
Grafana监控指标、日志与链路追踪数据采集到GreptimeDB的完整实践指南
以下是将Grafana监控指标、日志与链路追踪数据采集到GreptimeDB的完整实践指南,涵盖部署、运维、安全及扩展的全流程:
一、整体架构
图表
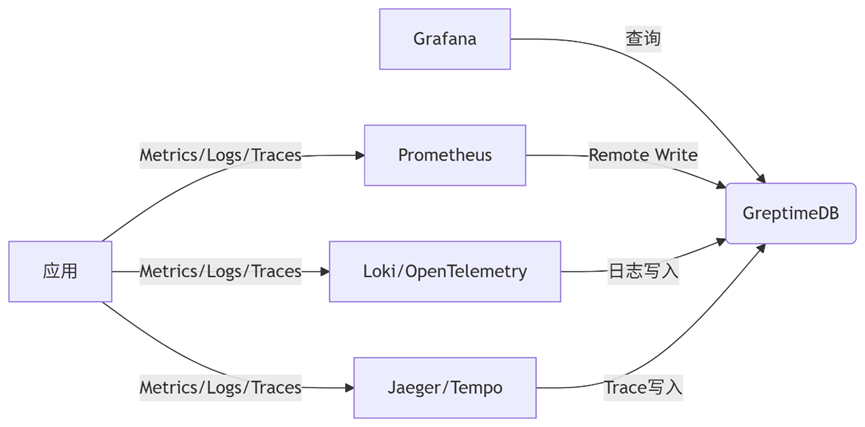
二、数据采集配置
1. 指标采集(Prometheus → GreptimeDB)
步骤:
- 修改Prometheus配置
yaml
remote_write:
- url: "http://<greptimedb>:4000/v1/prometheus/write?db=public"
- 验证数据
sql
SELECT * FROM prometheus_metrics LIMIT 10;
2. 日志采集(Loki → GreptimeDB)
方案:
- 通过OpenTelemetry Collector中转
yaml
# otel-collector-config.yaml
exporters:
greptimedb:
endpoint: "greptimedb:4000"
database: "logs"
service:
pipelines:
logs:
receivers: [otlp]
exporters: [greptimedb]
- Fluentd直写(需开发插件)
ruby
<match **>
@type greptimedb
host greptimedb
port 4000
database logs
</match>
3. 链路追踪(Jaeger/Tempo → GreptimeDB)
步骤:
- Jaeger配置
yaml
remote:
storage:
type: grpc-plugin
grpc-storage:
server: "greptimedb:4001"
- OpenTelemetry直写
yaml
exporters:
greptimedb:
traces_endpoint: "http://greptimedb:4000/v1/otlp/traces"
三、Grafana数据源配置
yaml
datasources:
- name: GreptimeDB
type: greptimedb-datasource
url: http://greptimedb:4000
jsonData:
timeField: "timestamp"
version: "latest"
四、运维操作指南
1. 日常监控
- 关键指标:
sql
SELECT
mem_used / mem_total AS mem_ratio,
cpu_usage
FROM system_metrics
WHERE region='cn-east-1'
2. 数据备份
方案:
- 逻辑备份(CSV导出)
bash
greptime --host=<addr> --query "COPY (SELECT * FROM logs) TO 'logs.csv'"
- 物理备份(分布式存储快照)
bash
# 1. 创建快照
curl -X POST http://<meta>:3002/v1/snapshot
