[从今天开始修炼数据结构]图的最小生成树 —— 最清楚易懂的Prim算法和kruskal算法讲解和实现
接上文,研究了一下算法之后,发现大话数据结构的代码风格更适合与前文中邻接矩阵的定义相关联,所以硬着头皮把大话中的最小生成树用自己的话整理了一下,希望大家能够看懂。
一、最小生成树
1,问题
最小生成树要解决的是带权图 即 网 结构的问题,就是n个顶点,用n-1条边把一个连通图连接起来,并且使得权值的和最小。可以广泛应用在修路建桥、管线运输、快递等各中网络方面。我们把构造连通图的最小代价生成树成为最小生成树。
最小生成树有两个算法 普里姆算法和克鲁斯卡尔算法
2,普里姆算法
(1)普里姆算法的思路是,从一个入口进入,找到距离入口最近的下一个结点;现在你有了两个结点,找到分别与这两个结点连通的点中,权值最小的;现在你有了三个结点,分别找到与这三个结点联通的点中,权值最小的;……
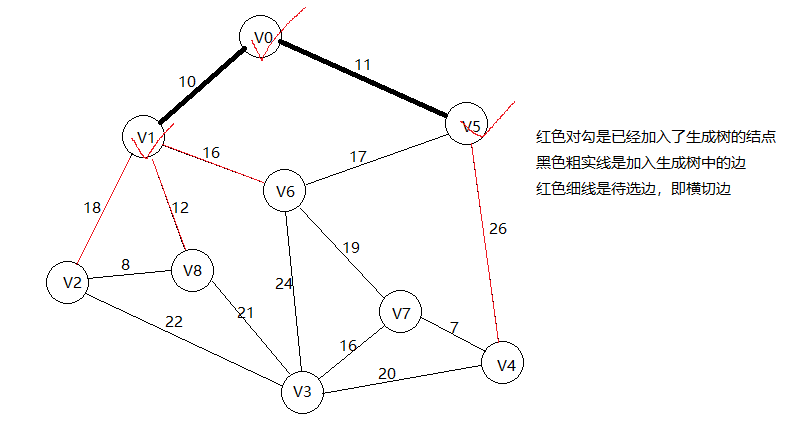
从思路可以看出,这就是一个切分问题。将一副加权图中的点进行区分,它的横切边中权值最小的必然属于子图的最小生成树。(横切边,指连接两个部分的顶点的边)也就是将已经找到的点,和没找到的点进行区分。
解决思路就是贪心算法,使用切分定理找到最小生成树的一条边,并且不断重复直到找到最小生成树的所有边。
(2)实现思路
下面我们就来一步一步地实现普里姆算法。为了方便讨论,我们先规定一些事情。a,只考虑连通图,不考虑有不连通的子图的情况。b,只考虑每条边的权值都不同的情况,若有权值相同,会导致生成树不唯一
c,Vi的角标对应了其在vertex[]中存储的角标。 d,这里我们从V0为入口进入。e,这里我们使用的是上一篇文章实现的邻接矩阵存储的图结构。
首先,我们拿到一张网。
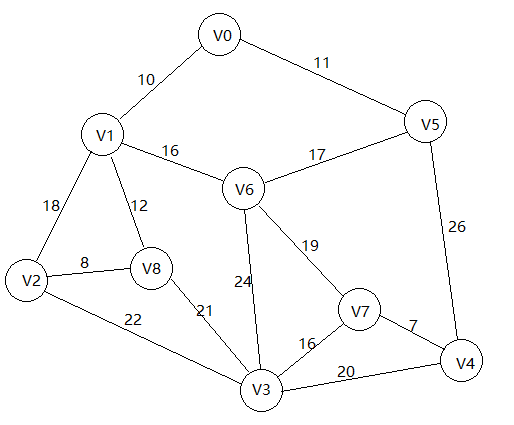
我们从V0进入,找到与V0相连的边,邻接点和权值。我们需要容器来存储,因为是邻接矩阵存储的,所以我们这里用一维数组来存储这些元素,我们仿照书中的代码风格,定义一个adjvex[numVertex]和一个lowcost[numVertex]。这两个数组的含义和具体用法我们后面再说,现在你只需要知道它们是用来横切边,邻接点和权值的。adjvex[]的值被初始为0,因为我们从V0开始进入。lowcost[]的值被初始化为INFINITY,因为我们要通过这个数组找到最小权值,所以要初始化为一个不可能的大值,以方便后续比较,但这里的INFINITE 不需要手动设置,因为edges中已经将没有边的位置设置为了I,所以只需要在拷贝权值时同事将I也拷贝过来。
