q则退出整个程序。
-
每个专区实现下载的案例如下:
-
图片
# 可供用户下载的图片如下 image_dict = { "1":("吉他男神","https://hbimg.huabanimg.com/51d46dc32abe7ac7f83b94c67bb88cacc46869954f478-aP4Q3V"), "2":("漫画美女","https://hbimg.huabanimg.com/703fdb063bdc37b11033ef794f9b3a7adfa01fd21a6d1-wTFbnO"), "3":("游戏地图","https://hbimg.huabanimg.com/b438d8c61ed2abf50ca94e00f257ca7a223e3b364b471-xrzoQd"), "4":("alex媳妇","https://hbimg.huabanimg.com/4edba1ed6a71797f52355aa1de5af961b85bf824cb71-px1nZz"), }# 下载图片示例 import request res = requests.get( url="https://hbimg.huabanimg.com/4edba1ed6a71797f52355aa1de5af961b85bf824cb71-px1nZz", headers={ "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36" } ) with open("alex媳妇.png",mode="wb") as f: f.write(res.content) -
短视频
# 可供用户下载的短视频如下 video_dict = { "1":{"title":"东北F4模仿秀",'url':"https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"}, "2":{"title":"卡特扣篮",'url':"https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"}, "3":{"title":"罗斯mvp",'url':"https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg"}, }# 下载视频示例 import requests res = requests.get( url="https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg", headers={ "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS" } ) with open('罗斯mvp.mp4', mode='wb') as f: f.write(res.content) -
NBA
# 可供用户下载的NBA视频如下 nba_dict = { "1":{"title":"威少奇才首秀三双","url":"https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300fc20000bvi413nedtlt5abaa8tg&ratio=720p&line=0"}, "2":{"title":"塔图姆三分准绝杀","url":"https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0d00fb60000bvi0ba63vni5gqts0uag&ratio=720p&line=0"} }# 下载示例 import requests res = requests.get( url="https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0d00fb60000bvi0ba63vni5gqts0uag&ratio=720p&line=0", headers={ "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS" } ) with open('塔图姆三分准绝杀.mp4', mode='wb') as f: f.write(res.content)
-
作业讲解
-
# 1.如何查看一个值得内存地址?
基于内置函数id来获取,例如:
addr1 = id("武沛齐")
addr2 = id([11,22,33,44])
# 2.函数的参数传递的是引用(内存地址)还是值(拷贝一份)?
参数参数默认传递的是引用(内存地址)
# 3.看代码写结果
v1 = {}
v2 = v1
v1["k1"] = 123
print(v1, v2) # {'k1': 123} {'k1': 123}
# 4.看代码写结果
def func(k, v, info={}):
info[k] = v
return info
v1 = func(1, 2)
print(v1) # {1: 2}
v2 = func(4, 5, {})
print(v2) # {4: 5}
v3 = func(5, 6)
print(v3) # {1: 2, 5: 6}
# 5.看代码写结果
def func(k, v, info={}):
info[k] = v
return info
v1 = func(1, 2)
v2 = func(4, 5, {})
v3 = func(5, 6)
print(v1, v2, v3) # {1: 2, 5: 6} {4: 5} {1: 2, 5: 6}
# 6. 简述第5题、第6题的结果为何结果不同。
第5题中的 v1和v3变量指向的都是函数内部维护的那个列表的内存地址。
先print(v1)时,函数内部维护的列表的值当时是{1: 2}
最后print(v3)时,函数内部维护的列表的值已被修改为{1: 2, 5: 6}
第5题中的 v1和v3变量也是指向的都是函数内部维护的那个列表的内存地址。
最后再print v1和v3 时,结果就是最终函数内部维护的列表的值,即: {1: 2, 5: 6}
# 7.看代码写结果
def func(*args, **kwargs):
print(args, kwargs)
return "完毕"
v1 = func(11, 22, 33) # (11, 22, 33) {}
print(v1) # 完毕
v2 = func([11, 22, 33]) # ([11, 22, 33],) {}
print(v2) # 完毕
v3 = func(*[11, 22, 33]) # (11, 22, 33) {}
print(v3) # 完毕
v4 = func(k1=123, k2=456) # () {'k1': 123, 'k2': 456}
print(v4) # 完毕
v5 = func({"k1": 123, "k2": 456}) # ({'k1': 123, 'k2': 456},) {}
print(v5) # 完毕
v6 = func(**{"k1": 123, "k2": 456}) # () {'k1': 123, 'k2': 456}
print(v6) # 完毕
v7 = func([11, 22, 33], **{"k1": 123, "k2": 456}) # ([11, 22, 33],) {'k1': 123, 'k2': 456}
print(v7) # 完毕
v8 = func(*[11, 22, 33], **{"k1": 123, "k2": 456}) # (11, 22, 33) {'k1': 123, 'k2': 456}
print(v8) # 完毕
# 8.看代码写结果
def func(*args, **kwargs):
prev = "-".join(args)
data_list = []
for k, v in kwargs.items():
item = "{}-{}".format(k, v)
data_list.append(item)
content = "*".join(data_list)
return prev, content
v1 = func("北京", "上海", city="深圳", count=99)
print(v1) # ('北京-上海', 'city-深圳*count-99')
v2 = func(*["北京", "上海"], **{"city": "深圳", "count": 99})
print(v2) # ('北京-上海', 'city-深圳*count-99')
# 9.补充代码,实现获取天气信息并按照指定格式写入到文件中。【重点讲】
import requests
def write_file(**kwargs):
data_list = []
row_dict = kwargs["weatherinfo"]
for k, v in row_dict.items():
group = "{}-{}".format(k, v)
data_list.append(group)
row_string = ",".join(data_list)
with open('xxxx.txt', mode='a', encoding="utf-8") as file_object:
file_object.write("{}\n".format(row_string))
def get_weather(code):
url = "http://www.weather.com.cn/data/ks/{}.html".format(code)
res = requests.get(url=url)
res.encoding = "utf-8"
weather_dict = res.json()
return weather_dict
city_list = [
{'code': "101020100", 'title': "上海"},
{'code': "101010100", 'title': "北京"},
]
for item in city_list:
# 101020100
result_dict = get_weather(item["code"])
write_file(**result_dict)
# 10.看代码写结果
def func():
return 1, 2, 3
val = func()
print( type(val) == tuple) # True
print( type(val) == list) # False
print( type(val) == dict) # False
info = {
"1": [11, 22, 33],
"2": {'k1': 123, "k2": 456, "k3": "999"}
}
index = input("请输入序号:")
value = info[index]
if type(value) == list:
print(value[0], value[1], value[2])
elif type(value) == dict:
print(value['k1'], value['k2'], value['k3'])
# 11.看代码写结果
def func(users, name):
users.append(name)
print(users)
result = func(['武沛齐', '李杰'], 'alex') # # ['武沛齐', '李杰', 'alex']
print(result) # None
# 12.看代码写结果
def func(v1):
return v1 * 2
def bar(arg):
return "%s 是什么玩意?" % (arg,)
val = func('你')
data = bar(val)
print(data) # 你你 是什么玩意?
# 13.看代码写结果
def func(v1):
return v1 * 2
def bar(arg):
msg = "%s 是什么玩意?" % (arg,)
print(msg)
val = func('你')
data = bar(val) # 你你 是什么玩意?
print(data) # None
# 14.看代码写结果
def func():
data = 2 * 2
return data
data_list = [func,func,func]
for item in data_list:
v = item()
print(v)
# 输出:
# 4
# 4
# 4
# 15.分析代码,写结果
def func(handler, **kwargs):
# handler() -> killer()
# kwargs = {"name": "武沛齐", "age": 18}
extra = {
"code": 123,
"name": "武沛齐"
}
kwargs.update(extra)
# kwargs = {"name": "武沛齐", "age": 18,"code": 123,}
return handler(**kwargs)
def something(**kwargs):
return len(kwargs)
def killer(**kwargs):
# {"name": "武沛齐", "age": 18,"code": 123,}
key_list = []
for key in kwargs.keys():
key_list.append(key)
return key_list # ["name","age","code"]
v1 = func(something, k1=123, k2=456)
print(v1) # 4
v2 = func(killer, **{"name": "武沛齐", "age": 18})
print(v2) # ["name","age","code"]
# 16.两个结果输出的分别是什么?并简述其原因。
def func():
return 123
v1 = [func, func, func, func, ]
print(v1) # 列表,内部元素都是函数(将函数名放在列表的索引位置,函数名代指函数)
v2 = [func(), func(), func(), func()]
print(v2) # 列表,内部元素都是123(执行函数之后,将函数的返回值放在列表的索引位置)
# 17.看代码结果
v1 = '武沛齐'
def func():
print(v1)
func() # 武沛齐
func() # 武沛齐
# 18.看代码结果
v1 = '武沛齐'
def func():
print(v1)
func() # 武沛齐
v1 = '老男人'
func() # 老男人
# 19.看代码写结果
NUM_LIST = []
SIZE = 18
def f1():
NUM_LIST.append(8)
SIZE = 19
def f2():
print(NUM_LIST)
print(SIZE)
f2() # [] 18
f1() # 无任何输出
f2() # [8] 18
# 20.看代码写结果
NUM_LIST = [11, 22, 33]
SIZE = 18
def f1():
global NUM_LIST
global SIZE
NUM_LIST = "武沛齐"
SIZE = 19
def f2():
print(NUM_LIST)
print(SIZE)
f2() # [11,22,33] 18
f1() # 无输出
f2() # 武沛齐 19
# 21.资源下载器 v1版本【重点讲】
import requests
SELECTED_IMAGE_SET = set() # 已下载图片ID(序号)
SELECTED_VIDEO_SET = set()
SELECTED_NBA_SET = set()
def download(file_path, url):
res = requests.get(
url=url,
headers={
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS"
}
)
with open(file_path, mode='wb') as f:
f.write(res.content)
def download_image():
total_image_dict = {
"1": ("吉他男神", "https://hbimg.huabanimg.com/51d46dc32abe7ac7f83b94c67bb88cacc46869954f478-aP4Q3V"),
"2": ("漫画美女", "https://hbimg.huabanimg.com/703fdb063bdc37b11033ef794f9b3a7adfa01fd21a6d1-wTFbnO"),
"3": ("游戏地图", "https://hbimg.huabanimg.com/b438d8c61ed2abf50ca94e00f257ca7a223e3b364b471-xrzoQd"),
"4": ("alex媳妇", "https://hbimg.huabanimg.com/4edba1ed6a71797f52355aa1de5af961b85bf824cb71-px1nZz"),
}
while True:
# 构造 1.吉他男神;2.漫画美女;
text_list = []
for num, item in total_image_dict.items():
if num in SELECTED_IMAGE_SET:
continue
data = "{}.{}".format(num, item[0])
text_list.append(data)
if text_list:
text = ";".join(text_list)
else:
text = "无可下载选项"
# 输出:1.吉他男神;2.漫画美女;3.游戏地图;4.alex媳妇
print(text)
# 返回上一步
index = input("请输入要选择的序号(Q/q退出):")
if index.upper() == "Q":
return
# 选择序号 3
if index in SELECTED_IMAGE_SET:
print("已下载,无法再继续下载,请重新选择!")
continue
group = total_image_dict.get(index)
if not group:
print("序号不存在,请重新选择")
continue
# 下载图片
file_path = "{}.png".format(group[0])
download(file_path, group[1])
# 已下载集合中
SELECTED_IMAGE_SET.add(index)
def download_video():
total_video_dict = {
"1": {"title": "东北F4模仿秀",
'url': "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"},
"2": {"title": "卡特扣篮",
'url': "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"},
"3": {"title": "罗斯mvp",
'url': "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg"},
}
while True:
text_list = []
for num, item in total_video_dict.items():
if num in SELECTED_VIDEO_SET:
continue
data = "{}.{}".format(num, item["title"])
text_list.append(data)
if text_list:
text = ";".join(text_list)
else:
text = "无可下载选项"
print(text)
index = input("请输入要选择的序号(Q/q退出):")
if index.upper() == "Q":
return
if index in SELECTED_VIDEO_SET:
print("已下载,无法再继续下载,请重新选择!")
continue
group = total_video_dict.get(index)
if not group:
print("序号不存在,请重新选择")
continue
file_path = "{}.mp4".format(group["title"])
download(file_path, group["url"])
SELECTED_VIDEO_SET.add(index)
def download_nba():
total_nba_dict = {
"1": {"title": "威少奇才首秀三双",
"url": "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300fc20000bvi413nedtlt5abaa8tg&ratio=720p&line=0"},
"2": {"title": "塔图姆三分准绝杀",
"url": "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0d00fb60000bvi0ba63vni5gqts0uag&ratio=720p&line=0"}
}
while True:
text_list = []
for num, item in total_nba_dict.items():
if num in SELECTED_NBA_SET:
continue
data = "{}.{}".format(num, item["title"])
text_list.append(data)
if text_list:
text = ";".join(text_list)
else:
text = "无可下载选项"
print(text)
index = input("请输入要选择的序号(Q/q退出):")
if index.upper() == "Q":
return
if index in SELECTED_NBA_SET:
print("已下载,无法再继续下载,请重新选择!")
continue
group = total_nba_dict.get(index)
if not group:
print("序号不存在,请重新选择")
continue
file_path = "{}.mp4".format(group["title"])
download(file_path, group["url"])
SELECTED_NBA_SET.add(index)
print("欢迎使用xxx系统")
func_dict = {
"1": download_image,
"2": download_video,
"3": download_nba
}
while True:
print("1.花瓣网图片专区;2.抖音短视频专区;3.NBA锦集专区 ")
choice = input("请选择序号:")
if choice.upper() == "Q":
break
func = func_dict.get(choice)
if not func:
print("输入错误,请重新选择!")
continue
# 进入专区
func()
# 21.资源下载器 v2版本
import requests
DB = {
"1": {
"area": "花瓣网图片专区",
"total_dict": {
"1": ("吉他男神", "https://hbimg.huabanimg.com/51d46dc32abe7ac7f83b94c67bb88cacc46869954f478-aP4Q3V"),
"2": ("漫画美女", "https://hbimg.huabanimg.com/703fdb063bdc37b11033ef794f9b3a7adfa01fd21a6d1-wTFbnO"),
"3": ("游戏地图", "https://hbimg.huabanimg.com/b438d8c61ed2abf50ca94e00f257ca7a223e3b364b471-xrzoQd"),
"4": ("alex媳妇", "https://hbimg.huabanimg.com/4edba1ed6a71797f52355aa1de5af961b85bf824cb71-px1nZz"),
},
"ext": "png",
"selected": set()
},
"2": {
"area": "抖音短视频专区",
"total_dict": {
"1": {"title": "东北F4模仿秀",
'url': "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"},
"2": {"title": "卡特扣篮",
'url': "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"},
"3": {"title": "罗斯mvp",
'url': "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg"},
},
"ext": "mp4",
"selected": set()
},
"3": {
"area": "NBA锦集专区",
"total_dict": {
"1": {"title": "威少奇才首秀三双",
"url": "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300fc20000bvi413nedtlt5abaa8tg&ratio=720p&line=0"},
"2": {"title": "塔图姆三分准绝杀",
"url": "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0d00fb60000bvi0ba63vni5gqts0uag&ratio=720p&line=0"}
},
"ext": "mp4",
"selected": set()
},
}
def download(file_path, url):
res = requests.get(
url=url,
headers={
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS"
}
)
with open(file_path, mode='wb') as f:
f.write(res.content)
def handler(area_info):
# 进入专区提醒
summary = "欢迎进入{}".format(area_info['area'])
print(summary)
# 专区中选择下载
while True:
text_list = []
for num, item in area_info['total_dict'].items():
if num in area_info['selected']:
continue
if type(item) == tuple:
data = "{}.{}".format(num, item[0])
else:
data = "{}.{}".format(num, item["title"])
text_list.append(data)
if text_list:
text = ";".join(text_list)
else:
text = "无可下载选项"
print(text)
index = input("请输入要选择的序号(Q/q退出):")
if index.upper() == "Q":
return
if index in area_info['selected']:
print("已下载,无法再继续下载,请重新选择!")
