模拟退火 - 学习笔记
前置知识:爬山算法
从爬山算法的局限到模拟退火
对于爬山算法所求解问题:计算一个函数的最大/小值。
我们知道它的核心目标是求解函数的最大值或最小值 —— 就像人沿着山坡向上爬,始终朝着 “更高”(求最大值)或 “更低”(求最小值)的方向移动,直到无法找到更优的下一步。
但爬山算法有个致命局限:极易陷入局部最优解。比如在连绵的山脉中,它可能爬到一座小山的山顶(局部最优),就误以为那是整个山脉的最高峰(全局最优),却看不到不远处更高的山峰。为了突破这个瓶颈,科学家们借鉴了物理中 “固体退火” 的原理,设计出一种看似 “玄学”、实则逻辑严谨的优化算法——模拟退火。
模拟退火的核心思路:主动接受 “不完美” 以跳出局限。
模拟退火的关键突破,在于它不执着于每次都选择更优解,而是在一定概率下主动接受 “非最优解”。这种 “退一步” 的策略,正是它能跳出局部最优、向全局最优靠近的核心。
如图所示:即使当前处于一个局部高点,算法也可能暂时 “向下走”,探索周围区域,最终找到真正的全局最高点。
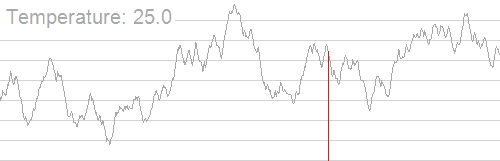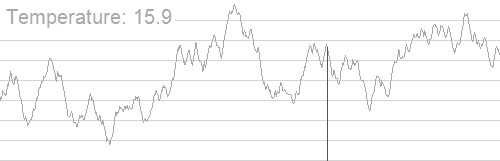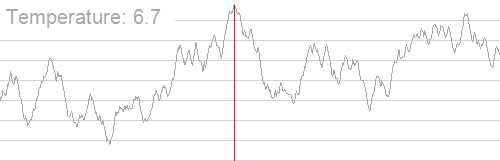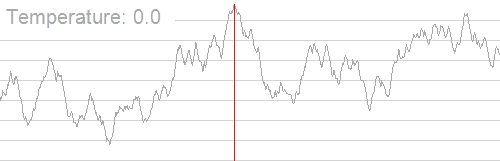
接受非最优解的依据:Metropolis 准则
刚才提到的 “接受非最优解的概率”,并非随机决定,而是遵循严格的Metropolis准则——其概率计算公式为:\(P=e^{-\frac{\Delta E}{T}}\)。
我们来拆解公式中两个关键参数的含义:
-
\(\Delta E\)(能量差):在函数极值问题中,可理解为新解与当前解的目标函数值之差。若我们求函数最大值,\(\Delta E=f(新解)-f(当前解)\):
当 \(\Delta E \gt 0\) 时,新解更优,算法会必然接受这个新解(类似爬山算法的逻辑);
当\(\Delta E \leq 0\)时,新解是 “非最优解”,算法会根据\(e^{-\frac{\Delta E}{T}}\)的概率决定是否接受它。 -
\(T\)(当前温度):模拟退火的 “温度” 是一个动态变化的参数,并非物理中的温度,但其核心作用类似 —— 温度越高,分子运动越剧烈,算法越容易接受非最优解;温度越低,算法越谨慎,接受非最优解的概率越小。
模拟退火的三大关键参数
算法的效果很大程度上依赖于三个核心参数的设置,它们共同控制着 “温度下降” 和 “解的探索” 过程:
-
初始温度 \(T_0\):算法开始时的 “初始温度”。\(T_0\) 需要设置得足够高——此时算法接受非最优解的概率大,能更自由地探索整个解空间,避免一开始就被局部最优 “困住”。
-
降温系数 \(\Delta T\):控制温度下降的 “速度”,最常用 0.99。每次迭代后,当前温度 \(T\) 会更新为$ T=T \times \Delta T$。降温系数不能太小(否则温度降得太快,容易提前陷入局部最优),也不能太大(否则算法效率太低,耗时过长)。
-
最终温度 \(T_t\):算法停止的 “终止条件”,通常是一个极小值(如 \(10^{-8}\)或\(10^{-10}\))。当当前温度 \(T\) 降至 \(T_t\) 以下时,算法对非最优解的接受概率已趋近于0,解也基本稳定在全局最优(或近似全局最优)附近,此时算法停止。
模拟退火的核心流程
简单梳理一下算法的执行逻辑,就能更清晰地理解它的工作方式:
-
初始化:设定初始温度 \(T_0\)、降温系数 \(\Delta T\)、最终温度 \(T_t\),并随机生成一个初始解;
-
迭代探索:在当前温度 \(T\) 下,通过微小扰动生成一个新解,计算新解与当前解的 \(\Delta E\);
-
接受判断:若 \(\Delta E \gt 0\)(新解更优),直接接受新解;
若 \(\Delta E \leq 0\)(新解非最优),则根据\(e^{-\frac{\Delta E}{T}}\) 的概率决定是否接受; -
降温更新:完成一次迭代后,将当前温度T更新为 \(T \times \Delta T\);
-
终止判断:重复步骤2至4,直到 \(T \lt T_t\),此时保留的解即为最终的优化结果。
总结
通过 “高温探索、低温收敛” 的策略,模拟退火既避免了爬山算法 “一叶障目” 的局限,又能在后期稳定到最优解附近,成为解决复杂函数极值、组合优化(如旅行商问题)等问题的经典算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号