现在我们的切分只区分了V0和其他点,横切边权值有10,11,分别对应邻接点V1,V5,我们将V1,V5的对应权值按照其在vertex[]中存储的角标1,5来存入lowcost,将与V1,V5对应的邻接点V0的角标0存入adjvex[]中(其实所有顶点的邻接点对应角标都被初始化为0)。所以我们现在得到
adjvex[] = { 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 };
lowcost[] = { 0 ,10 , I , I , I , 11 , I , I , I };
这里大家要理解这两个数组的含义,我再仔细解释一下。lowcost中存有非I元素的位置的下标,表示的是,横切边所连接的,没有被连入生成树的一端的顶点在vertex[]中保存的下标,在这里也等于Vi的下标,也可以理解为“刚刚被发现的结点的下标”。
然后adjvex[]中保存了非0元素的下标,与lowcost的中的下标是一样的意义,只不过这里因为被划分的点是0所以数组中没有非0元素。
lowcost中存有的非I元素,表示的是,这个位置对应的顶点与现有最小生成树的横切边中权值最小的一条边的权值。
adjvex中存有的非0元素,是一个顶点在vertex[]中的下标,表示的是该角标index对应的vertex[index]与adjvex[index]这两个顶点之间的权值最小,该权值是lowcost[index]。
这样大家应该能够对大话数据结构中这一部分有完整的理解了。
我们现在从lowcost[]中找到最小的权值,然后将该权值对应的顶点加入最小生成树。加入的方式是将该权值置为0,并且将该新结点的邻接点在adjvex中对应的角标置为该新结点的index。
对应现在的情况,就是把V1加入生成树,把两个数组调整如下:
adjvex[] = { 0 , 0 , 1 , 0 , 0 , 0 , 1 , 0 , 1 };
lowcost[] = { I , 0 , 18, I , I ,11 , 16, I , 12};

接下来我们有四条待选边,lowcost中找到最小的非零权值是11,对应index为5,去vertex[5]找到V5,所以此时V5加入生成树,将lowcost[5]置为0,V5的邻接点加入adjvex和lowcost,如下