continue
group = area_info['total_dict'].get(index)
if not group:
print("序号不存在,请重新选择")
continue
if type(group) == tuple:
title, url = group
else:
title, url = group['title'], group['url']
file_path = "{}.{}".format(title, area_info['ext'])
download(file_path, url)
area_info['selected'].add(index)
print("欢迎使用xxx系统")
while True:
print("1.花瓣网图片专区;2.抖音短视频专区;3.NBA锦集 专区 ")
choice = input("请选择序号(Q/q退出):")
if choice.upper() == "Q":
break
# 选择序号: 去db中找对应的字典信息
area_dict = DB.get(choice)
if not area_dict:
print("输入错误,请重新选择!")
continue
# 进入专区(area_dict选择的专区信息)
handler(area_dict)
day12 函数高级
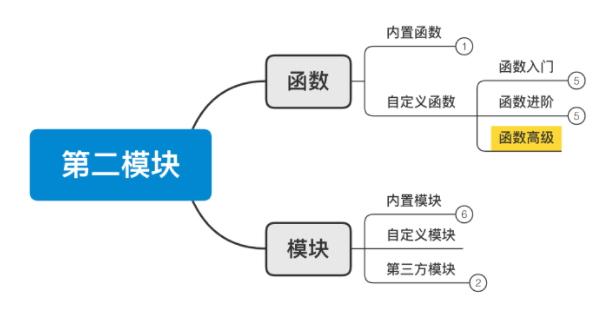
课程目标:掌握函数嵌套、闭包、装饰器等高级知识点。
今日概要:
- 函数的嵌套
- 闭包
- 装饰器
上述内容均属于函数部分必备知识,以后开发时直接和间接都会使用,请务必理解(重在理解,不要去死记硬背)。
1. 函数嵌套
Python中以函数为作用域,在作用域中定义的相关数据只能被当前作用域或子作用域使用。
NAME = "武沛齐"
print(NAME)
def func():
print(NAME)
func()
1.1 函数在作用域中
其实,函数也是定义在作用域中的数据,在执行函数时候,也同样遵循:优先在自己作用域中寻找,没有则向上一接作用域寻找,例如:
# 1. 在全局作用域定义了函数func
def func():
print("你好")
# 2. 在全局作用域找到func函数并执行。
func()
# 3.在全局作用域定义了execute函数
def execute():
print("开始")
# 优先在当前函数作用域找func函数,没有则向上级作用域中寻找。
func()
print("结束")
# 4.在全局作用域执行execute函数
execute()
此处,有一个易错点:作用域中的值在被调用时到底是啥?
-
情景1
def func(): print("你好") func() def execute(): print("开始") func() print("结束") execute() def func(): print(666) func() -
情景2
def func(): print("你好") func() def execute(): print("开始") func() print("结束") def func(): print(666) func() execute()
1.2 函数定义的位置
上述示例中的函数均定义在全局作用域,其实函数也可以定义在局部作用域,这样函数被局部作用域和其子作用于中调用(函数的嵌套)。
def func():
print("沙河高晓松")
def handler():
print("昌平吴彦祖")
def inner():
print("朝阳大妈")
inner()
func()
print("海淀网友")
handler()
到现在你会发现,只要理解数据定义时所存在的作用域,并根据从上到下代码执行过程进行分析,再怎么嵌套都可以搞定。
现在的你可能有疑问:为什么要这么嵌套定义?把函数都定义在全局不好吗?
其实,大多数情况下我们都会将函数定义在全局,不会嵌套着定义函数。不过,当我们定义一个函数去实现某功能,想要将内部功能拆分成N个函数,又担心这个N个函数放在全局会与其他函数名冲突时(尤其多人协同开发)可以选择使用函数的嵌套。
def f1():
pass
def f2():
pass
def func():
f1()
f2()
def func():
def f1():
pass
def f2():
pass
f1()
f2()
"""
生成图片验证码的示例代码,需要提前安装pillow模块(Python中操作图片中一个第三方模块)
pip3 install pillow
"""
import random
from PIL import Image, ImageDraw, ImageFont
def create_image_code(img_file_path, text=None, size=(120, 30), mode="RGB", bg_color=(255, 255, 255)):
""" 生成一个图片验证码 """
_letter_cases = "abcdefghjkmnpqrstuvwxy" # 小写字母,去除可能干扰的i,l,o,z
_upper_cases = _letter_cases.upper() # 大写字母
_numbers = ''.join(map(str, range(3, 10))) # 数字
chars = ''.join((_letter_cases, _upper_cases, _numbers))
width, height = size # 宽高
# 创建图形
img = Image.new(mode, size, bg_color)
draw = ImageDraw.Draw(img) # 创建画笔
def get_chars():
"""生成给定长度的字符串,返回列表格式"""
return random.sample(chars, 4)
def create_lines():
"""绘制干扰线"""
line_num = random.randint(*(1, 2)) # 干扰线条数
for i in range(line_num):
# 起始点
begin = (random.randint(0, size[0]), random.randint(0, size[1]))
# 结束点
end = (random.randint(0, size[0]), random.randint(0, size[1]))
draw.line([begin, end], fill=(0, 0, 0))
def create_points():
"""绘制干扰点"""
chance = min(100, max(0, int(2))) # 大小限制在[0, 100]
for w in range(width):
for h in range(height):
tmp = random.randint(0, 100)
if tmp > 100 - chance:
draw.point((w, h), fill=(0, 0, 0))
def create_code():
"""绘制验证码字符"""
if text:
code_string = text
else:
char_list = get_chars()
code_string = ''.join(char_list) # 每个字符前后以空格隔开
# Win系统字体
# font = ImageFont.truetype(r"C:\Windows\Fonts\SEGOEPR.TTF", size=24)
# Mac系统字体
# font = ImageFont.truetype("/System/Library/Fonts/SFNSRounded.ttf", size=24)
# 项目字体文件
font = ImageFont.truetype("MSYH.TTC", size=15)
draw.text([0, 0], code_string, "red", font=font)
return code_string
create_lines()
create_points()
code = create_code()
# 将图片写入到文件
with open(img_file_path, mode='wb') as img_object:
img.save(img_object)
return code
code = create_image_code("a2.png")
print(code)
1.3 嵌套引发的作用域问题
基于内存和执行过程分析作用域。
name = "武沛齐"
def run():
name = "alex"
def inner():
print(name)
inner()
run()

name = "武沛齐"
def run():
name = "alex"
def inner():
print(name)
return inner
v1 = run()
v1()
v2 = run()
v2()

name = "武沛齐"
def run():
name = "alex"
def inner():
print(name)
return [inner,inner,inner]
func_list = run()
func_list[2]()
func_list[1]()
funcs = run()
funcs[2]()
funcs[1]()
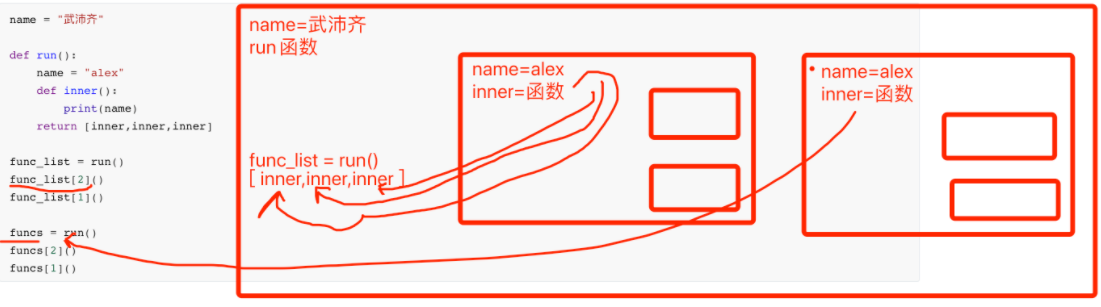
三句话搞定作用域:
- 优先在自己的作用域找,自己没有就去上级作用域。
- 在作用域中寻找值时,要确保此次此刻值是什么。
- 分析函数的执行,并确定函数
作用域链。(函数嵌套)
练习题
-
分析代码,写结果
name = '武沛齐' def func(): def inner(): print(name) res = inner() return res v = func() print(v) # 武沛齐 # None -
分析代码,写结果
name = '武沛齐' def func(): def inner(): print(name) return "alex" res = inner() return res v = func() print(v) # 武沛齐 # alex -
分析代码,写结果
name = 'root' def func(): def inner(): print(name) return 'admin' return inner v = func() result = v() print(result) # root # admin -
分析代码,写结果
def func(): name = '武沛齐' def inner(): print(name) return '路飞' return inner v11 = func() data = v11() print(data) v2 = func()() print(v2) -
分析代码,写结果
def func(name): # name="alex" def inner(): print(name) return 'luffy' return inner v1 = func('武沛齐')() print(v1) v2 = func('alex')() print(v2)
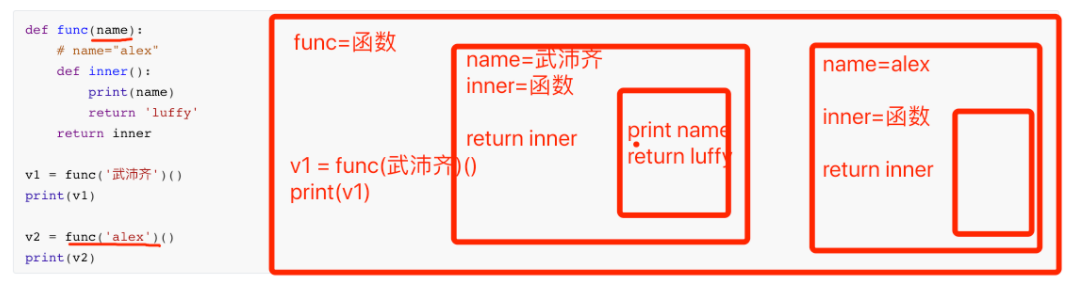
def func(name):
def inner():
print(name)
return 'luffy'
return inner
v1 = func('武沛齐')
v2 = func('alex')
v1()
v2()

-
分析代码,写结果
def func(name=None): if not name: name= '武沛齐' def inner(): print(name) return 'root' return inner v1 = func()() v2 = func('alex')() print(v1,v2) # 武沛齐 # alex # root root

2.闭包
闭包,简而言之就是将数据封装在一个包(区域)中,使用时再去里面取。(本质上 闭包是基于函数嵌套搞出来一个中特殊嵌套)
-
闭包应用场景1:封装数据防止污染全局。
name = "武沛齐" def f1(): print(name, age) def f2(): print(name, age) def f3(): print(name, age) def f4(): passdef func(age): name = "武沛齐" def f1(): print(name, age) def f2(): print(name, age) def f3(): print(name, age) f1() f2() f3() func(123) -
闭包应用场景2:封装数据封到一个包里,使用时在取。
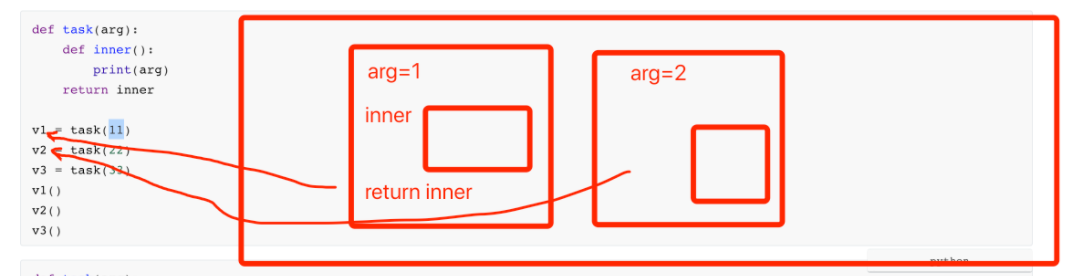
def task(arg): def inner(): print(arg) return inner v1 = task(11) v2 = task(22) v3 = task(33) v1() v2() v3()def task(arg): def inner(): print(arg) return inner inner_func_list = [] for val in [11,22,33]: inner_func_list.append( task(val) ) inner_func_list[0]() # 11 inner_func_list[1]() # 22 inner_func_list[2]() # 33""" 基于多线程去下载视频 """ from concurrent.futures.thread import ThreadPoolExecutor import requests def download_video(url): res = requests.get( url=url, headers={ "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS" } ) return res.content def outer(file_name): def write_file(response): content = response.result() with open(file_name, mode='wb') as file_object: file_object.write(content) return write_file POOL = ThreadPoolExecutor(10) video_dict = [ ("东北F4模仿秀.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"), ("卡特扣篮.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"), ("罗斯mvp.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg") ] for item in video_dict: future = POOL.submit(download_video, url=item[1]) future.add_done_callback(outer(item[0])) POOL.shutdown()
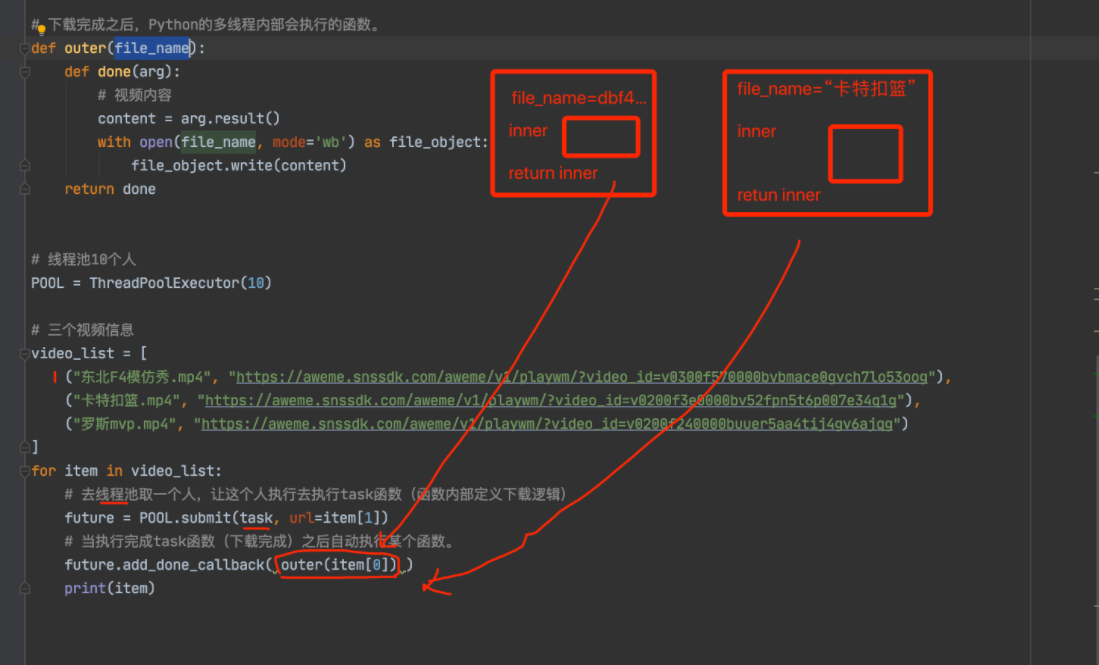
3.装饰器
现在给你一个函数,在不修改函数源码的前提下,实现在函数执行前和执行后分别输入 "before" 和 "after"。
def func():
print("我是func函数")
value = (11,22,33,44)
return value
result = func()
print(result)
3.1 第一回合
你的实现思路:
def func():
print("before")
print("我是func函数")
value = (11,22,33,44)
print("after")
return value
result = func()
我的实现思路:
def func():
print("我是func函数")
value = (11, 22, 33, 44)
return value
def outer(origin):
def inner():
print('inner')
origin()
print("after")
return inner
func = outer(func)
result = func()
处理返回值:
def func():
print("我是func函数")
value = (11, 22, 33, 44)
return value
def outer(origin):
def inner():
print('inner')
res = origin()
print("after")
return res
return inner
func = outer(func)
result = func()
3.2 第二回合
在Python中有个一个特殊的语法糖:
def outer(origin):
def inner():
print('inner')
res = origin()
print("after")
return res
return inner
@outer
def func():
print("我是func函数")
value = (11, 22, 33, 44)
return value
func()
3.3 第三回合
请在这3个函数执行前和执行后分别输入 "before" 和 "after"
def func1():
print("我是func1函数")
value = (11, 22, 33, 44)
return value
def func2():
print("我是func2函数")
value = (11, 22, 33, 44)
