Numpy & Pandas 基础
用 Jupyter Notebook 更方便学习。
Numpy
Numpy 支持高级大量的维度数组与矩阵运算,运算效率极好,是大量机器学习框架的基础。
Numpy 中最重要的对象是称为 ndarray 的 N 维数组类型:
-
数组:具有相同类型的一组数据的集合
-
一维数组:一组相同数据类型的线性集合
-
二维数组:多个一维数组的有序排列,且这些一维数组要满足数组内的元素数据类型相同、个数相同
在使用 numpy 前需要先导入这个库,一般写为 import numpy as np,则数组为 np.array()。
数组的属性
-
.ndim:数组的维度 -
.shape:数组的形状。返回的是一个元组,表示每个维度的大小
例1:
a = np.array( [1, 2, 3] ),形状是 a.shape = (3,)
例2:
a = np.array( [ [1, 2, 3], [4, 5, 6] ] ),形状是 a.shape = (2, 3)


例3:
a =np.array( [ [ [1,2], [2,3], [3,4] ], [ [4,5], [5,6], [6,7] ], [ [7,8], [8,9], [9,10] ] ] ),形状是 a.shape = (2, 3)
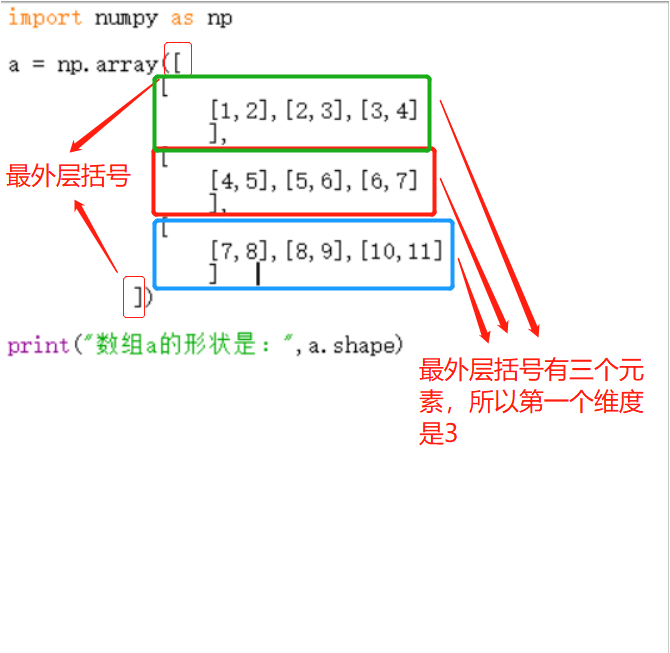


-
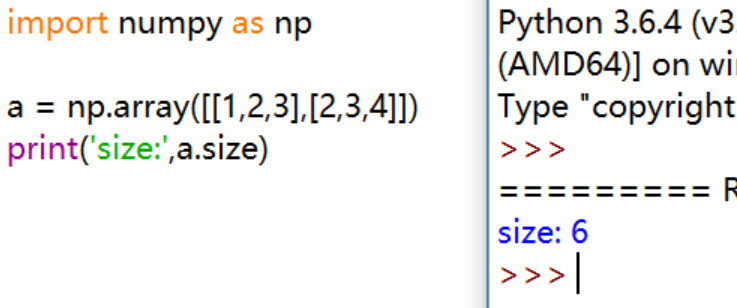
.size:数组的元素个数
![image]()
-
.dtype:数组中元素类型的对象
NumPy 提供了自己的类型,如 numpy.int32 和 numpy.float64 等
创建 nparray
-
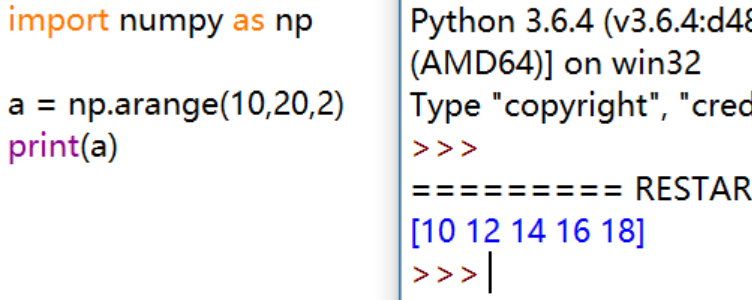
