keras 处理文本数据
使用人工智能判断imdb电影评论网站上的评论是好评还是恶评。
这些评论都是英文的,这时候我们需要将文字转换成对应的数字,神经网络才能对这些数字进行计算和分析。不过,keras已经把这些工作都做好了,它为这些评论中的单词设立了一个字典
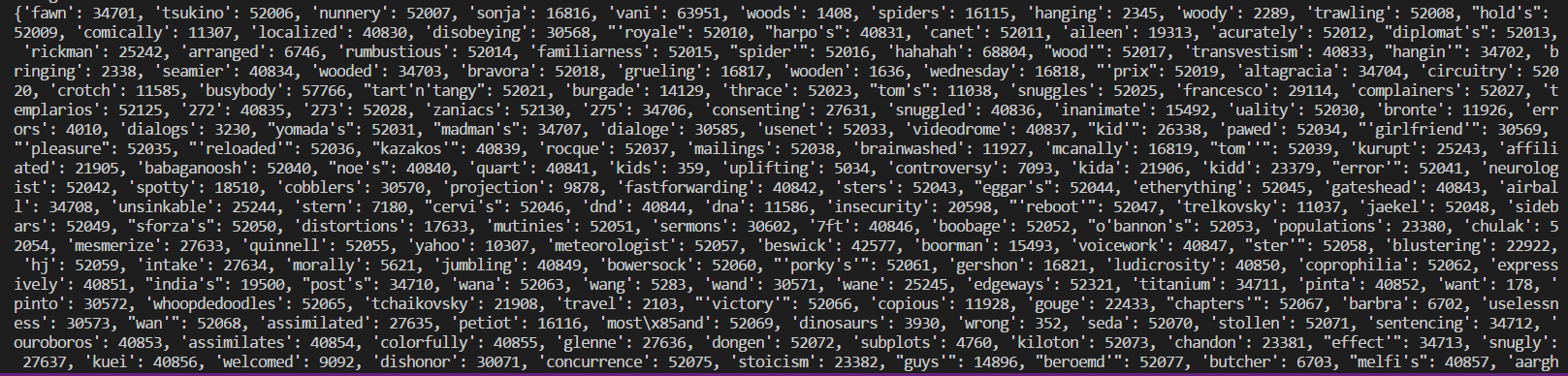
有了这个字典之后,keras把原评论中的单词变成了单词对应数字组成的数组

导入包
from tensorflow import keras
from tensorflow.keras.datasets import imdb
from tensorflow.keras import models
from tensorflow.keras import layers
from tensorflow.keras import losses
from tensorflow.keras import metrics
import numpy as np
载入数据并选择性查看
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=1000) # 加载数据。num_words = 1000 用来筛选单词:评论中的单词如果是最常用词的前1000个则可以显示,即 每一条评论里面至多会存在1000个不同的单词,如果不是则替换成 2
print(x_train[0])
print(x_train.shape)

结果表明 x_train 中一共有25000项数据,其中每一项数据都是一个数组,因为每个评论的长度都不一样,所以shape显示为(25000,)。
数据预处理
# 由于每一项数据的长度都不一样,而神经网络的输入层的输入是固定数量的,所以需要将每一项数据的长度变得一致
# 由于每一条评论里面至多会存在1000个不同的单词,所以可以用一个长度为1000的数组来表示这条评论中含有哪些单词
# one-hot编码:先初始化数组中元素全为 0,然后取评论中单词在字典中的键值。之后,使数组中对应键值位置的元素为1,表明评论中出现了这个单词
def one_hot_sequences(sequences, dimension=1000): # 第一个参数 sequences 是需要被编码的数据,第二个参数 dimension 是编码后每一项数据的长度。因为每一条评论里面至多会存在1000个不同的单词,需要为每一条评论创建的数组长度为1000,所以取 dimension=1000
results = np.zeros((len(sequences), dimension)) # 创建长度为1000的数组,初始化数组中元素全为 0。这些数组组合起来是一个大的矩阵,宽为1000,长为数据集中评论的条数,即 len(sequences)
for i, sequence in enumerate(sequences): # 遍历数据集sequences中的每一条评论: i 表示当前评论是 sequences 中第几条评论;sequence 是一个数组,对于评论中出现的单词,数组会顺序存入 keras 字典中该单词对应的键值
results[i, sequence] = 1 # 找到第 i 条评论对应 one-hot 矩阵中的第 i 行 result[i],把这一行看成一个result[i]数组,对 sequence数组中包含的每一个索引值,将result[i]数组中对应位置的元素全置为 1
return results # 当for循环结束时,每条评论的数组中出现的单词对应索引位置为1了,也就是说 result矩阵转换成sequences的one-hot编码形式
x_train = one_hot_sequences(x_train)
x_test = one_hot_sequences(x_test)
x_train = np.array(x_train)
x_test = np.array(x_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
可以再次查看 x_train[0]