return value
def func3():
print("我是func3函数")
value = (11, 22, 33, 44)
return value
func1()
func2()
func3()
你的实现思路:
def func1():
print('before')
print("我是func1函数")
value = (11, 22, 33, 44)
print("after")
return value
def func2():
print('before')
print("我是func2函数")
value = (11, 22, 33, 44)
print("after")
return value
def func3():
print('before')
print("我是func3函数")
value = (11, 22, 33, 44)
print("after")
return value
func1()
func2()
func3()
我的实现思路:
def outer(origin):
def inner():
print("before 110")
res = origin() # 调用原来的func函数
print("after")
return res
return inner
@outer
def func1():
print("我是func1函数")
value = (11, 22, 33, 44)
return value
@outer
def func2():
print("我是func2函数")
value = (11, 22, 33, 44)
return value
@outer
def func3():
print("我是func3函数")
value = (11, 22, 33, 44)
return value
func1()
func2()
func3()
装饰器,在不修改原函数内容的前提下,通过@函数可以实现在函数前后自定义执行一些功能(批量操作会更有意义)。
优化
优化以支持多个参数的情况。
def outer(origin):
def inner(*args, **kwargs):
print("before 110")
res = origin(*args, **kwargs) # 调用原来的func函数
print("after")
return res
return inner
@outer # func1 = outer(func1)
def func1(a1):
print("我是func1函数")
value = (11, 22, 33, 44)
return value
@outer # func2 = outer(func2)
def func2(a1, a2):
print("我是func2函数")
value = (11, 22, 33, 44)
return value
@outer # func3 = outer(func3)
def func3(a1):
print("我是func3函数")
value = (11, 22, 33, 44)
return value
func1(1)
func2(11, a2=22)
func3(999)
其中,我的那种写法就称为装饰器。
-
实现原理:基于@语法和函数闭包,将原函数封装在闭包中,然后将函数赋值为一个新的函数(内层函数),执行函数时再在内层函数中执行闭包中的原函数。
-
实现效果:可以在不改变原函数内部代码 和 调用方式的前提下,实现在函数执行和执行扩展功能。
-
适用场景:多个函数系统统一在 执行前后自定义一些功能。
-
装饰器示例
def outer(origin): def inner(*args, **kwargs): # 执行前 res = origin(*args, **kwargs) # 调用原来的func函数 # 执行后 return res return inner @outer def func(): pass func()
伪应用场景
在以后编写一个网站时,如果项目共有100个页面,其中99个是需要登录成功之后才有权限访问,就可以基于装饰器来实现。
pip3 install flask
基于第三方模块Flask(框架)快速写一个网站:
from flask import Flask
app = Flask(__name__)
def index():
return "首页"
def info():
return "用户中心"
def order():
return "订单中心"
def login():
return "登录页面"
app.add_url_rule("/index/", view_func=index)
app.add_url_rule("/info/", view_func=info)
app.add_url_rule("/login/", view_func=login)
app.run()
基于装饰器实现的伪代码:
from flask import Flask
app = Flask(__name__)
def auth(func):
def inner(*args, **kwargs):
# 在此处,判断如果用户是否已经登录,已登录则继续往下,未登录则自动跳转到登录页面。
return func(*args, **kwargs)
return inner
@auth
def index():
return "首页"
@auth
def info():
return "用户中心"
@auth
def order():
return "订单中心"
def login():
return "登录页面"
app.add_url_rule("/index/", view_func=index, endpoint='index')
app.add_url_rule("/info/", view_func=info, endpoint='info')
app.add_url_rule("/order/", view_func=order, endpoint='order')
app.add_url_rule("/login/", view_func=login, endpoint='login')
app.run()
重要补充:functools
你会发现装饰器实际上就是将原函数更改为其他的函数,然后再此函数中再去调用原函数。
def handler():
pass
handler()
print(handler.__name__) # handler
def auth(func):
def inner(*args, **kwargs):
return func(*args, **kwargs)
return inner
@auth
def handler():
pass
handler()
print(handler.__name__) # inner
import functools
def auth(func):
@functools.wraps(func)
def inner(*args, **kwargs):
return func(*args, **kwargs)
return inner
@auth
def handler():
pass
handler()
print(handler.__name__) # handler
其实,一般情况下大家不用functools也可以实现装饰器的基本功能,但后期在项目开发时,不加functools会出错(内部会读取__name__,且__name__重名的话就报错),所以在此大家就要规范起来自己的写法。
import functools
def auth(func):
@functools.wraps(func)
def inner(*args, **kwargs):
"""巴巴里吧"""
res = func(*args, **kwargs) # 执行原函数
return res
return inner
总结
-
函数可以定义在全局、也可以定义另外一个函数中(函数的嵌套)
-
学会分析函数执行的步骤(内存中作用域的管理)
-
闭包,基于函数的嵌套,可以将数据封装到一个包中,以后再去调用。
-
装饰器
-
实现原理:基于@语法和函数闭包,将原函数封装在闭包中,然后将函数赋值为一个新的函数(内层函数),执行函数时再在内层函数中执行闭包中的原函数。
-
实现效果:可以在不改变原函数内部代码 和 调用方式的前提下,实现在函数执行和执行扩展功能。
-
适用场景:多个函数系统统一在 执行前后自定义一些功能。
-
装饰器示例
import functools def auth(func): @functools.wraps(func) def inner(*args, **kwargs): """巴巴里吧""" res = func(*args, **kwargs) # 执行原函数 return res return inner
-
作业
-
请为以下所有函数编写一个装饰器,添加上装饰器后可以实现:执行func时,先执行func函数内部代码,再输出 "after"
def func(a1): return a1 + "傻叉" def base(a1,a2): return a1 + a2 + '傻缺' def foo(a1,a2,a3,a4): return a1 + a2 + a3 + a4 + '傻蛋' -
请为以下所有函数编写一个装饰器,添加上装饰器后可以实现:将被装饰的函数执行5次,讲每次执行函数的结果按照顺序放到列表中,最终返回列表。
import random def func(): return random.randint(1,4) result = func() # 内部自动执行5次,并将每次执行的结果追加到列表最终返回给result print(result) -
请为以下函数编写一个装饰器,添加上装饰器后可以实现: 检查文件所在路径(文件件)是否存在,如果不存在自动创建文件夹(保证写入文件不报错)。
def write_user_info(path): file_obj = open(path, mode='w', encoding='utf-8') file_obj.write("武沛齐") file_obj.close() write_user_info('/usr/bin/xxx/xxx.png') -
分析代码写结果:
def get_data(): scores = [] def inner(val): scores.append(val) print(scores) return inner func = get_data() func(10) func(20) func(30) -
看代码写结果
name = "武沛齐" def foo(): print(name) def func(): name = "root" foo() func() -
看代码写结果
name = "武沛齐" def func(): name = "root" def foo(): print(name) foo() func() -
看代码写结果
def func(val): def inner(a1, a2): return a1 + a2 + val return inner data_list = [] for i in range(10): data_list.append( func(i) ) print(data_list) -
看代码写结果
def func(val): def inner(a1, a2): return a1 + a2 + val return inner data_list = [] for i in range(10): data_list.append(func(i)) v1 = data_list[0](11,22) v2 = data_list[2](33,11) print(v1) print(v2)
作业答案
# ################### 第1题 ###################
import functools
def outer(function):
@functools.wraps(function)
def inner(*args, **kwargs):
# print("before")
res = function(*args, **kwargs) # 执行原函数
print("after")
return res
return inner
@outer
def func(a1):
return a1 + "傻叉"
@outer
def base(a1, a2):
return a1 + a2 + '傻缺'
@outer
def foo(a1, a2, a3, a4):
return a1 + a2 + a3 + a4 + '傻蛋'
# ################### 第2题 ###################
import random
import functools
def five_times(function):
@functools.wraps(function)
def inner(*args, **kwargs):
data_list = []
for i in range(5):
res = function(*args, **kwargs) # 执行原函数
data_list.append(res)
return data_list
return inner
@five_times
def func():
return random.randint(1, 4)
result = func() # 内部自动执行5次,并将每次执行的结果追加到列表最终返回给result
print(result)
# ################### 第3题 ###################
import os
import functools
def gard(function):
@functools.wraps(function)
def inner(path):
# 获取路径的上级目录
# folder_path = path.rsplit('/', 1)[0]
folder_path = os.path.dirname(path)
# 不存在,就创建
if not os.path.exists(folder_path):
os.makedirs(folder_path)
res = function(path)
return res
return inner
@gard
def write_user_info(path):
file_obj = open(path, mode='w', encoding='utf-8')
file_obj.write("武沛齐")
file_obj.close()
write_user_info('/Users/wupeiqi/PycharmProjects/luffyCourse/day12/xxx.txt')
# ################### 第4~8题 ###################
# 分析过程,请参见视频讲解
def func(val):
def inner(a1, a2):
return a1 + a2 + val
return inner
data_list = []
for i in range(10):
data_list.append(func(i))
# data_list 是inner函数列表
v1 = data_list[0](11, 22) # 11+22+0
v2 = data_list[2](33, 11) # 33+11+2
print(v1)
print(v2)
day13 内置函数和推导式
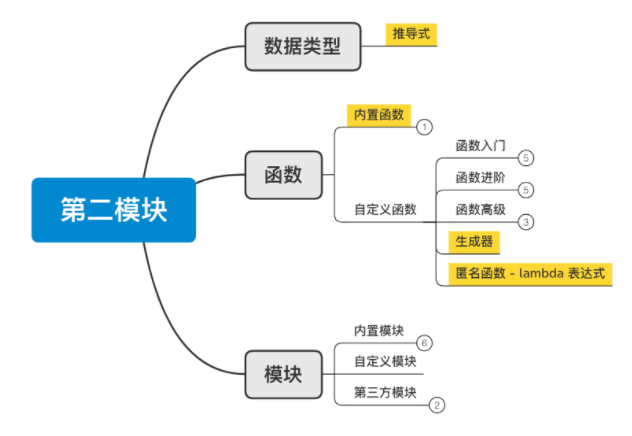
今日概要:
- 匿名函数
- 生成器
- 内置函数
- 附加:推导式,属于数据类型的知识,内部的高级的用法会涉及到【生成器】和【函数】的知识。
1. 匿名函数
传统的函数的定义包括了:函数名 + 函数体。
def send_email():
pass
# 1. 执行
send_email()
# 2. 当做列表元素
data_list = [send_email, send_email, send_email ]
# 3. 当做参数传递
other_function(send_email)
匿名函数,则是基于lambda表达式实现定义一个可以没有名字的函数,例如:
data_list = [ lambda x:x+100, lambda x:x+110, lambda x:x+120 ]
print( data_list[0] )
f1 = lambda x:x+100
res = f1(100)
print(res)
基于Lambda定义的函数格式为:lambda 参数:函数体
-
参数,支持任意参数。
lambda x: 函数体 lambda x1,x2: 函数体 lambda *args, **kwargs: 函数体 -
函数体,只能支持单行的代码。
def xxx(x): return x + 100 lambda x: x + 100 -
返回值,默认将函数体单行代码执行的结果返回给函数的执行这。
func = lambda x: x + 100 v1 = func(10) print(v1) # 110
def func(a1,a2):
return a1 + a2 + 100
foo = lambda a1,a2: a1 + a2 + 100
匿名函数适用于简单的业务处理,可以快速并简单的创建函数。
练习题
根据函数写写出其匿名函数的表达方式
def func(a1,a2):
return a1 + a2
func = lambda a1,a2: a1+a2
def func(data):
return data.replace("苍老师","***")
func= lambda data: data.replace("苍老师","***")
def func(data):
name_list = data.replace(".")