np.arange():类似于Python的 range() 函数,通过指定开始值、终值和步长来创建一维数组,注意数组不包括终值
![image]()
-
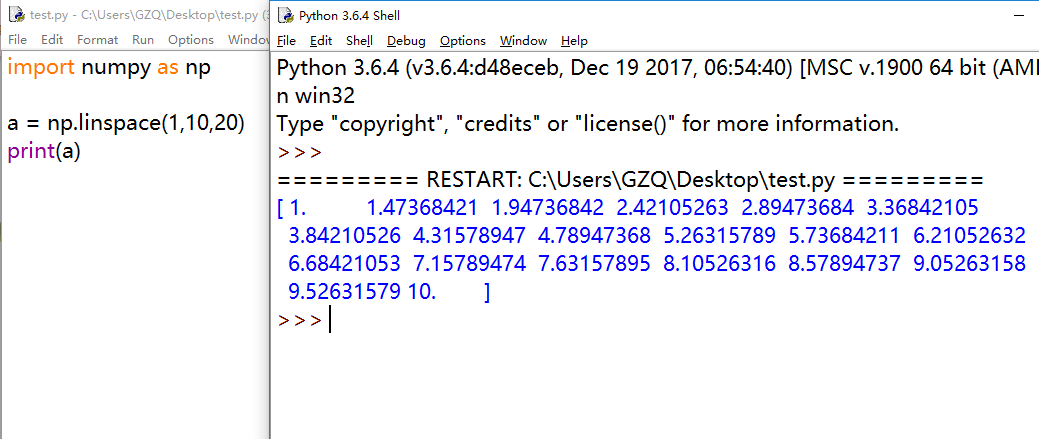
np.linspace():通过指定开始值、终值和元素个数来创建一维数组
![image]()
-
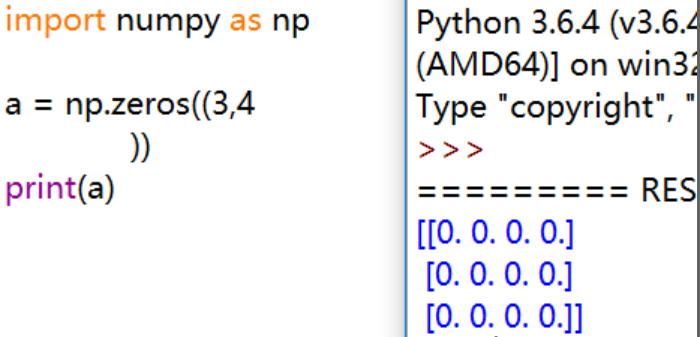
np.zeros():创建元素均为 0 的数组,默认的数据类型是 numpy.float64
![image]()
-
np.ones():生成元素均为1的数组 -
np.reshape():改变数组形状
![image]()

数组索引
索引的操作与 Python 列表相似。

得到第一个维度的变量:除去数组最外层的[]剩下的部分。
得到第二个维度的变量array[:,col]:第一个维度用冒号占位,然后输入第二个维度(也就是列)里面想要得到的元素索引,两者用逗号分隔开。
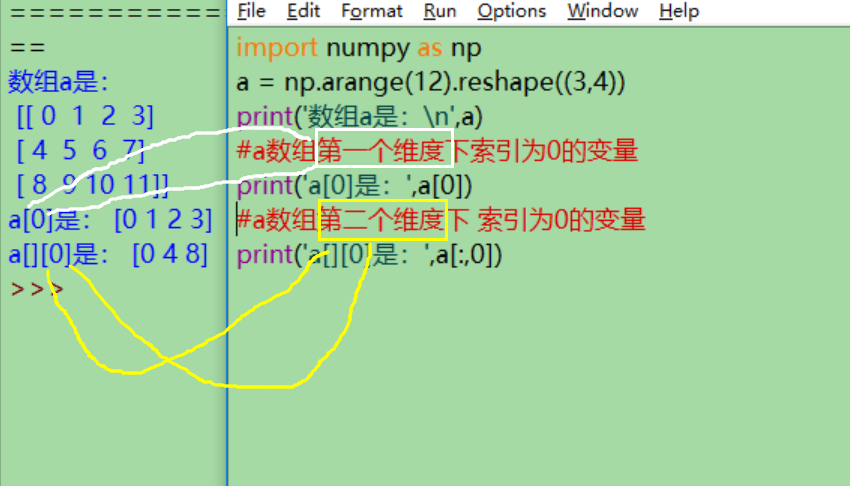
得到特定行特定列的元素:
-
array[row][col]或array[row, col] -
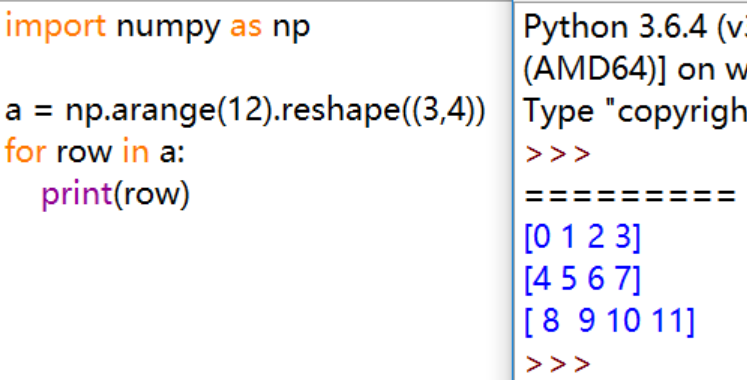
for 循环
![image]()
数组的运算
基本运算就是两个数组元素对应相加减乘除。如果想要求sin、cos等三角函数,就需要用np.sin(),其他三角函数也是一样的。
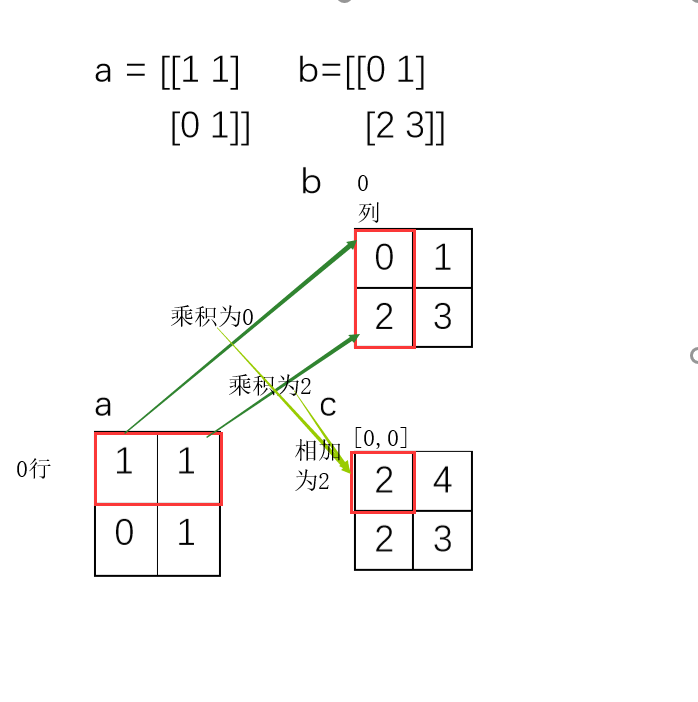
np.dot():矩阵的运算要用到点乘。
矩阵乘法就是 所得到的数组中的每个元素为,第一个矩阵中与该元素行号相同的元素与第二个矩阵与该元素列号相同的元素,两两相乘后再求和。
-
np.sum():数组内元素求和 -