adjvex[] = { 0 , 0 , 1 , 0 , 5 , 0 , 1 , 0 , 1 };
lowcost[] = { I , 0 , 18, I , 26, 0 , 16, I , 12};
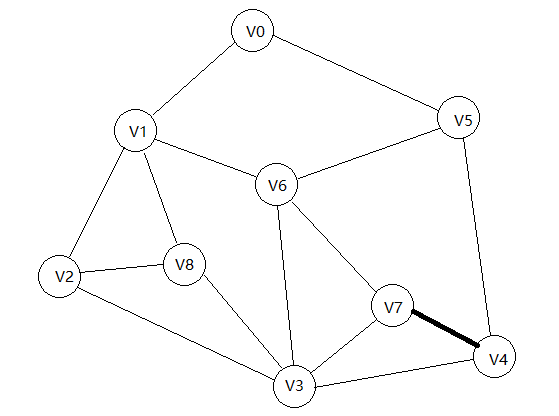
反复重复上面的动作v-1次,此时就加入了v-1条边,得到了最小生成树。
代码实现如下:
public void MiniSpanTree_Prim(){ int[] adjvex = new int[numVertex]; int[] lowcost = new int[numVertex]; adjvex[0] = 0; lowcost[0] = 0; /* for (int i = 1; i < numVertex; i++){ lowcost[i] = INFINITY; } */ for (int i = 1; i < numVertex; i++) { lowcost[i] = edges[0][i]; adjvex[0] = 0; } for (int i = 1; i < numVertex; i++){ int min = INFINITY; int k = 0; for (int j = 1; j < numVertex; j++){ if (lowcost[j] != 0 && lowcost[j] < min){ min = lowcost[j]; k = j; } } System.out.printf("(%d,%d,w = %d)加入生成树",adjvex[k],k,min); System.out.println(); lowcost[k] = 0; for (int j = 1; j < numVertex; j++){ if (lowcost[j] != 0 && lowcost[j] > edges[k][j]){ lowcost[j] = edges[k][j]; adjvex[j] = k; } } } }
2,克鲁斯卡尔(Kruskal)算法
如果说普里姆算法是面向顶点进行运算,那么克鲁斯卡尔算法就是面向边来进行运算的。
(1)思路:克鲁斯卡尔算法的思路是,在离散的顶点集中,不断寻找权值最小的边,如果加入该边不会在点集中生成环,则加入这条边,直到获得最小生成树。
所以我们的问题就是两个,第一个:将边按照权值排序 第二个:判断加入一条边之后会不会生成环
将边按照权值排序很容易,这里我们用边集数组