return name_list[-1]
func = lambda data: data.replace(".")[-1]
在编写匿名函数时,由于受限 函数体只能写一行,所以匿名函数只能处理非常简单的功能。
扩展:三元运算
简单的函数,可以基于lambda表达式实现。
简单的条件语句,可以基于三元运算实现,例如:
num = input("请写入内容")
if "苍老师" in num:
data = "臭不要脸"
else:
data = "正经人"
print(data)
num = input("请写入内容")
data = "臭不要脸" if "苍老师" in num else "正经人"
print(data)
# 结果 = 条件成立时 if 条件 else 不成立
lambda表达式和三元运算没有任何关系,属于两个独立的知识点。
掌握三元运算之后,以后再编写匿名函数时,就可以处理再稍微复杂点的情况了,例如:
func = lambda x: "大了" if x > 66 else "小了"
v1 = func(1)
print(v1) # "小了"
v2 = func(100)
print(v2) # "大了"
2. 生成器
生成器是由函数+yield关键字创造出来的写法,在特定情况下,用他可以帮助我们节省内存。
-
生成器函数,但函数中有yield存在时,这个函数就是生产生成器函数。
def func(): print(111) yield 1def func(): print(111) yield 1 print(222) yield 2 print(333) yield 3 print(444) -
生成器对象,执行生成器函数时,会返回一个生成器对象。
def func(): print(111) yield 1 print(222) yield 2 print(333) yield 3 print(444) data = func() # 执行生成器函数func,返回的生成器对象。 # 注意:执行生成器函数时,函数内部代码不会执行。def func(): print(111) yield 1 print(222) yield 2 print(333) yield 3 print(444) data = func() v1 = next(data) print(v1) v2 = next(data) print(v2) v3 = next(data) print(v3) v4 = next(data) print(v4) # 结束或中途遇到return,程序爆:StopIteration 错误data = func() for item in data: print(item)
生成器的特点是,记录在函数中的执行位置,下次执行next时,会从上一次的位置基础上再继续向下执行。
应用场景
-
假设要让你生成 300w个随机的4位数,并打印出来。
- 在内存中一次性创建300w个
- 动态创建,用一个创建一个。
import random val = random.randint(1000, 9999) print(val)import random data_list = [] for i in range(300000000): val = random.randint(1000, 9999) data_list.append(val) # 再使用时,去 data_list 中获取即可。 # ...import random def gen_random_num(max_count): counter = 0 while counter < max_count: yield random.randint(1000, 9999) counter += 1 data_list = gen_random_num(3000000) # 再使用时,去 data_list 中获取即可。 -
假设让你从某个数据源中获取300w条数据(后期学习操作MySQL 或 Redis等数据源再操作,了解思想即可)。
所以,当以后需要我们在内存中创建很多数据时,可以想着用基于生成器来实现一点一点生成(用一点生产一点),以节省内存的开销。
扩展
def func():
print(111)
v1 = yield 1
print(v1)
print(222)
v2 = yield 2
print(v2)
print(333)
v3 = yield 3
print(v3)
print(444)
data = func()
n1 = data.send(None)
print(n1)
n2 = data.send(666)
print(n2)
n3 = data.send(777)
print(n3)
n4 = data.send(888)
print(n4)
3.内置函数
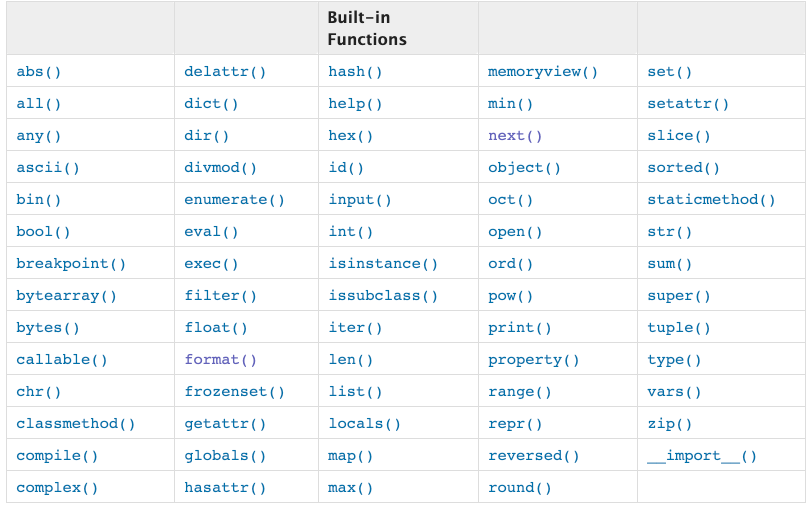
Python内部为我们提供了很多方便的内置函数,在此整理出来36个给大家来讲解。
-
第1组(5个)
-
abs,绝对值
v = abs(-10) -
pow,指数
v1 = pow(2,5) # 2的5次方 2**5 print(v1) -
sum,求和
v1 = sum([-11, 22, 33, 44, 55]) # 可以被迭代-for循环 print(v1) -
divmod,求商和余数
v1, v2 = divmod(9, 2) print(v1, v2) -
round,小数点后n位(四舍五入)
v1 = round(4.11786, 2) print(v1) # 4.12
-
-
第2组:(4个)
-
min,最小值
v1 = min(11, 2, 3, 4, 5, 56) print(v1) # 2v2 = min([11, 22, 33, 44, 55]) # 迭代的类型(for循环) print(v2)v3 = min([-11, 2, 33, 44, 55], key=lambda x: abs(x)) print(v3) # 2 -
max,最大值
v1 = max(11, 2, 3, 4, 5, 56) print(v1) v2 = max([11, 22, 33, 44, 55]) print(v2)v3 = max([-11, 22, 33, 44, 55], key=lambda x: x * 10) print(v3) # 55 -
all,是否全部为True
v1 = all( [11,22,44,""] ) # False -
any,是否存在True
v2 = any([11,22,44,""]) # True
-
-
第3组(3个)
- bin,十进制转二进制
- oct,十进制转八进制
- hex,十进制转十六进制
-
第4组(2个)
-
ord,获取字符对应的unicode码点(十进制)
v1 = ord("武") print(v1, hex(v1)) -
chr,根据码点(十进制)获取对应字符
v1 = chr(27494) print(v1)
-
-
第5组(9个)
-
int
-
foat
-
str,unicode编码
-
bytes,utf-8、gbk编码
v1 = "武沛齐" # str类型 v2 = v1.encode('utf-8') # bytes类型 v3 = bytes(v1,encoding="utf-8") # bytes类型 -
bool
-
list
-
dict
-
tuple
-
set
-
-
第6组(13个)
-
len
-
print
-
input
-
open
-
type,获取数据类型
v1 = "123" if type(v1) == str: pass else: pass -
range
range(10) -
enumerate
v1 = ["武沛齐", "alex", 'root'] for num, value in enumerate(v1, 1): print(num, value) -
id
-
hash
v1 = hash("武沛齐") -
help,帮助信息
- pycharm,不用
- 终端,使用
-
zip
v1 = [11, 22, 33, 44, 55, 66] v2 = [55, 66, 77, 88] v3 = [10, 20, 30, 40, 50] result = zip(v1, v2, v3) for item in result: print(item) -
callable,是否可执行,后面是否可以加括号。
v1 = "武沛齐" v2 = lambda x: x def v3(): pass print( callable(v1) ) # False print(callable(v2)) print(callable(v3)) -
sorted,排序
v1 = sorted([11,22,33,44,55])info = { "wupeiqi": { 'id': 10, 'age': 119 }, "root": { 'id': 20, 'age': 29 }, "seven": { 'id': 9, 'age': 9 }, "admin": { 'id': 11, 'age': 139 }, } result = sorted(info.items(), key=lambda x: x[1]['id']) print(result)data_list = [ '1-5 编译器和解释器.mp4', '1-17 今日作业.mp4', '1-9 Python解释器种类.mp4', '1-16 今日总结.mp4', '1-2 课堂笔记的创建.mp4', '1-15 Pycharm使用和破解(win系统).mp4', '1-12 python解释器的安装(mac系统).mp4', '1-13 python解释器的安装(win系统).mp4', '1-8 Python介绍.mp4', '1-7 编程语言的分类.mp4', '1-3 常见计算机基本概念.mp4', '1-14 Pycharm使用和破解(mac系统).mp4', '1-10 CPython解释器版本.mp4', '1-1 今日概要.mp4', '1-6 学习编程本质上的三件事.mp4', '1-18 作业答案和讲解.mp4', '1-4 编程语言.mp4', '1-11 环境搭建说明.mp4' ] result = sorted(data_list, key=lambda x: int(x.split(' ')[0].split("-")[-1]) ) print(result)
-
4.推导式
推导式是Python中提供了一个非常方便的功能,可以让我们通过一行代码实现创建list、dict、tuple、set 的同时初始化一些值。
请创建一个列表,并在列表中初始化:0、1、2、3、4、5、6、7、8、9...299 整数元素。
data = []
for i in range(300):
data.append(i)
-
列表
num_list = [ i for i in range(10)] num_list = [ [i,i] for i in range(10)] num_list = [ [i,i] for i in range(10) if i > 6 ] -
集合
num_set = { i for i in range(10)} num_set = { (i,i,i) for i in range(10)} num_set = { (i,i,i) for i in range(10) if i>3} -
字典
num_dict = { i:i for i in range(10)} num_dict = { i:(i,11) for i in range(10)} num_dict = { i:(i,11) for i in range(10) if i>7} -
元组,不同于其他类型。
# 不会立即执行内部循环去生成数据,而是得到一个生成器。 data = (i for i in range(10)) print(data) for item in data: print(item)
练习题
-
去除列表中每个元素的
.mp4后缀。data_list = [ '1-5 编译器和解释器.mp4', '1-17 今日作业.mp4', '1-9 Python解释器种类.mp4', '1-16 今日总结.mp4', '1-2 课堂笔记的创建.mp4', '1-15 Pycharm使用和破解(win系统).mp4', '1-12 python解释器的安装(mac系统).mp4', '1-13 python解释器的安装(win系统).mp4', '1-8 Python介绍.mp4', '1-7 编程语言的分类.mp4', '1-3 常见计算机基本概念.mp4', '1-14 Pycharm使用和破解(mac系统).mp4', '1-10 CPython解释器版本.mp4', '1-1 今日概要.mp4', '1-6 学习编程本质上的三件事.mp4', '1-18 作业答案和讲解.mp4', '1-4 编程语言.mp4', '1-11 环境搭建说明.mp4' ] result = [] for item in data_list: result.append(item.rsplit('.',1)[0]) result = [ item.rsplit('.',1)[0] for item in data_list] -
将字典中的元素按照
键-值格式化,并最终使用;连接起来。info = { "name":"武沛齐", "email":"xxx@live.com", "gender":"男", } data_list [] for k,v in info.items(): temp = "{}-{}".format(k,v) temp.append(data_list) resutl = ";".join(data) result = ";".join( [ "{}-{}".format(k,v) for k,v in info.items()] ) -
将字典按照键从小到大排序,然后在按照如下格式拼接起来。(微信支付API内部处理需求)
info = { 'sign_type': "MD5", 'out_refund_no': "12323", 'appid': 'wx55cca0b94f723dc7', 'mch_id': '1526049051', 'out_trade_no': "ffff", 'nonce_str': "sdfdffd", 'total_fee': 9901, 'refund_fee': 10000 } data = "&".join(["{}={}".format(key, value) for key, value in sorted(info.items(), key=lambda x: x[0])]) print(data) -
看代码写结果
def func(): print(123) data_list = [func for i in range(10)] print(data_list) -
看代码写结果
def func(num): return num + 100 data_list = [func(i) for i in range(10)] print(data_list) -
看代码写结果(执行出错,通过他可以让你更好的理解执行过程)
def func(x): return x + i data_list = [func for i in range(10)] val = data_list[0](100) print(val) -
看代码写结果(新浪微博面试题)
data_list = [lambda x: x + i for i in range(10)] # [函数,函数,函数] i=9 v1 = data_list[0](100) v2 = data_list[3](100) print(v1, v2) # 109 109
小高级
-
推导式支持嵌套
data = [ i for i in range(10)]data = [ (i,j) for j in range(5) for i in range(10)] data = [] for i in range(10): for j in range(5): data.append( (i,j) ) data = [ [i, j] for j in range(5) for i in range(10)]# 一副扑克牌 poker_list = [ (color,num) for num in range(1,14) for color in ["红桃", "黑桃", "方片", "梅花"]] poker_list = [ [color, num] for num in range(1, 14) for color in ["红桃", "黑桃", "方片", "梅花"]] print(poker_list) -
烧脑面试题
def num(): return [lambda x: i * x for i in range(4)] # 1. num()并获取返回值 [函数,函数,函数,函数] i=3 # 2. for循环返回值 # 3. 返回值的每个元素(2) result = [m(2) for m in num()] # [6,6,6,6] print(result)def num(): return (lambda x: i * x for i in range(4)) # 1. num()并获取返回值 生成器对象 # 2. for循环返回值 # 3. 返回值的每个元素(2) # **********************元祖推导式得到的是一个生成器************************ result = [m(2) for m in num()] # [0,2,4,6 ] print(result)
总结
- 匿名函数,基于lambda表达式实现一行创建一个函数。一般用于编写简单的函数。
- 三元运算,用一行代码实现处理简单的条件判断和赋值。
- 生成器,函数中如果yield关键字
- 生成器函数
- 生成器对象
- 执行生成器函数中的代码
- next
- for(常用)
- send
- 内置函数(36个)
- 推导式
- 常规操作
- 小高级操作
作业
-
看代码写结果
v = [ lambda :x for x in range(10)] print(v) print(v[0]) print(v[0]()) -
看代码写结果
v = [i for i in range(10,0,-1) if i > 5] print(v) -
看代码写结果
data = [lambda x:x*i for i in range(10)] print(data) print(data[0](2)) print(data[0](2) == data[8](2)) -
请用列表推导式实现,踢出列表中的字符串,最终生成一个新的列表保存。
data_list = [11,22,33,"alex",455,'eirc'] new_data_list = [ ... ] # 请在[]中补充代码实现。 # 提示:可以用type判断类型 -
请用列表推导式实现,对data_list中的每个元素判断,如果是字符串类型,则计算长度作为元素放在新列表的元素中;如果是整型,则让其值+100 作为元素放在新的列表的元素中。
data_list = [11,22,33,"alex",455,'eirc'] new_data_list = [ ... ] # 请在[]中补充代码实现。 # 提示:可以基于三元运算实现 -
请使用字典推导式实现,将如果列表构造成指定格式字典.
data_list = [ (1,'alex',19), (2,'老男',84), (3,'老女',73) ] # 请使用推导式将data_list构造生如下格式: """ info_dict = { 1:(1,'alex',19), 2:(2,'老男',84), 3:(3,'老女',73) } """ -
有4个人玩扑克牌比大小,请对比字典中每个人的牌的大小,并输入优胜者的姓名(值大的胜利,不必考虑A)。
player = { "武沛齐":["红桃",10], "alex":["红桃",8], 'eric':["黑桃",3], 'killy':["梅花",12], } -
尽量多的列举你记得的内置函数?【能记住多少就写多少,不强制去背,在此尽权利写即可,这种公共后续用的多了就自然而然就记住了】
-
请编写一个生成器函数实现生成n个斐波那契数列的值。
-
什么是斐波那契数列?
前两个数相加的结果,就是下一个数。 1 1 2 3 5 8 13 21 34 55 ... -
代码结构示例,请在此基础上补充代码实现。
def fib(max_count): pass count = input("请输入要生成斐波那契数列的个数:") count = int(count) fib_generator = fib(count) for num in fib_generator: print(num)
-
作业答案
# 第4题
data_list = [11, 22, 33, "alex", 455, 'eirc']
new_data_list = [item for item in data_list if type(item) == int] # 请在[]中补充代码实现。
print(new_data_list)
# 第5题
data_list = [11, 22, 33, "alex", 455, 'eirc']
new_data_list = [len(item) if type(item) == str else item + 100 for item in data_list]
print(new_data_list)
# 第6题
data_list = [