np.min(): -
np.max():-
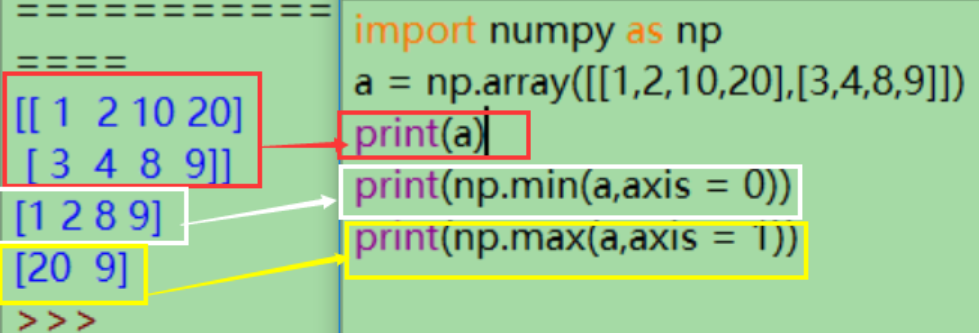
axis是轴的意思,代表维度的索引,从 0 开始。通过改变axis的值可以根据不同维度比较:
![image]()
- 二维数组a,axis=0 表示第一个维度。也就是数组去掉最外面的一对[],剩下的内容。
a = [[1,2,10,20], [3,4,8,9]], axis = 0 时,去掉最外面的一对[],里面剩下的是 [1,2,10,20] 和 [3,4,8,9],如果对这两者求 min,一一比较之下,结果是[1,2,8,9]。
- axis = 1 就是第二个维度,也就是找到第二层 [] 然后操作里面的内容。
这里第二层 [] 有两个,分别对里面的内容,如果求 max 就得到 1,2,10,20 的最大值20;3,4,8,9 的最大值9;输出这两个值。
-
数组的合并与分割
-
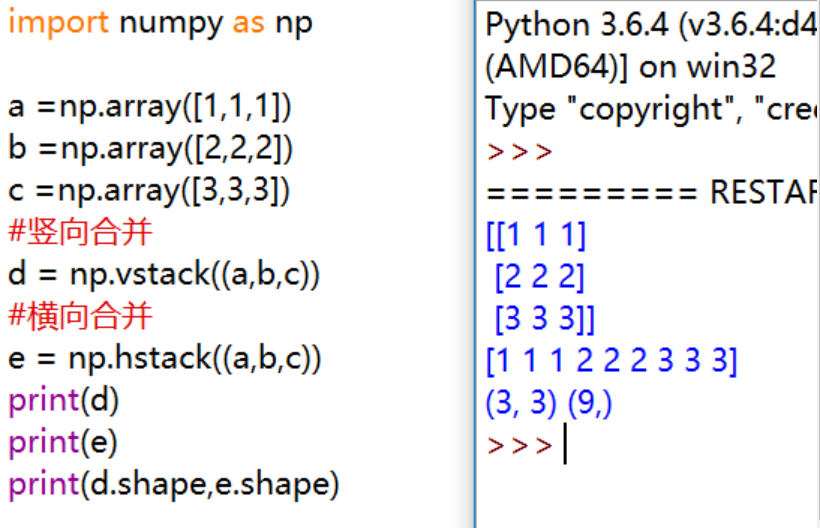
np.vstack():竖向合并数组 -
np.hstack():横向合并数组
![image]()
-
np.concatenate():横向合并数组 -
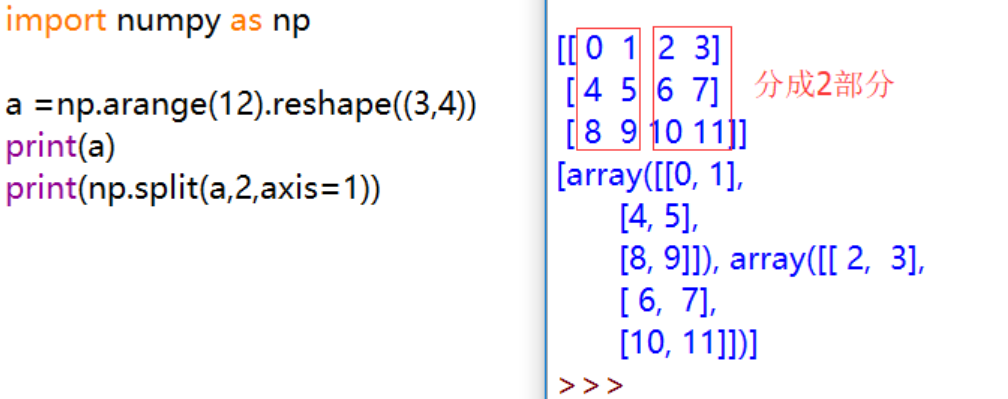
np.split():分割数组。最后的数据类型是list,里面的元素的数据类型是 ndarray
![image]()
将数组a按照 axis = 1,也就是第二个维度,分为两部分 [0,1] 和 [2,3],对应部分再合并在一起,形成新的数组 array([[0,1],[4,5],[8,9]]) 和 array([[2,3],[6,7],[10,11]]) ,两个新的数组再组成list输出作为结果。
-
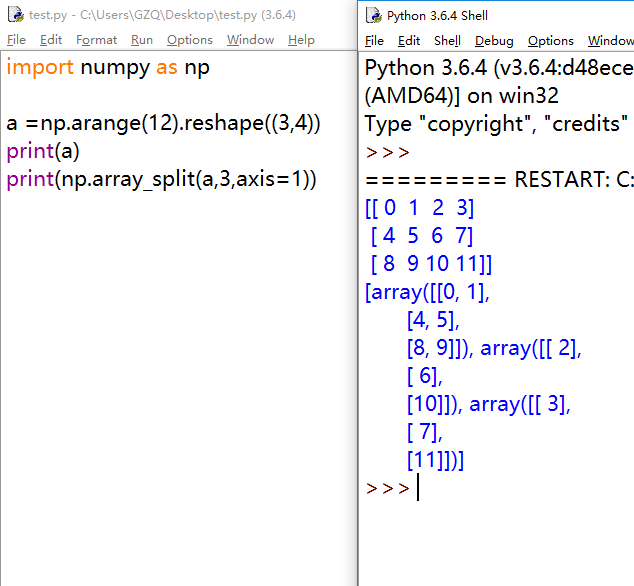