# 2. 备份S3/HDFS
aws s3 sync /var/lib/greptime/snapshots s3://backup-bucket
3. 安全加固
措施:
yaml
# greptime.toml
[security]
# 启用TLS
tls_mode = "require"
cert_file = "/path/to/server.crt"
key_file = "/path/to/server.key"
# 访问控制
[[user]]
username = "grafana_rw"
password = "encrypted_password"
permissions = ["read", "write"]
4. 扩容操作
垂直扩容:
bash
# 修改部署配置(K8s示例)
resources:
limits:
cpu: 8
memory: 32Gi
水平扩容:
- 添加数据节点
bash
greptime --start meta --node-id=3 --addr=0.0.0.0:3002
- 重平衡数据
sql
ALTER TABLE logs REBALANCE PARTITIONS;
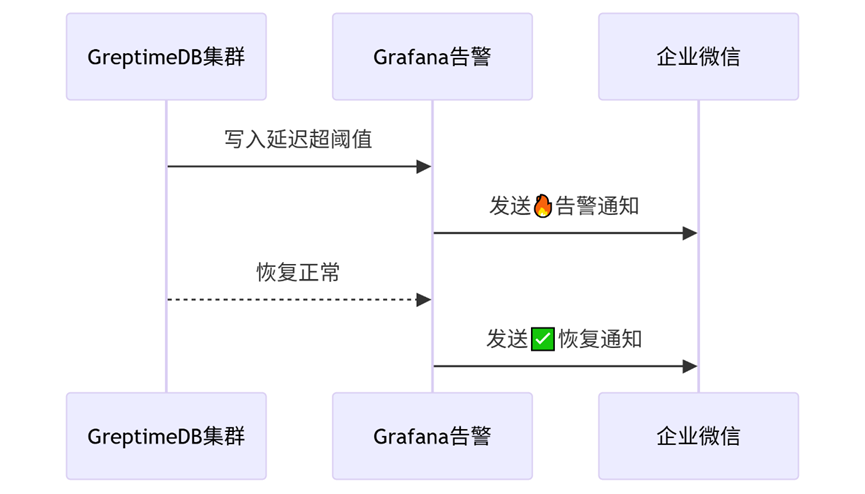
5. 告警通知管理
日常操作:
bash
# 查看活跃告警
curl -u admin:password http://grafana:3000/api/v1/alerts
# 测试通知通道
curl -X POST http://grafana:3000/api/v1/notifications/test/wecom-notifier
灾难恢复增强:
图表
安全加固补充
在原有安全配置中增加:
yaml
# greptime.toml
[security.alert_auth]
# 告警API访问控制
wecom_key = "encrypted_xxxxxxxx"
dingding_token = "encrypted_xxxxxxxx"
告警模块注意事项
- 消息去重机制
sql
ALTER TABLE alerts ADD DEDUP KEY(alert_name, instance);
- 敏感信息过滤
yaml
# otel-collector-config.yaml
processors:
redaction:
patterns: ["password=\\w+", "token=[a-f0-9]{32}"]
- 通知频次控制
yaml
# Grafana告警规则
- alert: 节点故障
...
annotations:
# 限制相同告警每30分钟通知一次
repeat_interval: 30m
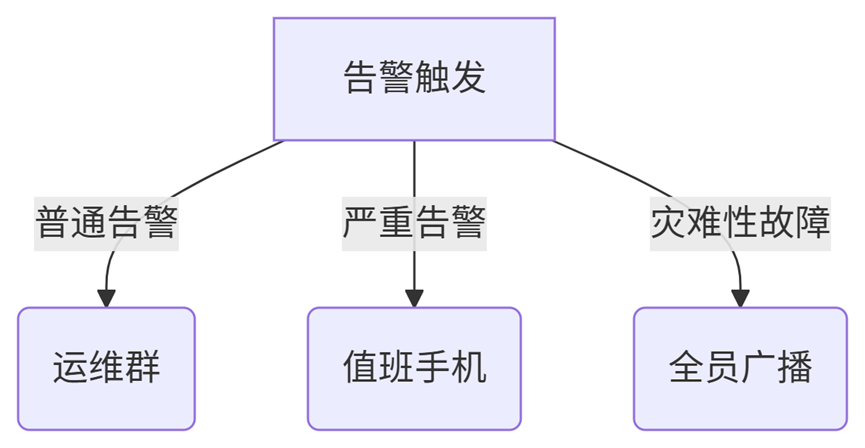
- 多级通知策略
图表
故障恢复验证流程
- 模拟故障注入
bash
# 触发写入延迟
stress-ng --cpu 8 --io 4 --timeout 300s
- 验证通知链:
- 企微/钉钉收到🔥告警
- 故障解除后收到✅恢复通知
- 检查告警状态同步
sql
SELECT * FROM alert_history