(1, 'alex', 19),
(2, '老男', 84),
(3, '老女', 73)
]
info_dict = {item[0]: item for item in data_list}
print(info_dict)
# 第7题
player = {
"武沛齐": ["红桃", 10],
"alex": ["红桃", 8],
'eric': ["黑桃", 3],
'killy': ["梅花", 12],
}
winner = sorted(player.items(), key=lambda x: x[1][-1], reverse=True)[0][0]
print(winner)
data = sorted(player.items(), key=lambda x: x[1][1])[-1][0]
print(data)
# 第9题
def fib(max_count):
first = 1
second = 0
count = 0
while count < max_count:
next_value = first + second
first = second
second = next_value
yield next_value
count += 1
limit_count = input("请输入要生成斐波那契数列的个数:")
limit_count = int(limit_count)
fib_generator = fib(limit_count)
for num in fib_generator:
print(num)
day14 模块
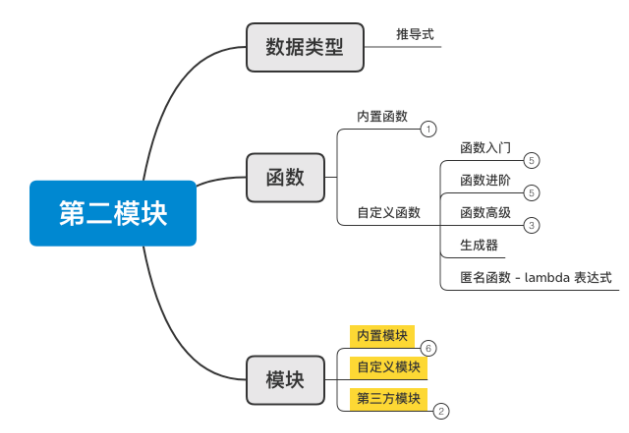
课程目标:掌握Python中常用模块的使用方法。
今日概要:
- 自定义模块(包)
- 第三方模块
- 内置模块【1/2】
1. 自定义模块
1.1 模块和包
import hashlib
def encrypt(data):
""" 数据加密 """
hash_object = hashlib.md5()
hash_object.update(data.encode('utf-8'))
return hash_object.hexdigest()
user = input("请输入用户名:")
pwd = input("请输入密码:")
md5_password = encrypt(pwd)
message = "用户名:{},密码:{}".format(user, md5_password)
print(message)
在开发简单的程序时,使用一个py文件就可以搞定,如果程序比较庞大,需要些10w行代码,此时为了,代码结构清晰,将功能按照某种规则拆分到不同的py文件中,使用时再去导入即可。另外,当其他项目也需要此项目的某些模块时,也可以直接把模块拿过去使用,增加重用性。
如果按照某个规则进行拆分,发现拆分到 commons.py 中函数太多,也可以通过文件夹来进行再次拆分,例如:
├── commons
│ ├── convert.py
│ ├── page.py
│ └── utils.py
└── run.py
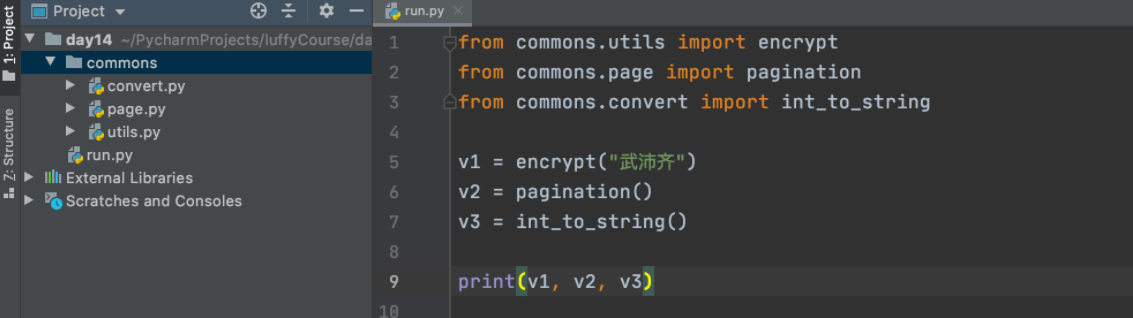
在Python中一般对文件和文件的称呼(很多开发者的平时开发中也有人都称为模块)
- 一个py文件,模块(module)。
- 含多个py文件的文件夹,包(package)。
注意:在包(文件夹)中有一个默认内容为空的__init__.py的文件,一般用于描述当前包的信息(在导入他下面的模块时,也会自动加载)。
- py2必须有,如果没有导入包就会失败。
- py3可有可无。
1.2 导入
当定义好一个模块或包之后,如果想要使用其中定义的功能,必须要先导入,然后再能使用。
导入,其实就是将模块或包加载的内存中,以后再去内存中去拿就行。
关于导如时的路径:
在Python内部默认设置了一些路径,导入模块或包时,都会按照指定顺序逐一去特定的路径查找。
import sys
print(sys.path)
[
'当前执行脚本所在的目录', /Users/wupeiqi/PycharmProjects/luffyCourse/day14/bin
/Users/wupeiqi/PycharmProjects/luffyCourse/day14
'/Applications/PyCharm.app/Contents/plugins/python/helpers/pycharm_display',
'/Library/Frameworks/Python.framework/Versions/3.9/lib/python39.zip',
'/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9',
'/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/lib-dynload',
'/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages',
'/Applications/PyCharm.app/Contents/plugins/python/helpers/pycharm_matplotlib_backend'
]
想要导入任意的模块和包,都必须写在如下路径下,才能被找到。
也可以自动手动在sys.path中添加指定路径,然后再导入可以,例如:
import sys
sys.path.append("路径A")
import xxxxx # 导入路径A下的一个xxxxx.py文件
-
你以后写模块名称时,千万不能和内置和第三方的同名(新手容易犯错误)。
-
项目执行文件一般都在项目根目录,如果执行文件嵌套的内存目录,就需要自己手动在sys.path中添加路径。
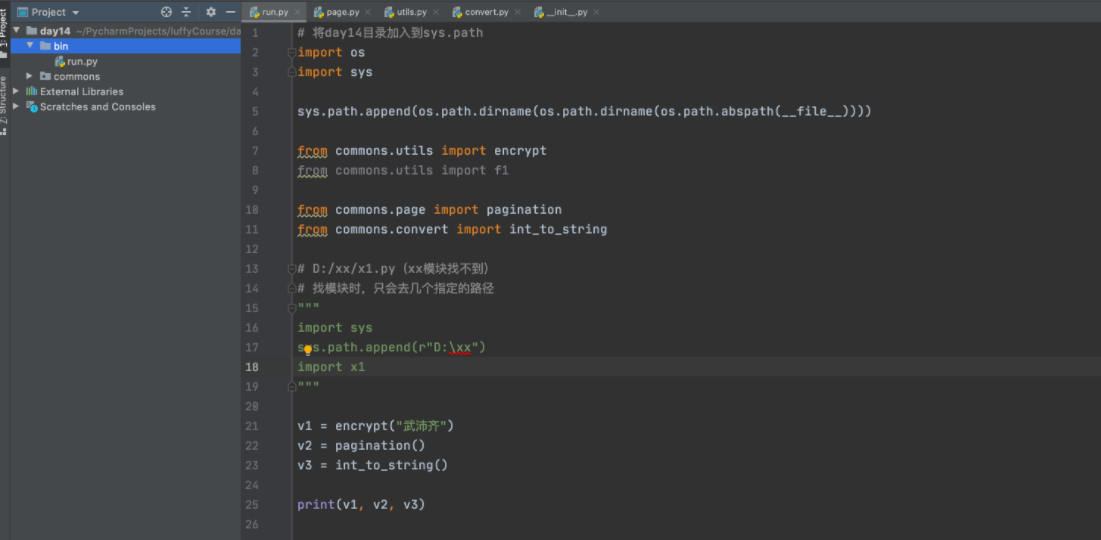
-
pycharm中默认会将项目目录加入到sys.path中
关于导入的方式:
导入本质上是将某个文件中的内容先加载到内存中,然后再去内存中拿过来使用。而在Python开发中常用的导入的方式有2类方式,每类方式都也多种情况。
-
第一类:import xxxx(开发中,一般多用于导入sys.path目录下的一个py文件)
-
模块级别
├── commons │ ├── __init__.py │ ├── convert.py │ ├── page.py │ ├── tencent │ │ ├── __init__.py │ │ ├── sms.py │ │ └── wechat.py │ └── utils.py ├── many.py └── run.py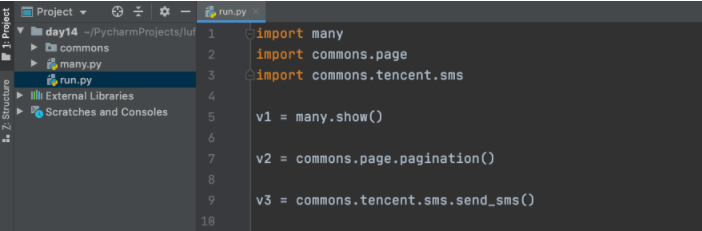
-
包级别
├── commons │ ├── __init__.py │ ├── convert.py │ ├── page.py │ └── utils.py ├── third │ ├── __init__.py │ ├── ali │ │ └── oss.py │ └── tencent │ ├── __init__.py │ ├── __pycache__ │ ├── sms.py │ └── wechat.py └── run.py
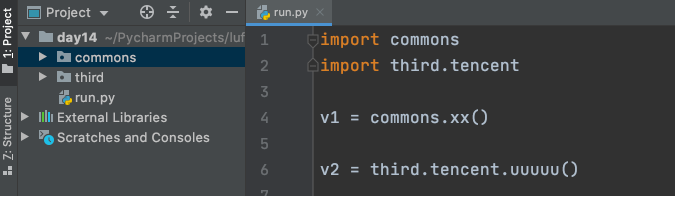
-
-
第二类:from xxx import xxx 【常用】,一般适用于多层嵌套和导入模块中某个成员的情况。
-
成员级别
├── commons │ ├── __init__.py │ ├── convert.py │ ├── page.py │ └── utils.py ├── many.py └── run.py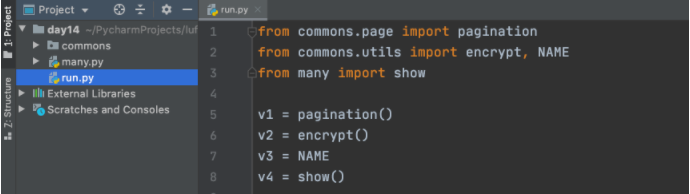
提示:基于from模式也可以支持
from many import *,即:导入一个模块中所有的成员(可能会重名,所以用的少)。 -
模块级别
├── commons │ ├── __init__.py │ ├── convert.py │ ├── page.py │ └── utils.py ├── many.py └── run.py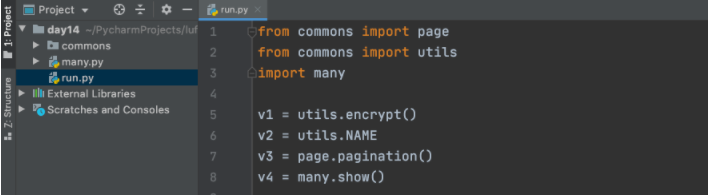
-
包级别
├── commons │ ├── __init__.py │ ├── convert.py │ ├── page.py │ ├── tencent │ │ ├── __init__.py │ │ ├── sms.py │ │ └── wechat.py │ └── utils.py ├── many.py └── run.py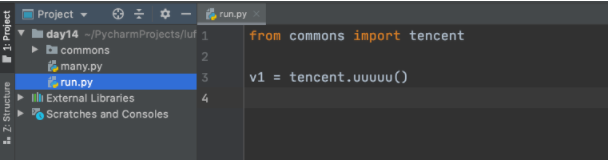
-
1.3 相对导入
在导入模块时,对于 from xx import xx这种模式,还支持相对到导入。例如:
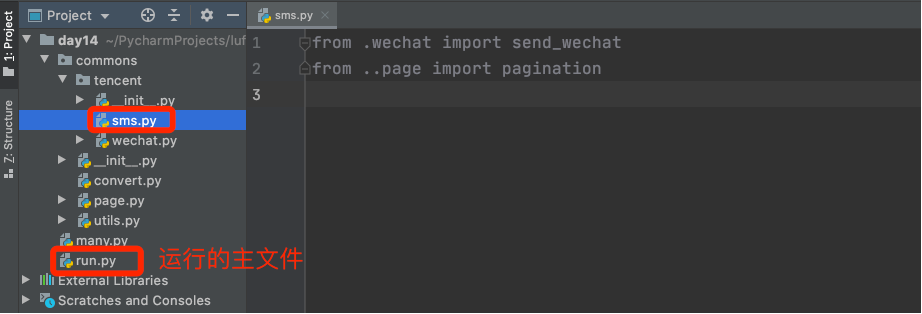
切记,相对导入只能用在包中的py文件中(即:嵌套在文件中的py文件才可以使用,项目根目录下无法使用)。
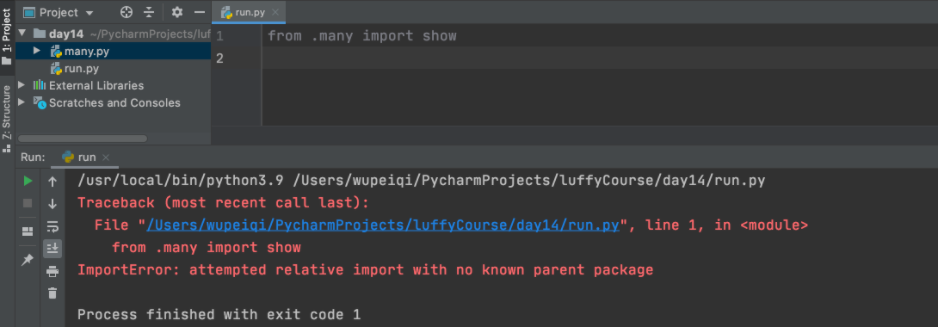
1.4 导入别名
如果项目中导入 成员/模块/包 有重名,那么后导入的会覆盖之前导入,为了避免这种情况的发生,Python支持重命名,即:
from xxx.xxx import xx as xo
import x1.x2 as pg
除此之外,有了as的存在,让 import xx.xxx.xxxx.xxx 在调用执行时,会更加简单(不常用,了解即可)。
-
原来
import commons.page v1 = commons.page.pagination() -
现在
import commons.page as pg v1 = pg.pagination()
1.5 主文件
-
执行一个py文件时
__name__ = "__main__" -
导入一个py文件时
__name__ = "模块名"
主文件,其实就是在程序执行的入口文件,例如:
├── commons
│ ├── __init__.py
│ ├── convert.py
│ ├── page.py
│ ├── tencent
│ │ ├── __init__.py
│ │ ├── sms.py
│ │ └── wechat.py
│ └── utils.py
├── many.py
└── run.py
我们通常是执行 run.py 去运行程序,其他的py文件都是一些功能代码。当我们去执行一个文件时,文件内部的 __name__变量的值为 __main__,所以,主文件经常会看到:
import many
from commons import page
from commons import utils
def start():
v1 = many.show()
v2 = page.pagination()
v3 = utils.encrypt()
if __name__ == '__main__':
start()
只有是以主文件的形式运行此脚本时start函数才会执行,被导入时则不会被执行。
小结
-
模块和包的区别
-
导入模块的两种方式:
import xx from xxx import xxx -
相对导入,需要有包名称。
-
模块重名可以通过as取别名。
-
执行py文件时,内部
__name__=="__main__",导入模块时,被导入的模块__name__="模块名" -
在项目开发中,一般在主文件中会写上 main (主文件标记,不是绝对的,因为其他文件在开发调试时候有时候也可能有main)。
2. 第三方模块
Python内部提供的模块有限,所以在平时在开发的过程中,经常会使用第三方模块。
而第三方模块必须要先安装才能可以使用,下面介绍常见的3中安装第三方模块的方式。
其实,使用第三方模块的行为就是去用别人写好并开源出来的py代码,这样自己拿来就用,不必重复造轮子了。。。。
2.1 pip(最常用)
这是Python中最最最常用的安装第三方模块的方式。
pip其实是一个第三方模块包管理工具,默认安装Python解释器时自动会安装,默认目录:
MAC系统,即:Python安装路径的bin目录下
/Library/Frameworks/Python.framework/Versions/3.9/bin/pip3
/Library/Frameworks/Python.framework/Versions/3.9/bin/pip3.9
Windows系统,即:Python安装路径的scripts目录下
C:\Python39\Scripts\pip3.exe
C:\Python39\Scripts\pip3.9.exe
提示:为了方便在终端运行pip管理工具,我们也会把它所在的路径添加到系统环境变量中。
pip3 install 模块名称
如果你的电脑上某个写情况没有找到pip,也可以自己手动安装:
-
下载
get-pip.py文件,到任意目录地址:https://bootstrap.pypa.io/get-pip.py -
打开终端进入目录,用Python解释器去运行已下载的
get-pip.py文件即刻安装成功。

使用pip去安装第三方模块也非常简单,只需要在自己终端执行:pip install 模块名称 即可。


默认安装的是最新的版本,如果想要指定版本:
pip3 install 模块名称==版本
例如:
pip3 install django==2.2
2.1.1 pip更新
上图的黄色字体提示:目前我电脑上的pip是20.2.3版本,最新的是 20.3.3 版本,如果想要升级为最新的版本,可以在终端执行他提示的命令:
/Library/Frameworks/Python.framework/Versions/3.9/bin/python3.9 -m pip install --upgrade pip
注意:根据自己电脑的提示命令去执行,不要用我这里的提示命令哈。
2.1.2 豆瓣源
pip默认是去 https://pypi.org 去下载第三方模块(本质上就是别人写好的py代码),国外的网站速度会比较慢,为了加速可以使用国内的豆瓣源。
-
一次性使用
pip3.9 install 模块名称 -i https://pypi.douban.com/simple/ -
永久使用
-
配置
# 在终端执行如下命令 pip3.9 config set global.index-url https://pypi.douban.com/simple/ # 执行完成后,提示在我的本地文件中写入了豆瓣源,以后再通过pip去安装第三方模块时,就会默认使用豆瓣源了。 # 自己以后也可以打开文件直接修改源地址。 Writing to /Users/wupeiqi/.config/pip/pip.conf -
使用
pip3.9 install 模块名称
-
写在最后,也还有其他的源可供选择(豆瓣应用广泛)。
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学:http://pypi.mirrors.ustc.edu.cn/simple/
2.2 源码
如果要安装的模块在pypi.org中不存在 或 因特殊原因无法通过pip install 安装时,可以直接下载源码,然后基于源码安装,例如:
-
下载requests源码(压缩包zip、tar、tar.gz)并解压。
下载地址:https://pypi.org/project/requests/#files -
进入目录
-
执行编译和安装命令
python3 setup.py build python3 setup.py install

2.3 wheel
wheel是Python的第三方模块包的文件格式的一种,我们也可以基于wheel去安装一些第三方模块。
-
安装wheel格式支持,这样pip再安装第三方模块时,就可以处理wheel格式的文件了。
pip3.9 install wheel -
下载第三方的包(wheel格式),例如:https://pypi.org/project/requests/#files
-
进入下载目录,在终端基于pip直接安装
无论通过什么形式去安装第三方模块,默认模块的安装路径在:
Max系统:
/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages
Windows系统:
C:\Python39\Lib\site-packages\
提醒:这个目录在sys.path中,所以我们直接在代码中直接导入下载的第三方包是没问题的。
3.内置模块(一)
Python内置的模块有很多,我们也已经接触了不少相关模块,接下来咱们就来做一些汇总和介绍。
内置模块有很多 & 模块中的功能也非常多,我们是没有办法注意全局给大家讲解,在此我会整理出项目开发最常用的来进行讲解。
3.1 os
import os
# 1. 获取当前脚本绝对路径
"""
abs_path = os.path.abspath(__file__)
print(abs_path)
"""
# 2. 获取当前文件的上级目录
"""
base_path = os.path.dirname( os.path.dirname(路径) )
print(base_path)
"""
# 3. 路径拼接
"""
p1 = os.path.join(base_path, 'xx')
print(p1)
p2 = os.path.join(base_path, 'xx', 'oo', 'a1.png')
print(p2)
"""
# 4. 判断路径是否存在
"""
exists = os.path.exists(p1)
print(exists)
"""
# 5. 创建文件夹
"""
os.makedirs(路径)
"""
"""
path = os.path.join(base_path, 'xx', 'oo', 'uuuu')
if not os.path.exists(path):
os.makedirs(path)
"""
# 6. 是否是文件夹
"""
file_path = os.path.join(base_path, 'xx', 'oo', 'uuuu.png')
is_dir = os.path.isdir(file_path)
print(is_dir) # False
folder_path = os.path.join(base_path, 'xx', 'oo', 'uuuu')
is_dir = os.path.isdir(folder_path)
print(is_dir) # True
"""
# 7. 删除文件或文件夹
"""
os.remove("文件路径")
"""
"""
path = os.path.join(base_path, 'xx')
shutil.rmtree(path)
"""
- listdir,查看目录下所有的文件
- walk,查看目录下所有的文件(含子孙文件)
import os
"""
data = os.listdir("/Users/wupeiqi/PycharmProjects/luffyCourse/day14/commons")
print(data)
# ['convert.py', '__init__.py', 'page.py', '__pycache__', 'utils.py', 'tencent']
"""
"""
要遍历一个文件夹下的所有文件,例如:遍历文件夹下的所有mp4文件
"""
data = os.walk("/Users/wupeiqi/Documents/视频教程/路飞Python/mp4")
for path, folder_list, file_list in data:
for file_name in file_list:
file_abs_path = os.path.join(path, file_name)
ext = file_abs_path.rsplit(".",1)[-1]
if ext == "mp4":
print(file_abs_path)
3.2 shutil
import shutil
# 1. 删除文件夹
"""
path = os.path.join(base_path, 'xx')
shutil.rmtree(path)
"""
# 2. 拷贝文件夹
"""
shutil.copytree("/Users/wupeiqi/Desktop/图/csdn/","/Users/wupeiqi/PycharmProjects/CodeRepository/files")
"""
# 3.拷贝文件
"""
shutil.copy("/Users/wupeiqi/Desktop/图/csdn/WX20201123-112406@2x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/")
shutil.copy("/Users/wupeiqi/Desktop/图/csdn/WX20201123-112406@2x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/x.png")
"""
# 4.文件或文件夹重命名
"""
shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/xxxx.png")
shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/files","/Users/wupeiqi/PycharmProjects/CodeRepository/images")
"""
# 5. 压缩文件
"""