np.array_split:与split相比,就是不强制一定要均等的划分该维度的元素
![image]()
![image]()
-
np.vsplit():竖向分割数组 -
np.hsplit():横向分割数组

Pandas
Pandas里的数据结构中,常用到的有 Series 和 DataFrame 两种:
-
Series:一维数组,与 Python 的数据结构 列表List 也很相近。
-
DataFrame:二维的表格型数据结构,看起来是表格,有行和列。
数据查看与导出
Pandas 可以兼容许多文本文件,比如 csv、xml、HTML、xls、xlsx 等。例如:
pd.read_csv(filename):导入csv格式文件中的数据
例如data = pd.read_csv(r"D:/Download/drinks.csv")。
(以下的data都是所导入文件的命名)
导入文件后查看是否导入成功:
-
data
.info():查看数据框 (DataFrame) 的索引、数据类型及内存信息 -
data
.shape:表达数据框的维度,结果为(行, 列) -
data
.head(n):查看数据框的前 n 行 -
data
.tail(n):查看数据框的最后 n 行 -
data.
to_excel(path):将数据导出到excel格式的文件中,括号里填想要导出到的路径
数据选取与清洗
选取
- data
.iloc[a:b, c:d]:选取第 a 到 b 行,c 到 d 列的数据
从 DataFrame 中选择一个 Series:
- data
['col']:以 Series 的形式返回选取的列(col→collumn 列)
注意格式
从 DataFrame 中选择一个新的 DataFrame:
- data
