【RL系列】SARSA算法的基本结构
SARSA算法严格上来说,是TD(0)关于状态动作函数估计的on-policy形式,所以其基本架构与TD的$v_{\pi}$估计算法(on-policy)并无太大区别,所以这里就不再单独阐述之。本文主要通过两个简单例子来实际应用SARSA算法,并在过程中熟练并总结SARSA算法的流程与基本结构。
强化学习中的统计方法(包括Monte Carlo,TD)在实现episode task时,无不例外存在着两层最基本的循环结构。如果我们将每一个episode task看作是一局游戏,那么这个游戏有开始也有结束,统计方法是就是一局接着一局不停的在玩,然后从中总结出最优策略。Monte Carlo与TD的区别在于,Monte Carlo是玩完一局,总结一次,而TD算法是边玩边总结。所以这两层基本结构的外层是以游戏次数为循环,内层则是以游戏过程为循环。
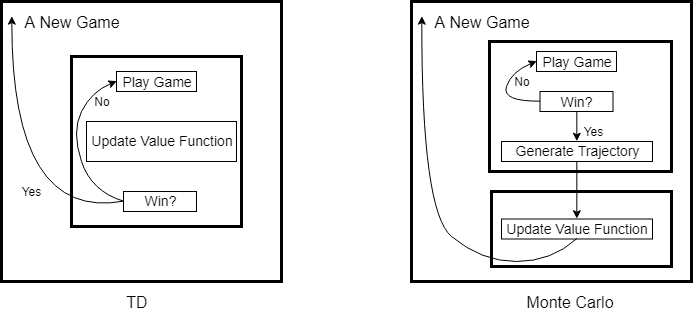
SARSA作为TD算法下的on-policy control算法,只需边进行游戏边更新动作值函数和Policy即可,所以SARSA算法的内层可以由TD算法细化为如下结构:

NumOfGames = 500
while(index < NumOfGames)
[Q, Policy] = PlayGame(Q, Policy);
end
function [Q, Policy] = PlayGame(Q, Policy)
while(1)
% Begin Game
while(1)
Action = ChooseAction(Policy(State));
NextState = State + Action + windy(State);
try
Grid(NextState) % Check for exception
catch
break;
end
NextAction = ChooseAction(Policy(NextState));
Q(State, Action) = Q(State, Action) + alpha*(R + gamma*Q(NextState, NextAction)...
- Q(State, Action));
Policy = UpdatePolicy(Policy);
State = NextState;
if(State == Target)
return;
end
end
end

 浙公网安备 33010602011771号
浙公网安备 33010602011771号