# base_name,压缩后的压缩包文件
# format,压缩的格式,例如:"zip", "tar", "gztar", "bztar", or "xztar".
# root_dir,要压缩的文件夹路径
"""
# shutil.make_archive(base_name=r'datafile',format='zip',root_dir=r'files')
# 6. 解压文件
"""
# filename,要解压的压缩包文件
# extract_dir,解压的路径
# format,压缩文件格式
"""
# shutil.unpack_archive(filename=r'datafile.zip', extract_dir=r'xxxxxx/xo', format='zip')
3.3 sys
import sys
# 1. 获取解释器版本
"""
print(sys.version)
print(sys.version_info)
print(sys.version_info.major, sys.version_info.minor, sys.version_info.micro)
"""
# 2. 导入模块路径
"""
print(sys.path)
"""
- argv,执行脚本时,python解释器后面传入的参数
import sys
print(sys.argv)
# [
# '/Users/wupeiqi/PycharmProjects/luffyCourse/day14/2.接受执行脚本的参数.py'
# ]
# [
# "2.接受执行脚本的参数.py"
# ]
# ['2.接受执行脚本的参数.py', '127', '999', '666', 'wupeiqi']
# 例如,请实现下载图片的一个工具。
def download_image(url):
print("下载图片", url)
def run():
# 接受用户传入的参数
url_list = sys.argv[1:]
for url in url_list:
download_image(url)
if __name__ == '__main__':
run()
3.4 random
import random
# 1. 获取范围内的随机整数
v = random.randint(10, 20)
print(v)
# 2. 获取范围内的随机小数
v = random.uniform(1, 10)
print(v)
# 3. 随机抽取一个元素
v = random.choice([11, 22, 33, 44, 55])
print(v)
# 4. 随机抽取多个元素
v = random.sample([11, 22, 33, 44, 55], 3)
print(v)
# 5. 打乱顺序
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
random.shuffle(data)
print(data)
3.5 hashlib
import hashlib
hash_object = hashlib.md5()
hash_object.update("武沛齐".encode('utf-8'))
result = hash_object.hexdigest()
print(result)
import hashlib
# 通过加盐的方式让数据产生2层加密
hash_object = hashlib.md5("iajfsdunjaksdjfasdfasdf".encode('utf-8'))
hash_object.update("武沛齐".encode('utf-8'))
result = hash_object.hexdigest()
print(result)
3.6 configparser
见:day09
3.7 xml
见:day09
总结
-
模块和包的区别
-
了解如何导入模块
- 路径
- 导入方式
-
导入模块时一般要遵循的规范【补充】
-
注释:文件顶部或init文件中。
-
在文件顶部导入
-
有规则导入,并用空行分割。
# 先内置模块 # 再第三方模块 # 最后自定义模块import os import sys import random import hashlib import requests import openpyxl from commons.utils import encrypt
-
-
第三方模块安装的方法
-
常见内置模块
作业
- 自己去网上搜索如何基于Python计算mp4视频的时长,最终实现用代码统计某个文件夹下所有mp4的时长。
作业答案
#pip install moviepy
import os
from moviepy.editor import VideoFileClip
def get_mp4_hour(folder_path):
# 1.遍历目录下的所有mp4
total_seconds = 0
data = os.walk(folder_path)
for path, folder_list, file_list in data:
for file_name in file_list:
file_abs_path = os.path.join(path, file_name)
ext = file_abs_path.rsplit(".", 1)[-1]
if ext == "mp4":
clip = VideoFileClip(file_abs_path)
total_seconds += clip.duration
hour = round(total_seconds / 60 / 60, 2)
return hour
if __name__ == '__main__':
res = get_mp4_hour("/Users/wupeiqi/Documents/视频教程/路飞Python/mp4/day03")
print(res)
day15 内置模块和开发规范
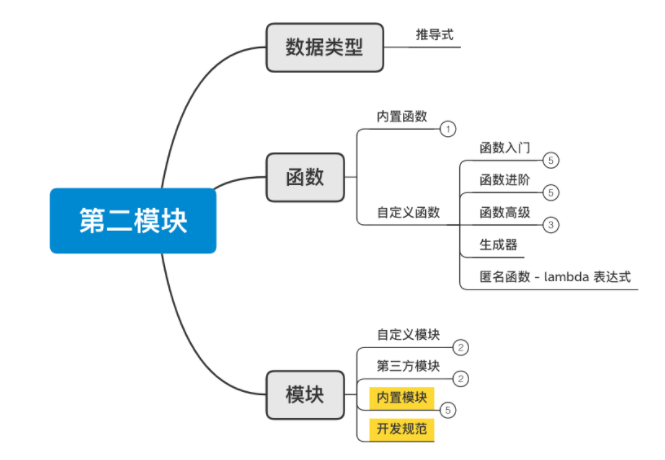
目标:掌握常见的内置模块的使用及了解软件开发的规范。
今日概要:
- 内置模块
- json
- time
- datetime
- re
- 开发规范
- 主文件
- 配置文件
- 数据
- 附件
- 业务代码
1. 内置模块
1.1 json
json模块,是python内部的一个模块,可以将python的数据格式 转换为json格式的数据,也可以将json格式的数据转换为python的数据格式。
json格式,是一个数据格式(本质上就是个字符串,常用语网络数据传输)
# Python中的数据类型的格式
data = [
{"id": 1, "name": "武沛齐", "age": 18},
{"id": 2, "name": "alex", "age": 18},
('wupeiqi',123),
]
# JSON格式
value = '[{"id": 1, "name": "武沛齐", "age": 18}, {"id": 2, "name": "alex", "age": 18},["wupeiqi",123]]'
1.1.1 核心功能
json格式的作用?
跨语言数据传输,例如:
A系统用Python开发,有列表类型和字典类型等。
B系统用Java开发,有数组、map等的类型。
语言不同,基础数据类型格式都不同。
为了方便数据传输,大家约定一个格式:json格式,每种语言都是将自己数据类型转换为json格式,也可以将json格式的数据转换为自己的数据类型。
Python数据类型与json格式的相互转换:
-
数据类型 -> json ,一般称为:序列化
import json data = [ {"id": 1, "name": "武沛齐", "age": 18}, {"id": 2, "name": "alex", "age": 18}, ] res = json.dumps(data) # 中文序列化会变成bytes print(res) # '[{"id": 1, "name": "\u6b66\u6c9b\u9f50", "age": 18}, {"id": 2, "name": "alex", "age": 18}]' res = json.dumps(data, ensure_ascii=False) print(res) # '[{"id": 1, "name": "武沛齐", "age": 18}, {"id": 2, "name": "alex", "age": 18}]' -
json格式 -> 数据类型,一般称为:反序列化
import json data_string = '[{"id": 1, "name": "武沛齐", "age": 18}, {"id": 2, "name": "alex", "age": 18}]' data_list = json.loads(data_string) print(data_list)
练习题
-
写网站,给用户返回json格式数据
-
安装flask模块,协助我们快速写网站(之前已安装过)
pip3 install flask -
使用flask写网站
import json from flask import Flask app = Flask(__name__) def index(): return "首页" def users(): data = [ {"id": 1, "name": "武沛齐", "age": 18}, {"id": 2, "name": "alex", "age": 18}, ] return json.dumps(data) app.add_url_rule('/index/', view_func=index, endpoint='index') app.add_url_rule('/users/', view_func=users, endpoint='users') if __name__ == '__main__': app.run()
-
-
发送网络请求,获取json格式数据并处理。
import json import requests url = "https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=5&page_start=20" res = requests.get( url=url, headers={ "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36" } ) # json格式 print(res.text) # json格式转换为python数据类型 data_dict = json.loads(res.text) print(data_dict)
1.1.2 类型要求
python的数据类型转换为 json 格式,对数据类型是有要求的,默认只支持:
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
data = [
{"id": 1, "name": "武沛齐", "age": 18},
{"id": 2, "name": "alex", "age": 18},
]
其他类型如果想要支持,需要自定义JSONEncoder 才能实现【目前只需要了解大概意思即可,以后项目开发中用到了还会讲解。】,例如:
import json
from decimal import Decimal
from datetime import datetime
data = [
{"id": 1, "name": "武沛齐", "age": 18, 'size': Decimal("18.99"), 'ctime': datetime.now()},
{"id": 2, "name": "alex", "age": 18, 'size': Decimal("9.99"), 'ctime': datetime.now()},
]
class MyJSONEncoder(json.JSONEncoder):
def default(self, o):
if type(o) == Decimal:
return str(o)
elif type(o) == datetime:
return o.strftime("%Y-%M-%d")
return super().default(o)
res = json.dumps(data, cls=MyJSONEncoder)
print(res)
1.1.3 其他功能
json模块中常用的是:
-
json.dumps,序列化生成一个字符串。 -
json.loads,发序列化生成python数据类型。 -
json.dump,将数据序列化并写入文件(不常用)import json data = [ {"id": 1, "name": "武沛齐", "age": 18}, {"id": 2, "name": "alex", "age": 18}, ] file_object = open('xxx.json', mode='w', encoding='utf-8') json.dump(data, file_object) file_object.close() -
json.load,读取文件中的数据并反序列化为python的数据类型(不常用)import json file_object = open('xxx.json', mode='r', encoding='utf-8') data = json.load(file_object) print(data) file_object.close()
1.2 时间处理
-
UTC/GMT:世界时间
-
本地时间:本地时区的时间。
Python中关于时间处理的模块有两个,分别是time和datetime。
1.2.1 time
import time
# 获取当前时间戳(自1970-1-1 00:00)
v1 = time.time()
print(v1)
# 时区
v2 = time.timezone
# 停止n秒,再执行后续的代码。
time.sleep(5)
1.2.2 datetime
在平时开发过程中的时间一般是以为如下三种格式存在:
-
datetime
from datetime import datetime, timezone, timedelta v1 = datetime.now() # 当前本地时间 print(v1) tz = timezone(timedelta(hours=7)) # 当前东7区时间 v2 = datetime.now(tz) print(v2) v3 = datetime.utcnow() # 当前UTC时间 print(v3)from datetime import datetime, timedelta v1 = datetime.now() print(v1) # 时间的加减 v2 = v1 + timedelta(days=140, minutes=5) print(v2) # datetime类型 + timedelta类型from datetime import datetime, timezone, timedelta v1 = datetime.now() print(v1) v2 = datetime.utcnow() # 当前UTC时间 print(v2) # datetime之间相减,计算间隔时间(不能相加) data = v1 - v2 print(data.days, data.seconds / 60 / 60, data.microseconds) # datetime类型 - datetime类型 # datetime类型 比较 datetime类型 -
字符串
# 字符串格式的时间 ---> 转换为datetime格式时间 text = "2021-11-11" v1 = datetime.strptime(text,'%Y-%m-%d') # %Y 年,%m,月份,%d,天。 print(v1)# datetime格式 ----> 转换为字符串格式 v1 = datetime.now() val = v1.strftime("%Y-%m-%d %H:%M:%S") print(val) -
时间戳
# 时间戳格式 --> 转换为datetime格式 ctime = time.time() # 11213245345.123 v1 = datetime.fromtimestamp(ctime) print(v1)# datetime格式 ---> 转换为时间戳格式 v1 = datetime.now() val = v1.timestamp() print(val)
练习题
-
日志记录,将用户输入的信息写入到文件,文件名格式为
年-月-日-时-分.txt。from datetime import datetime while True: text = input("请输入内容:") if text.upper() == "Q": break current_datetime = datetime.now().strftime("%Y-%m-%d-%H-%M") file_name = "{}.txt".format(current_datetime) with open(file_name, mode='a', encoding='utf-8') as file_object: file_object.write(text) file_object.flush() -
用户注册,将用户信息写入Excel,其中包含:用户名、密码、注册时间 三列。
import os import hashlib from datetime import datetime from openpyxl import load_workbook from openpyxl import workbook BASE_DIR = os.path.dirname(os.path.abspath(__file__)) FILE_NAME = "db.xlsx" def md5(origin): hash_object = hashlib.md5("sdfsdfsdfsd23sd".encode('utf-8')) hash_object.update(origin.encode('utf-8')) return hash_object.hexdigest() def register(username, password): db_file_path = os.path.join(BASE_DIR, FILE_NAME) if os.path.exists(db_file_path): wb = load_workbook(db_file_path) sheet = wb.worksheets[0] next_row_position = sheet.max_row + 1 else: wb = workbook.Workbook() sheet = wb.worksheets[0] next_row_position = 1 user = sheet.cell(next_row_position, 1) user.value = username pwd = sheet.cell(next_row_position, 2) pwd.value = md5(password) ctime = sheet.cell(next_row_position, 3) ctime.value = datetime.now().strftime("%Y-%m-%d %H:%M:%S") wb.save(db_file_path) def run(): while True: username = input("请输入用户名:") if username.upper() == "Q": break password = input("请输入密码:") register(username, password) if __name__ == '__main__': run()
1.3 正则表达式相关
当给你一大堆文本信息,让你提取其中的指定数据时,可以使用正则来实现。例如:提取文本中的邮箱和手机号
import re
text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀"
phone_list = re.findall("1[3|5|8|9]\d{9}", text)
print(phone_list)
1.3.1 正则表达式
1. 字符相关
-
wupeiqi匹配文本中的wupeiqiimport re text = "你好wupeiqi,阿斯顿发wupeiqasd 阿士大夫能接受的wupeiqiff" data_list = re.findall("wupeiqi", text) print(data_list) # ['wupeiqi', 'wupeiqi'] 可用于计算字符串中某个字符出现的次数 -
[abc]匹配a或b或c 字符。import re text = "你2b好wupeiqi,阿斯顿发awupeiqasd 阿士大夫a能接受的wffbbupqaceiqiff" data_list = re.findall("[abc]", text) print(data_list) # ['b', 'a', 'a', 'a', 'b', 'b', 'c']import re text = "你2b好wupeiqi,阿斯顿发awupeiqasd 阿士大夫a能接受的wffbbupqcceiqiff" data_list = re.findall("q[abc]", text) print(data_list) # ['qa', 'qc'] -
[^abc]匹配除了abc意外的其他字符。import re text = "你wffbbupceiqiff" data_list = re.findall("[^abc]", text) print(data_list) # ['你', 'w', 'f', 'f', 'u', 'p', 'e', 'i', 'q', 'i', 'f', 'f'] -
[a-z]匹配a~z的任意字符( [0-9]也可以 )。import re text = "alexrootrootadmin" data_list = re.findall("t[a-z]", text) print(data_list) # ['tr', 'ta'] -
