largebin_attack
largebin_attack
写在前面
本篇用于简要记录学习笔记,并不详细阐述原理,以后有机会有时间再改成详尽的解说。如果你对于这一块知识不是很熟悉,我不建议你看这个文章。但是如果你已经学习过这块知识,仅仅是想重新回顾一下强化一下记忆,那这篇文章也许能帮到你。
large bin结构回顾
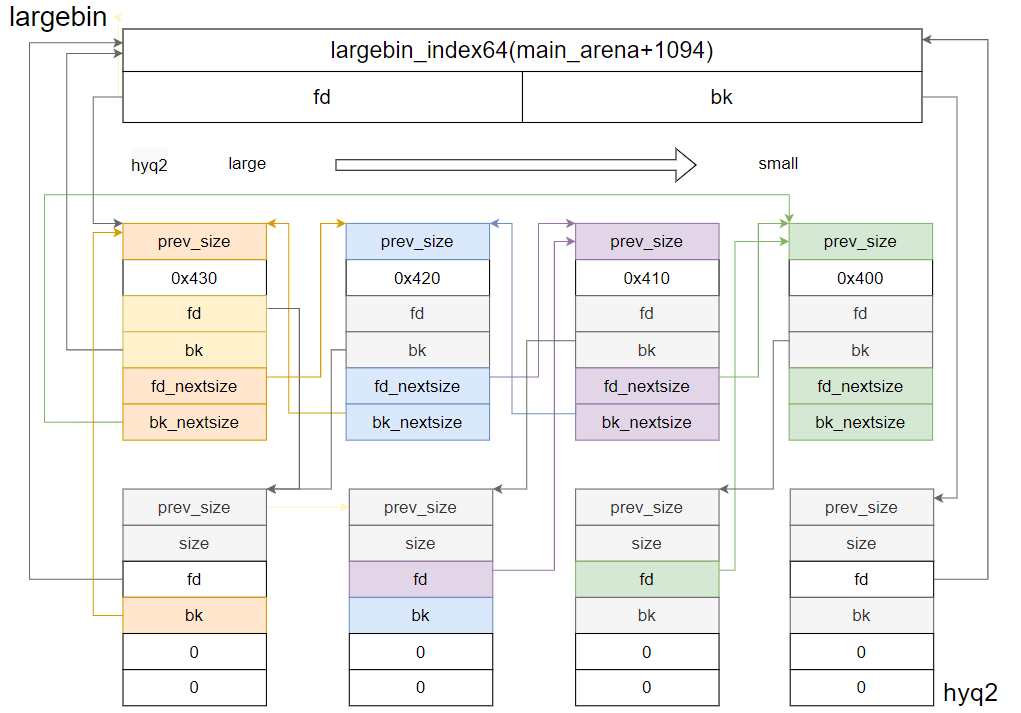
所有堆块按照大小顺序,通过fd和bk指针链接成一个双向循环列表,最靠近largebin头部的是最大的堆块
此外,对于任意一种特定大小的chunk,其第一个进入large bin的堆块会作为头部,与其他大小的第一个堆块通过fd_nextsize与bk_nextsize相互连接成另一个双向循环链表。
我在这里找了一个很好的图示,取自:About Largebin。这里不得不吐槽一下,网络上有很多示意图都是错误的,大家一定要注意甄别。
2.30之前的largebin attack
关于largebin attack,首先要先理明白什么时候一个堆块会进入large bin。一般来说,只有unsorted bin中的堆块在大循环中被取出且仍然不符合我们的需求时,才会进入large bin。而且你得保证这个堆块进入large bin后,不会立刻被取出来用作切割(会出问题的,最好提前准备一个小一点的堆块作为炮灰)
因此我们的关注点应该集中于malloc中unsorted bin chunk被取出并进入large bin的过程
和unsorted bin attack类似,large bin attack利用的也是双向链表完整性检查不完整的缺陷来尝试将堆地址写到程序的某个地方,只不过unsorted bin attack利用的检查缺陷在2.28的glibc中被修复了。
先看看2.30之前的large bin attack
我们要保证,large bin中应该已经有了一个chunk,且释放进来的chunk应该为当前large bin中最大的chunk。
{
victim_index = largebin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
if (fwd != bck)
{
//......