[['col1','col2','col3, …]]:以 DataFrame 的形式返回选取的列
空值
-
data.
isnull():检查数据中出现空值 (NaN) 的情况,并返回布尔值(True, False)组成的列 -
data.
notnull():检查数据中非空值出现的情况,并返回布尔值(True, False)组成的列 -
data.
dropna():移除 DataFrame 中包含空值的行-
axis = 1:移除 DataFrame 中包含空值的所有列
-
axis = 0:移除 DataFrame 中包含空值的所有行
-
-
data.
fillna(x):将 DataFrame 中的所有空值替换为 x
统计
-
data.
describe():得到数据每一列的描述性统计 -
data.
mean():得到数据每一列的平均值 -
data.
corr():得到数据每一列与其他列的相关系数 -
data.
max():得到数据中每一列的最大值 -
data.
min():得到数据中每一列的最小值 -
data.
median():得到数据中每一列的中位数 -
data.
std():得到数据中每一列的标准差
排序
-
data.
sort_values('col'):将数据按照某一列数据进行升序排列 -
data.
sort_values('col',ascending = False):将数据按照某一列数据进行降序排列 -
data.
sort_values([col1,col2]):多列排序
过滤(分类)
-
data.
groupby(col).mean():按照某列对数据做分组,并返回平均值 -
data.
groupby(col1)[col2].mean():按照某列对数据做分组,仅返回一列数据的平均值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号