.代指除换行符以外的任意字符。import re text = "alexraotrootadmin" data_list = re.findall("r.o", text) print(data_list) # ['rao', 'roo']import re text = "alexraotrootadmin" data_list = re.findall("r.+o", text) # 贪婪匹配 print(data_list) # ['raotroo']import re text = "alexraotrootadmin" data_list = re.findall("r.+?o", text) # 非贪婪匹配 print(data_list) # ['rao'] -
\w代指字母或数字或下划线(汉字)(非特殊字符)。import re text = "北京武沛alex齐北 京武沛alex齐" data_list = re.findall("武\w+x", text) print(data_list) # ['武沛alex', '武沛alex'] -
\d代指数字import re text = "root-ad32min-add3-admd1in" data_list = re.findall("d\d", text) print(data_list) # ['d3', 'd3', 'd1']import re text = "root-ad32min-add3-admd1in" data_list = re.findall("d\d+", text) print(data_list) # ['d32', 'd3', 'd1'] -
\s代指任意的空白符,包括空格、制表符等。import re text = "root admin add admin" data_list = re.findall("a\w+\s\w+", text) print(data_list) # ['admin add']
2. 数量相关
-
*重复0次或更多次import re text = "他是大B个,确实是个大2B。" data_list = re.findall("大2*B", text) print(data_list) # ['大B', '大2B'] -
+重复1次或更多次import re text = "他是大B个,确实是个大2B,大3B,大66666B。" data_list = re.findall("大\d+B", text) print(data_list) # ['大2B', '大3B', '大66666B'] -
?重复0次或1次import re text = "他是大B个,确实是个大2B,大3B,大66666B。" data_list = re.findall("大\d?B", text) print(data_list) # ['大B', '大2B', '大3B'] -
{n}重复n次import re text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" data_list = re.findall("151312\d{5}", text) print(data_list) # ['15131255789'] -
{n,}重复n次或更多次import re text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" data_list = re.findall("\d{9,}", text) print(data_list) # ['442662578', '15131255789'] -
{n,m}重复n到m次import re text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" data_list = re.findall("\d{10,15}", text) print(data_list) # ['15131255789']
3. 括号(分组)
-
提取数据区域
import re text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" data_list = re.findall("15131(2\d{5})", text) print(data_list) # ['255789']import re text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来15131266666呀" data_list = re.findall("15(13)1(2\d{5})", text) print(data_list) # [ ('13', '255789') ]import re text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" data_list = re.findall("(15131(2\d{5}))", text) print(data_list) # [('15131255789', '255789')] -
获取指定区域 + 或条件
import re text = "楼主15131root太牛15131alex逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" data_list = re.findall("15131(2\d{5}|r\w+太)", text) print(data_list) # ['root太', '255789']import re text = "楼主15131root太牛15131alex逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" data_list = re.findall("(15131(2\d{5}|r\w+太))", text) print(data_list) # [('15131root太', 'root太'), ('15131255789', '255789')]练习题
-
利用正则匹配QQ号码
[1-9]\d{4,} -
身份证号码
import re text = "dsf130429191912015219k13042919591219521Xkk" data_list = re.findall("\d{17}[\dX]", text) # [abc] print(data_list) # ['130429191912015219', '13042919591219521X']import re text = "dsf130429191912015219k13042919591219521Xkk" data_list = re.findall("\d{17}(\d|X)", text) print(data_list) # ['9', 'X']import re text = "dsf130429191912015219k13042919591219521Xkk" data_list = re.findall("(\d{17}(\d|X))", text) print(data_list) # [('130429191912015219', '9'), ('13042919591219521X', 'X')]import re text = "dsf130429191912015219k13042919591219521Xkk" data_list = re.findall("(\d{6})(\d{4})(\d{2})(\d{2})(\d{3})([0-9]|X)", text) print(data_list) # [('130429', '1919', '12', '01', '521', '9'), ('130429', '1959', '12', '19', '521', 'X')] -
手机号
import re text = "我的手机哈是15133377892,你的手机号是1171123啊?" data_list = re.findall("1[3-9]\d{9}", text) print(data_list) # ['15133377892'] -
邮箱地址
import re text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" email_list = re.findall("\w+@\w+\.\w+",text) print(email_list) # ['442662578@qq.com和xxxxx']import re text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" email_list = re.findall("[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+\.[a-zA-Z0-9_-]+", text, re.ASCII) print(email_list) # ['442662578@qq.com', 'xxxxx@live.com']import re text = "楼主太牛逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" email_list = re.findall("\w+@\w+\.\w+", text, re.ASCII) print(email_list) # ['442662578@qq.com', 'xxxxx@live.com']import re text = "楼主太牛44266-2578@qq.com逼了,在线想要 442662578@qq.com和xxxxx@live.com谢谢楼主,手机号也可15131255789,搞起来呀" email_list = re.findall("(\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*)", text, re.ASCII) print(email_list) # [('44266-2578@qq.com', '-2578', '', ''), ('xxxxx@live.com', '', '', '')] -
补充代码,实现获取页面上的所有评论(已实现),并提取里面的邮箱。
# 先安装两个模块 pip3 install requests pip3 install beautifulsoup4import re import requests from bs4 import BeautifulSoup res = requests.get( url="https://www.douban.com/group/topic/79870081/", headers={ 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36', } ) bs_object = BeautifulSoup(res.text, "html.parser") comment_object_list = bs_object.find_all("p", attrs={"class": "reply-content"}) for comment_object in comment_object_list: text = comment_object.text print(text) # 请继续补充代码,提取text中的邮箱地址
4. 起始和结束
上述示例中都是去一段文本中提取数据,只要文本中存在即可。
但,如果要求用户输入的内容必须是指定的内容开头和结尾,比就需要用到如下两个字符。
^开始$结束
import re
text = "啊442662578@qq.com我靠"
email_list = re.findall("^\w+@\w+.\w+$", text, re.ASCII)
print(email_list) # []
import re
text = "442662578@qq.com"
email_list = re.findall("^\w+@\w+.\w+$", text, re.ASCII)
print(email_list) # ['442662578@qq.com']
这种一般用于对用户输入数据格式的校验比较多,例如:
import re
text = input("请输入邮箱:")
email = re.findall("^\w+@\w+.\w+$", text, re.ASCII)
if not email:
print("邮箱格式错误")
else:
print(email)
5. 特殊字符
由于正则表达式中 * . \ { } ( ) 等都具有特殊的含义,所以如果想要在正则中匹配这种指定的字符,需要转义,例如:
import re
text = "我是你{5}爸爸"
data = re.findall("你{5}爸", text)
print(data) # []
import re
text = "我是你{5}爸爸"
data = re.findall("你\{5\}爸", text)
print(data)
1.3.2 re模块
python中提供了re模块,可以处理正则表达式并对文本进行处理。
-
findall,获取匹配到的所有数据
import re text = "dsf130429191912015219k13042919591219521Xkk" data_list = re.findall("(\d{6})(\d{4})(\d{2})(\d{2})(\d{3})([0-9]|X)", text) print(data_list) # [('130429', '1919', '12', '01', '521', '9'), ('130429', '1959', '12', '19', '521', 'X')] -
match,从起始位置开始匹配,匹配成功返回一个对象,如果起始位置未匹配成功返回None
import re text = "大小逗2B最逗3B欢乐" data = re.match("逗\dB", text) print(data) # Noneimport re text = "逗2B最逗3B欢乐" data = re.match("逗\dB", text) if data: content = data.group() # "逗2B" print(content) -
search,浏览整个字符串去匹配第一个,未匹配成功返回None
import re text = "大小逗2B最逗3B欢乐" data = re.search("逗\dB", text) if data: print(data.group()) # "逗2B" -
sub,替换匹配成功的位置
import re text = "逗2B最逗3B欢乐" data = re.sub("\dB", "沙雕", text) print(data) # 逗沙雕最逗沙雕欢乐import re text = "逗2B最逗3B欢乐" data = re.sub("\dB", "沙雕", text, 1) print(data) # 逗沙雕最逗3B欢乐 -
split,根据匹配成功的位置分割
import re text = "逗2B最逗3B欢乐" data = re.split("\dB", text) print(data) # ['逗', '最逗', '欢乐']import re text = "逗2B最逗3B欢乐" data = re.split("\dB", text, 1) print(data) # ['逗', '最逗3B欢乐'] -
finditer
import re text = "逗2B最逗3B欢乐" data = re.finditer("\dB", text) for item in data: print(item.group())import re text = "逗2B最逗3B欢乐" data = re.finditer("(?P<xx>\dB)", text) # 命名分组 for item in data: print(item.groupdict())text = "dsf130429191912015219k13042919591219521Xkk" data_list = re.finditer("\d{6}(?P<year>\d{4})(?P<month>\d{2})(?P<day>\d{2})\d{3}[\d|X]", text) for item in data_list: info_dict = item.groupdict() print(info_dict)
小结
到此,关于最常见的内置模块就全部讲完了(共11个),现阶段只需要掌握这些模块的使用即可,在后续的课程和练习题中也会涉及到一起其他内置模块。
- os
- shutil
- sys
- random
- hashlib
- configparser
- xml
- json
- time
- datetime
- re
2. 项目开发规范
现阶段,我们在开发一些程序时(终端运行),应该遵循一些结构的规范,让你的系统更加专业。
2.1 单文件应用
当基于python开发简单应用时(一个py文件就能搞定),需要注意如下几点。
"""
文件注释
"""
import re
import random
import requests
from openpyxl import load_workbook
DB = "XXX"
def do_something():
""" 函数注释 """
# TODO 待完成时,下一期实现xxx功能
for i in range(10):
pass
def run():
""" 函数注释 """
# 对功能代码进行注释
text = input(">>>")
print(text)
if __name__ == '__main__':
run()
2.2 单可执行文件
新创建一个项目,假设名字叫 【crm】,可以创建如下文件和文件夹来存放代码和数据。
crm
├── app.py 文件,程序的主文件(尽量精简)
├── config.py 文件,配置文件(放相关配置信息,代码中读取配置信息,如果想要修改配置,即可以在此修改,不用再去代码中逐一修改了)
├── db 文件夹,存放数据
├── files 文件夹,存放文件
├── src 包,业务处理的代码
└── utils 包,公共功能
示例程序见附件:crm.zip
2.3 多可执行文件
新创建项目,假设名称叫【killer】,可以创建如下文件和文件夹来存放代码和数据。
killer
├── bin 文件夹,存放多个主文件(可运行)
│ ├── app1.py
│ └── app2.py
├── config 包,配置文件
│ ├── __init__.py
│ └── settings.py
├── db 文件夹,存放数据
├── files 文件夹,存放文件
├── src 包,业务代码
│ └── __init__.py
└── utils 包,公共功能
└── __init__.py
示例程序见附件:killer.zip
总结
- json格式和json模块
- json模块处理特殊的数据类型
- datetime格式与字符串、时间戳以及相关之间的转换。
- datetime格式时间与timedelta的加减。
- 两个datetime相减可以计算时间间隔,得到的是一个timedelta格式的时间。
- 了解正则表达式的编写方式和python中re模块的使用。
- 项目开发规范。
作业:开发短视频资讯平台
- 有video.csv视频库文件,其中有999条短视频数据,格式如下:【 video.csv 文件已为大家提供好,在day15课件目录下。 】

-
项目的核心功能有:
-
分页看新闻(每页显示10条),提示用户输入页码,根据页码显示指定页面的数据。
- 提示用户输入页码,根据页码显示指定页面的数据。
- 当用户输入的页码不存在时,默认显示第1页
-
搜索专区
- 用户输入关键字,根据关键词筛选出所有匹配成功的短视频资讯。
- 支持的搜索两种搜索格式:
id=1715025,筛选出id等于1715025的视频(video.csv的第一列)。key=文本,模糊搜索,筛选包含关键字的所有新闻(video.csv的第二列)。
-
下载专区
-
用户输入视频id,根据id找到对应的mp4视频下载地址,然后下载视频到项目的files目录。
-
视频的文件名为:
视频id-年-月-日-时-分-秒.mp4 -
视频下载代码示例
import requests res = requests.get( url='https://video.pearvideo.com/mp4/adshort/20210105/cont-1715046-15562045_adpkg-ad_hd.mp4' ) # 视频总大小(字节) file_size = int(res.headers['Content-Length']) download_size = 0 with open('xxx.mp4', mode='wb') as file_object: # 分块读取下载的视频文件(最多一次读128字节),并逐一写入到文件中。 len(chunk)表示实际读取到每块的视频文件大小。 for chunk in res.iter_content(128): download_size += len(chunk) file_object.write(chunk) file_object.flush() message = "视频总大小为:{}字节,已下载{}字节。".format(file_size, download_size) print(message) file_object.close() res.close() -
下载的过程中,输出已下载的百分比,示例代码如下:
import time print("正在下载中...") for i in range(101): text = "\r{}%".format(i) print(text, end="") time.sleep(0.2) print("\n下载完成")