WHERE resolved = true AND notified = false;
关键优化:使用GreptimeDB的TQL实现告警状态自动追踪:
sql
CREATE TQL CONTINUOUS QUERY alert_tracker
BEGIN
SELECT
alert_name,
latest(status) as current_status,
sum(if(status='firing',1,0)) as firing_count
FROM alerts
GROUP BY time(1m), alert_name
END;
至此,告警通知模块已完整集成到GreptimeDB的监控体系中,实现从数据采集、存储、告警到通知的全闭环管理。
五、深度优化策略
1. 存储优化
- 分区策略:
sql
CREATE TABLE logs (
ts TIMESTAMP,
log TEXT,
PARTITION BY RANGE COLUMNS(ts) (
PARTITION p2024 VALUES LESS THAN ('2025-01-01')
)
)
2. 查询加速
- 物化视图:
sql
CREATE MATERIALIZED VIEW error_logs AS
SELECT * FROM logs WHERE level='ERROR'
3. 成本控制
- 冷热分离:
yaml
# greptime.toml
[storage]
hot_data_bucket = "s3://hot-bucket"
cold_data_bucket = "s3://glacier-bucket"
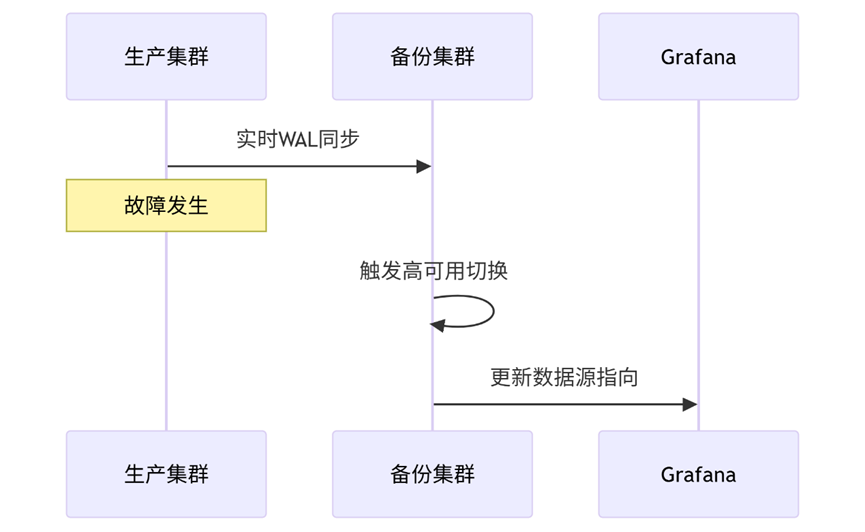
六、灾难恢复流程
图表
七、注意事项
- 版本兼容性
- GreptimeDB ≥ v0.4 支持完整OTLP协议
- Prometheus ≥ v2.25 需验证remote_write兼容性
- 资源预留
- 日志采集场景预留10%额外内存用于文本处理
- 安全审计
sql
CREATE AUDIT POLICY log_audit
ON logs
USING (user_name, query_time)
- 监控告警规则
yaml
# Grafana Alert
expr: rate(greptime_storage_write_errors[5m]) > 0
labels:
severity: critical
八、常见故障处理
|
现象 |
排查点 |
解决方案 |
|
写入延迟高 |
WAL同步延迟 |
增加datanode数量 |
|
日志字段丢失 |
OTel Collector映射错误 |
检查attribute处理器配置 |
|
分布式查询超时 |
节点时钟不同步 |
部署NTP服务 |
|
Prometheus数据断点 |
remote_write重试次数不足 |
增大max_retries=10 |
关键建议:生产环境部署前使用 GreptimeDB Bench 进行压力测试,验证不同工作负载下的性能表现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号