那么如何判断环呢? 克鲁斯卡尔判断环的依据是,在一棵树结构中,如果对其中两个结点添加一条原本不存在的边,那么一定会产生一个环。而一棵树中,根节点是唯一确定的。我们将添加边抽象为建立一棵树,并用数组parent[numVertex]存储这棵树的结构,下标index与结点在vertex[]中的位置vertex[index]相同,parent[index]是这个结点在这棵树中的父亲结点。每次添加一条边,就是在扩大森林中某一棵树,当森林全部连成一棵树,则得到了最小生成树。
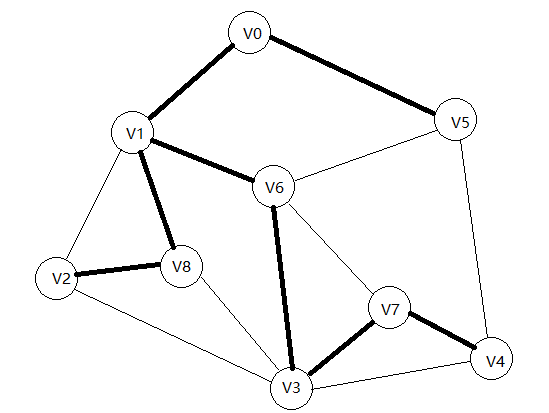
(2)具体步骤:我们这里使用与普里姆相同的例子
其边集数组排序后为
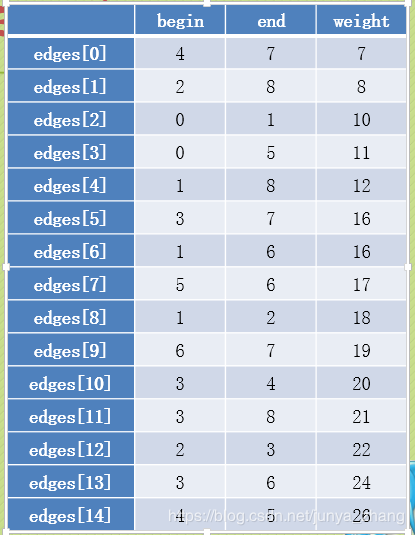
我们遍历边集数组,首先拿到edges[0],分别判断4和7是否拥有相同的最大顶点,方法是进入parent[]中查询它们所在的树的根结点是否相同。因为是第一次查询,所以结果都是0,即它们不是同一棵树,可以连线。连线时,将parent[4]置7或者将parent[7]置4都可以,这里我们选择前者。

下面拿到edges[1],查询parent[2],parent[8]得均为0,则不是同一棵树,可以连线。我们将parent[2]置8
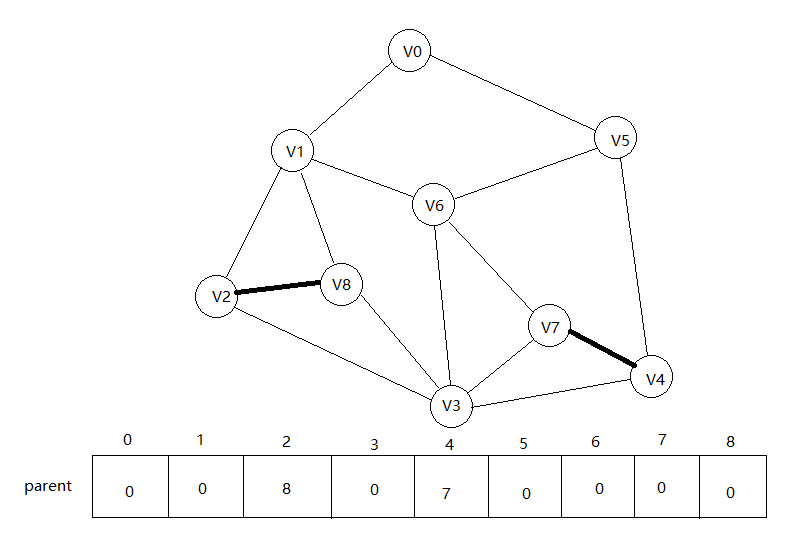
下面是edges[2],查询0,1,可以连线。

接下来edges[3],查询0,5,此时V0的父是V1,V1对应的parent[1]中存储的0表示V1是这棵树的父,parent[5]=0,即V0和V5不是同一棵树,可以连线。将parent[1]置为5
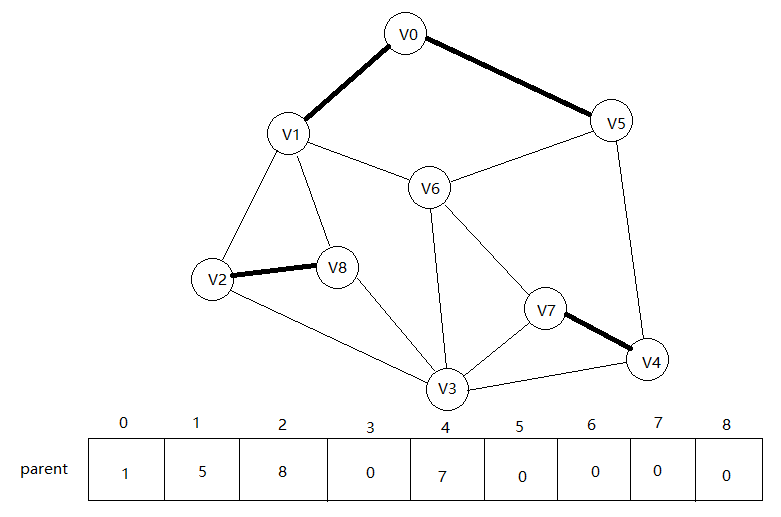
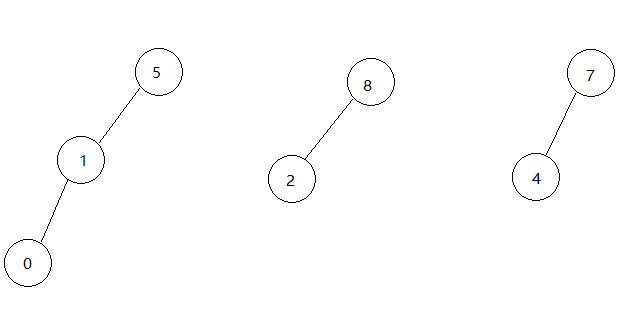
接下来edges[4], 查询1,8,不在同一棵树,此时1所在树的根是5,将1和8连线,此时树合并应该将根节点5的parent[5]置为8.现在上图的两个棵树合并了
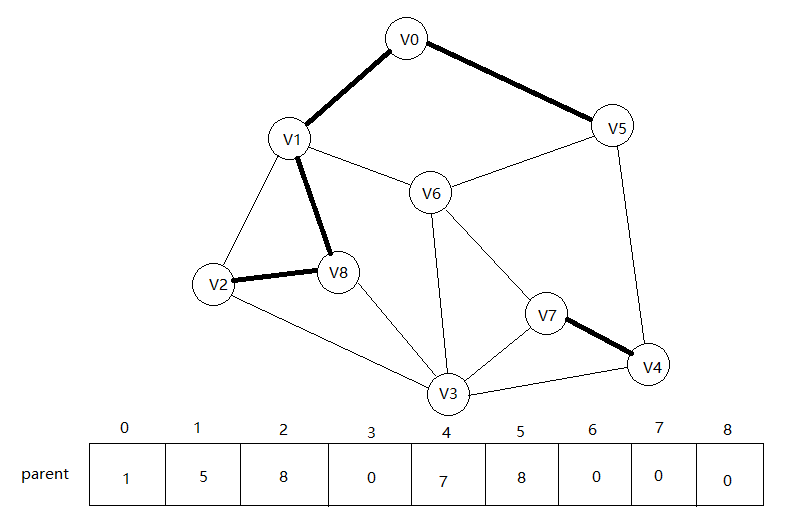
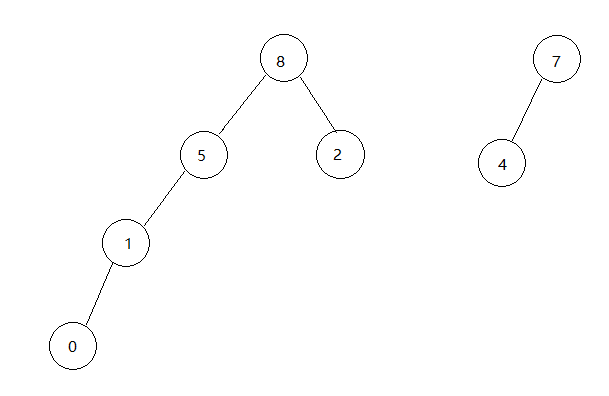
接下来是edges[5],查询3,7,不在同一子树,连线。
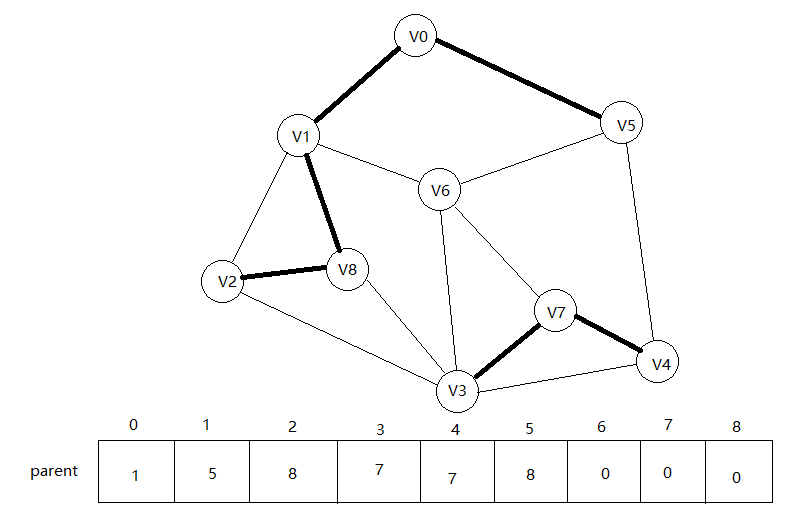
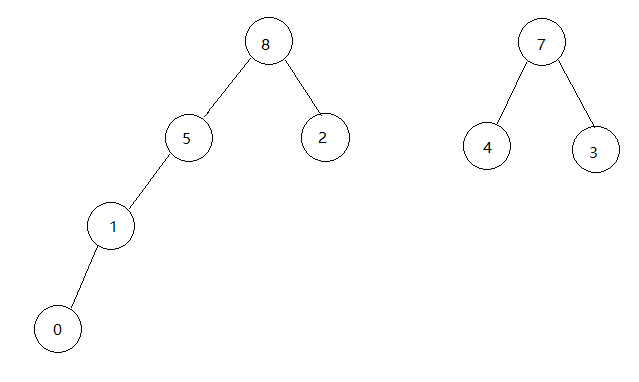