-
-
-
附赠
自动采集梨视频1000条资讯的爬虫脚本。梨视频平台系统更新后可能会导致下载失败,到时候需根据平台调整再来修改代码。
"""
下载梨视频的:视频ID,视频标题,视频URL地址 并写入到本次 video.csv 文件中。
运行此脚本需要预先安装:
pip install request
pip install beautifulsoup4
"""
import requests
from bs4 import BeautifulSoup
def get_mp4_url(video_id):
data = requests.get(
url="https://www.pearvideo.com/videoStatus.jsp?contId={}".format(video_id),
headers={
"Referer": "https://www.pearvideo.com/video_{}".format(video_id),
}
)
response = data.json()
image_url = response['videoInfo']['video_image']
video_url = response['videoInfo']['videos']['srcUrl']
middle = image_url.rsplit('/', 1)[-1].rsplit('-', 1)[0]
before, after = video_url.rsplit('/', 1)
suffix = after.split('-', 1)[-1]
url = "{}/{}-{}".format(before, middle, suffix)
return url
def download_video():
file_object = open('video.csv', mode='w', encoding='utf-8')
count = 0
while count <= 999:
res = requests.get(
url="https://www.pearvideo.com/category_loading.jsp?reqType=14&categoryId=&start={}".format(count)
)
bs = BeautifulSoup(res.text, 'lxml')
a_list = bs.find_all("a", attrs={'class': "vervideo-lilink"})
for tag in a_list:
title = tag.find('div', attrs={'class': "vervideo-title"}).text.strip()
video_id = tag.get('href').split('_')[-1]
mp4_url = get_mp4_url(video_id)
row = "{},{},{}\n".format(video_id, title, mp4_url)
file_object.write(row)
file_object.flush()
count += 1
message = "已下载{}个".format(count)
print(message)
file_object.close()
if __name__ == '__main__':
download_video()
day16 阶段总结
课程目标:对第二模块 “函数和模块” 阶段的知识点进行总结和考试,让学员更好的掌握此模块的相关知识。
课程概要:
- 知识补充
- 阶段总结(思维导图)
- 考试题
1.知识补充
1.1 nolocal关键字
在之前的课程中,我们学过global关键字。
name = 'root'
def outer():
name = "武沛齐"
def inner():
global name
name = 123
inner()
print(name)
outer()
print(name)
其实,还有一个nolocal关键字,用的比较少,此处作为了解即可。
name = 'root'
def outer():
name = "武沛齐"
def inner():
nonlocal name
name = 123
inner()
print(name)
outer()
print(name)
name = 'root'
def outer():
name = 'alex'
def func():
name = "武沛齐"
def inner():
nonlocal name
name = 123
inner()
print(name)
func()
print(name)
outer()
print(name)
name = 'root'
def outer():
name = 'alex'
def func():
nonlocal name
name = "武沛齐"
def inner():
nonlocal name
name = 123
inner()
print(name)
func()
print(name)
outer()
print(name)
1.2 yield from
在生成器部分我们了解了yield关键字,其在python3.3之后有引入了一个yield from。
def foo():
yield 2
yield 2
yield 2
def func():
yield 1
yield 1
yield 1
yield from foo()
yield 1
yield 1
for item in func():
print(item)
1.3 深浅拷贝
-
浅拷贝
-
不可变类型,不拷贝。
import copy v1 = "武沛齐" print(id(v1)) # 140652260947312 v2 = copy.copy(v1) print(id(v2)) # 140652260947312按理说拷贝v1之后,v2的内存地址应该不同,但由于python内部优化机制,内存地址是相同的,因为对不可变类型而言,如果以后修改值,会重新创建一份数据,不会影响原数据,所以,不拷贝也无妨。
-
可变类型,只拷贝第一层。
import copy v1 = ["武沛齐", "root", [44, 55]] print(id(v1)) # 140405837216896 print(id(v1[2])) # 140405837214592 v2 = copy.copy(v1) print(id(v2)) # 140405837214784 print(id(v2[2])) # 140405837214592
-
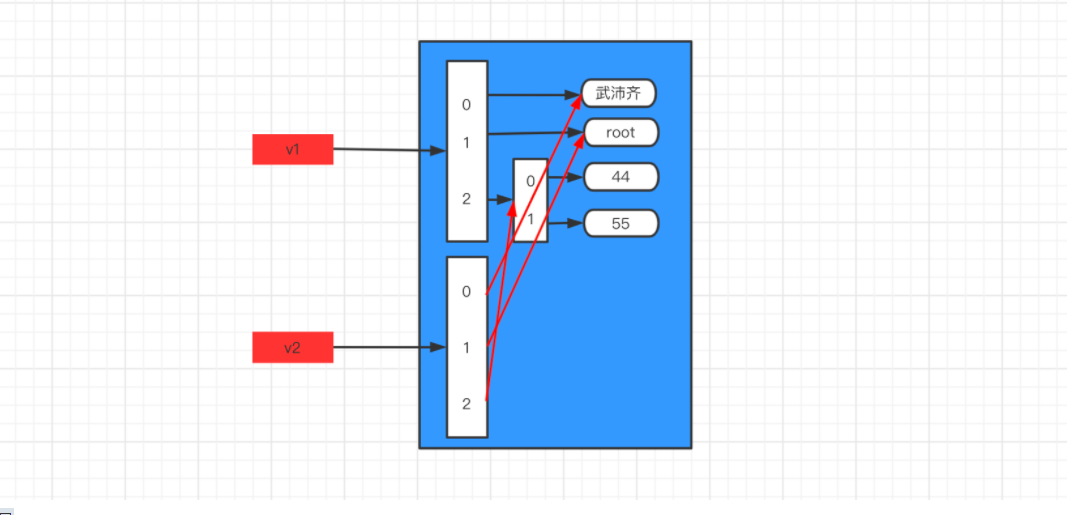
-
深拷贝
-
不可变类型,不拷贝
import copy v1 = "武沛齐" print(id(v1)) # 140188538697072 v2 = copy.deepcopy(v1) print(id(v2)) # 140188538697072特殊的元组:
-
元组元素中无可变类型,不拷贝
import copy v1 = ("武沛齐", "root") print(id(v1)) # 140243298961984 v2 = copy.deepcopy(v1) print(id(v2)) # 140243298961984 -
元素元素中有可变类型,找到所有【可变类型】或【含有可变类型的元组】 均拷贝一份
import copy v1 = ("武沛齐", "root", [11, [44, 55], (11, 22), (11, [], 22), 33]) v2 = copy.deepcopy(v1) print(id(v1)) # 140391475456384 print(id(v2)) # 140391475456640 print(id(v1[2])) # 140352552779008 print(id(v2[2])) # 140352552920448 print(id(v1[2][1])) # 140642999940480 print(id(v2[2][1])) # 140643000088832 print(id(v1[2][2])) # 140467039914560 print(id(v2[2][2])) # 140467039914560 print(id(v1[2][3])) # 140675479841152 print(id(v2[2][3])) # 140675480454784
-
-
可变类型,找到所有层级的 【可变类型】或【含有可变类型的元组】 均拷贝一份
import copy v1 = ["武沛齐", "root", [11, [44, 55], (11, 22), (11, [], 22), 33]] v2 = copy.deepcopy(v1) print(id(v1)) # 140391475456384 print(id(v2)) # 140391475456640 print(id(v1[2])) # 140352552779008 print(id(v2[2])) # 140352552920448 print(id(v1[2][1])) # 140642999940480 print(id(v2[2][1])) # 140643000088832 print(id(v1[2][2])) # 140467039914560 print(id(v2[2][2])) # 140467039914560 print(id(v1[2][3])) # 140675479841152 print(id(v2[2][3])) # 140675480454784import copy v1 = ["武沛齐", "root", [44, 55]] v2 = copy.deepcopy(v1) print(id(v1)) # 140405837216896 print(id(v2)) # 140405837214784 print(id(v1[2])) # 140563140392256 print(id(v2[2])) # 140563140535744
-
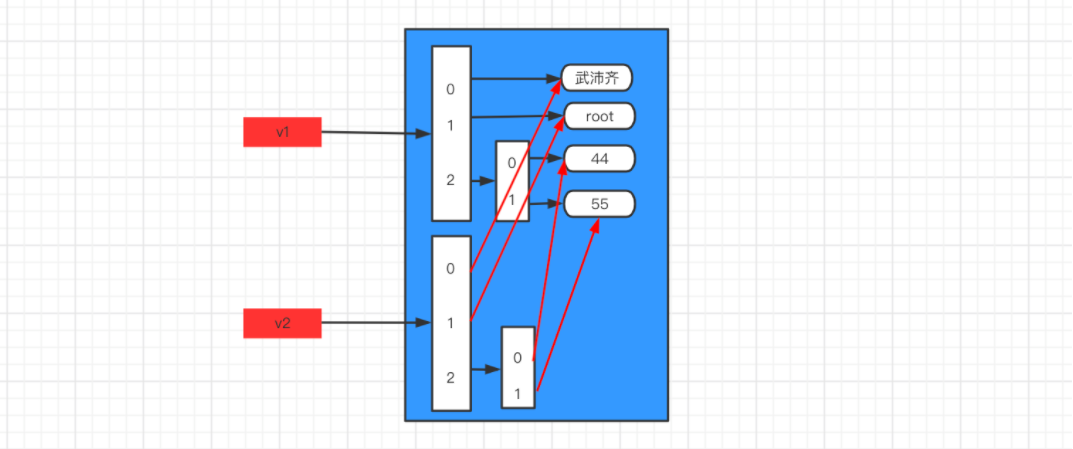
2.阶段总结
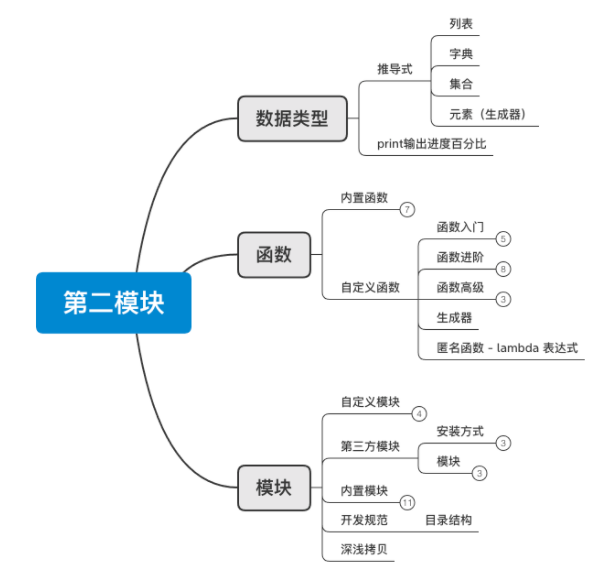
阶段考试题
-
一个大小为100G的文件 etl_log.txt,要读取文件中的内容,写出具体过程代码。
-
编写一个函数,这个函数接受一个文件夹名称作为参数,寻找文件夹中所有文件的路径并输入(包含嵌套)。
-
以下的代码数据的结果是什么?
def extend_list(val,data=[]): data.append(val) return data list1 = extend_list(10) list2 = extend_list(123,[]) list3 = extend_list("a") print(list1,list2,list3) -
python代码获取命令行参数。
-
简述深浅拷贝?
-
基于推导式一行代码生成1-100以内的偶数列表。
-
请把以下函数转化为python lambda匿名函数
def add(x,y): return x+y -
看代码写结果
def num(): return [lambda x: i * x for i in range(4)] result = [m(2) for m in num()] print(result) -
列表推导式和生成器表达式 [i % 2 for i in range(10)] 和 (i % 2 for i in range(10)) 输出结果分别是什么?
-
写装饰器
# 写timer装饰器实现:计算fun函数执行时间,并将结果给 result,最终打印(不必使用datetime,使用time.time即可)。 @timer def func(): pass result = func() print(result) -
re的match和search区别?
-
什么是正则的贪婪匹配?或 正则匹配中的贪婪模式与非贪婪模式的区别?
-
sys.path.append("/root/mods")的作用?
-
写函数
有一个数据结构如下所示,请编写一个函数从该结构数据中返画由指定的 字段和对应的值组成的字典。如果指定字段不存在,则跳过该字段。 DATA = { "time": "2016-08-05T13:13:05", "some_id": "ID1234", "grp1": {"fld1": 1, "fld2": 2, }, "xxx2": {"fld3": 0, "fld4": 0.4, }, "fld6": 11, "fld7": 7, "fld46": 8 } fields:由"|"连接的以fld开头的字符串, 如fld2|fld7|fld29 def select(fields): print(DATA) return result -
编写函数,实现base62encode加密(62进制),例如:
内部维护的数据有:0123456789AB..Zab..z(10个数字+26个大写字母+26个小写字母)。 当执行函数: base62encode(1),获取的返回值为1 base62encode(61),获取的返回值为z base62encode(62),获取的返回值为10 -
基于列表推导式一行实现输出9*9乘法表。
段考试题(答案)
-
一个大小为100G的文件 etl_log.txt,要读取文件中的内容,写出具体过程代码。
# 如果文件有很多行 with open('etl_log.txt',mode='r',encoding="utf-8") as file_object: for line in file_object: pass# 如果文件只有一行 import os file_size = os.path.getsize("etl_log.txt.txt") read_size = 0 with open('etl_log.txt.txt', 'rb') as file_object: while read_size < file_size: data = file_object.read(1) read_size += len(data) -
编写一个函数,这个函数接受一个文件夹名称作为参数,寻找文件夹中所有文件的路径并输入(包含嵌套)。
import os def get_file_path(folder_path): for base_path, folder_list, file_list in os.walk(folder_path): for file in file_list: file_path = os.path.join(base_path, file) print(file_path) -
以下的代码数据的结果是什么?
def extend_list(val, data=[]): data.append(val) return data list1 = extend_list(10) list2 = extend_list(123, []) list3 = extend_list("a") print(list1, list2, list3)输出:[10, 'a'] [123] [10, 'a'] -
python代码获取命令行参数。
import sys sys.argv -
简述深浅拷贝?
浅拷贝: - 不可变类型,不拷贝 - 可变类型,只拷贝第一层 深拷贝: - 不可变类型,不拷贝 - 可变类型,所有层级的可变类型都拷贝(元组中如果包含可变类型也会被拷贝) -
基于推导式一行代码生成1-100以内的偶数列表。
v = [i for i in range(1, 101) if i % 2 == 0] print(v) -
请把以下函数转化为python lambda匿名函数
def add(x,y): return x+yadd = lambda x,y:x+y -
看代码写结果
def num(): return [lambda x: i * x for i in range(4)] result = [m(2) for m in num()] print(result)输出:[6, 6, 6, 6] -
列表推导式和生成器表达式 [i % 2 for i in range(10)] 和 (i % 2 for i in range(10)) 输出结果分别是什么?
[i % 2 for i in range(10)] ,得到一个列表,内部元素是 [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] (i % 2 for i in range(10)) ,的到一个生成器对象。 -
写装饰器
# 写timer装饰器实现:计算fun函数执行时间,并将结果给 result,最终打印(不必使用datetime,使用time.time即可)。 @timer def func(): pass result = func() print(result)import time import functools def timer(func_name): @functools.wraps(func_name) def inner(*args, **kwargs): start = time.time() res = func_name(*args, **kwargs) end = time.time() message = "耗时:{}".format(end - start) print(message) return res return inner -
re的match和search区别?
match,从头开始匹配。 search,在整个字符串中进行匹配。 他们均获取一个匹配成功的值。 -
正则匹配中的贪婪模式与非贪婪模式的区别?
贪婪匹配,尽量多的匹配字符。 非贪婪匹配,尽量少的匹配字符(只要符合匹配条件就结束),特点是:? -
sys.path.append("/root/mods")的作用?
将路径加入到sys.path,那么项目中就可以直接导入/root/mods目录下的模块和包。 -
写函数
有一个数据结构如下所示,请编写一个函数从该结构数据中返画由指定的 字段和对应的值组成的字典。如果指定字段不存在,则跳过该字段。 DATA = { "time": "2016-08-05T13:13:05", "some_id": "ID1234", "grp1": {"fld1": 1, "fld2": 2, }, "xxx2": {"fld3": 0, "fld4": 0.4, }, "fld6": 11, "fld7": 7, "fld46": 8 } fields:由"|"连接的以fld开头的字符串, 如fld2|fld7|fld29 def select(fields): print(DATA) return resultDATA = { "time": "2016-08-05T13:13:05", "some_id": "ID1234", "grp1": {"fld1": 1, "fld2": 2, }, "xxx2": {"fld3": 0, "fld4": 0.4, }, "fld6": 11, "fld7": 7, "fld46": 8 } def select(fields): result = {} field_list = fields.split('|') for field in field_list: value = DATA.get(field) if not value: continue result[field] = value return result -
编写函数,实现base62encode加密(62进制),例如:
内部维护的数据有:0123456789AB..Zab..z(10个数字+26个大写字母+26个小写字母)。 当执行函数: base62encode(1),获取的返回值为1 base62encode(61),获取的返回值为z base62encode(62),获取的返回值为10 base62encode(63),获取的返回值为11思路:一直让输入的数值除以62取余数,以此取到的余数分别是每一位的索引位置。 5/62 得到 0 , 余数 5 05 62/62 得到 1 , 余数 0 10 178/62 得到 2 ,余数 54 2P 98723/62 得到1592,余数19 [C,B,K] 1592/62 得到25,余数42import string import itertools MAP = list(itertools.chain(string.digits, string.ascii_uppercase, string.ascii_lowercase)) def base62encode(num): total_count = len(MAP) position_value = [] while num >= total_count: num, remain = divmod(num, total_count) position_value.insert(0, MAP[remain]) position_value.insert(0, MAP[num]) result = "".join(position_value) return result -
基于列表推导式一行实现输出9*9乘法表。
# # 第一步:[['{}*{}'.format(i, j) for j in range(1, i + 1)] for i in range(1, 10)] # 第二步:[" ".join(['{}*{}'.format(i, j) for j in range(1, i + 1)]) for i in range(1, 10)] # 第三步:'\n'.join([" ".join(['{}*{}'.format(i, j) for j in range(1, i + 1)]) for i in range(1, 10)])print("\n".join([" ".join(['{}*{}'.format(i, j) for j in range(1, i + 1)]) for i in range(1, 10)]))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号