- DOM2 和DOM3支撑更多的交互能力,也支持更高级的XML的特性
- 从技术上说,HTML 不支持XML 命名空间,但XHTML 支持XML 命名空间。所以要区分开,需要增加XML前缀
1 <!DOCTYPE html> 2 <xhtml:html lang="en" xmlns:xhtml="http://www.w3.org/1999/xhtml"> 3 <xhtml:head> 4 <meta charset="UTF-8"> 5 <xhtml:title>DOM2</title> 6 <script type="text/javascript"></script> 7 </xhtml:head> 8 9 <xhtml:body> 10 11 </xhtml:body> 12 </xhtml:html>
- Node类型的变化:
- localName
- nameSpaceURI
- prefix
对于上面代码第一行来说,localName是html,nameSpaceURI是“http://www.w3.org/1999/xhtml",prefix是null
- document类型的变化
-
createElementNS(namespaceURI, tagName):使用给定的tagName 创建一个属于命名空间namespaceURI 的新元素。
-
createAttributeNS(namespaceURI, attributeName):使用给定的attributeName 创建一个属于命名空间namespaceURI 的新特性。
-
getElementsByTagNameNS(namespaceURI, tagName):返回属于命名空间namespaceURI的tagName 元素的NodeList。
- 偏移量
- offsetHeight/Width/Top/Left
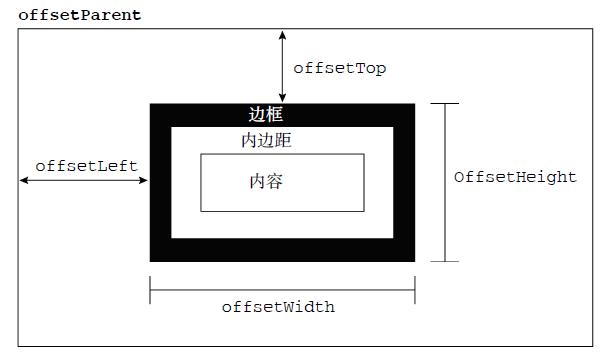
确定元素的准确偏移量:
1 function getElementLeft(element){ 2 var actualLeft = element.offsetLeft; 3 var current = element.offsetParent;//offsetParent指向父类元素的引用 4 while (current !== null){ 5 actualLeft += current.offsetLeft; 6 current = current.offsetParent; 7 } 8 return actualLeft; 9 }
- 遍历
- NodeIterator
1 var iterator = document.createNodeIterator(document, NodeFilter.SHOW_ALL,null, false);
2. TreeWalker
1 var walker= document.createTreeWalker(div, NodeFilter.SHOW_ELEMENT,filter, false);
1 var filter = function(node){ 2 return node.tagName.toLowerCase() == "li"? 3 NodeFilter.FILTER_ACCEPT : 4 NodeFilter.FILTER_SKIP; 5 };
创建TreeWalker 对象要使用document.createTreeWalker()方法,这个方法接受的4 个参数与document.createNodeIterator()方法相同:作为遍历起点的根节点、要显示的节点类型、过滤器和一个表示是否扩展实体引用的布尔值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号