接下来是edges[6],查询1,6,不在同一子树,连线。
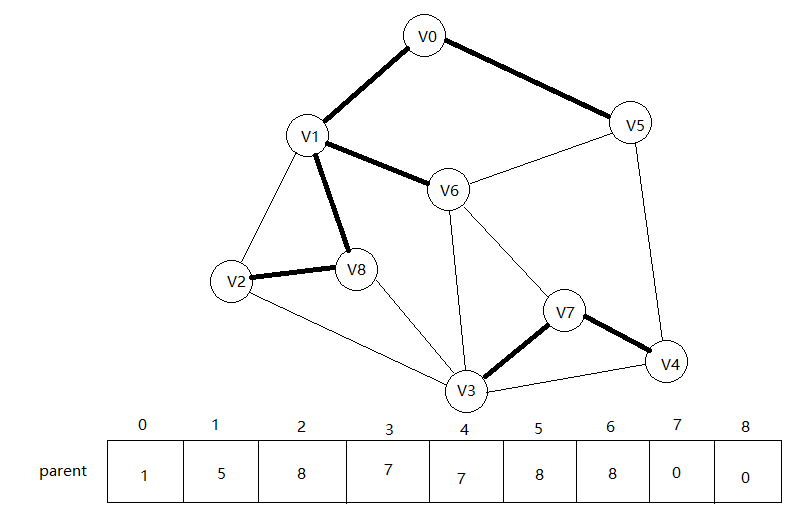
接下来是edges[7]查询5,6,发现它们的根节点都是8,在同一棵子树,所以不连线。
下面我就不再重复了,总之这样循环检测,可以得到最终的最小生成子树。(注!最小生成子树和我们上面用来判断是否连通的树是不同的!parent数组也并不是唯一的!因为在构造判断树的时候,不管把谁做父,谁做子,都可以构建树,并不影响判断环的结果)
(3)代码实现
/* 定义边结构的内部类。 */ private class Edge implements Comparable<Edge> { private int begin; private int end; private int weight; private Edge(int begin, int end, int weight){ this.begin = begin; this.end = end; this.weight = weight; } @Override public int compareTo(Edge e) { return this.weight - e.weight; } public int getBegin() { return begin; } public void setBegin(int begin) { this.begin = begin; } public int getEnd() { return end; } public void setEnd(int end) { this.end = end; } public int getWeight() { return weight; } public void setWeight(int weight) { this.weight = weight; } }
/** * 得到排序好的边集数组,用ArrayList存储 * @return */ public ArrayList<Edge> getOrderedEdges() { ArrayList<Edge> edgeList = new ArrayList<>(); for (int row = 0; row < numVertex; row++){ for (int col = row; col < numVertex; col++){ if(edges[row][col] != 