搭建模型
要将评论分类为正面评论和负面评论,这是一个二分类问题,所以输出层为一个 sigmoid 激活层
model = models.Sequential()
model.add(layers.Dense(64, input_shape=(1000,)))
model.add(layers.Dense(32))
model.add(layers.Dense(16))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adadelta', loss='binary_crossentropy', metrics=['acc'])
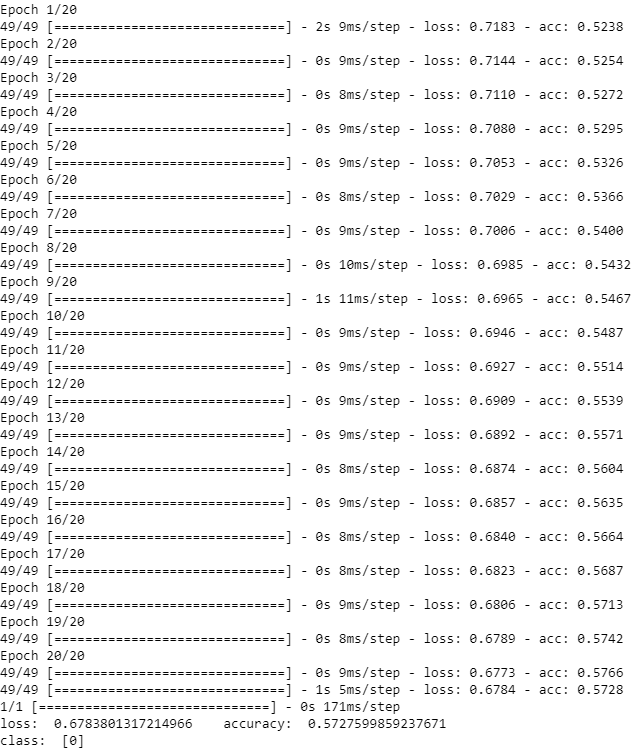
model.fit(x_train, y_train, epochs=20, batch_size=512)
score = model.evaluate(x_test, y_test, batch_size=512)
predict = model.predict(x_test[4].reshape(1,-1), batch_size=1)
classes = np.argmax(predict, axis=1)
print(r'loss: ', score[0], r' accuracy: ', score[1])
print(r'class: ', classes)
但是训练网络后,发现结果并不理想
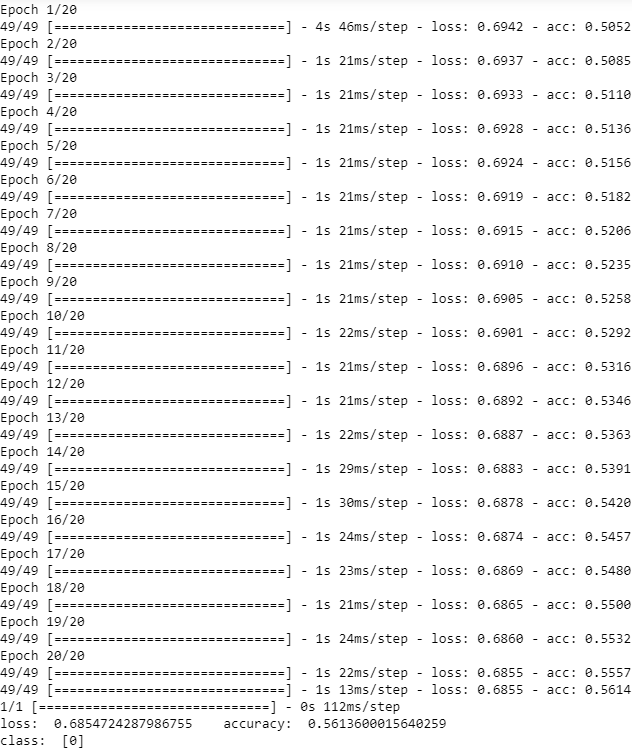
为了增加模型的拟合性,在每一个隐藏层后添加一个 ReLU 激活函数。ReLU 是一个非线性函数,能增加模型的非线性从而增强模型对数据的拟合能力
model.add(layers.Dense(512, activation='relu', input_shape=(1000,)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid')) # sigmoid 激活函数处理二分类问题
可以发现模型在训练数据集上的拟合能力得到了很大的提升。但是模型在测试数据上的拟合能力并不如它在训练数据上的能力。这种情况可能是由于过拟合。过拟合就是模型对训练数据的拟合能力过强了,几乎把所有的特征都学习到判断的规则中了,包括一些无关紧要的特征。对于训练数据的过拟合,会影响到模型对测试集中未遇到过的数据的拟合和辨别能力
可以适当地增加一些 dropout 层,作用是断开神经网络上的一些链接,减少特征的提取。通过 layer.Dropout() 方法来创建一个 dropout 层其中的参数用于控制需要断开的神经元的比例
model.add(layers.Dense(512, activation='relu', input_shape=(1000,)))
model.add(layers.Dropout(0.3))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.4))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid')) # sigmoid 激活层处理二分类问题


 浙公网安备 33010602011771号
浙公网安备 33010602011771号