【树】力扣637:二叉树的层平均值
给定一个非空二叉树的根节点 root , 以数组的形式返回每一层节点的平均值。与实际答案相差 \(10^{-5}\) 以内的答案可以被接受。
示例:
输入:root = [3,9,20,null,null,15,7]
输出:[3.00000,14.50000,11.00000]
解释:第 0 层的平均值为 3,第 1 层的平均值为 14.5,第 2 层的平均值为 11 。
因此返回 [3, 14.5, 11] 。
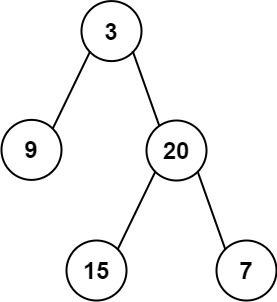
输入是一个二叉树,输出是一个一维数组,表示每层结点值的平均数。
看题目与树的层数有关,自然想到【层次遍历】。
广度优先搜索
使用广度优先搜索计算二叉树的层平均值:遍历二叉树的每一层,记录该层的结点总值和结点数,然后求该层平均值加入 res 结果集中,直至遍历完整棵二叉树。
至于每层的遍历,使用队列这种数据结构。使用队列保存每一层的所有结点(所以初始化为 [root]),把队列里的所有结点出队列,同时把这些出去结点各自的子结点入队列。
队列是一种先进先出(First in First Out)的数据结构,简称 FIFO。
两个队列
设置两个队列:queue 存储本层的所有结点,childque 另一个存储下一层的所有结点,然后将 chileque 赋给 queue。
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def averageOfLevels(self, root: Optional[TreeNode]) -> List[float]:
if not root:
return []
queue = [root] # 使用队列存储一层中的所有结点
# queue = collections.deque([root])
ave = [] # 结果集
while queue: # 队列为空时遍历结束
sum = 0 # 存储当前层结点和
size = len(queue) # 当前层结点数
childque = [] # 使用列表存储除第0层之外的当前层孩子结点
for node in queue:
sum += node.val
if node.left: # 若结点存在左孩子,入队
childque.append(node.left)
if node.right: # 若结点存在右孩子,入队
childque.append(node.right)
ave.append(sum / size) # 一层遍历结束即for循环结束,计算层平均值
queue = childque # 更新队列为下一层的结点,继续遍历
return ave
一个队列
直接设置一个"当前层尺寸"就可以。由于本来就已经设置了变量 size 存储当前层结点数,刚好可以用来进行 for 循环。
deque 是Python标准库 collections 中的一个类,是 double-ended queue的缩写,实现了两端都可以操作的队列,相当于双端队列。类似于 list,与 list 不同的是,deque 实现拥有更低的时间和空间复杂度。
-
出队:
popleft() -
入队:
append()
就很奇怪,不引入双向队列,或者引入了而仅用pop出队,结果都是差一些的。。
from collections import deque
class Solution:
def averageOfLevels(self, root: Optional[TreeNode]) -> List[float]:
if not root:
return []
queue = collections.deque([root]) # 使用队列存储一层中的所有结点,初始化为第0层的
ave = [] # 结果集
while queue: # 队列为空时遍历结束
sum = 0 # 存储当前层结点和
size = len(queue) # 当前层结点数
for _ in range(size):
node = queue.popleft()
sum += node.val
if node.left: # 若结点存在左孩子,入队
queue.append(node.left)
if node.right: # 若结点存在右孩子,入队
queue.append(node.right)
ave.append(sum / size) # 一层遍历结束即for循环结束,计算层平均值
return ave
时间复杂度:O(n),其中 n 是二叉树中的结点个数。广度优先搜索需要对每个结点访问一次,时间复杂度是 O(n);需要对二叉树的每一层计算平均值,时间复杂度是 O(h),其中 h 是二叉树的高度,任何情况下都满足 h ≤ n。因此总时间复杂度是 O(n)。