if ((unsigned long) (size) < (unsigned long) (bck->bk->size))
{
//......这里size小于large bin中最小chunk,我们这里不用这条分支
}
else
{
assert ((fwd->size & NON_MAIN_ARENA) == 0);
while ((unsigned long) size < fwd->size)
{
fwd = fwd->fd_nextsize;
assert ((fwd->size & NON_MAIN_ARENA) == 0);
}
if ((unsigned long) size == (unsigned long) fwd->size)
/* Always insert in the second position. */
//相等可以不看了
fwd = fwd->fd;
else
{
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;
}
bck = fwd->bk;
}
}
else
victim->fd_nextsize = victim->bk_nextsize = victim;
}
mark_bin (av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;
审计代码,我们可以知道,这里进行了两个双向链表的插入,一个是fd指针和bk指针构成,一个是fd_nextsize和bk_nextsize指针构成。
对于双向循环链表的插入操作,要定位到插入点前后的元素。而这个定位方法往往决定漏洞利用方式。
关于fd_nextsize与bk_nextsize构成的双向链表的攻击思路如下:
从large bin开始fd指针起手找最大chunk作比较,这里立刻发现比最大的chunk还大,那么fwd就你了。
fwd理所当然成为victim->fd_nextsize,而对于这里的"bck",并没有占用bck这个指针变量,而是直接通过fwd->bk_nextsize寻找到后赋值给victim,然后再通过victim->bk_nextsize找到这个"bck"并设置其fd_nextsize.
因此我们发现,"bck"的定位取决于fwd的bk_nextsize。且没有尝试找到"bck"后再向前找回fwd。我们就可以通过篡改在large bin中的chunk的bk_nextsize为target_addr-0x20,将victim的地址给写target_addr的地方。
接下来我们会发现,这里设置了bck,因为接下来要进行fd与bk构成的双向链表的插入操作
仔细看bck的寻找方式,它是通过fwd的bk指针找到的。
后面同样没有关于bck能否通过fd找回fwd做一个检查。因此我们如果能劫持这个已经进入large bin的堆块的bk指针指向target_addr-0x10,就能在target_addr处写入victim的地址。
这里是较早版本的large bin attack的手法。但是在高版本中针对双向链表完整性加入了新的检查,导致在2.30的glibc之后这个方法失效。
2.30之后的largebin attack
其实,安全性检查,添加了,但是没有完全添加。
{
victim_index = largebin_index (size);
bck = bin_at (av, victim_index);
fwd = bck->fd;
/* maintain large bins in sorted order */
if (fwd != bck)
{
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
if ((unsigned long) (size) < (unsigned long) chunksize_nomask (bck->bk))
{
fwd = bck;
bck = bck->bk;
victim->fd_nextsize = fwd->fd;
victim->bk_nextsize = fwd->fd->bk_nextsize;
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
}
else
{
assert (chunk_main_arena (fwd));
while ((unsigned long) size < chunksize_nomask (fwd))
{
fwd = fwd->fd_nextsize;
assert (chunk_main_arena (fwd));
}
if ((unsigned long) size== (unsigned long) chunksize_nomask (fwd))
/* Always insert in the second position. */
fwd = fwd->fd;
else
{
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
if (__glibc_unlikely (fwd->bk_nextsize->fd_nextsize != fwd))
malloc_printerr ("malloc(): largebin double linked list corrupted (nextsize)");
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim;
}
bck = fwd->bk;
if (bck->fd != fwd)
malloc_printerr ("malloc(): largebin double linked list corrupted (bk)");
}
}
else
victim->fd_nextsize = victim->bk_nextsize = victim;
}
mark_bin (av, victim_index);
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim;
可以看到我们之前利用的分支里面加入了malloc_printerr函数,对于上述情况做了安全检查。但是对于size小于large bin中最小chunk的分支并未进行检查,因此仍有可利用之机。
一开始,fwd是large bin,bck直接从large bin用bk指针定位到最小的堆块。这两个指针不受我们控制。
双向链表插入点中,前一个堆块的寻找是通过large bin的fd指针直接找最大的堆块,但是插入前最小的堆块是通过这个最大堆块的bk_nextsize找到的,而且找到后这里竟然没有添加一个安全检查。所以我们劫持这个最大堆块的bk_nextsize为target_addr-0x20,就可以把victim的地址写入target_addr

 浙公网安备 33010602011771号
浙公网安备 33010602011771号