0 && edges[row][col] != INFINITY){ edgeList.add(new Edge(row, col, edges[row][col])); } } } Collections.sort(edgeList); return edgeList; } /** * 克鲁斯卡尔算法 */ public void MiniSpanTree_Kruskal(){ ArrayList<Edge> edgeList = getOrderedEdges(); int[] parent = new int[numVertex]; for (int i = 0; i < numVertex; i++){ parent[i] = 0; } for (int i = 0; i < edgeList.size(); i++){ int m = findRoot(edgeList.get(i).getBegin(), parent); int n = findRoot(edgeList.get(i).getEnd(), parent); if (m != n){ link(edgeList.get(i), parent, m, n); } } } /* 连接两点,并且设置parent数组 */ private void link(Edge edge, int[] parent, int m, int n) { System.out.printf("(%d,%d),weight = %d 加入最小生成树", edge.getBegin(), edge.getEnd(), edge.getWeight()); System.out.println(); parent[m] = n; } /* 找到本子树的根节点 */ private int findRoot(int root, int[] parent) { while (parent[root] > 0){ root = parent[root]; } return root; }
总结:克鲁斯卡尔的FindRoot函数的时间复杂度由边数e决定,时间复杂度为O(loge),而外面有一个for循环e次,所以克鲁斯卡尔的时间复杂度是O(eloge)
对立两个算法,克鲁斯卡尔主要针对边展开,边少时时间效率很高,对于稀疏图有很大优势,;而普里姆算法对于稠密图会更好一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号