空间复杂度:O(n)。空间复杂度取决于队列开销,队列中的结点个数不会超过 n。
深度优先搜索
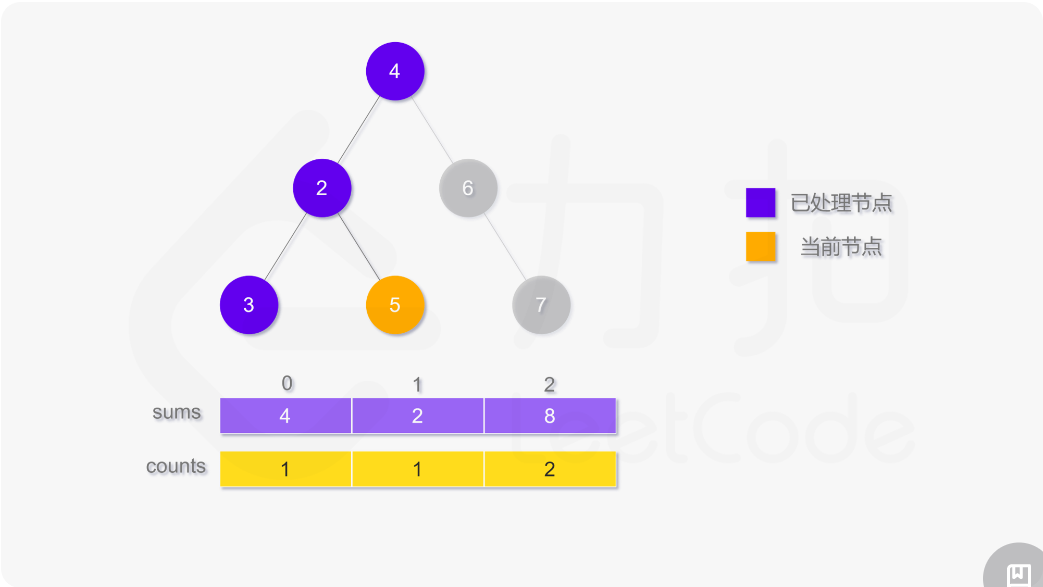
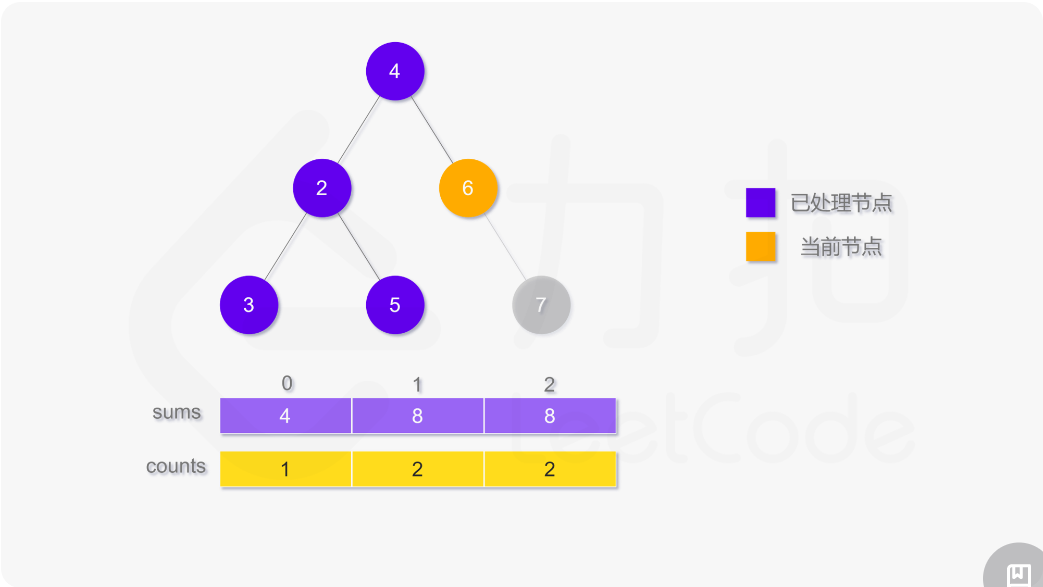
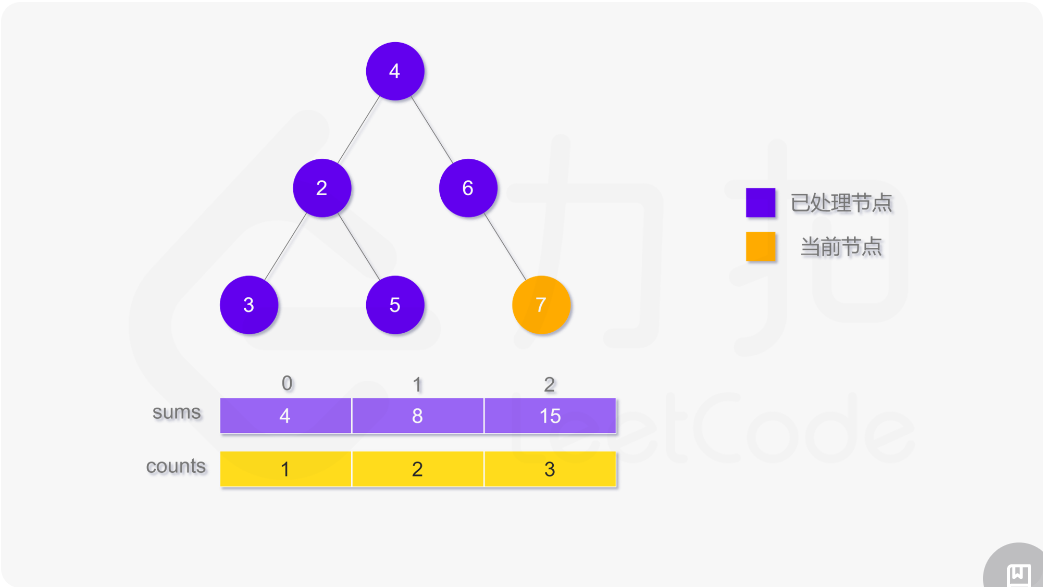
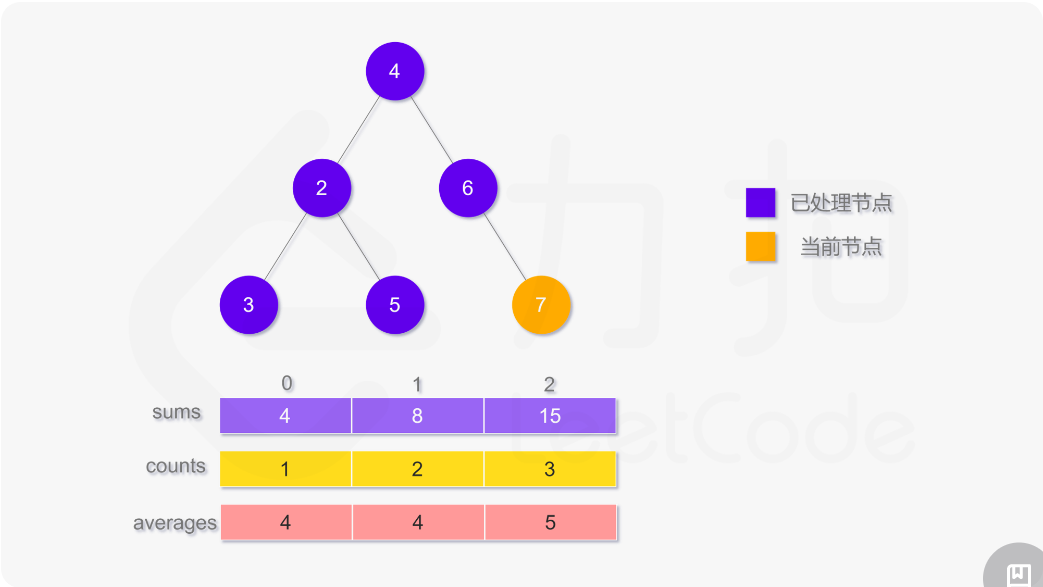
使用深度优先搜索计算二叉树的层平均值,需要维护两个数组,counts 用于存储二叉树的每一层的结点数,sums 用于存储二叉树的每一层的结点值之和。搜索过程中需要记录当前结点所在层,如果访问到的结点在第 i 层,则将 counts[i] 的值加 1,并将该结点的值 node.val 加到 sums[i]。
遍历结束之后,第 i 层的平均值即为 sums[i]/counts[i]。
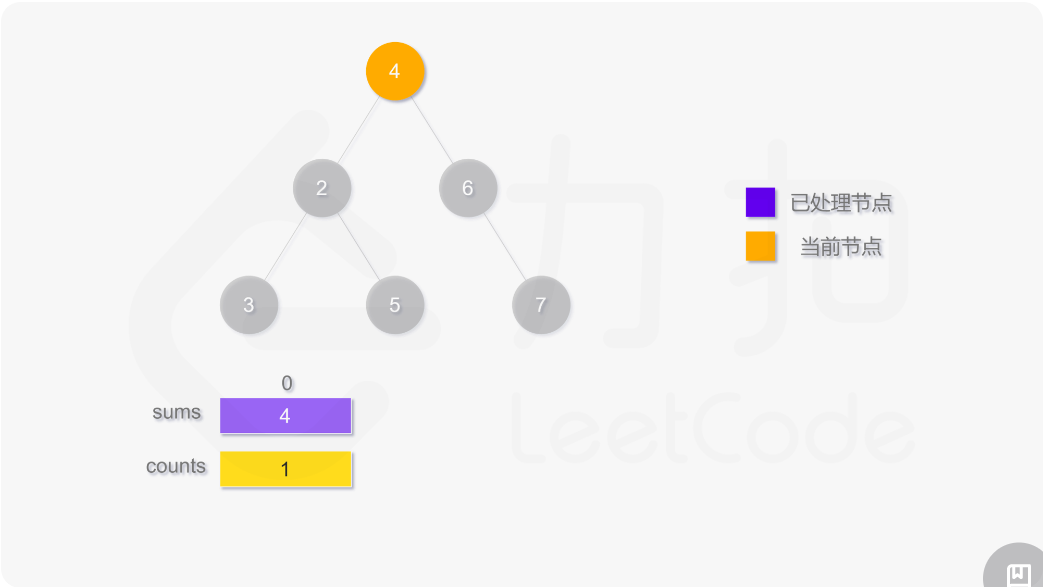
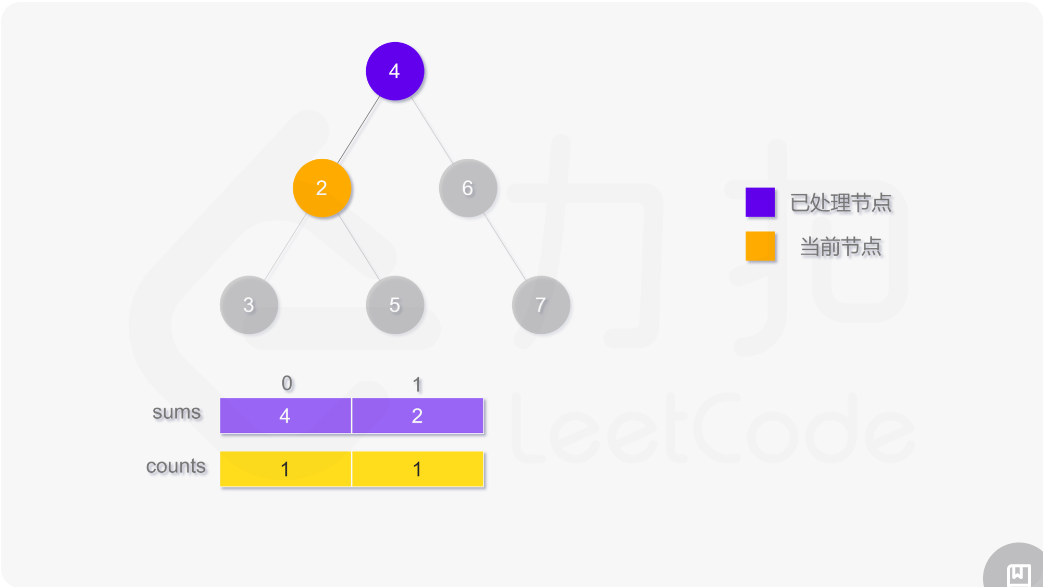
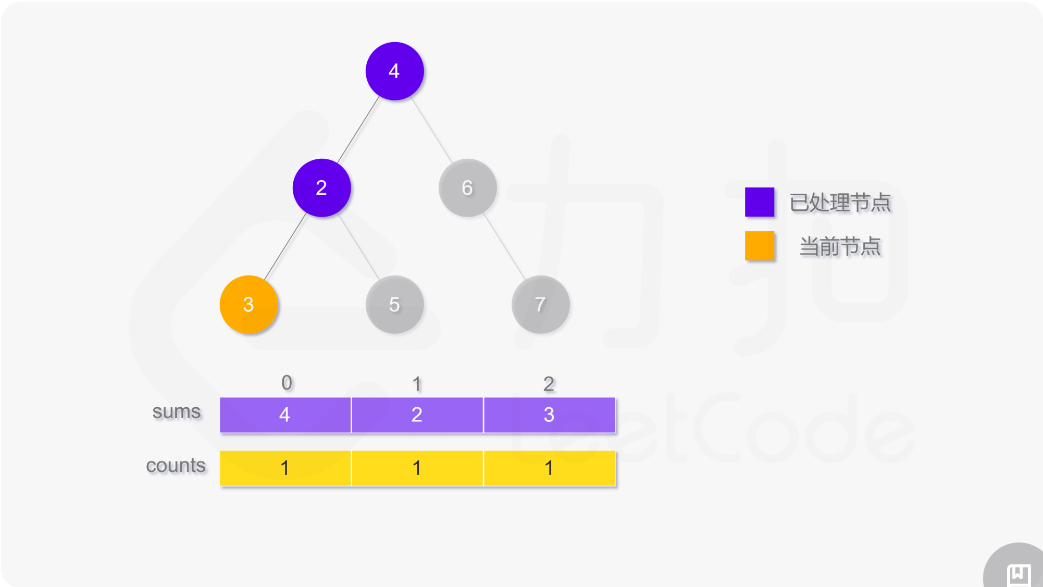
class Solution:
def averageOfLevels(self, root: Optional[TreeNode]) -> List[float]:
if not root:
return []
counts = list() # counts = [],储存每一层的结点数
sums = list() # sums = [],储存每一层的结点值之和
def dfs(node:TreeNode, level:int):
if not node:
return # return None
if level < len(sums):
sums[level] += node.val
counts[level] += 1
else:
sums.append(node.val)
counts.append(1)
dfs(node.left, level + 1)
dfs(node.right, level + 1)
dfs(root, 0)
return [sum / count for sum, count in zip(sums, counts)]
时间复杂度:O(n),其中 n 是二叉树中的节点个数。深度优先搜索需要对每个结点访问一次,对于每个结点,维护两个数组的时间复杂度都O(1),因此深度优先搜索的时间复杂度是 O(n)。遍历结束之后计算每层的平均值的时间复杂度是 O(h),其中 h 是二叉树的高度,任何情况下都满足 h ≤ n。
因此总时间复杂度是 O(n)。
空间复杂度:O(n),其中 n 是二叉树中的结点个数。空间复杂度取决于两个数组的大小和递归调用的层数,两个数组的大小都等于二叉树的高度,递归调用的层数不会超过二叉树的高度,最坏情况下,二叉树的高度等于结点个数 n。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号