
这是YOLO训练时的运作过程:首先我们先设定,现在可识别的类别数量是C。

输入图像之后。像左边这样,图像被分成S*S大小的grid cell,对于每个cell呢,如果obj的中心点落在grid cell中。这个cell就负责检测这个obj。
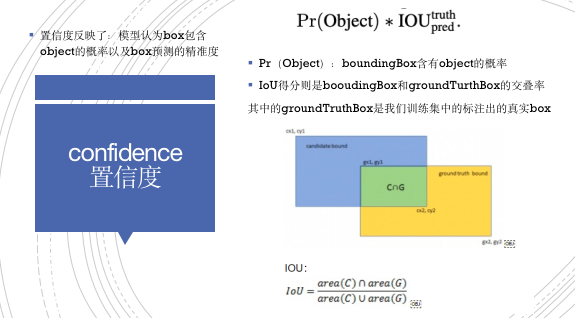
每个cell都会预测B个BoundingBox,如中间上左图,注意了,box是可以超过cell的范围的。每个boundingbox呢,都会有5个参数,分别是:这个box的置信度confidence,(置信度的计算我们可以看到下图:
(confidence、IoU解释)
![]()
左边Pr(Object)是这个boundingbox含有obj的概率,而右边IOU得分则是booudingbox和groundTurth的交并比,字面意思,也就是两部分交集和并集的比。其中的groundTruth是我们训练集中的标注出的真实box。
)
以及box的中心点坐标x、y,box的宽高width、height。
另外,,每个cell都会预测C个类别的概率,这个概率计算的前提条件是这个cell有object。并且,这个条件类别概率和boundingbox的置信度confidence是不相关的。并且,无论cell会生成多少个boundingbox,每个grid cell也只负责一个obj。进行一组条件类别概率预测。这就对应的是中下图的class probability map。
接着,YOLO会对这些boundingbox进行非最大值抑制算法(NMS),这个算法我们可以看到下图

NMS解释)
刚才对grid cell进行来条件类别概率的计算,就算cell没有obj也没关系,继续算,反正confidence=0,对结果没影响。
得到了这两个之后,我们可以计算一个分数来衡量“boundingbox含有某个类的物体的概率以及box的精准度”
![]()
基于这个分数,我们对其进行not-maximum suppression非极大值抑制,具体的运作过程就是,先遍历所有的box,挑选出得分最高的box,接着设立一个阈值,当其他box与这个挑选出来的框的IOU超过这个阈值,也就是说明他们极有可能预测的是同一个object时,删除掉这些box。接着我们继续在未处理过的box中重复上述过程。最后我们得到的结果就是每个obj都由得分最高的box框出。
【question:删除了,那为什么结果还是S*S的tensor?此处指的“删除”是以何种方式】
【置信度=0】
。那么可以看见,最终的结果是输出一个S*S*(B*5+C)的向量,就像这样

->输出S*S*(B*5+C)的向量;
综上所述:

【在PASCAL VOC数据集上进行YOLO训练测试,使用参数S=7,B=2,VOC有20个label因此C=20,我们最后的预测结果是7*7*(2*5+20)的向量】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号